高级技巧揭秘:Mechanize库在复杂网络交互中的应用
发布时间: 2024-10-05 21:42:17 阅读量: 3 订阅数: 4 

# 1. Mechanize库概述和安装
在自动化网页交互和网络爬虫领域中,Mechanize库作为Ruby语言的一个强大工具,提供了丰富的接口来进行网页的访问、数据的抓取、表单的提交等工作。本章节将概述Mechanize库的用途,并介绍如何进行安装配置,为后续章节的学习打下坚实基础。
Mechanize库是一个开源的Ruby库,它能够模拟浏览器的行为,让用户可以编写脚本来自动化地进行网页访问和数据提取。通过Mechanize,用户可以更加便捷地实现对网页内容的读取、表单的自动填写和提交,以及文件上传等操作。
接下来,我们将探讨Mechanize库的安装过程。在Ruby环境中,Mechanize库的安装十分简单,只需使用RubyGems包管理器即可轻松完成安装。你只需打开命令行界面,并执行以下命令:
```bash
gem install mechanize
```
执行完毕后,Mechanize库将被安装到你的Ruby环境中,你可以通过编写Ruby脚本来使用Mechanize库进行网络交互任务了。安装完成后,为了验证安装是否成功,可以在命令行中运行以下代码:
```ruby
require 'mechanize'
agent = Mechanize.new
puts agent.version
```
上述代码将输出Mechanize库的版本信息,如果安装成功,你将看到版本号的打印输出。这样,我们就完成了Mechanize库的概述和安装,接下来可以进入下一章节学习如何使用这一强大的工具了。
# 2. Mechanize库的基础使用技巧
### 2.1 Mechanize库的主要功能和特性
#### 2.1.1 Mechanize库的工作原理
Mechanize库是一个用于web自动化交互的工具,它提供了一种简便的方式来模拟浏览器的行为。通过封装底层的HTTP请求,Mechanize库允许用户以编程方式访问和操作网页。其核心机制在于模拟用户与网页进行交互的过程,包括链接的点击、表单的填写与提交、以及对JavaScript渲染页面的处理。
Mechanize工作原理的关键在于其内部状态管理,它模拟了一个真实用户的浏览器环境。Mechanize维护了cookie、session等状态信息,并且可以处理JavaScript生成的动态内容。这使得Mechanize不仅能够处理普通的HTTP请求,还能够与复杂的web应用程序交互,例如那些需要用户登录或者执行JavaScript才能加载数据的网站。
Mechanize通过提供一套丰富的API来简化web自动化任务。开发者可以利用这些API来实现如自动登录、数据抓取、表单提交等功能。Mechanize会自动处理如cookie的设置和管理、网页跳转、会话跟踪等复杂任务,开发者无需直接与HTTP协议交互。
#### 2.1.2 Mechanize库的主要特性
Mechanize库的主要特性包括但不限于:
- **自动化浏览**:Mechanize可以自动加载页面、处理重定向,并且可以进行链接点击、表单提交等操作。
- **表单自动填充与提交**:支持填充和提交表单,包括自动处理文件上传。
- **会话与cookie管理**:Mechanize可以管理会话信息和cookie,使用户能够保持登录状态。
- **异常处理**:提供了丰富的异常处理机制,允许开发者处理网络错误、页面不存在等常见问题。
- **易用性**:相较于直接使用底层库如`requests`或`urllib`,Mechanize的API更加直观和易于使用。
- **跨平台支持**:Mechanize库支持多种操作系统,并且可以与多种编程语言配合使用。
### 2.2 Mechanize库的基本操作
#### 2.2.1 创建和初始化Mechanize对象
在Python中使用Mechanize,首先需要导入库并创建一个Mechanize实例。下面是一个创建和初始化Mechanize对象的简单示例:
```python
import mechanize
# 创建Mechanize对象
br = mechanize.Browser()
# 设置用户代理,模拟浏览器
br.set_handle_robots(False)
br.addheaders = [('User-agent', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 9.0)')]
# 初始化操作,打开一个页面
br.open('***')
```
在这个过程中,`Browser`类实例化创建了一个Mechanize对象。通过设置`set_handle_robots(False)`,Mechanize将绕过robots.txt协议的限制,允许爬取网站上禁止爬取的部分。而`addheaders`设置则模拟了一个具体的浏览器,这在有些网站中是必需的,因为它们可能根据访问的用户代理(User-Agent)来提供不同的内容。
#### 2.2.2 页面的访问和解析
Mechanize通过简单的API实现了页面的自动访问和解析。一旦创建了浏览器实例,就可以通过`open`方法加载页面:
```python
response = br.open('***')
# 判断页面是否加载成功
if response.geturl() == '***':
print("页面加载成功")
```
Mechanize在加载页面后会返回一个响应对象,通过这个对象可以进一步解析和操作页面内容。Mechanize还提供了链接、表单等页面元素的直接访问方法,简化了元素的查找和操作流程。
#### 2.2.3 表单的提交和文件上传
Mechanize提供了便捷的方式来自动填写表单并提交,包括文件上传功能。对于简单的表单提交,可以直接使用如下方式:
```python
# 填写表单
br.select_form('form_name') # 如果页面有多个表单,可以通过name或index选择
br['field_name'] = 'value' # 填写表单字段
br['file_field'] = ('filename', open('path/to/file', 'rb')) # 文件上传
# 提交表单
br.submit()
```
Mechanize的`select_form`方法允许指定一个特定的表单进行操作,通过`['field_name']`的方式可以模拟用户填写表单,支持文本、单选按钮、复选框等字段类型。`submit`方法则是用来提交表单,这是自动化测试和数据抓取中常见的操作。
### 2.3 Mechanize库的异常处理
#### 2.3.1 常见的异常类型和处理方法
Mechanize在执行自动化任务时可能遇到多种异常情况,例如网络请求错误、页面无响应、元素未找到等。Mechanize预定义了一些常见的异常类型,用于处理这些错误情况,如`PageNotFoundError`和`LinkNotFoundError`等。
为了使自动化任务更加健壮,开发者可以使用`try-except`语句块捕获并处理这些异常:
```python
try:
br.open('***')
except mechanize.PageNotFoundError:
print("页面不存在")
except mechanize.HTTPError as e:
print(f"HTTP请求错误:{e}")
```
以上代码段演示了如何捕获页面不存在和HTTP错误这两种异常。通过合理使用异常处理,可以让自动化任务在遇到问题时不会直接崩溃,而是执行预设的错误处理逻辑。
#### 2.3.2 自定义异常处理策略
Mechanize还允许开发者定义自定义异常处理策略。自定义策略可以让你根据应用需求灵活处理各种异常,例如重试失败的请求或者记录日志信息。
以下是一个使用自定义异常处理策略的示例:
```python
from mechanize import HTTPNotModified
# 自定义异常处理函数
def handle_not_modified(exc, request, response):
print("页面未更改,无需重新加载")
return response
# 应用异常处理策略
br.addheaders = [('User-agent', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 9.0)')]
br.add_handler(HTTPNotModified, handle_not_modified)
# 尝试加载页面
br.open('***')
```
在这个例子中,我们定义了一个自定义函数`handle_not_modified`,它会在遇到`HTTPNotModified`异常时被调用。通过使用`add_handler`方法将自定义处理函数与异常类型关联,我们让Mechanize在遇到页面未更改的情况时执行特定逻辑。这在进行性能测试或爬虫开发时非常有用,能够避免对服务器的无意义请求,提高效率。
# 3. Mechanize库的进阶应用
## 3.1 Mechanize库在爬虫开发中的应用
### 3.1.1 网页数据的抓取和解析
Mechanize库提供了一系列工具来处理网页数据的抓取和解析。以下是一个使用Mechanize进行网页数据抓取的进阶实例。
```python
import mechanize
import re
# 创建一个Mechanize实例
br = mechanize.Browser()
# 设置请求头部信息,模拟浏览器行为
br.addheaders = [('User-agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36')]
# 访问目标网页
br.open('***')
# 使用正则表达式匹配页面中的数据
html_content = br.response().read()
links = re.findall(r'<a href="([^"]+)"', html_content)
# 输出找到的链接
for link in links:
print(link)
```
在这个例子中,我们首先导入了`mechanize`和`re`模块,创建了一个`Browser`对象用于模拟浏览器行为。然后通过`open`方法访问目标网页,并使用正则表达式从响应内容中提取出所有的链接。
**代码逻辑解读和参数说明:**
- `mechanize.Browser()` 创建了一个Mechanize的浏览器对象,用于发送网络请求并解析响应。
- `br.addheaders` 设置了请求的User-Agent,防止被服务器识别为爬虫并拒绝服务。
- `br.open('***')` 通过`open`方法访问指定的URL。
- `re.findall(r'<a href="([^"]+)"', html_content)` 使用正则表达式找到所有`<a>`标签的`href`属性值。
该代码片段展示了Mechanize库如何模拟一个真实用户的请求行为,抓取并解析网页上的特定数据。
### 3.1.2 多线程爬虫的实现
Mechanize库能够支持多线程爬虫的实现,通过创建多个浏览器实例来模拟多个用户同时进行网页访问,加快数据抓取的速度。以下是一个简单的多线程爬虫实现的例子。
```python
import mechanize
import threading
import queue
def fetch_url(browser, url_queue):
while not url_queue.empty():
url = url_queue.get()
try:
browser.open(url)
# 假设我们抓取并解析数据
data = browser.response().read()
# 处理抓取到的数据
finally:
url_queue.task_done()
# 创建浏览器实例
br = mechanize.Browser(factory=mechanize.RobustFactory())
# 创建一个URL队列
url_queue = queue.Queue()
urls_to_fetch = ['***', '***']
for url in urls_to_fetch:
url_queue.put(url)
# 创建并启动线程
threads = []
for i in range(5):
t = threading.Thread(target=fetch_url, args=(br, url_queue))
t.start()
threads.append(t)
# 等待所有任务完成
for t in threads:
t.join()
```
在这个多线程爬虫的实现中,我们首先创建了一个`Browser`实例,并定义了一个用于处理单个URL的函数`fetch_url`。我们创建了一个URL队列并初始化了一些要抓取的URL。然后创建了5个线程,每个线程都会从队列中取出URL并使用浏览器实例进行抓取。最后,我们通过`join()`方法等待所有线程执行完毕。
**代码逻辑解读和参数说明:**
- `fetch_url`函数是线程的工作目标,它会从`url_queue`队列中获取URL并进行访问。
- `queue.Queue()` 创建了一个先进先出的队列用于管理待抓取的URL。
- `threading.Thread()` 创建了一个线程,通过`target`参数指定线程要执行的函数。
- `t.start()` 启动线程,使线程可以并发执行。
- `t.join()` 等待线程完成,确保主线程在所有子线程结束后才继续执行。
通过多线程,我们可以显著提高爬虫的抓取效率。不过在实际应用中,还需要考虑线程安全和服务器负载等因素。
## 3.2 Mechanize库在自动化测试中的应用
### 3.2.1 测试用例的编写和执行
Mechanize库在自动化测试中通常用于模拟用户的行为,比如点击按钮、填写表单等,以便自动化执行测试用例。以下是一个使用Mechanize进行自动化测试的例子。
```python
import mechanize
import unittest
class TestMechanize(unittest.TestCase):
def setUp(self):
# 创建一个Mechanize浏览器实例
self.br = mechanize.Browser(factory=mechanize.RobustFactory())
self.br.open("***")
def test_login(self):
# 填写登录表单并提交
self.br.form['username'] = "testuser"
self.br.form['password'] = "testpass"
self.br.submit()
# 验证登录是否成功
self.assertIn("Welcome testuser", self.br.response().read())
if __name__ == "__main__":
unittest.main()
```
在这个测试用例中,我们首先创建了一个Mechanize的浏览器实例,并打开了登录页面。然后编写了一个`test_login`方法来模拟用户的登录过程。登录之后,我们检查响应内容是否包含"Welcome testuser",以验证登录是否成功。
**代码逻辑解读和参数说明:**
- `setUp` 方法是测试用例的初始化方法,在每个测试开始前执行,创建了一个Mechanize浏览器实例。
- `self.br.open("***")` 打开了登录页面。
- `self.br.form['username'] = "testuser"` 填写了用户名。
- `self.br.form['password'] = "testpass"` 填写了密码。
- `self.br.submit()` 提交了表单。
- `self.assertIn("Welcome testuser", self.br.response().read())` 检查响应内容是否包含预期的登录欢迎信息。
在实际的自动化测试中,Mechanize库还可以用来模拟复杂的用户交互流程,提高测试的覆盖率和效率。
## 3.3 Mechanize库在数据挖掘中的应用
### 3.3.1 数据的提取和清洗
Mechanize库可以帮助数据挖掘工程师快速提取网页中的数据,并进行初步的数据清洗。下面是一个简单的示例,展示了如何提取网页中的表格数据,并进行清洗。
```python
import mechanize
# 创建Mechanize浏览器实例
br = mechanize.Browser(factory=mechanize.RobustFactory())
# 打开目标网页
br.open("***")
# 选择页面中的第一个表格
table = br.select_form(nr=0)
# 提取表格中的数据
table_data = table.as_string()
# 数据清洗示例,将提取的数据转换为Python列表
import pandas as pd
data_frame = pd.read_html(table_data)[0]
# 输出清洗后的数据
print(data_frame)
```
在上面的代码中,我们通过Mechanize打开了一个包含表格数据的网页,并选择了页面中的第一个表格。然后,我们使用`pd.read_html`方法读取表格数据,将其转换为`pandas`的`DataFrame`对象,便于后续的数据分析和清洗。
**代码逻辑解读和参数说明:**
- `br.select_form(nr=0)` 选择页面中的第一个表格。Mechanize库可以处理页面中的表单数据。
- `table.as_string()` 将表格数据转换为字符串。
- `pd.read_html(table_data)[0]` 使用`pandas`库的`read_html`方法从字符串中读取表格数据,并选择第一个表格。
这个例子说明了Mechanize库如何与数据处理库`pandas`一起工作,来提取和清洗网页数据。数据清洗是数据挖掘的基础步骤,Mechanize的这种能力使得从网页到数据分析的过程变得更加顺畅。
# 4. Mechanize库在网络交互中的高级技巧
Mechanize库不仅仅是一个简单的网页自动化工具,它在模拟网络交互方面也具有强大的功能。本章节将深入探讨Mechanize在网络交互中的高级技巧,包括模拟登录、AJAX交互处理以及会话管理和cookie处理。
## 4.1 Mechanize库的模拟登录和表单处理
模拟登录是自动化测试和网络爬虫中常见的需求,Mechanize库提供了强大的支持来处理登录场景。
### 4.1.1 模拟登录的实现和优化
模拟登录是指模拟用户的行为输入用户名和密码,并提交登录表单。Mechanize库可以自动处理大部分登录场景中的CAPTCHA验证和cookies。
#### 模拟登录的实现
在Mechanize中,模拟登录通常涉及以下步骤:
1. 创建Mechanize对象。
2. 访问登录页面。
3. 填写登录表单。
4. 提交表单。
5. 检查是否登录成功。
以下是一个示例代码,展示如何使用Mechanize进行模拟登录:
```ruby
require 'mechanize'
agent = Mechanize.new
login_page = agent.get("***")
# 假设登录表单的action为 "/login",用户名字段的name为"username",密码字段的name为"password"
form = login_page.forms.first
# 填写用户名和密码
form["username"] = "your_username"
form["password"] = "your_password"
# 提交表单
agent.submit(form) do |page|
# 登录成功后的操作
end
```
#### 模拟登录的优化
模拟登录的成功率和效率往往可以通过一些优化手段得到提升。以下是一些优化策略:
- **存储和重用cookies**:Mechanize默认会存储cookies,如果登录成功,可以保存cookies并在下次请求时使用,以提高登录效率。
- **处理登录限制**:有些网站会对登录请求频率进行限制,Mechanize提供了等待(`agent.sleep(n)`)和重试机制(`agent.retry`)来应对。
- **异常处理**:登录过程中可能会遇到各种异常,比如输入验证失败等。Mechanize提供了异常处理机制,可以捕获这些异常并进行相应的处理。
### 4.1.2 表单数据的自动填充和验证
在自动化表单填写过程中,数据的自动填充和验证是非常重要的环节。Mechanize支持自动填充表单数据,并且可以通过验证机制确保数据的正确性。
#### 表单数据的自动填充
Mechanize库允许开发者通过编程方式自动填充表单数据。常见的数据源包括CSV文件、数据库或者动态生成的数据。例如,使用CSV文件填充:
```ruby
require 'csv'
require 'mechanize'
# 从CSV文件读取数据
CSV.foreach("user_data.csv", headers: true) do |row|
agent = Mechanize.new
form_page = agent.get("***")
form = form_page.forms.first
form["username"] = row["username"]
form["email"] = row["email"]
form["password"] = row["password"]
# 提交表单...
end
```
#### 表单数据的验证
数据验证可以确保提交的数据是有效且符合预期的。Mechanize不直接提供验证机制,但可以通过一些简单的策略来实现:
- **检查关键字段**:在表单提交前检查关键字段是否已被正确填写。
- **使用正则表达式匹配**:对于特定格式的字段,比如电子邮件或电话号码,可以使用正则表达式进行格式验证。
- **异常处理**:提交表单后,检查页面是否有错误提示或者页面是否跳转到了预期的地址,据此判断是否验证通过。
## 4.2 Mechanize库的AJAX交互处理
许多现代Web应用使用AJAX技术来提供动态内容。Mechanize库提供了捕获和处理AJAX请求的机制。
### 4.2.1 AJAX请求的捕获和处理
AJAX请求通常是异步的,Mechanize通过模拟浏览器行为来处理这些请求。
#### 捕获AJAX请求
Mechanize允许开发者捕获和处理AJAX请求,但需要一些额外的配置。例如,可以使用`Mechanize::Page#add_url_whitelist`来指定哪些URL应该被处理:
```ruby
agent = Mechanize.new
agent.add_url_whitelist(/https:\/\/***\/api.*/)
page = agent.get("***")
agent.click(page.at('a[href="***"]'))
```
#### 处理AJAX响应
处理AJAX响应需要解析响应数据。Mechanize可以将响应的内容作为HTML、JSON或XML进行解析。以JSON为例:
```ruby
require 'json'
agent.get("***") do |page|
json_data = JSON.parse(page.body)
# 分析和使用JSON数据...
end
```
### 4.2.2 动态内容的提取和分析
Mechanize可以处理动态加载的内容,但需要确定动态内容的加载机制,并进行相应的处理。
#### 动态内容的提取
动态内容通常是通过JavaScript在页面加载后异步加载的。Mechanize需要重新加载页面或触发相应的JavaScript事件来获取这些内容。例如,使用JavaScript触发器:
```ruby
page = agent.get("***")
agent.trigger(page.at('button#load-more'))
```
#### 动态内容的分析
获取动态内容后,需要对其进行分析。这可能涉及到提取特定数据点,或者根据数据做出进一步的决策。Mechanize没有内置的数据分析工具,但可以借助Ruby的其他库,如Nokogiri进行HTML解析,或者使用JSON解析库处理JSON数据。
## 4.3 Mechanize库的会话管理和cookie处理
会话管理和cookie处理对于模拟网络交互是至关重要的。Mechanize库提供了强大的会话和cookie管理功能。
### 4.3.1 会话的创建和管理
Mechanize通过跟踪cookie来管理会话状态,保证登录状态和浏览历史的持续性。
#### 创建和跟踪会话
Mechanize默认跟踪会话,并在多个页面请求之间保持cookie。这意味着一旦登录,后续的请求都将自动携带登录时的cookie信息,维持登录状态。
#### 会话管理策略
Mechanize允许开发者管理多个会话,这对于需要在同一应用中处理多个登录状态的情况非常有用。可以通过创建多个Mechanize实例来实现:
```ruby
agent1 = Mechanize.new
agent2 = Mechanize.new
# 分别进行不同的登录操作...
```
### 4.3.2 cookie的获取和使用
Mechanize允许开发者获取和使用cookie,这对于需要模拟特定浏览器行为的情况尤为重要。
#### 获取cookie
Mechanize存储了所有访问过的页面的cookie。可以通过Mechanize对象的`cookie_jar`方法获取cookie:
```ruby
cookies = agent.cookie_jar
puts cookies.to_a
```
#### 使用cookie
获取cookie后,可以根据需要使用这些cookie来访问受限制的内容。例如,手动设置cookie:
```ruby
agent.cookie_jar["***"]["session_id"] = "***"
```
Mechanize库的网络交互技巧为自动化测试、爬虫开发、数据挖掘等领域提供了强大的支持。通过模拟登录、处理AJAX交互、管理会话和cookie,Mechanize可以模拟大部分网络用户行为,使得自动化任务更加可靠和高效。
在本章节中,我们详细介绍了Mechanize库在网络交互中的高级技巧,包括模拟登录和表单处理、AJAX交互处理以及会话管理和cookie处理。这些技巧可以帮助开发者更有效地处理复杂的网络交互场景,提高自动化任务的效率和准确性。
# 5. Mechanize库的实战案例分析
## 5.1 Mechanize库在电商网站中的应用
### 5.1.1 商品信息的抓取和分析
在当今的电商时代,对商品信息的自动化抓取和分析是一个非常实用的场景。使用Mechanize库,我们可以快速地实现对电商网站商品信息的抓取。本节将介绍如何利用Mechanize库实现商品信息的自动化抓取,并且进行初步的数据分析。
首先,我们需要创建一个Mechanize实例,并且通过它访问目标电商网站。访问网站后,我们可以利用Mechanize提供的方法定位到特定的商品页面。一旦定位到页面,我们可以通过Mechanize的`search`方法或者其他DOM解析方法来提取出商品的名称、价格、库存状态、用户评价等信息。
```ruby
require 'mechanize'
agent = Mechanize.new
page = agent.get('***')
# 查找页面中的商品信息
products = page.search('.product-listing')
products.each do |product|
title = product.at('.title').text.strip
price = product.at('.price').text.strip
availability = product.at('.availability').text.strip
# 将获取到的数据存储或者进一步处理
puts "Product Title: #{title}, Price: #{price}, Availability: #{availability}"
end
```
在上述代码中,`.product-listing`、`.title`、`.price`、`.availability`是假定的CSS选择器,用于从商品列表中抓取所需信息。在实际应用中,这些选择器应根据目标网站的页面结构进行相应调整。
### 5.1.2 用户评论的提取和情感分析
电商网站上大量的用户评论信息是宝贵的数据资源。使用Mechanize抓取这些评论数据,并且通过情感分析技术来理解用户对商品的态度,对于电商企业来说具有重要的商业价值。
实现用户评论提取的一个基本方法是使用Mechanize解析目标页面上所有评论的HTML结构,并提取出每个评论的文本内容。下面的代码展示了如何使用Mechanize和Nokogiri库来提取评论信息。
```ruby
require 'mechanize'
require 'nokogiri'
agent = Mechanize.new
page = agent.get('***')
# 假设评论被包含在某个特定的CSS类中
comments = page.search('.comment-text')
comments.each do |comment|
text = comment.text.strip
# 将评论文本进行情感分析
sentiment = analyze_sentiment(text)
# 输出结果
puts "Comment: #{text}, Sentiment: #{sentiment}"
end
# 简单的情感分析函数示例
def analyze_sentiment(text)
# 这里应集成实际的情感分析算法或服务
# 情感分析是一个复杂的过程,这里仅为示例,返回结果为空
return nil
end
```
在这个过程中,`analyze_sentiment`函数应该是一个集成了复杂算法的函数,用于判断评论的情感倾向是积极的、消极的还是中立的。在实际应用中,你可能会使用专门的自然语言处理库或服务来完成这项任务,如TextBlob、VADER或者Azure Text Analytics API等。
通过上述的Mechanize应用,我们可以看到它不仅能够快速实现数据的抓取,还可以与其他技术结合,实现数据的深度分析和挖掘。这些例子展示了Mechanize库在电商领域的强大应用潜力,但它的应用远远不止于此。在下一节,我们将探讨Mechanize库在社交媒体应用中的实际案例。
# 6. Mechanize库的优化和扩展
在现代的网络爬虫和自动化任务中,Mechanize库已经成为一个不可或缺的工具。随着应用深度的增加,我们自然会遇到性能瓶颈和定制化需求。本章将重点讨论Mechanize库的性能优化策略以及如何进行扩展和定制开发。
## 6.1 Mechanize库的性能优化策略
随着项目规模的扩大,可能会出现资源消耗过快和执行速度下降等问题。优化性能是保持应用稳定运行的关键。
### 6.1.1 资源消耗的监控和优化
为了监控Mechanize库的资源消耗情况,可以使用各种工具进行分析。一个常用的工具是`memory_profiler`,它可以帮助我们跟踪Python代码的内存使用情况。
```python
# 安装memory_profiler
pip install memory_profiler
# 使用lprun来分析特定函数的内存消耗
lprun -f your_function your_script.py
```
使用该工具,我们可以对Mechanize执行的函数进行性能分析,从而找到内存消耗的瓶颈。
优化内存消耗通常涉及以下策略:
- 优化数据结构:使用更有效的数据结构来存储数据。
- 减少对象创建:避免在循环中创建大量的临时对象。
- 利用对象缓存:缓存重复使用的对象以避免重复创建。
### 6.1.2 代码的重构和性能提升
代码的重构是提高性能的有效手段,它不仅涉及代码结构的优化,还涉及算法的选择和实现。Mechanize库本身是基于Ruby的同名库进行的封装,因此在使用时要注意Ruby的调用开销。例如,对于重复的HTTP请求,可以考虑使用会话对象来维持连接。
```ruby
# 示例代码
require 'mechanize'
agent = Mechanize.new
agent.history.max = 1
page = agent.get("***") # 第一次访问
page = agent.get("***") # 第二次访问,使用了缓存的连接
```
对于更高级的优化,可以考虑使用`puppeteer`或`selenium`这样的JavaScript驱动,这些工具与浏览器更紧密集成,可以执行JavaScript代码,从而绕过Mechanize的一些限制。
## 6.2 Mechanize库的扩展和定制开发
Mechanize库提供了丰富的接口,但也存在局限性。在特定场景下,可能需要对库进行扩展或定制开发。
### 6.2.1 自定义Mechanize类的创建和使用
创建自定义的Mechanize类可以扩展其功能。比如,可以创建一个封装了登录逻辑的类,以便重复使用。
```ruby
# 自定义Mechanize类
require 'mechanize'
class CustomAgent < Mechanize
def login(username, password)
page = get('/login')
form = page.forms.first
form['username'] = username
form['password'] = password
submit_form(form)
end
end
agent = CustomAgent.new
agent.login('user', 'pass')
```
通过继承和重写Mechanize类,我们可以添加自定义的页面解析逻辑、异常处理策略等,使得Mechanize更加灵活和强大。
### 6.2.2 插件机制和社区贡献
Mechanize库支持插件机制,开发者可以根据自己的需求开发插件,并分享给社区,以增强库的功能。编写一个插件通常涉及几个步骤:
1. 创建一个插件类,该类继承自Mechanize的插件基类。
2. 实现`initialize`方法,并将Mechanize实例传递给插件基类。
3. 在插件类中定义需要扩展的方法。
4. 将插件注册到Mechanize实例中。
```ruby
# 示例代码
class MyPlugin < Mechanize::Plugin
def initialize(agent)
super
agent.add_plugin(self)
end
def get(url, &block)
# 自定义的GET请求逻辑
super
end
end
agent = Mechanize.new
agent.add_plugin(MyPlugin)
```
Mechanize社区非常活跃,贡献插件不仅能够帮助他人,也能促进个人技能的提升。通过访问Mechanize的官方文档和GitHub主页,我们可以找到社区共享的插件以及如何贡献自己的代码。
通过以上章节的介绍,我们已经全面了解了Mechanize库的基础、进阶应用,以及如何进行优化和扩展。Mechanize库的强大和灵活性使其在自动化测试、爬虫开发和数据挖掘等领域中发挥着重要作用。通过持续的优化和创新,Mechanize将继续支持IT从业者更好地完成他们的任务。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python Mechanize 库,一个功能强大的网络抓取和自动化工具。它涵盖了从基础到高级的各种主题,包括表单提交、会话管理、错误处理、网络数据处理和定制用户代理字符串。通过深入的教程、示例和技巧,本专栏旨在帮助开发人员充分利用 Mechanize 库,轻松应对复杂的网络交互,自动化测试流程,并有效处理网络数据。无论你是 Python 新手还是经验丰富的开发人员,本专栏都将为你提供宝贵的见解和实用的指南,帮助你提升你的网络自动化技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
httpie在自动化测试框架中的应用:提升测试效率与覆盖率

# 1. HTTPie简介与安装配置
## 1.1 HTTPie简介
HTTPie是一个用于命令行的HTTP客户端工具,它提供了一种简洁而直观的方式来发送HTTP请求。与传统的`curl`工具相比,HTTPie更易于使用,其输出也更加友好,使得开发者和测试工程师可以更加高效地进行API测试和调试。
## 1.2 安装
定制你的用户代理字符串:Mechanize库在Python中的高级使用

# 1. Mechanize库与用户代理字符串概述
## 1.1 用户代理字符串的定义和重要性
用户代理字符串(User-Agent String)是一段向服务器标识客户浏览器特性的文本信息,它包含了浏览器的类型、版本、操作系统等信息。这些信息使得服务器能够识别请
requests-html库进阶

# 1. requests-html库简介
在当今信息技术迅猛发展的时代,网络数据的抓取与分析已成为数据科学、网络监控以及自动化测试等领域不可或缺的一环。`requests-html`库应运而生,它是在Python著名的`requests`库基础上发展起来的,专为HTML内容解析和异步页面加载处理设计的工具包。该库允许用户方便地发送HTTP请求,解析HTML文档,并能够处理JavaScript
【django.utils.translation性能提升】:翻译效率的优化策略与技巧

# 1. django.utils.translation概述
django.utils.translation模块是Django框架中用于处理国际化(i18n)和本地化(l10n)的核心工具,它允许开发者将Web应
【lxml与数据库交互】:将XML数据无缝集成到数据库中

# 1. lxml库与XML数据解析基础
在当今的IT领域,数据处理是开发中的一个重要部分,尤其是在处理各种格式的数据文件时。XML(Extensible Markup Language)作为一种广泛使用的标记语言,其结构化数据在互联网上大量存在。对于数据科学家和开发人员来说,使用一种高效且功能强大的库来解析XML数据显得尤为重要。P
【Django模型字段测试策略】:专家分享如何编写高效模型字段测试用例

# 1. Django模型字段概述
## Django模型字段概述
Django作为一款流行的Python Web框架,其核心概念之一就是模型(Models)。模型代表数据库中的数据结构,而模型字段(Model Fields)则是这些数据结构的基石,它们定义了存储在数据库中每个字段的类型和行为。
简单来说,模型字段就像是数据库表中的列,它确定了数据的类型(如整数、字符串或日期
【App Engine微服务应用】:webapp.util模块在微服务架构中的角色
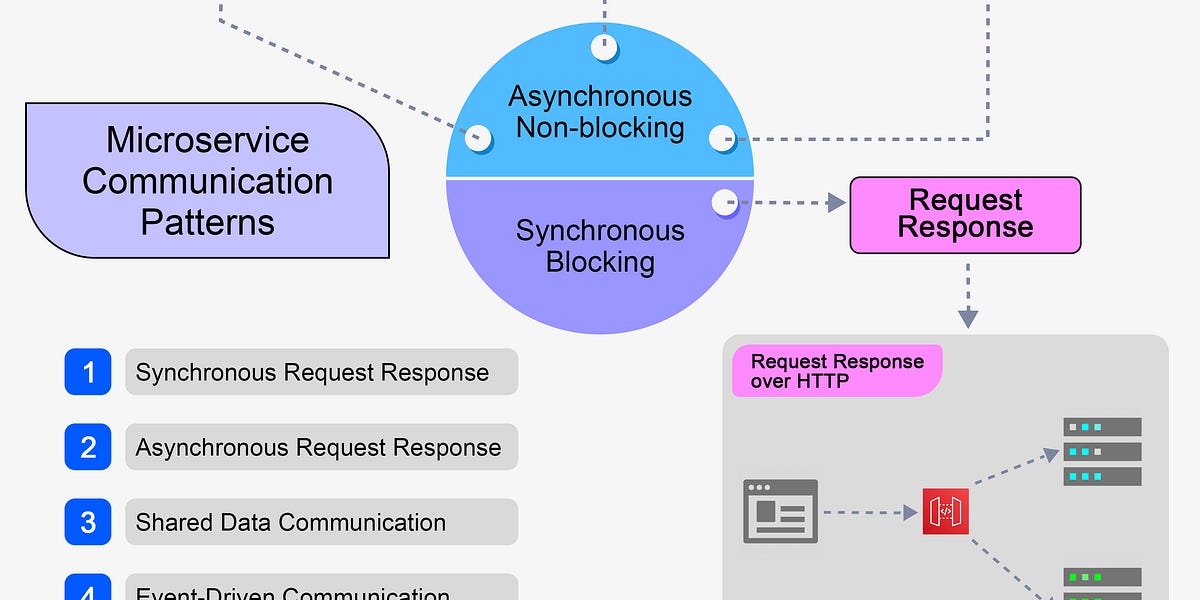
# 1. 微服务架构基础与App Engine概述
##
【feedparser教育应用】:在教育中培养学生信息技术的先进方法
# 1. feedparser技术概览及教育应用背景
## 1.1 feedparser技术简介
Feedparser是一款用于解析RSS和Atom feeds的Python库,它能够处理不同来源的订阅内容,并将其统一格式化。其强大的解析功能不仅支持多种语言编码,还能够处理各种数据异
【自动化测试报告生成】:使用Markdown提高Python测试文档的可读性

# 1. 自动化测试报告生成概述
在软件开发生命周期中,自动化测试报告是衡量软件质量的关键文档之一。它不仅记录了测试活动的详细过程,还能为开发者、测试人员、项目管理者提供重要的决策支持信息。随着软件复杂度的增加,自动化测试报告的作用愈发凸显,它能够快速、准确地提供测试结果,帮助团队成员对软件产品
【XPath高级应用】:在Python中用xml.etree实现高级查询

# 1. XPath与XML基础
XPath是一种在XML文档中查找信息的语言,它提供了一种灵活且强大的方式来选择XML文档中的节点或节点集。XML(Extensible Markup Language)是一种标记语言,用于存储和传输数据。为了在Python中有效地使用XPath,首先需要了解XML文档的结构和XPath的基本语法。
## 1
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )