Django模板上下文的国际化与本地化:让上下文支持多语言的解决方案
发布时间: 2024-10-07 17:05:49 阅读量: 22 订阅数: 27 

Django-中文教程.pdf

# 1. Django模板上下文简介
Django框架提供了一个强大的模板系统,它允许我们以一种易于理解且易于维护的方式来分离数据和表示。模板上下文是Django视图和模板之间交互的桥梁,它包含了所有传递给模板的数据。理解模板上下文的工作机制对于开发者来说至关重要,特别是在进行国际化和本地化处理时,上下文能够确保适当的信息被展示给最终用户。
## 1.1 Django模板上下文的构成
一个模板上下文通常由一系列的键值对组成,这些键称为变量名,值则可能是数字、字符串、列表、字典甚至是对象。在Django视图中,我们通常使用`render`函数来创建并返回一个`HttpResponse`对象,这个过程中会将上下文数据传入模板。
```python
def my_view(request):
template = loader.get_template('my_template.html')
context = {'message': 'Hello, World!'}
return HttpResponse(template.render(context, request))
```
## 1.2 上下文在国际化中的作用
在实现国际化和本地化的Django项目中,模板上下文扮演了传递翻译文本和格式化数据的角色。国际化不仅仅是翻译文本,还涉及到日期、时间、数字等的本地化显示。这些信息都是通过上下文传递给模板,然后在模板中使用特定的标签进行渲染,以符合用户的语言和地区偏好。
在下一章中,我们将深入了解如何通过Django的国际化机制来处理多语言内容,并且学习如何使用Django的翻译工具来优化我们的应用。
# 2. 国际化和本地化的基础
### 2.1 Django中的国际化
在当今全球化的互联网环境中,创建能够适应多种语言和文化的网站是许多Web开发者的目标。Django作为一个功能完备的框架,它提供了一整套国际化和本地化的工具,允许开发者轻松地将他们的应用翻译成不同的语言。本节将详细介绍Django国际化过程的各个环节。
#### 2.1.1 国际化过程的基本步骤
Django的国际化过程可以分为几个主要步骤:
1. **激活国际化支持**:首先需要在项目的设置文件中启用国际化支持。
2. **收集可翻译的字符串**:Django提供了一种机制来识别和提取需要翻译的文本。
3. **生成消息文件**:这些文件是翻译者工作的基础,包含了所有待翻译的字符串。
4. **翻译消息文件**:翻译者将消息文件翻译成不同的语言。
5. **使用翻译后的消息文件**:在Django项目中使用这些翻译完成的消息文件。
```python
# settings.py 示例
# 激活国际化支持
USE_I18N = True
# 设置翻译文件目录
LOCALE_PATHS = (
os.path.join(BASE_DIR, 'locale/'),
)
# urls.py 示例
# 添加国际化中间件和URLs
from django.conf.urls.i18n import i18n_patterns
from django.urls import path, include
urlpatterns = i18n_patterns(
path('admin/', ***.urls),
path('accounts/', include('django.contrib.auth.urls')),
# 更多路径...
)
```
#### 2.1.2 翻译文件和消息文件(.po 和 .mo)
消息文件是Django国际化过程中的核心。.po(Portable Object)文件是一个纯文本文件,它包含源代码中的字符串和对应的翻译文本。.mo(Machine Object)文件是二进制文件,通常由.po文件编译而来,用于优化查找速度。
生成和管理这些文件通常使用如`gettext`工具集中的`xgettext`和`msgfmt`工具。Django提供管理命令来处理这些文件,例如`makemessages`和`compilemessages`:
```shell
# 在命令行中执行
django-admin makemessages -l es # 为西班牙语创建消息文件
django-admin compilemessages # 编译所有消息文件
```
翻译完成后,服务器将根据用户的语言偏好使用正确的翻译。
### 2.2 Django中的本地化
本地化是国际化的一个重要组成部分,它涉及将国际化应用适配到特定地区的文化习俗和语言习惯。在Django中,本地化通常涉及到数据格式的转换,比如日期、时间和货币的表示。
#### 2.2.1 本地化过程的基本步骤
本地化的主要步骤如下:
1. **激活本地化支持**:在`settings.py`中设置相应的地区和语言。
2. **配置本地化文件**:设置地区数据文件,以便Django可以适配不同地区格式。
3. **使用本地化格式**:在模板和代码中使用Django提供的本地化函数和标签来格式化数据。
```python
# settings.py 示例
# 设置地区和语言
LANGUAGE_CODE = 'en-us'
LANGUAGES = (
('en', 'English'),
('es', 'Spanish'),
)
# 设置本地化信息
TIME_ZONE = 'UTC'
USE_TZ = True
```
#### 2.2.2 本地化文件的配置和使用
本地化文件通常存储在Python的`locale`目录中。Django支持从`gettext`兼容的目录中加载本地化文件。
在模板中,可以使用本地化标签来格式化日期和时间等:
```django
<!-- 在Django模板中 -->
{% load i18n %}
{% trans "This is a translatable string." %}
<!-- 格式化日期 -->
{% now "Y-m-d" %}
<!-- 格式化数字 -->
{% localize off %}
{{ value|floatformat:2 }}
{% endlocalize %}
```
代码块说明:
- `{% load i18n %}`: 加载Django的国际化模板标签和过滤器。
- `{% trans %}`: 用于翻译标签内的文本。
- `{% now %}`: 显示当前的日期和时间。
- `{% localize %}` 和 `{% endlocalize %}`: 控制数字和日期的本地化格式,`off`参数表示临时关闭本地化。
Django的国际化和本地化不仅仅局限于这些基本的步骤和代码块。在下一章节中,我们将深入探讨如何实现模板上下文的国际化,以及如何有效地将国际化应用到实际的项目中。
# 3. ```
# 第三章:实现模板上下文的国际化
为了构建面向全球用户的应用程序,国际化是不可忽视的一个步骤。Django作为一个成熟的Web框架,提供了强大的国际化支持。本章节将深入探讨如何在Django项目中实现模板上下文的国际化,从而使网站能够支持多种语言。
## 3.1 设置项目以支持国际化
设置项目以支持国际化是开始国际化过程的第一步。这个步骤确保了项目能够适应不同的语言环境。
### 3.1.1 配置国际化中间件
Django中用于支持国际化的核心中间件是`LocaleMiddleware`。这个中间件负责处理语言代码的激活。根据项目的`settings.py`文件配置,国际化中间件可以被添加到`MIDDLEWARE`设置中。
```python
MIDDLEWARE = [
# ...
'django.middleware.locale.LocaleMiddleware',
# ...
]
```
该中间件会根据用户的语言偏好、浏览器设置或cookie来确定使用哪种语言。在配置中间件之后,需要定义`LANGUAGE_CODE`,这是默认的语言代码,以及`LA
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Django 模板上下文的终极指南!本专栏将深入探讨 Django 中上下文 (context) 的方方面面,从基础知识到高级技巧。您将了解如何使用上下文处理器扩展上下文、优化上下文数据以提高性能、处理国际化和本地化、调试上下文问题以及自定义上下文处理器。此外,您还将了解上下文在视图和模板交互中的作用、上下文数据的同步和异步处理、扩展上下文以及上下文构建过程的源码解读。通过本专栏,您将成为 Django 模板上下文管理方面的专家,并能够构建可维护、可扩展且高效的上下文结构。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
TSPL2高级打印技巧揭秘:个性化格式与样式定制指南

# 摘要
TSPL2打印语言作为工业打印领域的重要技术标准,具备强大的编程能力和灵活的控制指令,广泛应用于各类打印设备。本文首先对TSPL2打印语言进行概述,详细介绍其基本语法结构、变量与数据类型、控制语句等基础知识。接着,探讨了TSPL2在高级打印技巧方面的应用,包括个性化打印格式设置、样
JFFS2文件系统设计思想:源代码背后的故事
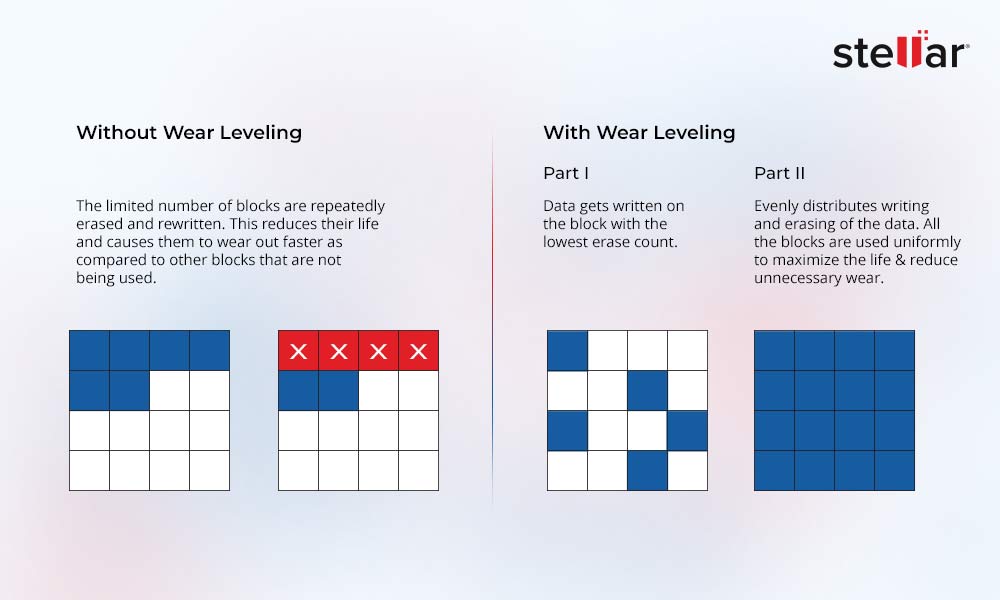
# 摘要
本文对JFFS2文件系统进行了全面的概述和深入的分析。首先介绍了JFFS2文件系统的基本理论,包括文件系统的基础概念和设计理念,以及其核心机制,如红黑树的应用和垃圾回收机制。接着,文章深入剖析了JFFS2的源代码,解释了其结构和挂载过程,以及读写操作的实现原理。此外,针对JFFS2的性能优化进行了探讨,分析了性能瓶颈并提出了优化策略。在此基础上,本文还研究了J
EVCC协议版本兼容性挑战:Gridwiz更新维护攻略

# 摘要
本文对EVCC协议进行了全面的概述,并探讨了其版本间的兼容性问题,这对于电动车充电器与电网之间的有效通信至关重要。文章分析了Gridwiz软件在解决EVCC兼容性问题中的关键作用,并从理论和实践两个角度深入探讨了Gridwiz的更新维护策略。本研究通过具体案例分析了不同EVCC版本下Gridwiz的应用,并提出了高级维护与升级技巧。本文旨在为相关领域的工程师和开发者提供有关EVCC协议及其兼容性维护
计算机组成原理课后答案解析:张功萱版本深入理解

# 摘要
计算机组成原理是理解计算机系统运作的基础。本文首先概述了计算机组成原理的基本概念,接着深入探讨了中央处理器(CPU)的工作原理,包括其基本结构和功能、指令执行过程以及性能指标。然后,本文转向存储系统的工作机制,涵盖了主存与缓存的结构、存储器的扩展与管理,以及高速缓存的优化策略。随后,文章讨论了输入输出系统与总线的技术,阐述了I/O系统的
CMOS传输门故障排查:专家教你识别与快速解决故障
# 摘要
CMOS传输门故障是集成电路设计中的关键问题,影响电子设备的可靠性和性能。本文首先概述了CMOS传输门故障的普遍现象和基本理论,然后详细介绍了故障诊断技术和解决方法,包括硬件更换和软件校正等策略。通过对故障表现、成因和诊断流程的分析,本文旨在提供一套完整的故障排除工具和预防措施。最后,文章展望了CMOS传输门技术的未来挑战和发展方向,特别是在新技术趋势下如何面对小型化、集成化挑战,以及智能故障诊断系统和自愈合技术的发展潜力。
# 关键字
CMOS传输门;故障诊断;故障解决;信号跟踪;预防措施;小型化集成化
参考资源链接:[cmos传输门工作原理及作用_真值表](https://w
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
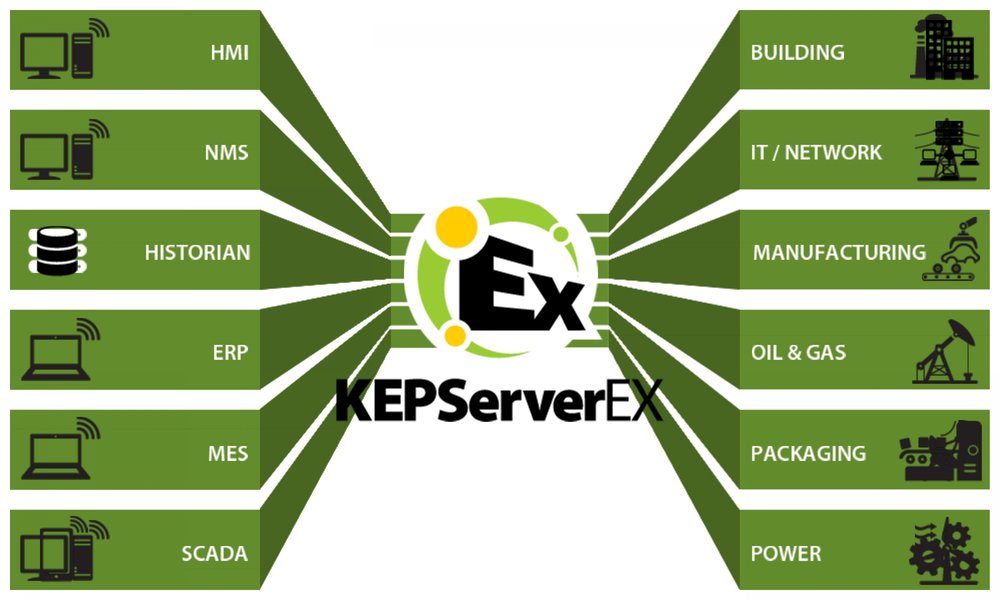
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
【域控制新手起步】:一步步掌握组策略的基本操作与应用
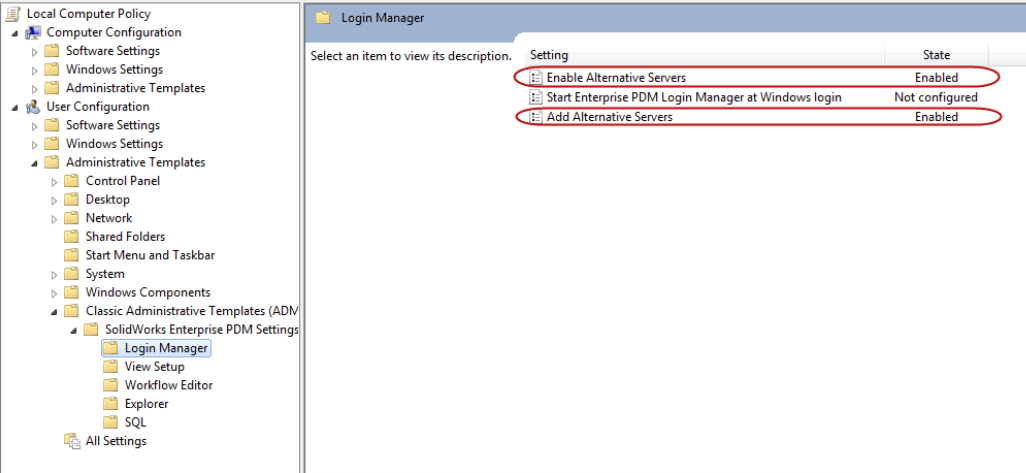
# 摘要
组策略是域控制器中用于配置和管理网络环境的重要工具。本文首先概述了组策略的基本概念和组成部分,并详细解释了其作用域与优先级规则,以及存储与刷新机制。接着,文章介绍了组策略的基本操作,包括通过管理控制台GPEDIT.MSC的使用、组策略对象(GPO)的管理,以及部署和管理技巧。在实践应用方面,本文探讨了用户环境管理、安全策略配置以及系统配置与优化。此
【SolidWorks自动化工具】:提升重复任务效率的最佳实践

# 摘要
本文全面探讨了SolidWorks自动化工具的开发和应用。首先介绍了自动化工具的基本概念和SolidWorks API的基础知识,然后深入讲解了编写基础自动化脚本的技巧,包括模型操作、文件处理和视图管理等。接着,本文阐述了自动化工具的高级应用
Android USB音频设备通信:实现音频流的无缝传输
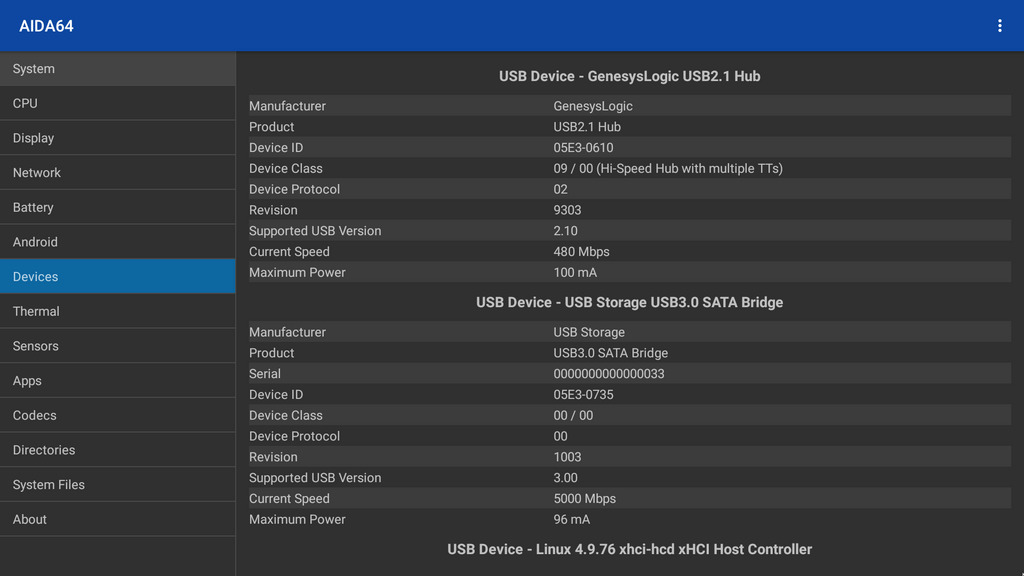
# 摘要
随着移动设备的普及,Android平台上的USB音频设备通信已成为重要话题。本文从基础理论入手,探讨了USB音频设备工作原理及音频通信协议标准,深入分析了Android平台音频架构和数据传输流程。随后,实践操作章节指导读者了解如何设置开发环境,编写与测试USB音频通信程序。文章深入讨论了优化音频同步与延迟,加密传输音频数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )