掌握Kong API网关的基础知识
发布时间: 2023-12-23 00:26:16 阅读量: 40 订阅数: 47 

kong API网关配置
# 第一章:Kong API网关简介
Kong是一个快速、可扩展、分布式的微服务抽象层(也称API网关),可以通过通过Kong来管理API的请求、路由和认证等。Kong基于Nginx,并使用Lua语言进行插件扩展,可以帮助开发人员轻松构建基于微服务架构的应用程序。在本章中,我们将介绍Kong API网关的基本概念和功能,以便于读者对Kong有一个全面的了解。
## 第二章:安装和配置Kong API网关
在本章中,我们将讨论Kong API网关的安装和配置过程。Kong是一个开源的、可扩展的API网关,它可以帮助开发人员管理、监控和安全地连接微服务、RESTful API和其他流量。
### 2.1 安装Kong API网关
要安装Kong API网关,您可以按照以下步骤进行操作:
#### 步骤一:安装Kong的依赖组件
在开始安装Kong之前,需要先安装一些必要的依赖组件,例如PostgreSQL、Cassandra或者DB-less模式所需的数据库。您可以根据您的需求选择其中一种数据库。
```shell
# 以Cassandra为例,安装Cassandra
sudo apt-get update
sudo apt-get install cassandra
```
#### 步骤二:安装Kong
安装Kong主要有两种方式:通过包管理器安装或者通过官方提供的Docker镜像安装。以下是通过包管理器安装Kong的示例:
```shell
# 添加Kong的源
echo "deb https://kong.bintray.com/kong-deb `lsb_release -sc` main" | sudo tee -a /etc/apt/sources.list
# 安装Kong
sudo apt-get update
sudo apt-get install -y kong
```
### 2.2 配置Kong API网关
安装完成后,接下来需要配置Kong API网关。主要的配置包括数据库连接、节点名称、日志级别等。
#### 步骤一:配置数据库连接
编辑Kong的配置文件`kong.conf`,配置Kong连接数据库的信息。如果选择了Cassandra作为数据库,需要配置Cassandra的相关信息。
```shell
# 编辑kong.conf
sudo nano /etc/kong/kong.conf
# 配置数据库连接信息
database = cassandra
cassandra_contact_points = 127.0.0.1:9042
```
#### 步骤二:启动Kong服务
完成配置后,可以启动Kong API网关服务并验证配置是否生效。
```shell
# 启动Kong服务
sudo kong start
# 检查Kong服务状态
sudo kong health
```
至此,您已完成了Kong API网关的安装和配置。接下来,您可以开始使用Kong来管理和保护您的API。
### 第三章:Kong API网关的核心概念解析
Kong API网关作为一个灵活且可扩展的API网关解决方案,具有一些核心概念需要我们理解。在本章中,我们将深入解析这些核心概念,包括服务(Service)、路由(Route)、插件(Plugin)和消费者(Consumer)。
#### 3.1 服务(Service)
在Kong中,服务代表了一组API请求的后端目标。通过定义服务,Kong能够有效地管理API请求的转发和负载均衡。每个服务都有一个唯一的名称和URL地址。我们可以使用Kong的管理界面或者API来创建和配置服务。
让我们通过以下Python代码示例来创建一个名为"example-service"的服务:
```python
import requests
url = "http://localhost:8001/services/"
payload = {
"name": "example-service",
"url": "http://example.com/api"
}
headers = {
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
```
代码总结:上述代码使用Python的requests库向Kong的管理API发送了一个POST请求,创建了一个名为"example-service"的服务,指向"http://example.com/api"。
结果说明:成功创建服务后,Kong将会返回该服务的详细信息,包括唯一的ID、名称和URL地址。
#### 3.2 路由(Route)
路由定义了客户端如何访问Kong中的服务。通过路由,我们可以控制API请求的入口和转发。路由可以根据请求的路径、主机和协议进行匹配,进而将请求转发到对应的后端服务。
以下是一个Java代码示例,用于在Kong中创建一个路由:
```java
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.entity.StringEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
CloseableHttpClient client = HttpClients.createDefault();
HttpPost httpPost = new HttpPost("http://localhost:8001/services/example-service/routes");
StringEntity entity = new StringEntity("{\"paths\": [\"/v1\"]}");
httpPost.setEntity(entity);
httpPost.setHeader("Content-type", "application/json");
CloseableHttpResponse response = client.execute(httpPost);
client.close();
```
代码总结:上述Java代码使用Apache HttpClient库向Kong的管理API发送了一个POST请求,为名为"example-service"的服务创建了一个路径为"/v1"的路由。
结果说明:成功创建路由后,Kong将返回该路由的详细信息,包括唯一的ID和匹配的路径。
### 第四章:使用Kong进行API管理和路由
在本章中,我们将深入探讨如何使用Kong API网关进行API管理和路由。我们将学习如何创建和管理API,配置路由规则以及执行一些高级的API管理任务。
#### 1. 创建和管理API
首先,我们需要了解如何在Kong中创建和管理API。通过Kong的Admin API或者Kong的Web界面,我们可以轻松地创建新的API,并定义其相关属性,比如名称、请求路径、上游服务地址等等。
让我们来看一个使用Kong Admin API创建API的示例:
```python
import requests
kong_admin_url = 'http://localhost:8001/apis/'
data = {
"name": "example-api",
"upstream_url": "http://example.com",
"uris": ["/example"]
}
response = requests.post(kong_admin_url, json=data)
print(response.json())
```
这段Python代码使用了requests库向Kong Admin API发送了一个POST请求,创建了一个名为"example-api"的API,并将其关联到"http://example.com"的上游服务地址,映射到"/example"的请求路径上。
#### 2. 配置路由规则
一旦API创建完成,我们就需要为其配置路由规则,以确定API的访问路径和流量转发方式。Kong允许我们配置多种类型的路由规则,比如基于请求路径、请求方法、Host头等等。
下面是一个使用Kong Admin API配置路由规则的示例:
```java
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
CloseableHttpClient client = HttpClients.createDefault();
HttpPost httpPost = new HttpPost("http://localhost:8001/routes/");
httpPost.addHeader("content-type", "application/json");
String routeConfig = "{\"hosts\":[\"example.com\"],\"paths\":[\"/example\"],\"methods\":[\"GET\"]}";
StringEntity routeEntity = new StringEntity(routeConfig);
httpPost.setEntity(routeEntity);
CloseableHttpResponse response = client.execute(httpPost);
System.out.println(response.getStatusLine().getStatusCode());
client.close();
```
这段Java代码使用了Apache HttpClient库向Kong Admin API发送了一个POST请求,配置了一个路由规则,该规则指定了当Host为"example.com"、路径为"/example"、方法为"GET"时,流量应该转发到之前创建的"example-api"API上。
#### 3. 高级API管理任务
除了简单的API创建和路由配置之外,Kong还提供了许多高级的API管理功能,比如访问控制、日志记录、认证等。通过Kong的插件系统,我们可以轻松地为API添加各种功能。
下面是一个使用Kong插件为API添加访问控制功能的示例:
```go
package main
import (
"bytes"
"fmt"
"net/http"
)
func main() {
url := "http://localhost:8001/apis/example-api/plugins/"
payload := []byte(`{"name": "acl"}`)
req, _ := http.NewRequest("POST", url, bytes.NewBuffer(payload))
req.Header.Set("Content-Type", "application/json")
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
fmt.Println("Error:", err)
}
defer resp.Body.Close()
fmt.Println("Response Status:", resp.Status)
}
```
这段Go代码向Kong Admin API发送了一个POST请求,为之前创建的"example-api"API添加了名为"acl"的访问控制插件,从而实现了对该API的访问控制功能。
通过本章的学习,我们深入了解了如何使用Kong进行API管理和路由配置,以及如何执行一些高级的API管理任务。在下一章,我们将学习Kong插件的使用与扩展。
现在您可以阅读本章内容,并深入了解使用Kong进行API管理和路由的详细步骤和示例代码了。
## 第五章:Kong插件的使用与扩展
在本章中,我们将讨论Kong API网关的插件系统,以及如何使用和扩展这些插件来增强API网关的功能。
### 5.1 插件的基本概念
Kong插件是一种可用于扩展Kong API网关功能的模块化组件。通过使用插件,用户可以在HTTP请求的不同阶段添加或修改行为,以实现诸如认证、日志记录、限流等功能。Kong插件分为全局插件和服务/路由插件,分别作用于所有服务或特定服务/路由。Kong自身提供了丰富的插件功能,同时也支持自定义插件的开发。
### 5.2 常用的Kong插件介绍
Kong提供了多种常用插件,包括但不限于:
- 认证插件:如基于JWT的身份认证、OAuth2.0认证等。
- 日志插件:可以将HTTP请求和响应信息记录到日志系统中。
- 频率限制插件:用于限制API的访问频率,防止滥用。
- 负载均衡插件:用于将流量分发到多个后端服务。
- 请求转发插件:用于将请求按照自定义规则转发到不同的后端服务。
### 5.3 使用Kong插件
下面我们以Kong的日志插件为例,介绍如何在API网关中使用插件。
首先,我们需要在Kong中启用日志插件:
```shell
$ curl -i -X POST --url http://localhost:8001/services/{service}/plugins --data "name=http-log"
```
接下来,我们可以通过配置插件的参数来定义日志记录的方式,例如将日志发送到指定的Elasticsearch或Kafka集群中。以下是一个使用Elasticsearch的示例:
```shell
$ curl -i -X POST --url http://localhost:8001/services/{service}/plugins --data "name=http-log" --data "config.http_endpoint=http://elasticsearch:9200"
```
### 5.4 扩展Kong插件
除了使用Kong自带的插件之外,用户还可以根据自身需求开发定制化的插件。Kong提供了开发自定义插件的API和SDK,使得插件的开发变得简单和灵活。开发者可以使用Lua或者其他语言编写自定义插件,并在Kong中进行注册和配置。下面是一个使用Lua语言编写Kong插件的示例:
```lua
-- custom-auth-plugin.lua
local CustomAuthHandler = {}
function CustomAuthHandler:access(config)
-- 在这里编写自定义认证逻辑
end
return CustomAuthHandler
```
通过上述示例,我们可以看到,用户可以使用Lua语言编写自定义插件的逻辑,并在Kong中注册和配置该插件,以实现自定义的API网关功能。
### 5.5 插件的总结与展望
Kong插件系统为用户提供了丰富的功能扩展能力,使得API网关的功能变得更加强大和灵活。除了Kong提供的常用插件之外,用户还可以根据自身需求开发定制化的插件,满足特定的业务场景。随着Kong生态的不断完善和社区的贡献,我们相信Kong插件系统将会变得更加丰富多样,为用户提供更好的API网关体验。
### 第六章:Kong API网关的部署和运维策略
在本章中,我们将讨论Kong API网关的部署和运维策略。Kong作为一个重要的API网关工具,在部署和运维方面有着一些值得注意的策略和最佳实践。
#### 1. 自动化部署
在部署Kong时,我们可以采用自动化部署的方式,例如使用Docker容器进行部署。通过Docker容器,可以更方便地部署和扩展Kong API网关,并且能够快速构建和部署整个Kong环境。
```shell
# 使用Docker Compose进行Kong部署示例
version: '3'
services:
kong-database:
image: postgres:9.6
environment:
POSTGRES_DB: kong
POSTGRES_USER: kong
POSTGRES_PASSWORD: kong
kong:
image: kong:latest
depends_on:
- kong-database
environment:
KONG_DATABASE: postgres
KONG_PG_HOST: kong-database
KONG_PG_DATABASE: kong
KONG_PG_USER: kong
KONG_PG_PASSWORD: kong
ports:
- "8000:8000"
- "8443:8443"
- "8001:8001"
- "8444:8444"
```
#### 2. 高可用部署
针对高可用性要求较高的生产环境,可以采用Kong的高可用部署方式,通过搭建多个Kong节点进行负载均衡,提高系统的稳定性和容错能力。常见的做法是使用Nginx或Haproxy作为Kong节点的负载均衡器。
#### 3. 监控和日志
在部署Kong后,需要密切关注其性能和运行状况。可以选择使用Prometheus、Grafana等监控工具对Kong的各项指标进行监控,并结合Elasticsearch、Logstash和Kibana等工具对Kong的日志进行收集和分析,及时发现和解决潜在问题。
```yaml
# 配置Kong输出日志到Elasticsearch示例
loggers:
- name: kong
level: notice
file: "logs/error.log"
metrics: true
healthchecks: false
format: "json"
- name: file
path: "logs/access.log"
rotation:
type: "size"
size: "10M"
count: 10
```
#### 4. 故障处理与自动恢复
Kong API网关作为中间件,需要具备一定的故障处理和自动恢复能力。在部署环境中,需结合负载均衡、健康检查等机制,实现对Kong节点的实时监控,并在节点出现故障时能够自动触发故障转移或自动恢复的操作。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《kong》专栏深入探讨了Kong API网关的各种关键知识和实践技巧。从基础知识到高级应用,包括身份验证与授权、流量控制与限流策略、日志记录与监控优化、负载均衡与故障转移等多个方面的内容,旨在帮助读者全面掌握Kong API网关的功能和特性。此外,专栏还详细介绍了Kong插件开发的指南和实例,包括构建自定义功能、请求转发策略、数据转换与格式化、高性能的请求缓存策略、防御攻击手段等多个方面,帮助读者深入理解Kong的插件机制和执行流程,进而实现对Kong API网关的个性化定制。同时,该专栏还涵盖了构建高可用的Kong API网关集群架构,以及故障排除与监控策略等内容,帮助读者进一步优化Kong API网关的性能和可扩展性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ACC自适应巡航软件功能规范】:揭秘设计理念与实现路径,引领行业新标准

# 摘要
自适应巡航控制(ACC)系统作为先进的驾驶辅助系统之一,其设计理念在于提高行车安全性和驾驶舒适性。本文从ACC系统的概述出发,详细探讨了其设计理念与框架,包括系统的设计目标、原则、创新要点及系统架构。关键技术如传感器融合和算法优化也被着重解析。通过介绍ACC软件的功能模块开发、测试验证和人机交互设计,本文详述了系统的实现
敏捷开发与DevOps的融合之道:软件开发流程的高效实践

# 摘要
敏捷开发与DevOps是现代软件工程中的关键实践,它们推动了从开发到运维的快速迭代和紧密协作。本文深入解析了敏捷开发的核心实践和价值观,探讨了DevOps的实践框架及其在自动化、持续集成和监控等方面的应用。同时,文章还分析了敏捷开发与DevOps的融合策略,包括集成模式、跨功能团队构建和敏捷DevOps文化的培养。通过案例分析,本文提供了实施敏捷DevOps的实用技巧和策略
【汇川ES630P伺服驱动器终极指南】:全面覆盖安装、故障诊断与优化策略
# 摘要
汇川ES630P伺服驱动器是工业自动化领域中先进的伺服驱动产品,它拥有卓越的基本特性和广泛的应用领域。本文从概述ES630P伺服驱动器的基础特性入手,详细介绍了其主要应用行业以及与其他伺服驱动器的对比。进一步,探讨了ES630P伺服驱动
AutoCAD VBA项目实操揭秘:掌握开发流程的10个关键步骤
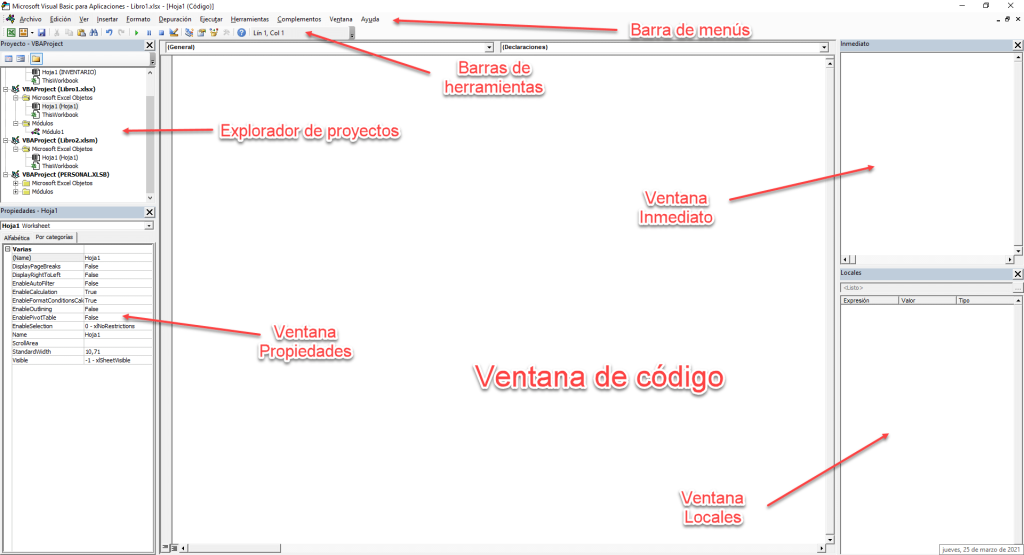
# 摘要
本文旨在全面介绍AutoCAD VBA的基础知识、开发环境搭建、项目实战构建、编程深入分析以及性能优化与调试。文章首先概述AutoCAD VBA的基本概念和开发环境,然后通过项目实战方式,指导读者如何从零开始构建AutoCAD VBA应用。文章深入探讨了VBA编程的高级技巧,包括对象模型、类模块的应用以及代码优化和错误处理。最后,文章提供了性能优化和调试的方法,并
NYASM最新功能大揭秘:彻底释放你的开发潜力
# 摘要
NYASM是一个功能强大的汇编语言工具,支持多种高级编程特性并具备良好的模块化编程支持。本文首先对NYASM的安装配置进行了概述,并介绍了其基础与进阶语法。接着,本文探讨了NYASM在系统编程、嵌入式开发以及安全领域的多种应用场景。文章还分享了NYASM的高级编程技巧、性能调优方法以及最佳实践,并对调试和测试进行了深入讨论。最后,本文展望了NYASM的未来发展方向,强调了其与现代技
ICCAP高级分析:挖掘IC深层特性的专家指南
# 摘要
本文全面介绍了ICCAP的理论基础、实践应用及高级分析技巧,并对其未来发展趋势进行了展望。首先,文章介绍了ICCAP的基本概念和基础知识,随后深入探讨了ICCAP软件的架构、运行机制以及IC模型的建立和分析方法。在实践应用章节,本文详细阐述了ICCAP在IC参数提取和设计优化中的具体应用,包括方法步骤和案例分析。此外,还介绍了ICCAP的脚本编程技巧和故障诊断排除方法。最后,文章预测了ICCAP在物联网和人工智能
【Minitab单因子方差分析】:零基础到专家的进阶路径
# 摘要
本文详细介绍了Minitab单因子方差分析的各个方面。第一章概览了单因子方差分析的基本概念和用途。第二章深入探讨了理论基础,包括方差分析的原理、数学模型、假设检验以及单因子方差分析的类型和特点。第三章则转向实践操作,涵盖了Minitab界面介绍、数据分析步骤、结果解读和报告输出。第四章讨论了高级应用,如多重比较、方差齐性检验及案例研究。第五章关注在应用单因子方差分析时可能
FTTR部署实战:LinkHome APP用户场景优化的终极指南
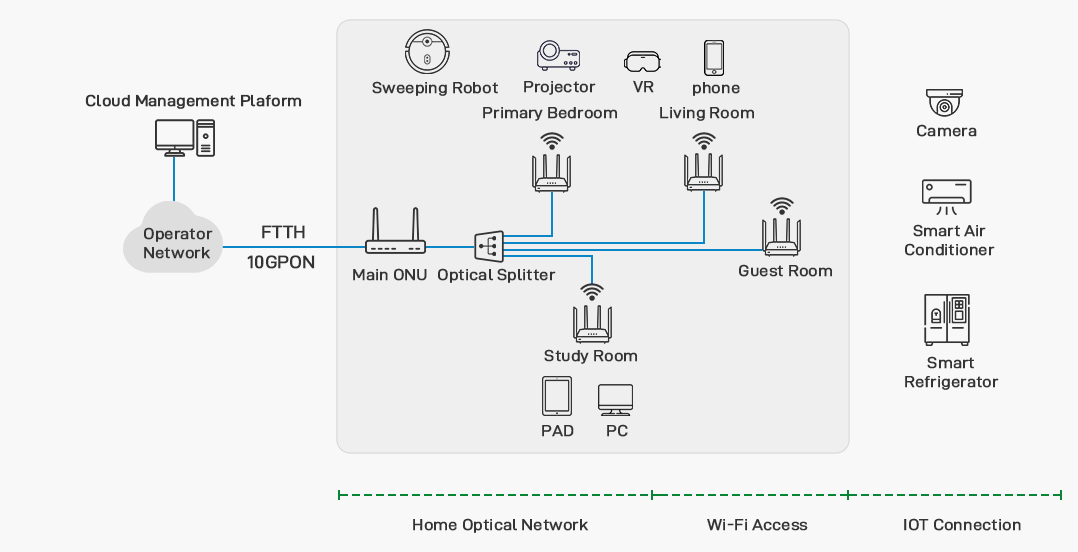
# 摘要
本论文首先介绍了FTTR(Fiber To The Room)技术的基本概念及其背景,以及LinkHome APP的概况和功能。随后详细阐述了在FTTR部署前需要进行的准备工作,包括评估网络环境与硬件需求、分析LinkHome APP的功能适配性,以及进行预部署测试与问题排查。重点介绍了FTTR与LinkHome APP集成的实践,涵盖了用户场景配置、网络环境部署实施,以及网络性能监
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )