Camunda工作流引擎安装与配置详解
发布时间: 2024-02-23 11:31:34 阅读量: 221 订阅数: 35 
# 1. 简介
工作流引擎是指用于管理、执行和监控流程工作流程的软件系统。它可以帮助组织优化业务流程、提高效率和可靠性。Camunda是一个开源的、灵活且轻量级的工作流引擎,具有强大的流程管理和执行能力。
## 介绍工作流引擎的概念和作用
工作流引擎可以将业务逻辑、规则和流程定义集成到一个可执行的模型中,进而实现自动化和流程控制。它能够提供跟踪、监控、执行和优化各种类型的业务流程,并支持复杂的流程逻辑和人机交互。
## 介绍Camunda工作流引擎及其特点
Camunda是基于BPMN 2.0标准的工作流引擎,具有简单易用的特点,适用于各种规模的企业应用。它支持工作流和决策管理,并提供了丰富的API和插件,可以轻松地集成到现有的应用系统中。Camunda还提供了用户友好的管理控制台,方便用户对流程进行监控和管理。
# 2. 准备工作
在安装和配置Camunda工作流引擎之前,我们需要进行一些准备工作,包括系统要求和环境准备、下载安装包以及安装所需的数据库软件。让我们逐步进行准备工作:
### 系统要求和环境准备
在开始安装Camunda工作流引擎之前,请确保你的系统满足以下要求:
- Java JDK 8或更高版本
- 支持的操作系统:Windows、Linux、Mac OS
- 推荐使用最新版本的浏览器进行访问
### 下载Camunda工作流引擎安装包
访问Camunda官方网站(https://camunda.com/download/)下载最新版本的Camunda工作流引擎安装包。你可以选择适合你系统的版本进行下载,例如zip压缩包或war文件。
### 安装所需的数据库软件
Camunda需要数据库来存储流程定义、实例数据等信息。你可以选择使用MySQL、PostgreSQL、Oracle等数据库软件。在这里以MySQL为例,首先安装MySQL数据库并创建一个数据库供Camunda使用:
```sql
-- 创建一个数据库
CREATE DATABASE camunda_database;
-- 创建一个用户并授予数据库权限
CREATE USER 'camunda_user'@'localhost' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON camunda_database.* TO 'camunda_user'@'localhost';
FLUSH PRIVILEGES;
```
在接下来的章节中,我们将详细介绍如何安装和配置Camunda工作流引擎,敬请关注。
# 3. 安装Camunda工作流引擎
在本章节中,我们将详细介绍如何安装Camunda工作流引擎。按照以下步骤操作:
1. **安装过程详解:**
- 下载Camunda工作流引擎安装包并解压缩到指定目录。
- 运行启动脚本或命令以启动Camunda引擎。
- 在浏览器中输入相应的地址来确认安装成功。
```bash
# 示例启动Camunda引擎的命令
cd /path/to/camunda/bin
./start-camunda.sh
```
2. **常见安装问题及解决方法:**
- 问题:启动时提示端口被占用。
解决方法:修改Camunda配置文件中的端口号,确保不与其他服务冲突。
- 问题:无法连接数据库。
解决方法:检查数据库连接配置是否正确,并确保数据库服务正常运行。
通过以上步骤就可以顺利安装Camunda工作流引擎,若遇到问题可参考上述解决方法。
# 4. 配置
在安装完成Camunda工作流引擎后,接下来需要进行相应的配置,包括数据库连接、管理员账户和权限配置,以及可选的配置项如邮件服务器配置等。
#### 4.1 配置数据库连接
在使用Camunda工作流引擎之前,需要配置数据库连接,确保工作流引擎能够正确地存储流程定义、流程实例和相关数据。
```java
// Java代码示例
public class CamundaDatabaseConfiguration {
public static void main(String[] args) {
// 配置数据库连接信息
String url = "jdbc:mysql://localhost:3306/camunda";
String username = "username";
String password = "password";
// 配置数据源
DataSource dataSource = new DataSource(url, username, password);
// 将数据源配置到Camunda引擎中
ProcessEngineConfiguration configuration = ProcessEngineConfiguration.createStandaloneProcessEngineConfiguration()
.setDataSource(dataSource)
.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE);
ProcessEngine processEngine = configuration.buildProcessEngine();
}
}
```
#### 4.2 配置管理员账户和权限
在配置管理员账户和权限时,需要确保只有经过授权的用户才能管理和监控工作流引擎,保障系统的安全性。
```java
// Java代码示例
public class CamundaAdminConfiguration {
public static void main(String[] args) {
// 配置管理员账户和权限
String adminUserId = "admin";
String adminPassword = "admin123";
// 配置权限控制
IdentityService identityService = processEngine.getIdentityService();
User user = identityService.newUser(adminUserId);
user.setPassword(adminPassword);
identityService.saveUser(user);
// 授予管理员权限
identityService.setAuthenticatedUserId(adminUserId);
Authorization adminAuthorization = identityService.createNewAuthorization(Authorization.AUTH_TYPE_GRANT);
adminAuthorization.setUserId(adminUserId);
adminAuthorization.addPermission(Permissions.ALL);
identityService.saveAuthorization(adminAuthorization);
}
}
```
#### 4.3 配置邮件服务器等可选配置项
除了基本的数据库连接和权限配置外,还可以配置邮件服务器等可选项,以便在工作流实例执行过程中发送邮件通知等。
```java
// Java代码示例
public class CamundaEmailConfiguration {
public static void main(String[] args) {
// 配置邮件服务器
MailServerConfiguration mailConfig = new MailServerConfiguration("smtp.example.com", 25, "username", "password");
// 配置邮件任务监听器
MailTaskListener mailTaskListener = new MailTaskListener(mailConfig);
// 将邮件任务监听器添加到流程中
Bpmn.addTaskListener("Task", TaskListener.EVENTNAME_CREATE, mailTaskListener);
}
}
```
以上示例代码演示了如何在Java环境下配置Camunda工作流引擎的数据库连接、管理员账户和权限,以及可选的邮件服务器配置。在实际应用中,还可以根据具体需求进行更多定制化的配置。
在下一章节中,我们将介绍如何启动Camunda工作流引擎并进行简单的使用和测试。
# 5. 使用与测试
在本章节中,我们将介绍如何启动Camunda工作流引擎并进行基本的使用和测试。首先,我们将启动引擎,然后访问管理控制台,并进行一些常见的操作,包括创建和部署流程定义,启动和监控流程实例。
#### 启动Camunda工作流引擎
启动Camunda工作流引擎非常简单。只需执行以下步骤:
1. 打开命令行窗口或终端
2. 切换到Camunda安装目录下的bin目录
3. 执行启动命令,例如:`start-camunda.bat` (Windows) 或 `./start-camunda.sh` (Linux)
启动成功后,你将看到引擎日志输出,并且可以访问默认的管理控制台。
#### 访问管理控制台
在浏览器中输入以下URL来访问Camunda管理控制台:`http://localhost:8080/camunda/app/welcome/default/`。在默认情况下,使用用户名 `demo` 和密码 `demo` 可以登录。
#### 创建和部署流程定义
在管理控制台中,你可以创建并部署流程定义。点击左侧菜单栏中的“流程定义”选项,然后点击“创建新的流程定义”按钮。在弹出的对话框中,选择要部署的BPMN文件,填写相关信息,然后点击“部署”按钮即可完成流程定义的创建和部署。
#### 启动和监控流程实例
在管理控制台中,点击左侧菜单栏中的“流程实例”选项,你可以查看已部署流程的实例列表,并可以手动启动新的流程实例。在流程实例详情页,你可以监控流程实例的执行情况,包括任务完成情况、流程变量等信息。
通过以上操作,你可以对Camunda工作流引擎进行基本的使用和测试。接下来,让我们来看看如何将工作流引擎集成到项目中。
# 6. 部署与集成
在这一节中,我们将讨论如何将Camunda工作流引擎集成到项目中,以及如何部署自定义流程并添加用户任务和表单。
#### 将工作流引擎集成到项目中
在将工作流引擎集成到项目中之前,首先需要确保项目的依赖中包含了Camunda的相关库。接下来,我们将演示如何在Java项目中完成集成。
首先,在项目的pom.xml文件中添加Camunda BPM的依赖:
```xml
<dependency>
<groupId>org.camunda.bpm</groupId>
<artifactId>camunda-engine</artifactId>
<version>7.14.0</version>
</dependency>
```
然后,创建一个Camunda配置类,用于配置工作流引擎的设置:
```java
import org.camunda.bpm.engine.ProcessEngine;
import org.camunda.bpm.engine.ProcessEngineConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CamundaConfig {
@Bean
public ProcessEngine processEngine() {
return ProcessEngineConfiguration
.createStandaloneProcessEngineConfiguration()
.setJdbcUrl("jdbc:h2:mem:my-database")
.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE)
.setJobExecutorActivate(true)
.buildProcessEngine();
}
}
```
通过以上配置,我们已经成功将Camunda工作流引擎集成到了项目中。
#### 部署自定义流程
要部署自定义流程,首先需要创建一个BPMN 2.0流程定义文件,然后将该文件部署到Camunda引擎中。
接下来,演示一个简单的BPMN 2.0流程定义文件:
```xml
<!-- 这里是BPMN 2.0流程定义的XML文件内容 -->
<definitions id="definitions"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
targetNamespace="http://camunda.org/examples">
<process id="myProcess" name="My Process">
<!-- 这里是流程定义的详细内容 -->
</process>
</definitions>
```
然后,使用Camunda提供的API将该流程定义文件部署到引擎中:
```java
repositoryService.createDeployment()
.addClasspathResource("path/to/your/process.bpmn")
.deploy();
```
#### 添加用户任务和表单
在BPMN 2.0流程定义文件中,可以定义用户任务并为其添加表单,以便在流程执行过程中收集用户输入。
以下是一个简单的用户任务定义示例:
```xml
<userTask id="task1" name="Review Task">
<documentation>Review the request and provide feedback</documentation>
<formKey>embedded:app:forms/review-form.html</formKey>
</userTask>
```
上述示例中,定义了一个名为"Review Task"的用户任务,并指定了与之关联的表单。
通过以上步骤,我们成功地对Camunda工作流引擎进行了部署与集成,并添加了自定义流程和用户任务。
接下来,我们将深入探讨Camunda工作流引擎的高级功能和应用场景。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏以"Camunda工作流引擎"为主题,围绕着该工作流引擎的各个方面展开了多篇文章,内容涵盖了从入门指南到高级应用的多个主题。首先介绍了Camunda工作流引擎的基本概念和入门指南,帮助读者快速了解其基本原理和使用方法。接着深入探讨了任务管理、REST API的使用、定时任务与事件触发机制、性能优化与调优经验等方面,为读者呈现了更加全面和深入的技术知识。此外,还涉及了事件驱动流程、消息中间件集成、数据变量与表达式的使用方法,以及与数据库集成等实践经验。通过这些文章,读者可以系统地学习Camunda工作流引擎,并掌握其在实际项目中的应用技巧和最佳实践,为工作流引擎的使用和开发提供了全面的指导和参考。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
GMW3122二次开发指南:拓展功能的10大进阶技术

# 摘要
GMW3122二次开发是一个系统性的工程,它涉及对设备基础功能的深入理解与实践操作,以及对开发环境的配置和技术的选择。本文首先概述了GMW3122二次开发的概况,随后详细介绍了其基础功能的硬件结构和软件环境,并指导如何进行实践操作。接下来,文章深入探讨了如何选择和配置开发工具以及应用中的常用技术。关键技术的应用和具体实例分析是本文的核心部分,涉及硬件接口、软件架构等关键领
【创新教程】74HC01芯片逻辑功能拓展:构建复杂逻辑控制电路的策略
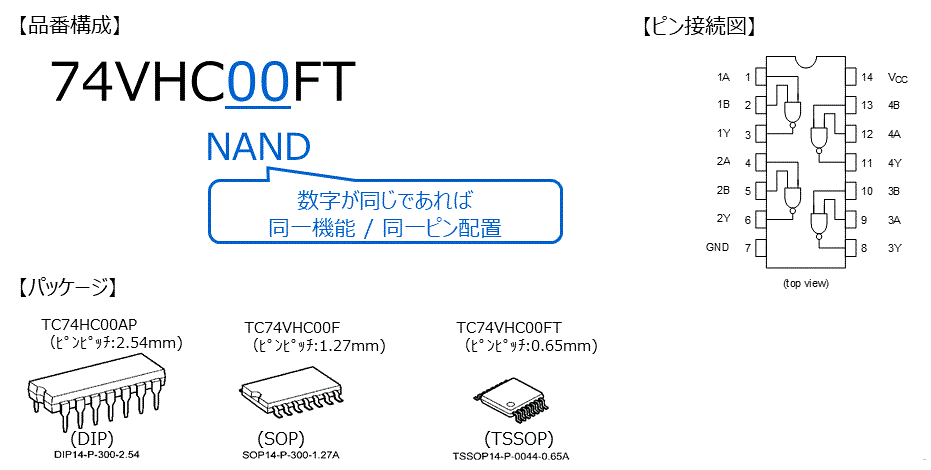
# 摘要
本文首先介绍了74HC01芯片的基本逻辑功能及其在现代电子设计中的重要性。随后,文章深入探讨了逻辑电路的设计原理,包括逻辑门的概念、复杂逻辑的构建方法以及电路优化和标准化策略。在此基础上,详细阐述了74HC01芯片在实现多路选择器、
编码器分辨率优化策略:10个提升编码器性能的实用技巧
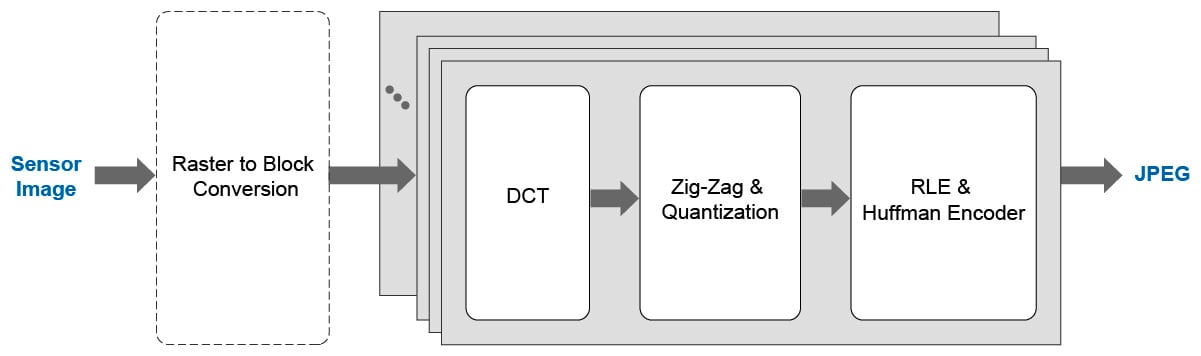
# 摘要
编码器分辨率优化是提升视频处理质量和效率的关键技术。本文首先介绍了编码器分辨率优化的基础知识,随后分析了分辨率与编码器性能指标之间的关系,包括图像质量和处理速度的影响。本文详细探讨了硬件升级与调整技巧,并深入讨论了软件算法和设置对分辨率提升的作用。最后,通过
【VBA编程深度剖析】:从Excel新手到VBA宏编程专家的成长之路
# 摘要
本文全面探讨了VBA编程在Excel集成环境中的应用,包括基础概念、进阶技巧、实际应用案例、面向对象编程、性能优化和安全策略等多个方面。文章从基础的VBA编程基础和Excel集成讲起,深入介绍高级编程技巧,如数据结构、算法实现、过程与函数设计及错误处理。随后,探讨了VBA在Excel自动化操作、数据分析和报告生成等实际应用场景,并扩展到与其他Office
【FPGA存储虚拟化】:NVMe IP与资源管理的革命性方法
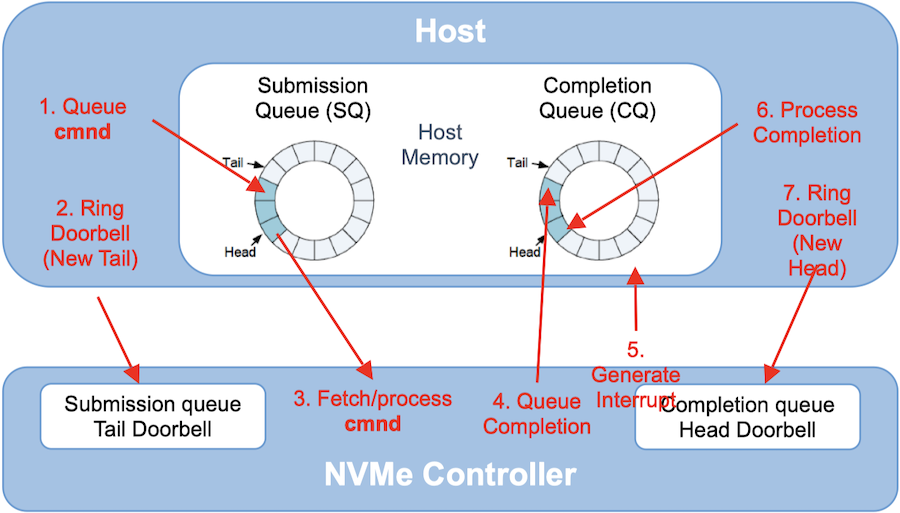
# 摘要
本论文系统地探讨了FPGA存储虚拟化技术的原理、实现、管理以及安全性考量。首先概述了FPGA存储虚拟化的概念,随后深入分析了NVMe技术的原理及其在FPGA中的实现,包括核心功能和性能优化策略。接着,论文从理论和实践两个维度讨论了存储资源管理的基础和在FPGA中的应用。此外,本研究还讨论了存储虚拟化实践中的系统架构、应用案例以及面临的挑战和未来发
【fm17520:模块功能解锁】:深入了解每个模块的实用信息

# 摘要
模块化编程作为一种提升软件开发效率和质量的重要实践,其理论基础和设计原则对于构建可维护、可扩展的软件系统至关重要。本文系统地探讨了模块功能的设计原则,包括提高代码的可重用性和优化代码的可维护性,以及模块化结构的设计。通过分析模块功能实现的技术细节,包括代码实现、模块间交互与通信、模块测试与验证,本文强
智能语音助手技术革命:打造下一代交互体验

# 摘要
智能语音助手作为一种新兴技术,近年来在全球范围内迅速兴起并广泛应用于多种场景中。本文从智能语音助手的发展历程入手,详细探讨了语音识别技术的理论基础与实践应用,并进一步阐述了自然语言处理(NLP)在提升智能助手理解和交互能力方面的重要作用。文章还分析了智能语音助手的设
八位运算器设计的功耗散热平衡术:成本效益与性能的双重优化

# 摘要
本文系统性地探讨了八位运算器的设计与优化策略,涵盖了功耗管理、散热解决方案以及成本效益与性能的双重优化。首先,分析了运算器的功耗基础理论和影响因素,并提出了能源效率提升和动态电压频率调整(DVFS)等优化策略。接着,从基本原理出发,详细讨论了散热技术的应用和优化实践案例。本文还对成本效益分析进行了基础性的探讨,阐述了设计中成本与性能权衡的策略,并分享了优化的成功案例。最后,文章总结了当
事务回滚的多维视角:非线性规划的综合应用剖析

# 摘要
事务回滚是保证数据库事务一致性和系统稳定性的关键技术,本文全面探讨了事务回滚的概念、理论框架、实践应用、高级话题以及相关技术的深入探讨。文中首先介绍了事务的一致性原理和ACID特性,随后详细阐述了回滚机制的工作流程,包括日志记录与恢复点的设置以及错误检测与触发条件。非线性规划在优化事务回滚策略中的应用也得到了深入分析。实践应用部分通过对数据库事务回滚的案例分析
【DSP-C6713通信机制详解】:与外围设备的协同工作

# 摘要
本文详细介绍了DSP-C6713处理器的特性、与外围设备的接口技术、通信机制理论基础以及协同工作实践和应用实例。首先概述了DSP-C6713的基本情况,随后深入探讨了其与外围设备的接口技术,包括引脚定义、总线协议和通信接口标准。接着,文章阐述了DSP-C
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )