深度学习基础概述
发布时间: 2024-01-31 02:47:17 阅读量: 41 订阅数: 45 

深度学习基础
# 1. 深度学习简介
## 1.1 深度学习的定义
深度学习是一种基于人工神经网络模型的机器学习方法,其目标是通过模拟人脑神经元之间的连接和信息传递,实现对大规模数据进行自动学习和分析的能力。深度学习的主要特点是具备多层神经网络结构,能够从原始数据中提取高级抽象特征,并具备逐层学习的能力。
深度学习通过反向传播算法来不断调整神经网络中的参数,使得网络能够根据输入和期望输出之间的误差进行学习和优化。由于深度学习在处理大规模数据和复杂问题上具备出色的性能,因此在许多领域都取得了重要的突破。
## 1.2 深度学习的历史发展
深度学习的概念最早可以追溯到20世纪40年代,当时人们通过构建多层感知机(Multilayer Perceptron)来模拟神经网络的工作原理。然而,由于当时计算能力的限制以及缺乏大规模数据集,深度学习在理论与实践上未能取得突破性进展。
直到2006年,Hinton等人提出了一种被称为深度信念网络(Deep Belief Network,DBN)的模型,为深度学习的发展带来了重要的推动。随后,随着图形处理器(GPU)计算能力的提升以及大规模数据集的产生,深度学习开始迅速发展。
2012年,深度学习在计算机视觉领域取得了重大突破。由Deep Learning旗下的研究团队设计的深度卷积神经网络(Convolutional Neural Network,CNN)在ImageNet比赛中击败了传统的机器学习方法,引起了广泛关注。
## 1.3 深度学习在人工智能领域的应用
深度学习在人工智能领域具有广泛应用,涉及计算机视觉、语音识别、自然语言处理等多个领域。以下是深度学习在一些应用场景中的应用示例:
- **计算机视觉:** 在图像分类、目标检测、图像生成等任务中,深度学习方法可以从原始图像中提取高级特征,并实现准确的图像分析和理解。
- **语音识别:** 深度学习方法在语音识别中具有出色的性能,可以将语音信号转换成文本或命令,广泛应用于语音助手、智能音箱等设备中。
- **自然语言处理:** 在文本分类、命名实体识别、机器翻译等任务中,深度学习方法可以实现对文本信息的理解和分析,提高自然语言处理的精度和效果。
深度学习通过其强大的学习能力和表达能力,正在改变着人工智能领域的发展路径,为解决复杂问题和提高人工智能应用的性能提供了新的可能性。
# 2. 神经网络基础
### 2.1 人工神经元的概念
人工神经元是深度学习中的基本组成单元,模拟了生物神经元的工作原理。每个人工神经元接收输入信号,通过激活函数对输入信号进行加权求和并产生输出结果。人工神经元的输出可以作为其他神经元的输入,从而构成了神经网络的结构。
在深度学习中,常用的激活函数包括sigmoid函数、ReLU函数等,它们能够将输入信号映射到一个非线性的输出值,提供了神经网络进行复杂模式学习的能力。
```python
# Python代码示例:定义一个人工神经元的类
import numpy as np
class Neuron:
def __init__(self, weights, bias, activation_function):
self.weights = weights
self.bias = bias
self.activation_function = activation_function
def activate(self, inputs):
# 对输入信号进行加权求和
z = np.dot(self.weights, inputs) + self.bias
# 使用激活函数对加权求和结果进行映射
output = self.activation_function(z)
return output
# 创建一个sigmoid激活函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 定义人工神经元的权重、偏置和激活函数
weights = np.array([0.5, 0.8, -0.3])
bias = 0.2
activation_function = sigmoid
# 创建一个人工神经元对象
neuron = Neuron(weights, bias, activation_function)
# 输入信号
inputs = np.array([0.2, 0.4, 0.1])
# 激活人工神经元并输出结果
output = neuron.activate(inputs)
print("输出结果:", output)
```
**代码解释:**
首先定义了一个`Neuron`类,该类表示一个人工神经元。在类的实例化过程中,需要传入神经元的权重、偏置和激活函数作为参数。
`activate`方法实现了人工神经元的激活过程,将输入信号进行加权求和,并通过激活函数进行映射得到输出结果。
通过定义一个sigmoid函数作为激活函数,并给定输入信号,可以得到人工神经元的输出结果。
### 2.2 前馈神经网络
前馈神经网络(Feedforward Neural Network)是一种常见的神经网络模型,其中神经元按层次结构排列,信号单向传播,不会出现回路,也不会存在反馈。
前馈神经网络由输入层、隐藏层和输出层组成。输入层接受外部输入信号,隐藏层通过一系列的人工神经元对输入信号进行处理,最终输出层产生网络的最终输出。
下面是一个简单的前馈神经网络示例代码:
```java
// Java代码示例:定义一个前馈神经网络的类
public class FeedforwardNeuralNetwork {
private int inputSize;
private int hiddenSize;
private int outputSize;
private double[][] weights1;
private double[][] weights2;
public FeedforwardNeuralNetwork(int inputSize, int hiddenSize, int outputSize) {
this.inputSize = inputSize;
this.hiddenSize = hiddenSize;
this.outputSize = outputSize;
this.weights1 = new double[inputSize][hiddenSize];
this.weights2 = new double[hiddenSize][outputSize];
// 初始化权重
initializeWeights();
}
private void initializeWeights() {
// 权重初始化逻辑
// ...
}
public double[] predict(double[] inputs) {
double[] hiddenOutputs = new double[hiddenSize];
// 计算隐藏层输出
// ...
double[] outputs = new double[outputSize];
// 计算输出层输出
// ...
return outputs;
}
}
// 创建一个前馈神经网络对象
FeedforwardNeuralNetwork neuralNetwork = new FeedforwardNeuralNetwork(4, 5, 3);
double[] inputs = {0.2, 0.4, 0.1, 0.8};
double[] outputs = neuralNetwork.predict(inputs);
System.out.println("输出结果: " + Arrays.toString(outputs));
```
**代码解释:**
在上述代码中,首先定义了一个`FeedforwardNeuralNetwork`类,该类表示一个前馈神经网络。在类的实例化过程中,需要指定输入层大小、隐藏层大小和输出层大小。
`initializeWeights`方法用于初始化网络的权重,可以根据具体的需求选择合适的初始化方法。
`predict`方法用于根据给定的输入信号计算出前馈神经网络的输出结果。
通过创建一个前馈神经网络对象并给定输入信号,可以得到网络的输出结果。
### 2.3 反向传播算法
反向传播算法是用于训练神经网络的一种常用方法。它通过不断调整网络的权重和偏置来最小化网络的输出与真实值之间的误差。
反向传播算法利用梯度下降的方法来更新网络的参数。具体来说,它通过计算损失函数对权重和偏置的梯度,并根据梯度的方向和大小来更新参数,使得损失函数逐渐减小。
下面是一个简单的反向传播算法示例代码:
```python
# Python代码示例:反向传播算法的实现
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
class NeuralNetwork:
def __init__(self, input_size, hidden_size, output_size):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.weights1 = np.random.rand(hidden_size, input_size)
self.weights2 = np.random.rand(output_size, hidden_size)
self.bias1 = np.random.rand(hidden_size, 1)
self.bias2 = np.random.rand(output_size, 1)
def predict(self, inputs):
# 前向传播过程
hidden_outputs = sigmoid(np.dot(self.weights1, inputs) + self.bias1)
outputs = sigmoid(np.dot(self.weights2, hidden_outputs) + self.bias2)
return outputs
def train(self, inputs, labels, learning_rate, epochs):
for epoch in range(epochs):
# 前向传播
hidden_outputs = sigmoid(np.dot(self.weights1, inputs) + self.bias1)
outputs = sigmoid(np.dot(self.weights2, hidden_outputs) + self.bias2)
# 反向传播
error = labels - outputs
delta2 = error * sigmoid_derivative(outputs)
delta1 = np.dot(self.weights2.T, delta2) * sigmoid_derivative(hidden_outputs)
# 更新权重和偏置
self.weights2 += learning_rate * np.dot(delta2, hidden_outputs.T)
self.weights1 += learning_rate * np.dot(delta1, inputs.T)
self.bias2 += learning_rate * delta2
self.bias1 += learning_rate * delta1
# 创建一个神经网络对象
neural_network = NeuralNetwork(4, 5, 3)
# 输入信号和标签
inputs = np.array([[0.2], [0.4], [0.1], [0.8]])
labels = np.array([[0.5], [0.2], [0.8]])
# 训练神经网络
learning_rate = 0.1
epochs = 1000
neural_network.train(inputs, labels, learning_rate, epochs)
# 预测结果
outputs = neural_network.predict(inputs)
print("输出结果:")
print(outputs)
```
**代码解释:**
在上述代码中,首先定义了一个`NeuralNetwork`类,该类表示一个神经网络。在类的实例化过程中,需要指定输入层大小、隐藏层大小和输出层大小。
`predict`方法用于根据给定的输入信号计算出神经网络的输出结果。
`train`方法用于训练神经网络。在训练过程中,首先进行前向传播计算得到输出结果,然后通过反向传播计算各层的梯度,并根据梯度的大小和方向来更新权重和偏置。
通过创建一个神经网络对象并给定输入信号和标签,可以使用训练数据训练神经网络,并得到网络的输出结果。
# 3. 深度学习的核心概念
深度学习的核心概念包括卷积神经网络(CNN)、递归神经网络(RNN)和长短时记忆网络(LSTM)。这些概念是深度学习领域中最重要的模型之一,被广泛应用于图像识别、自然语言处理等领域。
#### 3.1 卷积神经网络(CNN)
卷积神经网络是一种专门用于处理图像数据的深度学习模型。它通过卷积层、池化层和全连接层构成,能够有效地提取图像特征并进行分类识别。以下是一个简单的使用TensorFlow实现的卷积神经网络的示例代码:
```python
import tensorflow as tf
# 构建卷积神经网络模型
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax)
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=5)
```
通过上述代码,我们可以看到如何使用TensorFlow构建一个简单的卷积神经网络模型,并且进行模型的编译和训练。
#### 3.2 递归神经网络(RNN)
递归神经网络是一种专门用于处理序列数据的深度学习模型。它具有记忆功能,能够对序列数据进行建模,并进行预测。以下是一个简单的使用Keras实现的递归神经网络的示例代码:
```python
import numpy as np
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense
# 构建递归神经网络模型
model = Sequential()
model.add(SimpleRNN(units=32, input_shape=(None, 100)))
model.add(Dense(10, activation='softmax'))
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 生成模拟数据
data = np.random.random((1000, 10, 100))
labels = np.random.random((1000, 10))
# 训练模型
model.fit(data, labels, epochs=10, batch_size=32)
```
通过上述代码,我们可以看到如何使用Keras构建一个简单的递归神经网络模型,并进行模型的编译和训练。
#### 3.3 长短时记忆网络(LSTM)
长短时记忆网络是一种特殊的递归神经网络,它在处理长序列数据时能够有效地避免梯度消失或梯度爆炸的问题,能够更好地捕捉序列数据中的长期依赖关系。以下是一个简单的使用PyTorch实现的长短时记忆网络的示例代码:
```python
import torch
import torch.nn as nn
# 构建长短时记忆网络模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, input):
output, _ = self.lstm(input)
output = self.fc(output[-1, :, :])
return output
# 创建模型实例
input_size = 10
hidden_size = 20
output_size = 5
model = LSTMModel(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(100):
# 此处省略数据准备和训练过程
# ...
```
通过上述代码,我们可以看到如何使用PyTorch构建一个简单的长短时记忆网络模型,并进行模型的训练。
以上便是深度学习核心概念的介绍及代码示例。在实际应用中,根据任务需求选择合适的深度学习模型至关重要。接下来,我们将继续探讨深度学习的常见模型及其应用场景。
# 4. 深度学习的常见模型
深度学习是一种强大的机器学习方法,可以通过多层非线性模型来表示高级抽象。在深度学习中,有许多常见的模型被广泛应用于各种领域。
#### 4.1 深度信念网络(DBN)
深度信念网络是一种多层神经网络模型,通常由若干层受限玻尔兹曼机(RBM)组成。它的训练过程分为无监督预训练和有监督微调两个阶段,常用于特征提取和数据降维。
以下是Python中使用TensorFlow实现深度信念网络的示例代码:
```python
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 导入数据集
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 定义模型
input_units = 784
hidden1_units = 500
hidden2_units = 300
x = tf.placeholder(tf.float32, [None, input_units])
W1 = tf.Variable(tf.truncated_normal([input_units, hidden1_units], stddev=0.1))
b1 = tf.Variable(tf.constant(0.1, shape=[hidden1_units]))
h1 = tf.nn.sigmoid(tf.matmul(x, W1) + b1)
W2 = tf.Variable(tf.truncated_normal([hidden1_units, hidden2_units], stddev=0.1))
b2 = tf.Variable(tf.constant(0.1, shape=[hidden2_units]))
h2 = tf.nn.sigmoid(tf.matmul(h1, W2) + b2)
W3 = tf.Variable(tf.zeros([hidden2_units, 10]))
b3 = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(h2, W3) + b3)
# 定义损失函数和优化算法
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# 训练模型
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# 评估模型
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
```
在该示例中,我们通过TensorFlow构建了一个两层的深度信念网络,并使用MNIST手写数字数据集进行训练和测试。
#### 4.2 生成对抗网络(GAN)
生成对抗网络是由两个模型组成的对抗性系统,一个生成器模型和一个判别器模型。生成器模型用于生成与真实样本相似的数据,而判别器模型则用于区分生成的数据与真实数据。
以下是Python中使用Keras实现生成对抗网络的示例代码:
```python
from keras.models import Sequential
from keras.layers import Dense, LeakyReLU
from keras.optimizers import Adam
# 生成器模型
generator = Sequential([
Dense(128, input_dim=100),
LeakyReLU(0.2),
Dense(784, activation='tanh')
])
# 判别器模型
discriminator = Sequential([
Dense(128, input_dim=784),
LeakyReLU(0.2),
Dense(1, activation='sigmoid')
])
# 定义GAN模型
from keras.models import Model
from keras.layers import Input
z = Input(shape=(100,))
img = generator(z)
validity = discriminator(img)
gan = Model(z, validity)
gan.compile(loss='binary_crossentropy', optimizer=Adam(0.0002, 0.5))
# 训练GAN模型
# 略去训练过程的代码
```
在上述示例中,我们使用Keras构建了一个简单的生成对抗网络模型,并使用Adam优化器进行编译。由于生成对抗网络的训练过程较为复杂,此处略去了训练过程的代码。
#### 4.3 强化学习
强化学习是一种通过智能体与环境的交互来学习最优行为策略的机器学习方法。在深度学习中,强化学习被广泛应用于各种任务,如游戏玩法、机器人控制等领域。
以下是Python中使用强化学习库Gym和Keras实现强化学习的示例代码:
```python
import gym
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
env = gym.make('CartPole-v1')
observation_space = env.observation_space.shape[0]
action_space = env.action_space.n
model = Sequential([
Dense(24, input_dim=observation_space, activation='relu'),
Dense(24, activation='relu'),
Dense(action_space, activation='linear')
])
model.compile(loss='mse', optimizer='adam')
# 训练强化学习模型
# 略去训练过程的代码
```
在上述示例中,我们使用Gym创建了一个CartPole的环境,并通过Keras构建了一个简单的神经网络模型来进行强化学习训练。
以上便是深度学习常见模型的简要介绍以及使用Python语言实现的示例代码。这些模型在不同的领域都有广泛的应用,对于深度学习的进一步学习和探索具有重要意义。
# 5. 深度学习的训练与调优
深度学习模型的训练与调优是非常重要的环节,它直接影响模型的性能和泛化能力。在本章节中,我们将讨论深度学习模型训练与调优的相关内容。
#### 5.1 数据预处理
数据预处理是深度学习中至关重要的一环。常见的数据预处理操作包括数据标准化、特征缩放、特征选择、数据增强等。其中,数据标准化是指将数据按比例缩放,使之落入特定的范围,以消除不同特征之间的量纲影响;特征缩放则是对特征进行缩放,使其范围落入相似的区间;特征选择则是从所有特征中选择出最具代表性的特征,以降低维度和减少噪音;数据增强则是通过对原始数据进行旋转、翻转、平移等操作,增加数据量,缓解过拟合。
```python
# Python代码示例:数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
```
#### 5.2 损失函数与优化算法
在深度学习中,损失函数用于衡量模型预测结果与实际标签之间的差异,优化算法则用于不断调整模型参数以最小化损失函数。常见的损失函数包括均方误差损失、交叉熵损失等;常见的优化算法包括随机梯度下降(SGD)、Adam、RMSprop等。选择合适的损失函数和优化算法对模型训练影响巨大。
```python
# Python代码示例:使用Adam优化算法进行模型训练
from keras.optimizers import Adam
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.001), metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_val, y_val))
```
#### 5.3 正则化与过拟合
正则化是防止深度学习模型过拟合的重要手段,主要包括L1正则化、L2正则化和Dropout正则化。L1正则化通过增加模型参数的绝对值和作为惩罚项,来降低模型复杂度;L2正则化则通过增加模型参数的平方和作为惩罚项;Dropout正则化则是在训练过程中随机丢弃部分神经元,强制使模型学习更加鲁棒和泛化。
```python
# Python代码示例:使用Dropout正则化防止过拟合
from keras.layers import Dropout
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
```
以上便是深度学习的训练与调优相关内容,包括数据预处理、损失函数与优化算法、正则化与过拟合等方面。这些内容在实际的深度学习模型训练中起着至关重要的作用。
# 6. 深度学习的应用领域
深度学习作为人工智能领域的热门技术,广泛应用于以下领域:
### 6.1 计算机视觉
深度学习在计算机视觉领域具有重要的应用价值。通过深度学习,计算机可以自动从图像或视频中提取并理解特征,实现图像分类、目标检测、图像生成等任务。常用的深度学习模型包括卷积神经网络(CNN)和生成对抗网络(GAN)等。例如,在图像分类任务中,可以使用CNN模型对图像进行训练和分类。在目标检测任务中,可以使用CNN提取图像中的特征,并结合其他算法实现目标的定位和识别。
### 6.2 语音识别
深度学习在语音识别领域也有广泛的应用。语音识别是将语音信号转化为文字的过程,深度学习可以通过训练神经网络模型来实现这一过程。常用的深度学习模型包括循环神经网络(RNN)和长短时记忆网络(LSTM)等。通过这些模型,可以对语音信号进行建模和分析,进而实现语音识别的功能。例如,可以使用RNN模型对语音信号进行时序建模,通过LSTM模型对长期依赖关系进行建模,从而提高语音识别的准确度。
### 6.3 自然语言处理
深度学习在自然语言处理领域也有广泛的应用。自然语言处理是研究如何让计算机能够理解和处理人类语言的方法。深度学习可以通过对大量文本数据的训练来构建语言模型,从而实现自然语言处理的任务。常用的深度学习模型包括循环神经网络(RNN)、长短时记忆网络(LSTM)和注意力机制等。通过这些模型,可以对自然语言进行语义理解、情感分析、机器翻译等任务。例如,在机器翻译任务中,可以使用LSTM模型对源语言和目标语言之间的对应关系进行建模,实现自动的翻译功能。
以上便是深度学习的应用领域的概述。随着技术的不断进步和发展,深度学习在各个领域的应用越来越广泛,也为人们带来了更多的便利和创新。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏《深度学习及其应用》涵盖了深度学习的基础概述以及入门指南。专栏内的文章包括了对BP神经网络的原理与实践的深入探讨,以及通过利用神经网络预测银行客户流失的案例研究。专栏还深入研究了阿里云天池AI实验平台,并总览了人工智能中深度学习的应用。同时,还介绍了智能应用与深度学习的结合,以及卷积神经网络的发展历程。此外,该专栏还介绍了深度学习在图像分类、目标检测、自然语言处理、医疗、推荐系统、金融、交通以及语音识别等领域的应用。通过这些文章的阅读,读者可以获得对深度学习的全面了解以及在不同领域中应用深度学习的方法。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入解析用例图
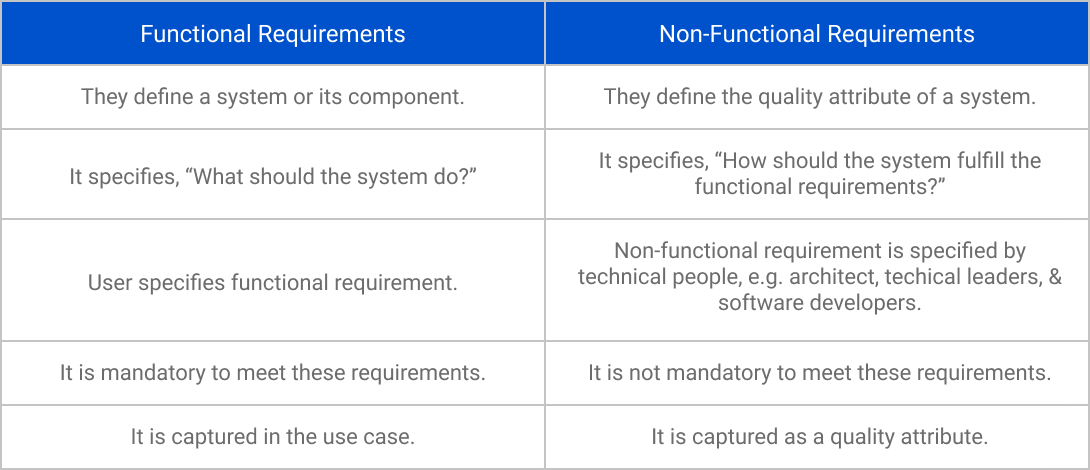
# 摘要
用例图是一种用于软件和系统工程中的图形化表示方法,它清晰地展示了系统的功能需求和参与者之间的交互。本文首先介绍了用例图的基础知识及其在软件工程中的重要作用,随后详细探讨了用例图的组成元素,包括参与者、用例以及它们之间的关系。文章深入分析了用例图的设计规则和最佳实践,强调了绘制过程中的关键步骤,如确定系统范围、识别元素和关系,以及遵循设计原则以保持图的简洁性、可读性和一致性。此外,本文还探讨了用例图在需求分析、系统设计以及敏捷开发中的应用,并通过案例分
IGMP v2报文在大型网络中的应用案例研究:揭秘网络优化的关键
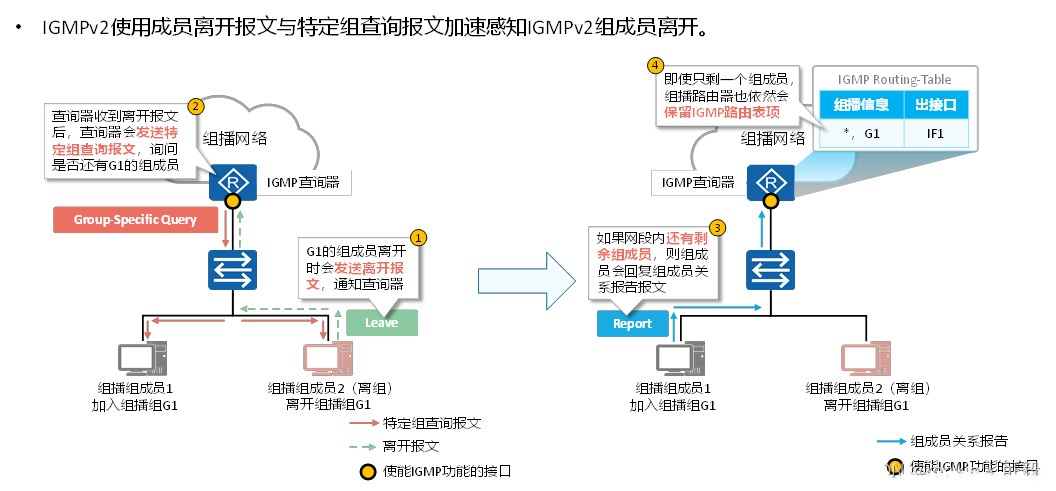
# 摘要
本文深入探讨了互联网组管理协议版本2(IGMP v2)的核心概念、报文结构、功能及其在大型网络中的应用。首先概述了IGMP v2协议的基本原理和报文类型,接着分析了其在网络中的关键作用,包括组成员关系的管理和组播流量的控制与优化。文中进一步探讨了在大型网络环境中如何有效地配置和应用IGMP v2,以及如何进行报文监控与故障排除。同时,本文也讨论了IGMP v
LTE网络优化基础指南:掌握核心技术与工具提升效率

# 摘要
本文旨在全面介绍LTE网络优化的概念及其重要性,并深入探讨其关键技术与理论基础。文章首先明确了LTE网络架构和组件,分析了无线通信原理,包括信号调制、MIMO技术和OFDMA/SC-FDMA等,随后介绍了性能指标和KPI的定义与评估方法。接着,文中详细讨论了LTE网络优化工具、网络覆盖与容量优化实践,以及网络故障诊断和问题解决策略。最后,本文展望了LTE网络的未来发展趋势,包括与5G的融合、新
艺术照明的革新:掌握Art-Net技术的7大核心优势

# 摘要
Art-Net作为一种先进的网络照明控制技术,其发展历程、理论基础、应用实践及优势展示构成了本文的研究核心。本文首先概述了Art-Net技术,随后深入分析了其理论基础,包括网络照明技术的演变、Art-Net协议架构及控制原理。第三章聚焦于Art-Net在艺术照明中的应用,从设计项目到场景创造,再到系统的调试与维护,详尽介绍了艺术照
【ANSYS网格划分详解】:一文掌握网格质量与仿真的秘密关系

# 摘要
ANSYS作为一款强大的工程仿真软件,其网格划分技术在保证仿真精度与效率方面发挥着关键作用。本文系统地介绍了ANSYS网格划分的基础知识、不同网格类型的选择依据以及尺寸和密度对仿真结果的影响。进一步,文章探讨了高级网格划分技术,包括自适应网
【STAR-CCM+网格划分进阶】:非流线型表面处理技术核心解析
# 摘要
本文对STAR-CCM+软件中的网格划分技术进行了全面的介绍,重点探讨了针对非流线型表面的网格类型选择及其特点、挑战,并提供了实操技巧和案例研究。文章首先介绍了网格划分的基础知识,包括不同类型的网格(结构化、非结构化、混合网格)及其应用。随后,深入分析了非流线型表面的特性,以及在网格划分过程中可能遇到的问题,并探讨了高级网格技术如局部加密与细化。实
【智能车竞赛秘籍】:气垫船控制系统架构深度剖析及故障快速修复技巧

# 摘要
气垫船作为一种先进的水上交通工具,其控制系统的设计与实现对于性能和安全性至关重要。本文首先概述了气垫船控制系统的基础理论,接着详细分析了硬件组成及其交互原理,包括动力系统的协同工作、传感器应用以及通信与数据链路的安全机制。第三章深入探讨了气垫船软件架构的设计,涵盖了实时操作系统的配置、控制算法的实现以及软件测试与验证。故障诊断与快速修复技术在第四章被讨论,提供了
Java网络编程必备:TongHTP2.0从入门到精通的全攻略

# 摘要
随着网络技术的快速发展,Java网络编程在企业级应用中占据了重要地位。本文首先介绍了Java网络编程的基础知识,然后深入探讨了HTTP协议的核心原理、不同版本的特性以及工作方式。文章进一步阐释了TongHTTP2.0的安装、配置、客户端和服务器端开发的具体操作。在高级应用部分,本文详细讲解了如何在TongHTTP2.0中集成SSL/TLS以实现安全通信,如何优化性
【LabVIEW编程:电子琴设计全攻略】:从零开始到精通,掌握LabVIEW电子琴设计的终极秘诀
# 摘要
本文系统介绍了LabVIEW编程在信号处理、图形用户界面设计以及电子琴项目中的应用。首先,阐述了LabVIEW编程基础和信号处理的基本知识,包括数字信号的生成、采样与量化,以及声音合成技术和数字滤波器设计。接着,深入探讨了LabVIEW编程图形用户界面的设计原则,交互式元素的实现以及响应式和自适应设计方法。最后,通过LabVIEW电子琴项目实战,分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )