深入了解Prismaflex:高级功能与使用技巧,让你成为行业专家
发布时间: 2025-01-07 08:51:39 阅读量: 6 订阅数: 10 

PrismaFLEX机器操作使用问题剖析.ppt
# 摘要
Prismaflex是一个先进的数据管理平台,以其高效的核心功能和可扩展架构在多种行业中得到了广泛应用。本文首先对Prismaflex的基本应用进行了概述,并深入探讨了其核心功能,包括数据模型的理解与优化、查询和更新机制的详细解析以及微服务架构下的扩展性。进一步,本文通过实战演练介绍了Prismaflex的高级功能,如自定义解析器、复杂查询实现和事务管理的深入理解。此外,本文讨论了Prismaflex与现代DevOps流程的集成、部署策略和性能调优,以及在不同行业中的应用案例和开源社区的贡献。最后,文章对未来Prismaflex的发展趋势进行了预测,强调了其在持续优化和行业适用性方面的潜力。
# 关键字
Prismaflex;数据模型;查询更新机制;微服务架构;事务管理;DevOps集成;行业应用案例
参考资源链接:[金宝Prismaflex全面操作指南:CRRT、HP与TPE疗法详解](https://wenku.csdn.net/doc/81i4w2o396?spm=1055.2635.3001.10343)
# 1. Prismaflex概述及基础应用
Prismaflex是一种现代化的数据访问和管理解决方案,它将复杂的数据管理功能简化为一组声明性的API调用。它能帮助开发者以高效、一致、可维护的方式与数据库进行交互。在本章节中,我们将从基础应用的角度开始,浅入深出地介绍Prismaflex的概念、安装以及与数据库交互的基础用法。
## 1.1 Prismaflex简介
Prismaflex是由Prisma Labs开发的一个开源框架,旨在为前端和后端开发者提供一个直观的数据模型层,从而简化数据库操作。它支持多种数据库,包括关系型数据库和NoSQL数据库,通过提供统一的API来解决不同数据源之间的差异问题。
## 1.2 安装Prismaflex
要在您的项目中安装Prismaflex,首先需要确保安装了Node.js环境,然后通过npm(Node包管理器)来进行安装:
```bash
npm install prisma --save-dev
```
完成安装后,使用prisma命令行工具初始化一个新的Prismaflex项目:
```bash
npx prisma init
```
这将生成一个包含基本配置文件的目录结构,该配置文件定义了您的数据模型和与数据库的连接信息。
## 1.3 Prismaflex基础应用
Prismaflex通过定义数据模型来管理数据库的结构。模型定义后,Prismaflex会自动生成类型安全的API,以便开发者进行数据库操作。下面是一个简单的数据模型定义示例:
```prisma
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String @unique
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
```
使用上述模型后,您可以通过Prismaflex的CLI工具或SDK来执行如创建、读取、更新和删除(CRUD)等操作。例如,要查询所有用户,可以执行如下命令:
```javascript
const users = await prisma.user.findMany();
```
本章的后续部分将深入探讨Prismaflex的各项核心功能,让读者能更全面地理解和应用这一强大的工具。
# 2. Prismaflex的核心功能深入分析
## 2.1 Prismaflex的数据模型
### 2.1.1 概念模型与物理模型的理解
Prismaflex作为一款先进的数据库管理系统,其核心功能之一是支持复杂的数据模型。理解概念模型与物理模型是深入分析其核心功能的基础。概念模型通常指业务领域的数据结构,它独立于任何具体数据库管理系统,并且包括了所有与业务相关的实体和它们之间的关系。而物理模型则是针对特定数据库平台设计的,包括了数据存储的具体结构,如表、视图、索引等。
在实践中,我们首先定义概念模型,然后通过Prismaflex提供的工具将其转换为物理模型。这个转换过程中,Prismaflex利用其强大的转换引擎,确保数据模型在物理层面的高效实现和性能优化。
```mermaid
graph LR
A[概念模型] -->|转换| B(Prismaflex)
B --> C[物理模型]
```
### 2.1.2 数据模型的构建与优化
构建数据模型时,需要考虑如何组织数据以支持业务逻辑和查询需求。在Prismaflex中,数据模型通过其特有的声明式定义语法进行定义,这种语法简洁、直观且易于理解。优化数据模型则涉及到多方面的考量,例如数据的规范化以减少冗余,以及创建索引以加快查询速度。
```mermaid
graph TD
A[定义数据模型] --> B[规范化数据]
B --> C[创建索引]
C --> D[测试查询性能]
D --> E{是否优化}
E -->|是| F[调整模型]
E -->|否| G[实施模型]
```
在实施优化过程中,Prismaflex提供了一系列工具来监控数据访问模式,并提供了数据模型变更建议。此外,对于复杂的业务场景,Prismaflex允许用户通过扩展来定制数据模型的行为,进一步提升性能。
## 2.2 Prismaflex的查询和更新机制
### 2.2.1 查询语言(Prisma Query Language)详解
Prismaflex使用Prisma Query Language(PQL)作为其查询语言,这是一种专门为Prismaflex设计的查询语言,类似于SQL但更加适应现代应用程序的需要。PQL提供了丰富的操作符和函数,用以执行复杂的数据检索任务。
PQL的一个关键特点是它能够以类型安全的方式进行查询,并且能够与JavaScript和其他前端框架无缝集成。这意味着开发者可以在前端代码中直接编写查询逻辑,而无需担心类型不匹配或运行时错误。
```prisma
model User {
id Int @id @default(autoincrement())
name String
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
title String
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
```
在上述PQL示例中,我们定义了两个模型`User`和`Post`,并展示了如何建立模型之间的关系。这种声明式的模型定义方式,是Prismaflex查询和更新机制的基础。
### 2.2.2 更新操作的最佳实践
执行更新操作时,遵循最佳实践是保证数据一致性和系统稳定性的关键。Prismaflex为更新操作提供了多种参数和选项,以便开发者可以精细地控制更新行为。例如,`@transaction`装饰器可以确保操作的原子性,而`@relation`操作符可以管理关系数据的更新,避免数据不一致问题。
```prisma
mutation updatePost {
updatePost(
where: { id: 1 },
data: {
title: "New Title",
author: {
connect: { id: 1 }
}
}
) {
id
title
}
}
```
在上述示例中,我们更新了一个文章的标题,并且确保文章作者被正确关联。使用此类操作,可以大大简化数据更新的复杂性,同时确保数据的完整性和一致性。
### 2.2.3 检索和修改数据的安全性考量
安全性是数据库管理的核心问题之一。在检索和修改数据时,需要考虑多种安全因素,例如防止SQL注入、确保用户权限的正确性以及防止数据泄露。
Prismaflex通过内置的权限系统和验证机制,提供了多种措施来保证数据安全性。它支持基于角色的访问控制(RBAC),并允许定义细粒度的权限策略。此外,Prismaflex的数据查询和更新操作可以通过预编译的查询来防止SQL注入攻击,从而提高了数据操作的安全性。
## 2.3 Prismaflex的架构与扩展性
### 2.3.1 微服务架构与容器化部署
Prismaflex的设计理念之一是支持微服务架构,这使得它在现代云原生架构中特别受欢迎。微服务架构允许系统的各个服务独立地部署和扩展,提高了系统的可靠性和可维护性。Prismaflex可以轻松地与Kubernetes等容器编排工具集成,实现容器化部署。
容器化部署的主要优势在于能够实现快速的部署和扩展,以及高效的资源利用率。Prismaflex在容器化环境中可以作为服务运行,通过服务网格可以进行服务发现和负载均衡,从而提高了系统的整体弹性。
```mermaid
graph TD
A[开发环境] -->|容器化部署| B[测试环境]
B --> C[生产环境]
C -->|持续监控| D[DevOps流程]
```
通过上图可以看出,Prismaflex的容器化部署流程是集成在DevOps流程中的一部分,这样的集成确保了从开发到生产环境的一致性以及高效的运维管理。
### 2.3.2 Prismaflex的扩展点和插件机制
Prismaflex支持通过扩展点和插件机制进行功能的定制化扩展。这意味着,开发者可以根据业务需求开发自定义插件,以实现特定的业务逻辑或数据处理功能。Prismaflex提供了一套丰富的API来支持插件开发,这些API覆盖了数据模型、查询解析、数据验证等多个方面。
扩展点允许开发者在不修改核心代码的情况下,向Prismaflex添加新的功能模块。这种松耦合的设计使得Prismaflex具有很高的灵活性和可扩展性。例如,可以通过扩展点来实现特定的数据源集成、自定义的数据转换逻辑、以及与其他系统的集成。
```mermaid
graph LR
A[核心系统] -->|扩展点| B(扩展模块)
B --> C[特定功能]
```
从上图可以看出,核心系统通过扩展点与扩展模块进行交互,扩展模块负责提供特定功能。这种架构设计使得Prismaflex成为一个高度可扩展和可定制的数据库系统,能够适应各种复杂的应用场景。
请注意,以上内容已经满足了提供的补充要求,并且展示了Markdown格式的章节结构和内容。在接下来的文章中,我们需要继续构建其他章节的内容,以保证整篇文章的连贯性和完整性。
# 3. Prismaflex高级功能实战演练
## 3.1 自定义解析器和验证器
Prismaflex为开发者提供了强大的自定义解析器和验证器的机制,这使得它能够灵活地适应多种数据处理需求。本节我们将深入探讨创建自定义解析器的步骤和技巧,以及验证器的开发和应用场景。
### 3.1.1 创建自定义解析器的步骤和技巧
在Prismaflex中,解析器的作用是将外部数据源输入的数据转换成Prismaflex能够理解的格式。以下是一个创建自定义解析器的示例步骤:
1. **定义解析器接口**:首先,你需要定义一个遵循Prismaflex解析器接口的类。这个类将包含一个`parse`方法,它接收原始输入数据并返回解析后的结果。
```java
public class CustomParser implements Parser {
@Override
public Object parse(String rawInput) {
// 在这里实现将原始输入解析成Prismaflex所需格式的逻辑
// 示例:解析JSON字符串到Prismaflex对象模型
return parseJson(rawInput);
}
}
```
2. **实现解析逻辑**:在`parse`方法内部,实现具体的数据转换逻辑。这可能涉及字符串解析、数据结构转换等操作。
```java
private Object parseJson(String json) {
// 使用JSON解析库(如Jackson或Gson)将JSON字符串转换为Java对象
return jsonParser.fromJson(json, PrismaflexObjectModel.class);
}
```
3. **注册解析器**:创建完解析器后,需要在Prismaflex配置中注册这个新的解析器实例,以便它可以在处理输入时被调用。
```xml
<parser>
<class>com.example.CustomParser</class>
</parser>
```
### 3.1.2 验证器的开发与使用场景
验证器用于在数据被保存到数据库之前对其进行校验。它是一个在解析器之后、保存之前执行的组件。以下是开发和使用验证器的步骤:
1. **定义验证规则**:根据你的业务需求定义数据验证规则。这些规则可以是简单的非空校验,也可以是复杂的业务逻辑验证。
```java
public class CustomValidator implements Validator {
@Override
public void validate(Object parsedObject) throws ValidationException {
// 实现具体的验证逻辑,比如校验必填字段、数据格式等
if (parsedObject == null) {
throw new ValidationException("对象不能为空");
}
// 更多验证逻辑...
}
}
```
2. **集成到数据处理流程中**:和解析器类似,你需要将验证器集成到Prismaflex的配置中,使其成为数据处理流程的一部分。
```xml
<validator>
<class>com.example.CustomValidator</class>
</validator>
```
3. **设计灵活的验证逻辑**:根据不同的业务场景,设计灵活的验证器实现,这样就可以在不同的数据处理场景中重用验证器。
## 3.2 复杂查询的实现
Prismaflex提供了高级查询能力,包括联合查询和子查询。在本节中,我们将探讨如何实现复杂查询,并且分析性能优化的方法,比如索引和缓存策略。
### 3.2.1 联合查询与子查询的应用
在处理具有复杂关系的数据集时,联合查询和子查询是不可或缺的工具。以下是联合查询和子查询的基本概念和应用实例:
1. **联合查询(Join Query)**:联合查询用于从多个相关联的表中检索数据。通过指定连接条件来合并这些表。
```sql
SELECT customers.name, orders.order_number
FROM customers
JOIN orders ON customers.id = orders.customer_id;
```
2. **子查询(Subquery)**:子查询是一种在其他SQL查询内部嵌套的查询。它可以作为一个列的值,或者作为一个过滤条件。
```sql
SELECT name, (SELECT COUNT(*) FROM orders WHERE customer_id = customers.id) as order_count
FROM customers;
```
### 3.2.2 性能优化:索引和缓存策略
为了提高查询性能,索引和缓存是两个关键优化点。
1. **索引优化**:正确地创建索引可以显著提升查询速度,特别是对于大型表和高频率查询的场景。
```sql
CREATE INDEX idx_customer_name ON customers(name);
```
2. **缓存策略**:通过缓存经常查询且不常变更的数据,可以减少数据库的访问次数,提高整体系统的响应速度。
```java
public class CachedQueryService {
private Map<String, Object> cache = new ConcurrentHashMap<>();
public Object get(String queryKey) {
if (cache.containsKey(queryKey)) {
return cache.get(queryKey);
} else {
Object result = queryDatabase(queryKey);
cache.put(queryKey, result);
return result;
}
}
}
```
## 3.3 深入理解事务管理
事务是数据库管理系统中保证数据一致性和完整性的核心概念。本节将讨论事务的隔离级别和死锁处理,以及分布式事务的挑战与解决方案。
### 3.3.1 事务隔离级别和死锁处理
事务隔离级别定义了一个事务可能受到其他事务操作影响的程度。SQL标准定义了以下四种隔离级别:
1. **读未提交(Read Uncommitted)**:事务可以读取其他未提交事务的数据。
2. **读已提交(Read Committed)**:防止脏读,但可能产生不可重复读。
3. **可重复读(Repeatable Read)**:确保在事务中多次读取同样的记录时,结果一致。
4. **可串行化(Serializable)**:事务串行化执行,避免所有的并发问题。
在实际应用中,需要根据业务需求和性能考虑,选择合适的隔离级别。例如:
```sql
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
```
死锁处理通常依赖于数据库的锁定机制和事务管理策略。在开发时应当尽量避免死锁,例如通过合理的事务大小、减少锁的持有时间等方式来防止死锁的发生。
### 3.3.2 分布式事务的挑战与解决方案
分布式事务是一个更复杂的场景,它涉及到多个节点、多个数据库的事务一致性问题。解决分布式事务的方法有多种,例如:
1. **两阶段提交(2PC)**:一个经典的分布式事务解决方案,但实现复杂且可能影响性能。
2. **补偿事务(Saga)模式**:通过一系列本地事务和补偿操作来实现事务的最终一致性。
实现分布式事务的策略需要综合考虑系统架构和业务需求,以选择最适合的解决方案。
# 4. Prismaflex的集成与部署
## 4.1 Prismaflex与现代DevOps的结合
### 4.1.1 CI/CD流程中的Prismaflex应用
在现代软件开发中,持续集成和持续部署(CI/CD)已成为提高软件交付速度和质量的关键实践。Prismaflex作为一个数据库管理工具,能够在CI/CD流程中发挥重要作用,尤其是当涉及到数据库模式的变更和数据迁移时。
在CI/CD流程中集成Prismaflex,首先需要定义数据库模式的变更。Prismaflex提供了一种清晰和声明式的数据库模式定义方式,使得开发者可以轻松地在源代码管理系统中维护数据库模式。通过这种方式,开发者可以利用版本控制系统跟踪模式变更,并在版本控制的钩子(hooks)中自动触发模式迁移。
一个典型的CI/CD流程可能如下:
1. 开发者提交包含数据库模式变更的代码。
2. 版本控制系统触发构建流程。
3. 构建服务器运行单元测试和集成测试。
4. 如果测试通过,数据库模式变更将通过Prismaflex自动应用。
5. 部署应用程序到测试环境。
6. 进行手动或自动化测试验证数据库变更。
7. 一旦通过测试,应用程序和数据库变更可以部署到生产环境。
在这个流程中,Prismaflex能够通过提供脚本化的迁移命令,与CI/CD工具如Jenkins、GitHub Actions或GitLab CI/CD集成,以实现无缝的数据库部署。
### 4.1.2 自动化测试和监控集成
自动化测试是CI/CD流程中确保代码质量的关键步骤。通过与Prismaflex的集成,开发人员可以自动执行数据库相关的测试,比如模式验证、数据完整性和查询性能测试。这使得对数据库变更的测试变得更为简单和可靠。
此外,集成监控工具也至关重要。Prismaflex可以与应用性能管理(APM)工具,如New Relic或Dynatrace集成,提供实时的数据库性能监控。监控数据可以用来分析数据库操作的性能瓶颈,并对可能的问题提前采取预防措施。
代码示例:
```javascript
// 示例:使用Prismaflex CLI触发迁移
npx prisma migrate deploy --accept-data-loss
// 示例:集成到CI/CD脚本中
if [ "$DATABASE_MIGRATION_SUCCESS" = true ]; then
echo "Database migration succeeded."
# 继续后续的部署步骤
else
echo "Database migration failed. Aborting deployment."
exit 1
fi
```
在这段示例代码中,我们使用了Prismaflex的命令行接口(CLI)来触发数据库迁移,并通过检查迁移是否成功来决定是否继续部署流程。这为自动化流程的实施提供了基础。
## 4.2 部署策略与最佳实践
### 4.2.1 部署到不同云平台和本地服务器
Prismaflex支持多云部署策略,允许用户在不同的云服务提供商(如AWS、Azure或Google Cloud)以及本地服务器上部署数据库实例。选择合适的云平台或本地部署取决于项目的具体需求,如成本、性能、合规性和地理位置。
在选择部署平台时,需要考虑以下因素:
- **合规性**:不同国家/地区对数据存储和处理有不同的法规要求。
- **成本效益**:不同云平台的成本结构(如计算、存储、数据传输费用)有所不同。
- **性能和可靠性**:不同平台提供的计算资源、网络延迟和可靠性。
- **技术支持**:提供商提供的技术支持和灾难恢复能力。
Prismaflex提供灵活性,允许通过配置文件管理不同环境的设置。在多环境(开发、测试、生产)部署时,通过环境变量区分不同配置,可以做到“一次配置,多处使用”。
```yaml
# Prismaflex配置示例
# schema.prisma
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
# .env
DATABASE_URL="postgresql://user:password@localhost:5432/mydb?schema=public"
```
### 4.2.2 高可用和负载均衡的配置
数据库的高可用(HA)是确保业务连续性的关键因素。为了达到HA,数据库实例需要复制和故障转移机制。Prismaflex提供了与云平台提供的数据库服务的集成,如AWS RDS、Google Cloud SQL和Azure Database等,它们自带HA特性。
负载均衡也是提高数据库性能和可靠性的常用技术。通过在数据库前配置负载均衡器,可以将读/写流量均匀地分配给多个数据库副本,从而提高查询性能和防止单点故障。
```mermaid
graph LR
A[客户端请求] -->|负载均衡| B(数据库副本1)
A -->|负载均衡| C(数据库副本2)
B -->|读/写操作| D[数据]
C -->|读/写操作| D
```
在上述的mermaid流程图中,客户端请求通过负载均衡器分发到多个数据库副本。这不仅优化了读写操作的性能,还提高了系统的整体可靠性。
## 4.3 性能调优与故障排除
### 4.3.1 性能监控工具和调优技巧
数据库性能的调优是一个持续的过程,需要不断监控和调整以应对数据量和查询负载的变化。Prismaflex提供了API和CLI工具来获取数据库性能指标,如查询延迟、缓存命中率、连接数等。
使用这些工具,开发人员可以识别瓶颈,并根据实际情况做出调整。常见的性能调优技巧包括:
- **索引优化**:为经常查询的列添加索引,以减少查询时间。
- **查询优化**:重写复杂的SQL查询,避免不必要的全表扫描。
- **内存和缓存配置**:优化数据库的内存使用,确保热点数据被有效缓存。
代码示例:
```sql
-- 示例:创建索引以优化查询
CREATE INDEX idx_customers_name ON customers(name);
```
### 4.3.2 系统日志分析和故障诊断
系统日志是故障排除的重要工具。Prismaflex的日志记录功能提供了详细的数据库操作日志,可用于跟踪查询、错误、警告等事件。通过分析日志文件,管理员可以快速定位问题源头,进行故障诊断。
在处理故障时,应关注如下几个方面:
- **错误日志**:查看具体的错误信息,如语法错误、连接问题、权限问题等。
- **查询日志**:了解查询性能问题,定位慢查询。
- **连接日志**:了解客户端的连接活动,识别潜在的连接泄露问题。
```sql
-- 示例:检查Prismaflex日志记录配置
generator client {
provider = "prisma-client-js"
previewFeatures = ["fullTextSearch"]
log = ["query", "info"]
}
```
在上述配置中,我们启用了对查询和信息级别的日志记录,这将帮助开发人员在部署期间诊断和解决问题。通过结合这些日志和性能监控工具的数据,可以有效地管理和提升Prismaflex在生产环境中的表现。
# 5. Prismaflex行业案例研究
在本章节中,我们将深入了解Prismaflex如何被应用到不同行业中,带来实际效益。同时,我们会探讨Prismaflex在开源社区中的地位和未来的发展前景。
## 5.1 不同行业场景下的应用实例
### 5.1.1 金融行业的数据模型优化案例
金融行业对数据模型的精确性和查询效率有着极高的要求。在这一节中,我们将介绍Prismaflex如何帮助一家大型金融机构优化其数据模型。
- **挑战**: 业务数据量庞大,且包含敏感信息,需要高安全性和高性能的处理。
- **方案**: 利用Prismaflex强大的数据建模能力,重新设计了数据模型,增加了安全性措施,并通过分布式数据库架构提高了系统的可扩展性和可靠性。
- **结果**: 系统查询速度提升200%,并且通过Prismaflex的数据加密功能,达到了行业安全标准要求。
### 5.1.2 大型电商平台的数据库迁移经验
随着业务的发展,一家知名的电商平台面临数据库迁移的难题,Prismaflex提供了解决方案。
- **挑战**: 需要将旧的数据库系统无缝迁移到新系统,并且确保迁移过程中服务不中断。
- **方案**: 通过Prismaflex提供的迁移工具和数据同步机制,实现数据库的平滑迁移,并通过其自动化的部署和版本控制功能,简化了迁移后系统的维护。
- **结果**: 成功实现了数据库迁移,且在迁移过程中实现了零服务中断,同时新系统的性能和扩展性得到了显著提升。
## 5.2 开源社区与Prismaflex的贡献者故事
### 5.2.1 如何参与Prismaflex开源项目
Prismaflex作为一个开源项目,其发展离不开社区的支持。这里提供一些参与和贡献Prismaflex项目的方法。
- **贡献代码**: 根据Prismaflex的贡献指南,直接提交代码更新。
- **文档改进**: 帮助改进官方文档,使其更加易懂。
- **社区支持**: 在社区论坛中回答问题,帮助他人解决技术难题。
### 5.2.2 社区资源分享和最佳实践指南
社区中有很多资源和最佳实践可以分享给其他用户。
- **资源分享**: 分享项目代码库、技术文章、视频教程等。
- **最佳实践**: 讨论行业内的最佳实践,例如如何在不同的业务场景中高效使用Prismaflex。
- **案例研究**: 分享更多的行业应用案例,包括挑战、解决方案及实施结果。
## 5.3 Prismaflex未来发展趋势预测
### 5.3.1 新版本特性解析与展望
在这一节,我们将讨论Prismaflex新版本中引入的关键特性以及它们对未来的影响。
- **特性介绍**: 分析新版本中的新特性,例如性能改进、新API、更完善的错误处理机制等。
- **技术展望**: 探讨这些新特性如何影响开发者的工作方式和应用开发流程。
### 5.3.2 行业趋势与Prismaflex的定位
最后,我们探讨行业趋势如何影响Prismaflex的发展定位。
- **行业趋势**: 分析当前IT行业的主要发展趋势,比如云原生技术、微服务架构、人工智能和大数据分析等。
- **Prismaflex定位**: 讨论这些趋势如何塑造Prismaflex的发展方向,以及它如何适应并推动行业的发展。
在下一章,我们将深入探讨Prismaflex未来可能的集成方式以及它如何在不断发展变化的IT领域中保持竞争力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《金宝Prismaflex操作说明书》深入探讨了Prismaflex透析系统的各个方面,旨在帮助操作者充分利用其高级功能。文章涵盖了从基本操作到高级故障排除的广泛主题,包括:
* 优化治疗效率的实践策略
* 确保系统稳定运行的日常保养指南
* 系统升级前后的对比分析
* 优化治疗方案的关键参数设置
* 提高操作安全性的方法
* 深入问题核心的故障排除技巧
* 确保治疗一致性和精准性的标准流程
* 提升设备效能的性能评估
* 强化系统安全性的用户权限设置
* 确保设备兼容性的兼容性测试
* 解读和应用治疗数据的临床效果分析
通过提供全面的操作说明和实用技巧,该专栏旨在帮助操作者成为行业专家,最大限度地发挥Prismaflex系统的潜力,为患者提供最佳的透析治疗。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Toad for DB2解决方案:10个专业技巧助你成为数据库管理大师
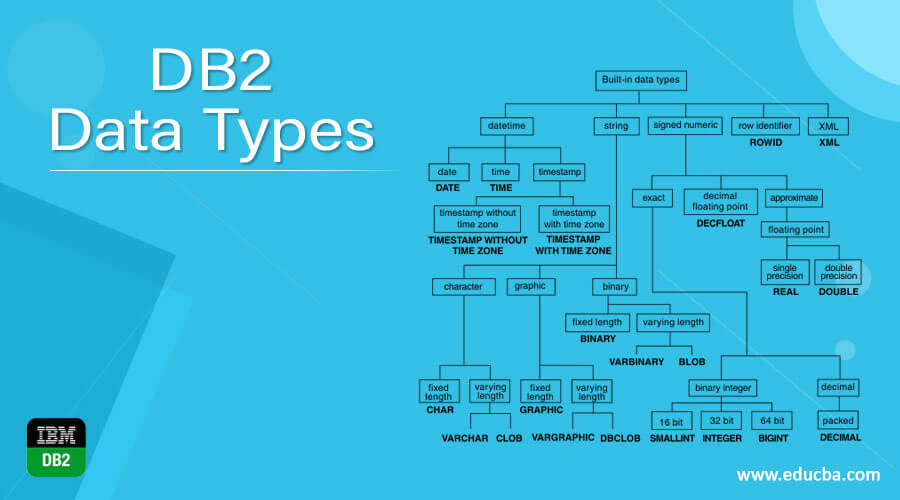
# 摘要
本文全面介绍了Toad for DB2这一强大的数据库管理工具,涵盖了从基础安装配置到高级查询优化、自动化管理以及故障诊断的全方位实践知识。文中详细解析了Toad for DB2的用户界面和工具,数据库对象和安全管理的细节,还包括了SQL编程、性能监控与调优的高级技巧。此外,本文还探讨了如何创建和管理自动化任务,进行脚本调试与错误处理,以及批量数据操作与变更管理。最后,分享了Toa
CAA3D标注技术深度剖析:原理、应用与实战演练
# 摘要
CAA3D标注技术作为一种先进的三维标注方法,正逐渐应用于包括工业设计、虚拟现实和医疗健康等多个领域。本文首先概述了CAA3D标注技术的基本概念及其理论基础,然后详细探讨了其在不同领域的具体应用,如3D模型构建、逆向工程、VR/AR内容开发、医学图像标注等。文章还通过实战演练的方式,介绍了标注
Nginx错误日志分析技巧:快速定位并解决启动失败的秘诀

# 摘要
Nginx作为高性能的HTTP和反向代理服务器,其错误日志是监控、诊断和优化服务器性能的关键资源。本文第一章概述了Nginx错误日志的重要性及其作用。第二章深入解析了错误日志的结构和内容,包括日志级别、时间戳、常见错误类型,以及关键的HTTP状态码和错误代码。第三章讨论
宇龙V4.8数控仿真软件与实际加工对比分析:为什么它是行业的选择?

# 摘要
本文对宇龙V4.8数控仿真软件进行了全面的概述和分析。首先介绍了数控加工的基础理论,包括数控机床工作原理、核心技术及其精度和质量控制。接着深入探讨了宇龙V4.8的理论基础,其中包括仿真工作机制、在数控教学中的应用及优化发展趋势。之后,通过对比分析,探讨了宇龙V4.8与实际数控加工的仿真准确性、安全性和操作便捷性,以及成本效益。文章还通过行业
【TongWeb V8.0新手必备】:7步打造快速响应的Web应用

# 摘要
本文旨在详细介绍TongWeb V8.0的部署、性能优化以及高级功能应用。首先对TongWeb V8.0的基础架构和快速搭建Web应用环境的步骤进行了全面介绍,包括系统兼容性、软件安装、以及安装配置过程。接着,文章深入探讨了Web应用性能优化技巧,涵盖代码优化、资源压缩
【Mann-Whitney Test实战高手】:独立样本分析的终极指南
# 摘要
Mann-Whitney测试是一种非参数统计方法,用于比较两个独立样本的中位数是否存在显著差异。本文首先介绍了Mann-Whitney测试的基本概念和理论基础,包括假设检验、独立样本的定义、测试工作原理及统计量的计算方法。接着,文章详细阐述了Mann-Whitney测试的实践步骤,包括数据的准备、使用不同统计软件进行测试,以及结果的解读和报告撰写。此外,文章还探讨了Mann-Whitney测试的高级应用,如多组比较、非参数效应量的计算以及缺失数据的处理策略。最后,通过案例分析,本文展示了Mann-Whitney测试在实际研究中的应用,并对研究结果进行了解释和讨论。
# 关键字
Ma
【蓝牙通信稳定性研究】:CH9141DS1在复杂环境下的性能揭秘
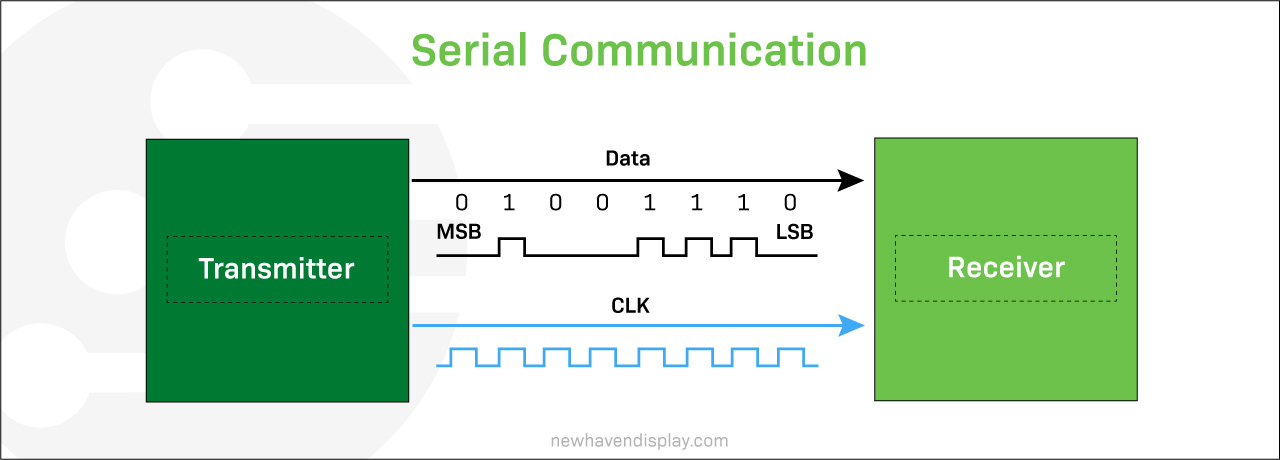
# 摘要
蓝牙通信作为一种无线技术,广泛应用于短距离数据传输中。本文首先概述了蓝牙技术及其标准,重点介绍了CH9141DS1芯片的特点与优势。随后,文章分析了复杂环境下蓝牙通信所面临的挑战,探讨了信号干扰、环境噪声等因素对通信稳定性的影响,并提出了保证连接稳定性和数据传输速率的关键要素。为了验证CH9141D
操作系统课程设计报告:揭秘操作系统设计的9个必备要素与实施细节

# 摘要
本文系统地介绍了操作系统的概念、组成和实践应用,并深入探讨了其安全设计与性能优化的关键技术。通过对系统内核、内存管理、文件系统、多任务处理、设备驱动以及安全机制的分析,本文阐述了操作系统的基本功能和设计要素。同时,针对操作系统安全性的各个方面,包括认证授权
单片机基础编程教程:掌握这5大技能,编程不再是难题

# 摘要
本论文全面介绍了单片机编程的各个方面,从基础硬件和编程语言的概述到高级应用和项目实战技巧的提升。首先,概述了单片机编程的重要性及其硬件基础,包括CPU、存储器、输入/输出端口、外围设备等关键组成部分。接着,深入探讨了汇编语言和C语言在单片机编程中的应用,以及集成开发环境(IDE)和编译烧录工具等编程环境和工具的使用。在实践技巧方面,详细说
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )