




中学排课管理数据库设计秘籍:从基础到高级优化指南


某中学的排课管理系统数据库系统设计
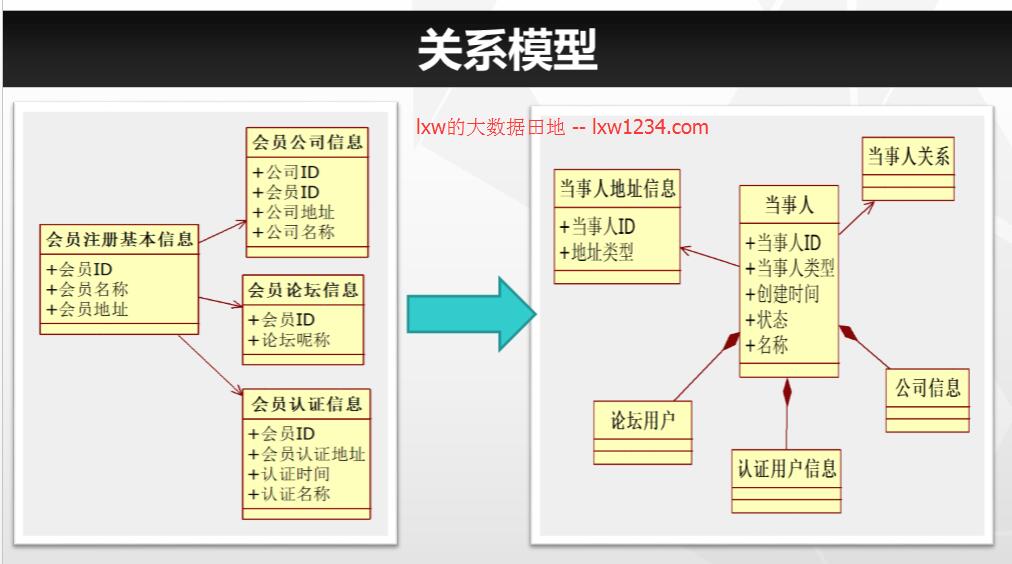
参考资源链接:某中学的排课管理系统数据库系统设计
1. 中学排课管理数据库的需求分析
在教育行业的数字化转型过程中,中学排课管理系统的构建显得尤为重要。需求分析阶段是整个数据库设计和开发过程中的首要步骤,它直接影响到系统的可用性和扩展性。
1.1 功能性需求
中学排课管理数据库应满足教师、学生和行政人员的不同需求。其中,教师需要能够查看和调整自己的课程表、管理学生考勤记录;学生则需要查询课程安排、考试时间;而行政人员负责录入课程信息、处理课程冲突等。
1.2 数据一致性与完整性需求
为了确保排课信息的准确性,数据库必须保证数据的一致性和完整性。例如,一个课程只能存在于一个教室的特定时间段内,而且教师在任一时间点上只能有一个课程任务。
1.3 安全性与隐私性需求
考虑到教育行业的敏感性,数据库中的学生成绩、个人信息等必须得到严格保护。系统应实现访问控制,不同角色只能访问授权的数据,并且需要有日志记录所有关键操作。
本章节通过对中学排课管理数据库功能、一致性和安全性的深入分析,为下一阶段的数据库设计奠定了坚实的基础。
2. 数据库基础设计原则
2.1 实体-关系模型构建
2.1.1 确定实体和属性
构建实体-关系模型是数据库设计的核心环节之一。首先,我们需要识别出系统中的主要实体。在中学排课管理数据库的上下文中,主要实体可能包括:
- 学生(Student)
- 教师(Teacher)
- 课程(Course)
- 班级(Class)
- 时间表(Schedule)
每个实体都有其特定的属性。例如,对于实体“学生”,可能具有以下属性:
- 学号(StudentID)
- 姓名(Name)
- 性别(Gender)
- 出生日期(DateOfBirth)
- 所在班级(Class)
通过分析实体及其属性,我们可以创建一个清晰的实体-关系模型。这将为数据库的表结构设计打下坚实的基础。
2.1.2 实体间关系的规范化
在确定实体和属性之后,下一个步骤是定义实体之间的关系。在数据库中,常见的关系类型包括一对多、多对多以及一对一。以中学排课管理为例,我们可以定义以下关系:
- 教师与课程:一对多(一个教师可以教授多个课程,但一个课程只能由一个教师教授)
- 班级与学生:一对多(一个班级有多个学生,但一个学生只能属于一个班级)
- 课程与时间表:多对多(一个课程可以在多个时间段进行,一个时间段可以安排多个课程)
规范化这些关系是至关重要的,因为它影响到数据的一致性和完整性。规范化的过程需要确保每个实体都有一个主键,并且通过外键正确地关联到其他实体。
2.2 数据库表结构设计
2.2.1 表的创建和字段定义
在确定了实体及其关系后,我们可以开始设计数据库表。每个实体通常对应一个表,而实体的属性则成为表的字段。下面是一个简单的学生表创建语句示例,使用SQL语言:
- CREATE TABLE Students (
- StudentID INT PRIMARY KEY,
- Name VARCHAR(50) NOT NULL,
- Gender CHAR(1),
- DateOfBirth DATE,
- ClassID INT,
- FOREIGN KEY (ClassID) REFERENCES Classes(ClassID)
- );
在这个例子中,我们创建了一个名为Students的表,并定义了五个字段,其中StudentID作为主键确保了每个学生的唯一性,ClassID作为外键指向了班级表,实现了班级与学生之间的一对多关系。
2.2.2 主键、外键以及索引的运用
在设计表时,正确运用主键、外键以及索引是至关重要的。主键用于唯一标识表中的每一条记录,外键用于建立表之间的关联,而索引则用于提高查询效率。
索引可以为数据库中的数据检索提供极大的性能优势,特别是在大型数据库中。以下是一个为学生姓名创建索引的SQL语句示例:
- CREATE INDEX idx_student_name ON Students(Name);
通过为频繁查询的字段创建索引,可以显著减少查询所需的时间。然而,索引也不是越多越好,过多的索引会增加数据库的维护负担和存储空间的消耗。因此,合理设计索引是一个需要慎重考虑的问题。
2.3 数据库设计的规范化过程
2.3.1 第一范式到第三范式
规范化是数据库设计的一个重要过程,它通过一系列标准确保数据的组织是合理和高效的。第一范式(1NF)要求表中的每个字段都是不可分割的基本数据项,即表中的每个字段都只包含原子值。
第二范式(2NF)要求表必须先满足1NF,并且非主属性完全依赖于主键,也就是说消除部分函数依赖。
第三范式(3NF)要求表必须先满足2NF,并且消除传递依赖,即一个非主属性不依赖于其他非主属性。
规范化过程有助于减少数据冗余和提高数据一致性。但是过度的规范化可能导致查询性能下降。因此,设计师可能需要在规范化和性能之间进行权衡。
2.3.2 范式化与反范式化的权衡
在数据库设计中,范式化和反范式化是一个需要权衡的过程。范式化可以消除数据冗余,提升数据完整性;但过度范式化可能导致查询需要联合多个表,增加查询复杂度和执行时间。
反范式化则是在一些情况下为了提高性能故意引入冗余数据。例如,可以在学生表中增加一个教师姓名字段,这样在查询学生及其对应教师信息时,可以避免与教师表进行连接操作。
在实际应用中,要根据具体需求、数据更新频率以及查询模式来决定在何处进行反范式化。通常情况下,反范式化用于优化读操作,而牺牲了写操作的性能。在设计数据库时,需要综合考虑性能、维护性和扩展性,以达到最佳的设计平衡。
3. 数据库高级功能实现
在当今的信息化社会,数据库不仅是存储和管理数据的重要工具,其高级功能的实现也成为了优化数据操作、提升系统性能的关键。本章节将详细探讨数据库视图、存储过程、触发器、事务处理以及安全性设计的核心知识点和实践技巧。
3.1 视图与存储过程的应用
3.1.1 视图的设计与使用场景
视图(View)是数据库中的一个虚拟表,其内容由查询数据库而生成。视图包含一系列带有名称的列和行数据,但数据库中实际并不存在这个表,它仅仅是一个查询语句。
场景一:简化复杂查询
对于复杂查询,使用视图可以将结果集持久化,简化对这些复杂逻辑的重复调用。比如,对于一个涉及多个表联合查询的报表数据,可以将其定义为视图,然后通过简单的SELECT语句来访问。
场景二:数据的逻辑分组
企业中不同部门对数据的查看权限不同,可以将对应的数据定义为视图,只包含该部门允许看到的数据字段。这样,即使底层的数据表结构发生变化,对外展示的逻辑表也不会受到影响。
场景三:提供数据抽象层
在多层架构的应用中,视图能够提供一个数据抽象层。外部应用只需要关注视图中提供的数据,而不必了解数据背后的复杂逻辑。
代码块展示
- -- 创建一个视图的例子
- CREATE VIEW view_students AS
- SELECT student_id, student_name, student_age
- FROM students
- WHERE status = 'active';
在上述SQL语句中,我们创建了一个名为view_students的视图,其中只包含状态为’active’的学生信息。此视图简化了查询过程,可以避免每次查询时都要编写完整的筛选条件。
3.1.2 存储过程的编写和调用
存储过程是一组为了完成特定功能的SQL语句集,它们被存储在数据库中,并且可以通过名称被调用。
编写存储过程
编写存储过程的目的是将一系列操作封装起来,并且可以通过参数化的方式来重用这些操作。
调用存储过程
一旦存储过程被创建后,数据库用户可以通过CALL语句来执行它。
代码块展示
- -- 创建存储过程示例
- DELIMITER //
- CREATE PROCEDURE add_student(IN student_id INT, IN student_name VARCHAR(255))
- BEGIN
- INSERT INTO students (student_id, student_name) VALUES (student_id, student_name);
- END //
- DELIMITER ;
- -- 调用存储过程示例
- CALL add_student(1, 'Alice');
在上述SQL语句中,我们定义了一个名为add_student的存储过程,该过程接受两个参数:student_id和student_name,并使用这两个参数向students表中插入一条新记录。
存储过程的编写和调用提高了代码的复用性,并且由于在数据库服务器端执行,还可以减少网络传输的数据量,提升整体性能。
3.2 触发器和事务处理
3.2.1 触发器的创建和作用
触发器是一种特殊类型的存储过程,它会在满足特定条件时自动执行。触发器可以响应INSERT、UPDATE、DELETE等事件。
创建触发器
- DELIMITER //
- CREATE TRIGGER after_insert_student
- AFTER INSERT ON students
- FOR EACH ROW
- BEGIN
- INSERT INTO audit_log (operation, details) VALUES ('INSERT', CONCAT('New student added with ID ', NEW.student_id));
- END //
- DELIMITER ;
上述示例中创建了一个名为after_insert_student的触发器,该触发器在students表中插入新记录后执行,用于记录谁在何时插入了新学生记录。
触发器的作用
触发器通常用于:
- 自动化复杂的验证过程。
- 实施数据完整性。
- 实现安全审计和记录操作日志。
3.2.2 事务管理及隔离级别
事务是一组操作的集合,它们作为一个整体单元被提交或回滚。事务管理是数据库管理系统的核心功能之一。
事务的特性(ACID属性)
- 原子性(Atomicity):事务中的操作要么全部完成,要么全部不执行。
- 一致性(Consistency):事务必须使数据库从一个一致性状态转换到另一个一致性状态。
- 隔离性(Isolation):事务的执行不能被其他事务干扰。
- 持久性(Durability):一旦事务提交,则其所做的修改会永久保存在数据库中。
事务的隔离级别
为了平衡数据一致性与系统性能,数据库提供了不同的事务隔离级别:
- 读未提交(Read Uncommitted)
- 读已提交(Read Committed)
- 可重复读(Repeatable Read)
- 可串行化(Serializable)
代码块展示
- -- 开启事务
- START TRANSACTION;
- -- 执行一系列操作...
- -- 如果一切正常,提交事务
- COMMIT;
- -- 如果发现问题,回滚事务
- ROLLBACK;
在上述SQL语句中,我们使用了事务的开始、提交和回滚操作。合理管理事务,特别是在高并发场景下设置合适的隔离级别,对于保证数据的完整性和准确性至关重要。
3.3 数据库的安全性设计
3.3.1 用户权限管理
数据库安全性设计的核心之一是实现用户权限管理。权限管理确保了只有授权用户才能执行特定数据库操作。
权限的类型
- 数据操作权限:允许用户执行SELECT、INSERT、UPDATE、DELETE等数据操作。
- 数据库管理权限:允许用户创建和管理数据库、表、视图等。
- 资源控制权限:如文件读写权限、内存使用限制等。
权限管理的实践
- -- 创建新用户
- CREATE USER 'db_user'@'localhost' IDENTIFIED BY 'password';
- -- 授予权限
- GRANT SELECT, INSERT ON my_database.* TO 'db_user'@'localhost';
- -- 撤销权限
- REVOKE INSERT ON my_database.* FROM 'db_user'@'localhost';
- -- 删除用户
- DROP USER 'db_user'@'localhost';
在权限管理实践中,应该遵循“最小权限原则”,只给予用户完成其任务所必需的权限,并定期对权限进行审计和调整。
3.3.2 数据备份与恢复策略
为了保证数据的安全和业务的连续性,数据备份与恢复策略是不可或缺的。
备份类型
- 完全备份:备份整个数据库系统。
- 增量备份:备份自上次备份以来发生变化的数据。
- 差异备份:备份自上次完全备份以来发生变化的数据。
恢复策略
- 恢复操作应尽量模拟生产环境,避免因环境差异导致的问题。
- 在执行恢复之前,应详细检查备份的有效性和完整性。
- 在恢复后进行必要的数据验证,确保数据的一致性和完整性。
代码块展示
- -- 完全备份示例
- mysqldump -u username -p my_database > my_database_backup.sql
- -- 恢复备份示例
- mysql -u username -p my_database < my_database_backup.sql
通过合理的备份和恢复策略,即使在出现硬件故障、数据损坏、恶意攻击等严重问题时,也能确保数据的安全和业务的连续性。
以上就是本章节关于数据库高级功能实现的介绍。通过视图、存储过程、触发器、事务以及安全性设计的深入分析,我们能更好地理解并运用这些高级功能,使数据库系统的效率和安全性得到显著提升。
4. 数据库性能优化技术
数据库的性能优化是一个持续不断的过程,它涉及到从应用层到数据库层的多个方面。有效的性能优化可以显著提高数据库操作的速度,减少资源消耗,并确保系统的稳定运行。
4.1 查询优化技巧
查询优化是数据库性能调优中最为重要的环节之一。良好的查询语句设计不仅可以提高查询速度,还能有效减少服务器的资源消耗。
4.1.1 SQL查询语句的调优
为了优化SQL查询语句,首先应该尽可能减少不必要的数据检索。以下是几个关键点:
- **避免使用SELECT ***:仅选择需要的列,而不是查询所有的列。
- 减少JOIN操作:尽可能减少表的连接操作,尤其是在大表之间进行连接。
- 合理使用索引:对于经常用于过滤、排序和连接操作的列,应建立索引。
考虑下面的例子:
- SELECT * FROM students JOIN classes ON students.class_id = classes.id WHERE classes.name = 'Physics';
我们可以通过限制查询结果的列来优化该查询:
- SELECT students.id, students.name, classes.name AS class_name
- FROM students
- JOIN classes ON students.class_id = classes.id
- WHERE classes.name = 'Physics';
4.1.2 索引优化策略
索引的优化是查询性能的关键。对于经常用于查询的列,创建适当的索引至关重要。但是索引并不是越多越好,因为它们会占用额外的存储空间,并在每次数据修改时都需要更新索引,从而影响性能。
- 单一索引与复合索引:单一索引适用于单列查询优化,而复合索引则是基于多个列创建的,适用于组合查询条件。
- 索引覆盖:当查询涉及的列完全由一个索引覆盖时,查询可以直接利用索引的数据而不需要回表查询。
- 索引选择性:选择性高的列更适合建立索引,因为它们可以过滤掉更多的数据。
4.2 数据库系统配置优化
数据库系统的配置对于整体性能有着深远的影响。优化配置可以提高数据库对资源的使用效率。
4.2.1 缓存与连接池的配置
缓存是数据库优化中常见的一种技术,它通过保存经常访问的数据来减少磁盘I/O,从而提高性能。
- 查询缓存:在数据库中配置查询缓存,能够存储执行过的SQL语句和查询结果,对于完全相同的查询语句可以快速返回结果。
- 连接池:使用连接池技术可以复用数据库连接,减少频繁的建立和断开连接的开销。
4.2.2 资源分配和性能监控
合理分配数据库服务器的资源是提升性能的另一个重要方向。
- 内存分配:数据库缓存和缓冲池的大小直接影响到数据库的读写性能。
- CPU分配:根据数据库的使用模式,合理分配CPU资源,可以使用SQL语句分析工具识别并优化CPU密集型操作。
4.3 高级优化工具和方法
在数据库性能调优的过程中,除了日常的查询语句和系统配置优化外,还可以利用一些高级工具和方法。
4.3.1 分区表和并行查询
分区表是将一个大表分割成若干个小表,每个小表对应不同的存储区域。这样的设计可以提高查询效率,尤其是在处理大量数据时。
- 分区表的作用:分区表可以将数据的存储和查询分散在多个区域中,提高读写性能。
- 并行查询:利用数据库的并行查询能力,可以在多个CPU核心上同时执行查询,大幅减少查询时间。
4.3.2 案例分析:性能瓶颈诊断与解决
对真实环境下的数据库性能问题进行诊断,并找到合适的解决方案。
- 性能监控工具:介绍一些常用的性能监控工具,例如
EXPLAIN语句,它可以帮助开发者了解SQL语句的执行计划。 - 案例演示:详细分析一个具体的性能问题,并展示如何通过分析和优化解决该问题。
以下是性能监控工具的一个简单示例:
- EXPLAIN SELECT * FROM students WHERE age > 18;
执行上述命令后,数据库会返回关于查询的详细执行计划,如下所示:
- +----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
- +----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
- | 1 | SIMPLE | students | NULL | index | NULL | age_idx | 4 | NULL | 100 | 100.00 | NULL |
- +----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
在本示例中,Extra列显示NULL,表示没有使用额外的条件进行过滤。如果没有合适的索引,type列可能会显示为ALL,这表示进行了全表扫描,这通常意味着需要优化查询或添加索引。
通过对查询语句、数据库配置和性能监控工具的深入理解和应用,可以显著提升数据库系统的性能表现。这不仅要求数据库管理员对数据库系统有深入的理解,还需要不断地测试和监控,以确保数据库运行在最佳状态。
5. 实践案例分析与故障排除
5.1 排课系统数据库实例
5.1.1 系统架构和数据库部署
排课系统通常需要支持高并发读写操作,以及强大的数据处理能力。系统架构可以分为前端展示层、业务逻辑层和数据持久层。在部署数据库时,通常会采用主从复制、读写分离的方式来提高系统的可用性和扩展性。
在数据库部署方面,需要考虑的因素包括:
- 数据库服务器的硬件配置:CPU、内存、存储等。
- 操作系统的优化设置,如文件系统的类型、网络参数等。
- 数据库软件的选择和配置,例如使用MySQL、PostgreSQL或Oracle等。
以下是一个简化的数据库部署步骤:
- 准备数据库服务器。
- 安装数据库软件。
- 配置数据库参数文件,如
my.cnf或postgresql.conf。 - 设置字符集、时区和语言环境。
- 创建数据库实例,并配置主从复制。
- 实施读写分离策略,配置负载均衡。
5.1.2 关键功能实现与性能测试
在排课系统中,关键功能可能包括:
- 自动排课算法,用以平衡教师和教室资源。
- 课程表的生成和查询。
- 修改和删除课程安排的接口。
为了确保关键功能的性能,需要进行压力测试和性能评估。性能测试的步骤包括:
- 使用模拟用户工具(如JMeter、Locust)生成并发访问。
- 监控数据库的响应时间和资源使用情况。
- 根据测试结果调整数据库配置和应用代码。
- 实施SQL查询优化和索引调整。
- 反复测试直到满足性能要求。
5.2 常见问题诊断与解决
5.2.1 问题收集和分析方法
在排课系统运行过程中,可能会遇到各种性能瓶颈或故障。问题收集和分析的方法通常包括:
- 使用日志文件记录和分析错误信息。
- 开启数据库的慢查询日志,定位效率低下的SQL。
- 利用数据库管理系统自带的监控工具,如MySQL的
Performance Schema。 - 利用第三方监控工具进行应用和数据库的实时监控。
在收集问题后,应遵循以下步骤进行分析:
- 从时间轴上定位问题发生的时刻。
- 查看相关日志文件,确认错误类型。
- 使用查询分析工具找出资源消耗大的查询。
- 分析系统负载和数据库的系统状态。
5.2.2 故障排除案例分享
假设排课系统在下午5点到6点之间出现了性能急剧下降的情况。通过查看慢查询日志,发现了一个复杂的JOIN操作导致了查询时间过长。根据日志中的执行计划,我们发现涉及到的表没有有效索引。
排除故障的步骤如下:
- 评估该查询对业务的影响,如果影响较小,可以暂时从查询计划中移除。
- 在表上创建合适的索引以优化查询。
- 重新运行查询并监控执行时间。
- 如果问题依然存在,进一步检查表的锁定情况和系统资源使用情况。
- 与开发团队沟通,考虑调整数据模型或查询逻辑,以提高效率。
通过上述步骤,可以有效地定位和解决问题,确保排课系统的稳定性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
Cygwin系统监控指南:性能监控与资源管理的7大要点
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
【T-Box能源管理】:智能化节电解决方案详解
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
【精准测试】:确保分层数据流图准确性的完整测试方法
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















