深入了解iptables链与策略
发布时间: 2023-12-16 14:08:43 阅读量: 64 订阅数: 23 

超详细的iptables设置
# 章节一:iptables简介与基本概念
## 1.1 iptables是什么?
iptables是Linux操作系统上用于配置和管理防火墙规则的工具,它能够监控数据包并决定它们的去向,从而实现网络流量的控制和过滤。
## 1.2 iptables的基本工作原理
iptables基于规则集(ruleset)来决定如何处理网络数据包,当数据包到达网络设备时,iptables会根据预先定义的规则来决定是允许还是拒绝数据包的传输,同时也能对数据包进行一些修改。
## 1.3 iptables链的概念与分类
iptables的规则被组织成不同的链,每个链都有特定的功能和作用。主要的链包括INPUT链(处理进入本地系统的数据包)、OUTPUT链(处理从本地系统发出的数据包)和FORWARD链(处理通过本地系统转发的数据包)等。
## 章节二:iptables链详解
iptables是一个非常强大的Linux防火墙工具,其核心功能是根据预定义的规则集对网络数据包进行过滤和转发。iptables通过一系列的规则链(chains)来实现对网络数据包的处理。本章节将深入介绍iptables的几种常用链,包括INPUT链、OUTPUT链和FORWARD链。
### 2.1 INPUT链的作用与配置
INPUT链是iptables默认的入站链,用于处理进入系统的数据包。通过对输入数据包进行过滤和转发,可以实现对进入系统的网络连接进行控制。以下是一个基本的INPUT链配置示例:
```bash
iptables -A INPUT -s 192.168.1.0/24 -p tcp --dport 22 -j ACCEPT
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT -j DROP
```
上述配置示例中,第一条规则允许来自192.168.1.0/24网段的主机通过SSH(端口号22)进行连接;第二条规则允许已建立或相关的连接通过;最后一条规则将其他未匹配的数据包丢弃。
### 2.2 OUTPUT链的作用与配置
OUTPUT链是iptables默认的出站链,用于处理从系统发送出去的数据包。通过对输出数据包进行过滤和转发,可以实现对从系统发送出去的网络连接进行控制。以下是一个基本的OUTPUT链配置示例:
```bash
iptables -A OUTPUT -d 192.168.2.0/24 -p tcp --dport 80 -j ACCEPT
iptables -A OUTPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A OUTPUT -j DROP
```
上述配置示例中,第一条规则允许向192.168.2.0/24网段的主机发送HTTP(端口号80)请求;第二条规则允许已建立或相关的连接通过;最后一条规则将其他未匹配的数据包丢弃。
### 2.3 FORWARD链的作用与配置
FORWARD链用于对通过系统进行转发的数据包进行控制。当系统作为路由器或网关时,数据包需要经过FORWARD链进行转发。以下是一个基本的FORWARD链配置示例:
```bash
iptables -A FORWARD -s 192.168.1.0/24 -d 192.168.2.0/24 -p tcp --dport 443 -j ACCEPT
iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A FORWARD -j DROP
```
上述配置示例中,第一条规则允许来自192.168.1.0/24网段的主机向192.168.2.0/24网段的主机发送HTTPS(端口号443)请求;第二条规则允许已建立或相关的连接通过;最后一条规则将其他未匹配的数据包丢弃。
## **章节三:iptables策略管理**
在本章中,我们将深入探讨iptables策略管理的相关内容,包括管理与配置iptables策略、策略的优先级与匹配规则,以及常见的iptables策略应用场景。
### **3.1 管理与配置iptables策略**
在iptables中,策略指的是对数据包进行匹配与处理的规则集合,可以通过iptables命令进行策略的管理与配置。其中,常见的策略包括允许、拒绝、转发等。
下面是一个简单的iptables策略配置示例:
```shell
# 清空所有规则
iptables -F
# 设置默认策略
iptables -P INPUT ACCEPT
iptables -P FORWARD DROP
iptables -P OUTPUT ACCEPT
# 允许从指定IP地址的主机访问本机的22端口
iptables -A INPUT -s 192.168.1.100 -p tcp --dport 22 -j ACCEPT
# 拒绝来自指定IP地址的访问
iptables -A INPUT -s 192.168.1.200 -j REJECT
```
### **3.2 策略的优先级与匹配规则**
在iptables中,策略的匹配是按照规则从上到下依次匹配的,因此策略的优先级非常重要。一般来说,先匹配到的规则会生效,后面的规则不再执行。
同时,iptables的匹配规则也非常灵活,可以根据协议、源/目标IP地址、源/目标端口等进行匹配。
### **3.3 常见的iptables策略应用场景**
iptables策略在实际应用中非常广泛,常见的应用场景包括:
- 搭建防火墙:通过设置合适的策略,可以实现对网络流量的精确控制,提高网络安全性。
- 访问控制:可以根据不同的IP地址、端口号等信息,实现对访问的控制和限制。
- 数据包转发:通过设定转发策略,可以实现数据包的转发功能,满足特定的网络需求。
以上就是iptables策略管理的基本内容,通过合理的策略管理与配置,可以有效地实现网络安全与流量控制的需求。
## 4. 章节四:iptables高级功能与扩展
### 4.1 使用iptables进行网络地址转换(NAT)
网络地址转换(Network Address T

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"iptables"为主题,涵盖了iptables入门指南、规则设置实例、网络地址转换、链与策略、规则管理技巧、流量控制、端口转发、安全策略制定、规则优化与性能调优、日志功能与日志分析、基础防火墙设计与配置、高级规则、网络地址映射、应用案例分享与实战演练、IP集的使用、IPv6配置与规则限制、调试方法与技巧、网络故障诊断与解决、高可用性防火墙系统构建和iptables数据包处理过程等方面的知识。通过这些文章以及实例分享,读者可以深入了解iptables的基本概念和常用命令,并掌握其在网络安全和防火墙配置中的应用。无论是初学者还是有经验的运维人员,都能从本专栏中获得实用的技巧和最佳实践,从而更好地配置和管理iptables防火墙。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【BIOS配置艺术】:提升ProLiant DL380 G6性能的Windows Server 2008优化教程

# 摘要
本文旨在探讨BIOS在服务器性能优化中的作用及其配置与管理策略。首先,概述了BIOS的基本概念、作用及其在服务器性能中的角色,接着详细介绍了BIOS的配置基础和优化实践,包括系统启动、性能相关设置以及安全性设置。文章还讨论
【安全性的守护神】:适航审定如何确保IT系统的飞行安全

# 摘要
适航审定作为确保飞行安全的关键过程,近年来随着IT系统的深度集成,其重要性愈发凸显。本文首先概述了适航审定与IT系统的飞行安全关系,并深入探讨了适航审定的理论基础,包括安全性管理原则、风险评估与控制,以及国内外适航审定标准的演变与特点。接着分析了IT系统在适航审定中的角色,特别是IT系统安全性要求、信息安全的重要性以及IT系统与飞行控制系统的接口安全。进一步,文
【CListCtrl行高优化实用手册】:代码整洁与高效维护的黄金法则
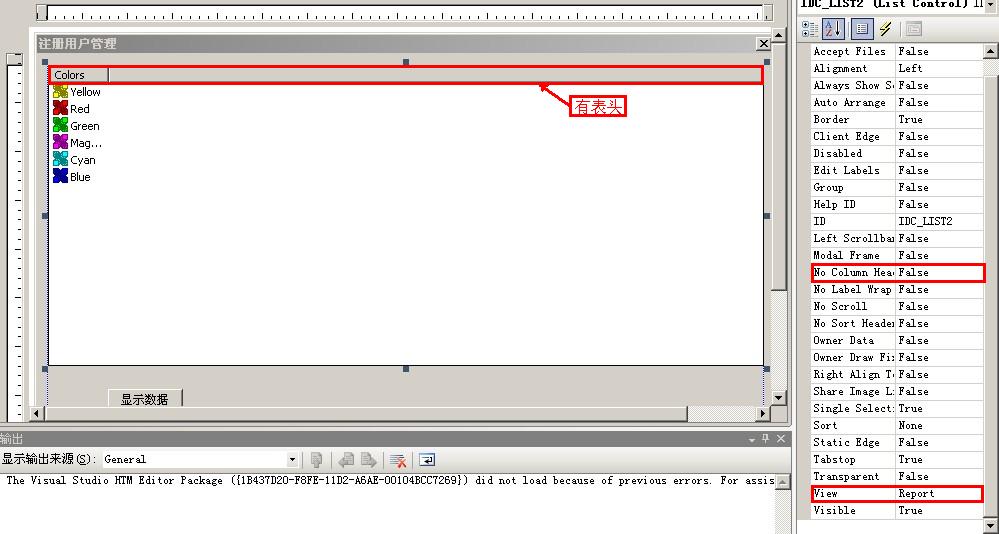
# 摘要
本文针对CListCtrl控件的行高优化进行了系统的探讨。首先介绍了CListCtrl行高的基础概念及其在不同应用场景下的重要性。其次,深入分析了行高优化的理论基础,包括其基本原理、设计原则以及实践思路。本研究还详细讨论了在实际编程中提高行高可读性与性能的技术,并提供了代码维护的最佳实践。此外,文章探讨了行高优化在用户体验、跨平台兼容性以及第三方库集成方面的高级应用。最后
【高级时间序列分析】:傅里叶变换与小波分析的实战应用

# 摘要
时间序列分析是理解和预测数据随时间变化的重要方法,在众多科学和工程领域中扮演着关键角色。本文从时间序列分析的基础出发,详细介绍了傅里叶变换与小波分析的理论和实践应用。文中阐述了傅里叶变换在频域分析中的核心地位,包括其数学原理和在时间序列中的具体应用,以及小波分析在信号去噪、特征提取和时间-频率分析中的独特优势。同时,探讨了当前高级时间序列分析工具和库的使用,以及云平台在大数据时间
【文档编辑小技巧】:不为人知的Word中代码插入与行号突出技巧
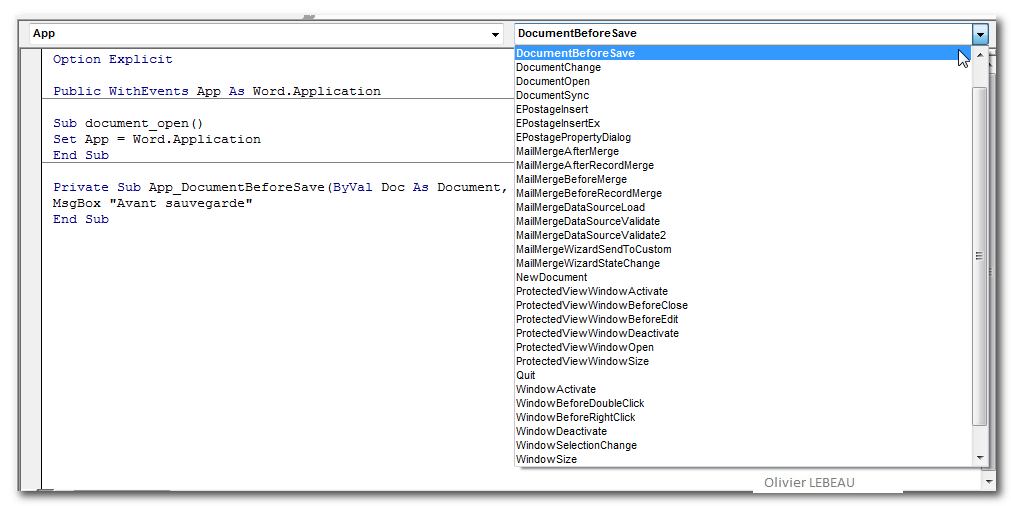
# 摘要
本文主要探讨在Microsoft Word文档中高效插入和格式化代码的技术。文章首先介绍了代码插入的基础操作,接着深入讨论了高级技术,包括利用“开发工具”选项卡、使用“粘贴特殊”功能以及通过宏录制来自动化代码插入。在行号应用方面,文章提供了自动和手动添加行号的技巧,并讨论了行号的更新与管理方法。进阶实践部分涵盖了高级代码格式化和行号与代码配合使用的技巧
长安汽车生产技术革新:智能制造与质量控制的全面解决方案

# 摘要
智能制造作为一种先进的制造范式,正逐渐成为制造业转型升级的关键驱动力。本文系统阐述了智能制造的基本概念与原理,并结合长安汽车的实际生产技术实践,深入探讨了智能制造系统架构、自动化与机器人技术、以及数据驱动决策的重要性。接着,文章着重分析了智能制造环境下的质量控制实施,包括质量管理的数字化转型、实时监控与智能检测技术的应用,以及构建问题追踪与闭环反馈机制。最后,通过案例分析和国内外比较,文章揭示了智
车载网络性能提升秘籍:测试优化与实践案例

# 摘要
随着智能网联汽车技术的发展,车载网络性能成为确保车辆安全、可靠运行的关键因素。本文系统地介绍了车载网络性能的基础知识,并探讨了不同测试方法及其评估指标。通过对测试工具、优化策略以及实践案例的深入分析,揭示了提升车载网络性能的有效途径。同时,本文还研究了当前车载网络面临的技术与商业挑战,并展望了其未来的发展趋势。本文旨在为业内研究人员、工程师提供车载
邮件规则高级应用:SMAIL中文指令创建与管理指南

# 摘要
SMAIL是一种电子邮件处理系统,具备强大的邮件规则设置和过滤功能。本文介绍了SMAIL的基本命令、配置文件解析、邮件账户和服务器设置,以及邮件规则和过滤的应用。文章进一步探讨了SMAIL的高级功能,如邮件自动化工作流、内容分析与挖掘,以及第三方应用和API集成。为了提高性能和安全性,本文还讨论了SMAIL
CCU6与PWM控制:高级PWM技术的应用实例分析
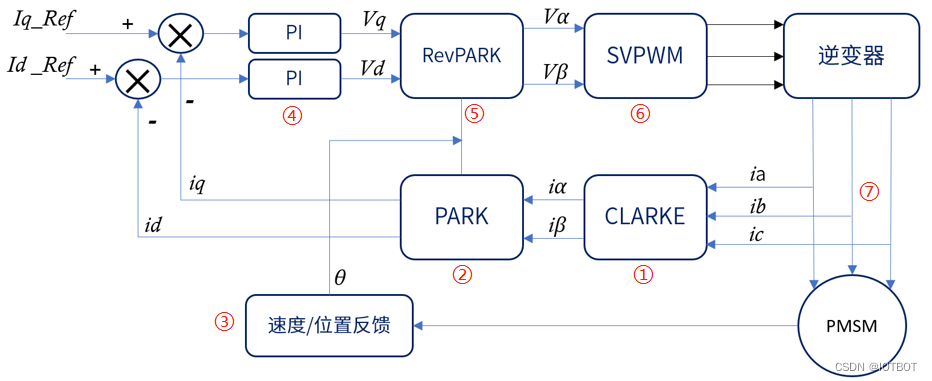
# 摘要
本文针对CCU6控制器与PWM控制技术进行了全面的概述和分析。首先,介绍PWM技术的理论基础,阐述了其基本原理、参数解析与调制策略,并探讨了在控制系统中的应用,特别是电机控制和能源管理。随后,专注于CCU6控制器的PWM功能,从其结构特点到PWM模块的配置与管理,详细解析了CCU6控制器如何执行高级PWM功能,如脉宽调制、频率控制以及故障检测。文章还通过多个实践应用案例,展示了高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )