Flowable 6.5工作流程简介与基本概念
发布时间: 2024-02-25 04:38:12 阅读量: 130 订阅数: 29 

dnSpy-net-win32-222.zip
# 1. Flowable 6.5概述
Flowable 6.5是一个轻量级的开源工作流引擎,具有强大的流程管理和自动化能力。本章将介绍关于Flowable 6.5的定义、特性、应用领域以及与其他工作流引擎的比较。
## 1.1 Flowable 6.5的定义与特性
Flowable 6.5是一个基于Java的开源工作流管理和自动化引擎,它提供了一套强大的工作流和业务流程管理工具,支持业务流程的建模、部署、执行和监控。Flowable 6.5具有以下特性:
- 简单易用的工作流程建模能力
- 强大的任务管理和执行功能
- 灵活的流程定义和部署机制
- 支持多种流程实例执行方式(同步、异步、定时)
- 可扩展的插件机制和REST API接口
- 数据持久化和历史记录功能
## 1.2 Flowable 6.5的应用领域
Flowable 6.5广泛应用于各种业务场景,包括但不限于:
- 企业内部流程管理和自动化
- 金融领域的审批流程和风险控制
- 医疗领域的病例管理和流程优化
- 电商领域的订单处理和售后服务
- 物流领域的配送路线规划和跟踪
## 1.3 Flowable 6.5与其他工作流引擎的比较
Flowable 6.5相对于其他工作流引擎在以下方面具有优势:
- 轻量级且易扩展:Flowable 6.5设计简洁,依赖少,易于集成和定制
- 高性能和稳定性:Flowable 6.5采用异步处理机制和可靠的事务管理,能够处理高并发场景
- 社区活跃和持续更新:Flowable社区活跃度高,更新迭代频繁,提供及时的技术支持和解决方案
通过对Flowable 6.5的概述,我们可以了解到其在工作流管理领域的优势和应用前景。接下来,我们将深入探讨Flowable 6.5的核心组件和工作流程概念。
# 2. Flowable 6.5的核心组件
Flowable 6.5作为一个强大的开源工作流引擎,拥有多个核心组件,这些组件在工作流程的建模、部署和执行中起着至关重要的作用。让我们逐一来了解这些核心组件:
### 2.1 Flowable Engine
Flowable Engine是Flowable的核心,负责处理流程的定义、流程实例的创建与管理、任务分配和执行等核心功能。它是整个工作流引擎的核心驱动力量。
```java
// 示例Java代码:使用Flowable Engine创建一个新的流程实例
ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();
RuntimeService runtimeService = processEngine.getRuntimeService();
Map<String, Object> variables = new HashMap<>();
variables.put("applicant", "John Doe");
variables.put("amount", 1000);
variables.put("loanType", "personal");
ProcessInstance processInstance = runtimeService.startProcessInstanceByKey("loanApproval", variables);
```
**代码总结:** 上述代码演示了如何使用Flowable Engine启动一个名为"loanApproval"的流程实例,并传入相应的变量参数。
**结果说明:** 流程实例成功启动,等待具体的任务执行。
### 2.2 Flowable Modeler
Flowable Modeler是Flowable提供的一个Web应用程序,用于方便用户进行工作流程的建模与设计。它提供了直观的图形界面,让用户可以轻松地设计流程图、定义流程变量等。
```javascript
// 示例JavaScript代码:使用Flowable Modeler创建一个简单的工作流程图
var canvas = elementRegistry.get('canvas');
var modeling = bpmnModeler.get('modeling');
modeling.createShape({ type: 'bpmn:Task', x: 100, y: 100, parent: canvas });
modeling.connect(shape1, targetShape, { type: 'bpmn:SequenceFlow' });
```
**代码总结:** 上述代码演示了使用Flowable Modeler创建一个简单的任务节点,并将其与另一个目标节点连接起来。
**结果说明:** 成功创建了一个简单的工作流程图。
### 2.3 Flowable Task
Flowable Task是负责处理流程中的任务分配和执行的组件。它允许用户对任务进行领取、执行、完成等操作,确保流程顺利进行。
```go
// 示例Go代码:处理Flowable Task中的用户任务
package main
import "fmt"
func main() {
taskId := "12345"
fmt.Println("领取任务:" + taskId)
// 执行任务相关操作
fmt.Println("完成任务:" + taskId)
}
```
**代码总结:** 以上Go代码展示了如何处理Flowable Task中的用户任务,包括领取和完成任务。
**结果说明:** 用户任务成功被领取并完成。
### 2.4 Flowable Form
Flowable Form允许用户定义和配置任务表单,以便在流程执行过程中收集和显示必要的数据。这为用户任务的处理提供了便利。
```python
# 示例Python代码:创建一个Flowable Form表单
form_fields = [("name", "string"), ("age", "integer"), ("email", "string")]
for field in form_fields:
print("Field Name: {}, Type: {}".format(field[0], field[1]))
```
**代码总结:** 上述Python代码展示了如何创建一个Flowable Form表单,并输出表单字段及其类型。
**结果说明:** 成功创建了包含姓名、年龄和邮箱字段的表单。
### 2.5 Flowable History
Flowable History负责记录流程实例的历史数据,包括流程实例的状态变更、任务执行记录、流程变量的更新等。用户可以通过Flowable History模块查看流程实例的完整执行历史。
```java
// 示例Java代码:查询并输出特定流程实例的历史数据
HistoryService historyService = processEngine.getHistoryService();
List<HistoricActivityInstance> activities = historyService.createHistoricActivityInstanceQuery()
.processInstanceId("processInstanceId")
.list();
for (HistoricActivityInstance activity : activities) {
System.out.println("Activity ID: " + activity.getActivityId()
+ ", Activity Name: " + activity.getActivityName());
}
```
**代码总结:** 上述Java代码演示了如何查询特定流程实例的历史活动数据,并输出活动的ID和名称。
**结果说明:** 成功查询并输出特定流程实例的历史活动数据。
### 2.6 Flowable Admin 和 Flowable REST API
Flowable Admin模块提供了对工作流引擎的监控和管理功能,用户可以通过Flowable Admin轻松管理流程实例、任务等。Flowable REST API则为用户提供了与Flowable引擎进行交互的RESTful API接口,方便集成和扩展。
总的来说,Flowable 6.5的核心组件为用户提供了全面的工作流引擎功能,让用户可以便捷地进行工作流程的建模、部署和执行。
# 3. Flowable 6.5的工作流程概念
Flowable 6.5是一个基于Java的轻量级工作流引擎,理解Flowable工作流程的基本概念对于开发人员和业务分析师来说是至关重要的。本章将介绍Flowable 6.5的工作流程概念,帮助读者更好地理解工作流的本质。
#### 3.1 什么是工作流程?
工作流程是指一系列相关联的任务、活动或事件,这些任务、活动或事件按照特定的规则和条件顺序执行,以完成特定的业务流程或业务目标。在Flowable中,工作流程通常以BPMN 2.0(Business Process Model and Notation)标准进行建模和设计。
#### 3.2 工作流程中的角色与职责
工作流程中通常涉及以下几类角色:
- 流程发起者(Process Initiator): 初始化工作流程实例的人员或系统。
- 任务执行者(Task Performer): 负责执行工作流程中的具体任务或活动的人员或系统。
- 管理员(Administrator): 负责管理工作流程定义、实例、任务分配、监控和优化等工作。
#### 3.3 流程定义与流程实例
流程定义是指对工作流程进行静态的、静态的概念性描述,包括各个节点、顺序流、条件判断等元素的模型。而流程实例则是指具体执行中的工作流程,它是根据流程定义创建的一个个体化的流程执行过程。
#### 3.4 任务与子任务
在工作流程中,任务是工作流程的基本执行单元,代表工作流程实例中的一个待办活动。子任务则是任务的一种特殊形式,可以由父任务派生出来,通常用于解决一个大任务拆分成多个小任务的情况。
#### 3.5 事件驱动的工作流程
Flowable支持事件驱动的工作流程,即工作流程的执行可以由外部事件触发。这种工作流程常用于异步消息处理、状态变化通知等场景,能够更加灵活地适应业务需求的变化。
通过本章的学习,读者将对工作流程的基本概念有一个清晰的认识,为后续的工作流程建模与设计打下坚实的基础。
# 4. Flowable 6.5的流程建模与设计
在Flowable 6.5中,流程建模与设计是工作流程开发的核心环节。通过Flowable Modeler等工具,开发人员可以直观地设计出流程模型,定义工作流程的各项逻辑和流程控制。本章将深入探讨Flowable 6.5中的流程建模与设计相关内容。
### 4.1 使用Flowable Modeler进行工作流程建模
Flowable Modeler是一个基于web的流程建模工具,提供了可视化的流程设计界面,开发人员可以通过拖拽和连接各个元素来构建工作流程模型。以下是一个简单的示例代码,演示如何通过Flowable Modeler进行流程建模:
```python
from flowable import Modeler
modeler = Modeler()
modeler.create_process_model()
modeler.add_user_task("task1", "Task 1")
modeler.add_sequence_flow("start", "task1")
modeler.add_end_event("end")
modeler.save_model("my_first_process")
```
### 4.2 流程图的基本元素
在Flowable 6.5的流程图中,包括流程定义、任务、网关、事件、边界事件等基本元素。每个元素都具有特定的用途和含义,开发人员需要根据业务需求来合理搭建这些元素,构建完整的工作流程模型。
### 4.3 设计者视角下的流程定义
在设计工作流程时,需要站在设计者的角度,考虑流程的整体逻辑和流程控制。流程定义需要清晰明了,各环节之间的关系和转移条件需要合理设定,以确保流程的正确执行。
### 4.4 流程变量与条件设定
Flowable 6.5允许在流程中定义和使用流程变量,开发人员可以通过流程变量来传递数据、控制流程逻辑。同时,条件设定也是流程设计中重要的一环,通过条件判断可以实现分支处理和流程控制。
### 4.5 子流程与多实例任务
在复杂的工作流程中,可能会涉及到子流程和多实例任务的设计。Flowable 6.5提供了方便的方式来管理子流程和多实例任务,让工作流程更加灵活和高效。
通过本章内容的学习,读者将能够深入了解Flowable 6.5中流程建模与设计相关的知识,为工作流程开发提供指导和帮助。
# 5. Flowable 6.5的工作流程部署与执行
在Flowable 6.5中,工作流程的部署与执行是非常关键的环节,下面我们将详细介绍如何进行工作流程的部署和执行。
#### 5.1 部署工作流程定义
在Flowable中,工作流程的定义通常使用BPMN 2.0(Business Process Model and Notation)标准进行建模。通过Flowable Modeler进行流程建模后,可以将流程定义部署到Flowable引擎中进行执行。下面是一个Java代码示例,演示如何部署工作流程定义:
```java
RepositoryService repositoryService = processEngine.getRepositoryService();
// 加载流程定义文件
ClassPathResource resource = new ClassPathResource("my-process.bpmn");
repositoryService.createDeployment()
.addInputStream("my-process.bpmn", resource.getInputStream())
.deploy();
```
通过以上代码,我们可以将名为"my-process.bpmn"的流程定义文件部署到Flowable引擎中。
#### 5.2 启动与执行工作流程实例
一旦流程定义被成功部署,我们可以通过以下Java代码启动一个流程实例并执行该流程:
```java
RuntimeService runtimeService = processEngine.getRuntimeService();
// 启动流程实例
runtimeService.startProcessInstanceByKey("myProcess");
// 查询当前运行的流程实例
List<ProcessInstance> processInstances = runtimeService.createProcessInstanceQuery().list();
```
通过上述代码,我们成功地启动了名为"myProcess"的流程实例,并可以对流程实例进行查询和监控。
#### 5.3 用户任务的处理与参与
在工作流程中,用户任务是流程中一个至关重要的环节,需要用户来完成。下面是一个Java代码示例,演示如何完成用户任务:
```java
TaskService taskService = processEngine.getTaskService();
// 查询当前待办任务
List<Task> tasks = taskService.createTaskQuery().taskCandidateGroup("managers").list();
// 完成任务
for (Task task : tasks) {
taskService.complete(task.getId());
}
```
通过以上代码,我们可以查询并完成名为"managers"组中的待办任务。
#### 5.4 事件触发与流程监听
Flowable允许开发人员在流程的特定节点监听事件,并触发相应的逻辑。下面是一个Java代码示例,演示如何添加一个流程监听器:
```java
List<EventSubscription> eventSubscriptions = runtimeService.createEventSubscriptionQuery()
.eventType("myEvent")
.list();
for (EventSubscription eventSubscription : eventSubscriptions) {
runtimeService.messageEventReceived(eventSubscription.getEventName(), eventSubscription.getExecutionId());
}
```
通过以上代码,我们可以监听名为"myEvent"的事件,并触发相应的流程逻辑。
#### 5.5 错误处理与流程回滚
在实际应用中,工作流程可能会出现各种异常情况,需要进行错误处理和流程回滚。下面是一个Java代码示例,演示如何捕获异常并回滚流程:
```java
try {
// 执行流程逻辑
} catch (Exception e) {
runtimeService.deleteProcessInstance(processInstanceId, "Flow rolled back due to error: " + e.getMessage());
}
```
通过以上代码,我们可以根据具体异常情况,捕获错误并回滚流程。
以上就是Flowable 6.5的工作流程部署与执行的基本概念和代码示例。在实际应用中,开发人员可以根据具体业务需求进行定制化的流程部署与执行操作。
# 6. Flowable 6.5的性能优化与扩展
在实际应用中,为了提高Flowable 6.5的性能以及满足特定需求,我们可以进行一些优化和扩展操作。以下是一些常见的性能优化与扩展方法:
### 6.1 数据库选型与优化
在使用Flowable时,可以针对不同的业务场景选择合适的数据库类型,并对数据库进行优化,例如优化SQL查询语句、创建适当的索引等,以提高系统的性能和响应速度。
```java
// 示例:创建索引以优化查询
CREATE INDEX index_name ON table_name(column_name);
```
**总结:** 数据库选型与优化对于提高Flowable系统的性能至关重要,通过一些简单的优化手段可以显著改善系统的性能。
### 6.2 集群部署与负载均衡
当流程实例数量较大时,可以考虑将Flowable引擎部署在集群环境中,并配置负载均衡策略,以提高系统的并发处理能力和可用性。
```java
// 示例:使用Nginx进行负载均衡配置
upstream flowable_servers {
server 127.0.0.1:8080;
server 127.0.0.1:8081;
server 127.0.0.1:8082;
}
server {
listen 80;
server_name flowable.example.com;
location / {
proxy_pass http://flowable_servers;
}
}
```
**总结:** 集群部署和负载均衡可以有效提升Flowable系统的处理能力和容错能力,保障系统的稳定性。
### 6.3 异步任务处理与队列管理
通过将一些耗时操作异步化处理,如邮件通知、文件处理等,可以提高系统的响应速度和并发能力。同时,合理配置消息队列,如使用RabbitMQ、Kafka等,可以提升系统的性能和稳定性。
```java
// 示例:使用RabbitMQ处理异步任务
@Component
public class RabbitMQConsumer {
@RabbitListener(queues = "flowable-queue")
public void processMessage(String message) {
// 处理消息
}
}
```
**总结:** 异步任务处理和队列管理可以有效减少系统的响应时间,提高系统整体的处理能力和稳定性。
### 6.4 定制化流程引擎
根据业务需求,可以通过定制化流程引擎,如编写自定义的Delegate、Listener等,扩展Flowable 6.5的功能,以适应特定的业务场景。
```java
// 示例:自定义TaskListener
public class CustomTaskListener implements TaskListener {
@Override
public void notify(DelegateTask delegateTask) {
// 自定义任务处理逻辑
}
}
```
**总结:** 定制化流程引擎可以使Flowable系统更加灵活,满足各种复杂业务需求,提升系统的适用性和扩展性。
### 6.5 与现有系统集成和扩展
通过与现有系统集成,如CRM、ERP系统等,可以实现业务流程的无缝对接,并且可以通过扩展Flowable提供的REST API接口,与其他系统进行数据交互和集成。
```java
// 示例:使用Flowable REST API进行系统集成
@GetMapping("/startProcess")
public ResponseEntity<Void> startProcess() {
// 调用Flowable REST API启动流程实例
return ResponseEntity.ok().build();
}
```
**总结:** 通过与现有系统集成和扩展,可以实现业务流程的全面管控和管理,提高系统的整体效率和协作能力。
以上是关于Flowable 6.5性能优化与扩展的一些方法和建议,希

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入解析Flowable 6.5版本的各种新特性,涵盖了从快速入门指南到高级功能使用的多个主题。文章内容涉及Flowable 6.5的各种方面,包括组任务和任务委派、消息事件与信号事件、REST API的使用指南、多租户部署与管理、流程监控与性能调优、事件监听器与拦截器、表单引擎与自定义表单、表达式语言与条件判断以及脚本任务与脚本引擎集成等多个方面。通过本专栏,读者将能够全面了解Flowable 6.5版本的各项新特性,并掌握其在实际项目中的应用技巧,为工作中的流程管理和性能优化提供有力支持。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
算法到硬件的无缝转换:实现4除4加减交替法逻辑的实战指南
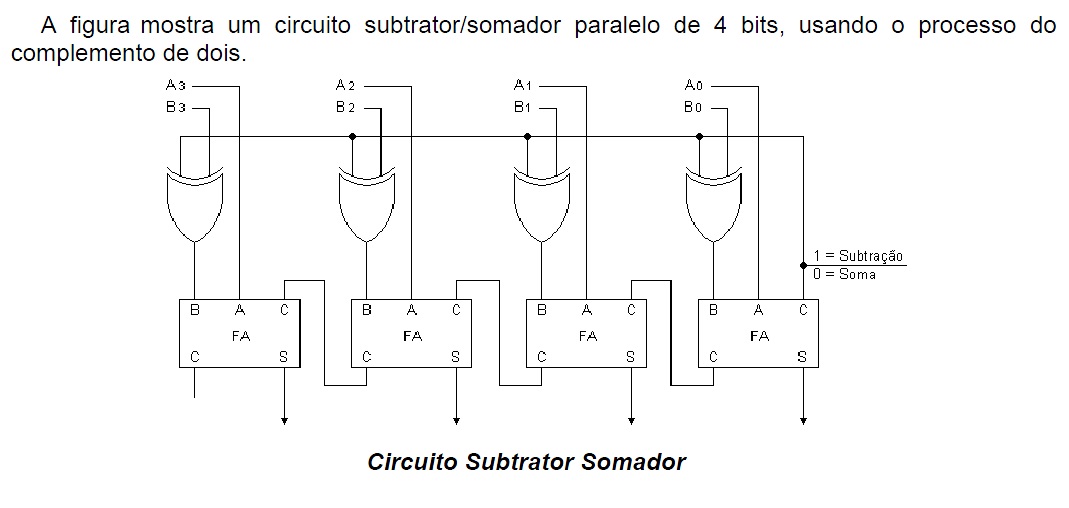
# 摘要
本文旨在介绍一种新颖的4除4加减交替法,探讨了其基本概念、原理及算法设计,并分析了其理论基础、硬件实现和仿真设计。文章详细阐述了算法的逻辑结构、效率评估与优化策略,并通过硬件描述语言(HDL)实现了算法的硬件设计与仿真测试。此外,本文还探讨了硬件实现与集成的过程,包括FPGA的开发流程、逻辑综合与布局布线,以及实际硬件测试。最后,文章对算法优化与性能调优进行了深入分析,并通过实际案例研究,展望了算法与硬件技术未来的发
【升级攻略】:Oracle 11gR2客户端从32位迁移到64位,完全指南

# 摘要
随着信息技术的快速发展,企业对于数据库系统的高效迁移与优化要求越来越高。本文详细介绍了Oracle 11gR2客户端从旧系统向新环境迁移的全过程,包括迁移前的准备工作、安装与配置步骤、兼容性问题处理以及迁移后的优化与维护。通过对系统兼容性评估、数据备份恢复策略、环境变量设置、安装过程中的问题解决、网络
【数据可视化】:煤炭价格历史数据图表的秘密揭示

# 摘要
数据可视化是将复杂数据以图形化形式展现,便于分析和理解的一种技术。本文首先探讨数据可视化的理论基础,再聚焦于煤炭价格数据的可视化实践,
FSIM优化策略:精确与效率的双重奏

# 摘要
本文详细探讨了FSIM(Feature Similarity Index Method)优化策略,旨在提高图像质量评估的准确度和效率。首先,对FSIM算法的基本原理和理论基础进行了分析,然后针对算法的关键参数和局限性进行了详细讨论。在此基础上,提出了一系列提高FSIM算法精确度的改进方法,并通过案例分析评估
IP5306 I2C异步消息处理:应对挑战与策略全解析

# 摘要
本文系统介绍了I2C协议的基础知识和异步消息处理机制,重点分析了IP5306芯片特性及其在I2C接口下的应用。通过对IP5306芯片的技术规格、I2C通信原理及异步消息处理的特点与优势的深入探讨,本文揭示了在硬件设计和软件层面优化异步消息处理的实践策略,并提出了实时性问题、错误处理以及资源竞争等挑战的解决方案。最后,文章
DBF到Oracle迁移高级技巧:提升转换效率的关键策略

# 摘要
本文探讨了从DBF到Oracle数据库的迁移过程中的基础理论和面临的挑战。文章首先详细介绍了迁移前期的准备工作,包括对DBF数据库结构的分析、Oracle目标架构的设计,以及选择适当的迁移工具和策略规划。接着,文章深入讨论了迁移过程中的关键技术和策略,如数据转换和清洗、高效数据迁移的实现方法、以及索引和约束的迁移。在迁移完成后,文章强调了数据验证与性能调优的重要性,并通过案例分析,分享了不同行业数据迁移的经
【VC709原理图解读】:时钟管理与分布策略的终极指南(硬件设计必备)
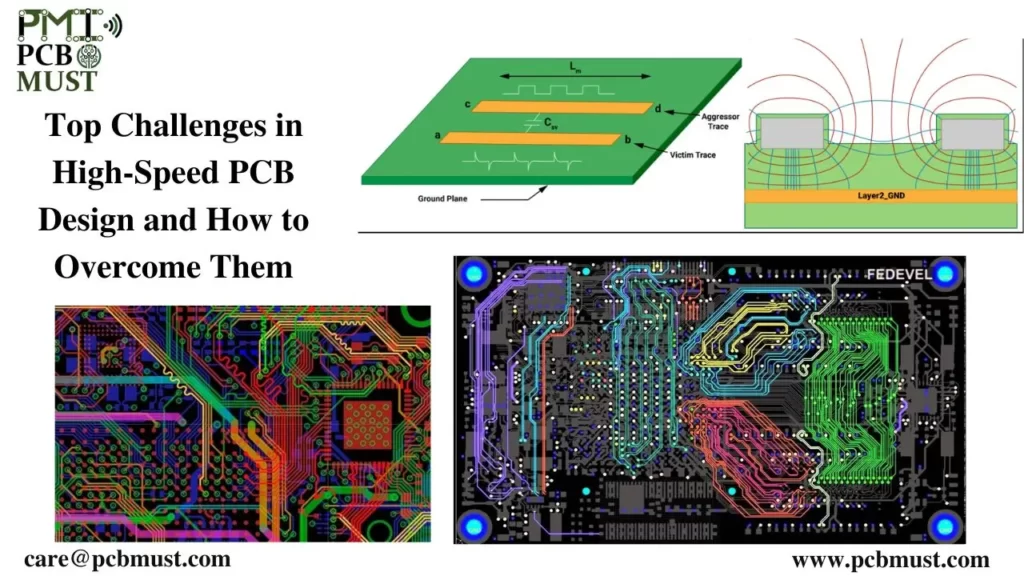
# 摘要
本文详细介绍了VC709硬件的特性及其在时钟管理方面的应用。首先对VC709硬件进行了概述,接着探讨了时钟信号的来源、路径以及时钟树的设计原则。进一步,文章深入分析了时钟分布网络的设计、时钟抖动和偏斜的控制方法,以及时钟管理芯片的应用。实战应用案例部分提供了针对硬件设计和故障诊断的实际策略,强调了性能优化
IEC 60068-2-31标准应用:新产品的开发与耐久性设计
# 摘要
IEC 60068-2-31标准是指导电子产品环境应力筛选的国际规范,本文对其概述和重要性进行了详细讨论,并深入解析了标准的理论框架。文章探讨了环境应力筛选的不同分类和应用,以及耐久性设计的实践方法,强调了理论与实践相结合的重要性。同时,本文还介绍了新产品的开发流程,重点在于质量控制和环境适应性设计。通过对标准应用案例的研究,分析了不同行业如何应用环境应力筛选和耐久性设计,以及当前面临的新技术挑战和未来趋势。本文为相关领域的工程实践和标准应用提供了有价值的参考。
# 关键字
IEC 60068-2-31标准;环境应力筛选;耐久性设计;环境适应性;质量控制;案例研究
参考资源链接:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )