【R语言案例解决高手】:用clara包巧妙解决实际问题
发布时间: 2024-11-03 09:23:17 阅读量: 32 订阅数: 31 

使用R语言实现CLARA算法对鸢尾花数据集进行大规模聚类分析

# 1. R语言与clara包基础
## 1.1 R语言的简介
R语言是一种广泛应用于统计分析和数据科学的语言,以其强大的数据处理能力和丰富的数据可视化包而著称。R语言的社区活跃,支持各种高级统计分析和机器学习算法的实现。
```r
# R语言的基本使用示例
print("Hello, World!")
```
## 1.2 clara包介绍
clara包是R语言中一个用于进行聚类分析的扩展包。它实现了一种基于划分的聚类方法,特别适合于处理大型数据集。该方法通过在数据的子集中寻找代表性样本(即质心),从而有效地对数据进行聚类。
## 1.3 安装clara包的步骤
在开始使用clara包之前,需要确保已经安装了R语言和相应的开发工具。然后可以使用以下命令安装clara包:
```r
install.packages("cluster") # 安装cluster包,clara函数包含在其中
library(cluster) # 加载cluster包
```
通过上述步骤,你将能够利用clara包来执行复杂的数据聚类分析。在后续的章节中,我们将深入了解clara算法的理论基础及其在现实问题中的应用实例。
# 2. clara包的理论与实践基础
## 2.1 clara算法理论
### 2.1.1 层次聚类与划分聚类的区别
聚类分析是一种将数据点按照其内在性质分组的方法,旨在揭示数据的结构。在聚类分析中,层次聚类(Hierarchical Clustering)和划分聚类(Partitioning Clustering)是两种常见的方法,它们之间存在显著的差异。
层次聚类依据数据间的相似性逐步合并或分割成多个聚类,最终形成一棵“树状图”,其结果是一种嵌套的聚类结构。它主要包括凝聚层次聚类(Agglomerative Hierarchical Clustering)和分裂层次聚类(Divisive Hierarchical Clustering)两种方式。层次聚类适合于小至中等规模的数据集,对于大数据集来说,其计算成本较高。
划分聚类是将数据点划分为固定数量的聚类,这些聚类之间互不相交。clara包实现的clara算法就是一种划分聚类方法,它针对大数据集进行了优化。clara算法通过对数据集进行抽样并使用PAM(Partitioning Around Medoids)算法来寻找最佳聚类,这种方法能够有效处理大规模数据集。
### 2.1.2 clara算法的工作原理
clara算法的核心在于寻找最优的聚类中心(medoids),medoids是一种介于簇内所有点中距离簇内其他点距离之和最小的点,与簇内其他点相比,它更具有代表性。
算法的工作原理可概括为以下步骤:
1. **数据抽样**:clara算法首先对原始数据集进行抽样,以生成包含足够数据点的子集。这个步骤显著减少了计算量,从而能够处理大规模数据集。
2. **初始化**:在子集上使用PAM算法初始化聚类中心,即选择出medoids。
3. **迭代优化**:通过反复分配和重新选择medoids来优化聚类中心,直到获得稳定的聚类结果。这包括将每个非medoid点分配到最近的medoid所在的簇,并计算所有可能的非medoid点与medoid点对的总距离,如果交换medoid点对能够降低总距离,则执行交换。
4. **结果选择**:在多次迭代过程中,算法保存最佳的聚类结果。最后,返回最佳聚类解作为算法的输出。
clara算法因其对大数据集的处理能力,广泛应用于实际数据分析中,如生物信息学、市场细分、社会网络分析等领域。
## 2.2 数据预处理
### 2.2.1 数据清洗技巧
数据预处理是数据分析和挖掘的重要环节,它直接影响到后续分析的准确性和可靠性。clara算法的高效运用离不开优质的数据预处理。数据清洗是数据预处理的首要步骤,主要目的是消除数据中的噪声和异常值,纠正错误。
以下是一些常用的数据清洗技巧:
- **缺失值处理**:缺失数据是数据集中常见的问题,处理方式包括删除含有缺失值的记录、填充缺失值(使用均值、中位数、众数或通过预测模型)、插值等。
- **重复数据处理**:重复的数据记录可能会扭曲分析结果,应该去除重复数据,只保留唯一记录。
- **异常值识别与处理**:异常值可能来源于输入错误或测量误差,通过箱线图、Z分数、IQR等方法识别异常值,并决定是删除、修正还是保留。
- **格式统一**:确保数据格式一致,比如日期、时间格式化,货币单位统一等。
### 2.2.2 数据标准化和归一化
数据标准化和归一化是调整数据分布的过程,以确保数据在不同尺度和量纲间具有可比性。
- **标准化(Standardization)**:将数据按比例缩放,使之落入一个小的特定区间,通常为标准正态分布。公式为 \( z = \frac{(x - \mu)}{\sigma} \),其中 \( \mu \) 是均值,\( \sigma \) 是标准差。R语言中的 `scale` 函数可以进行数据的标准化。
```R
# 示例:标准化一个数据集
data("mtcars")
standardized_data <- scale(mtcars)
```
- **归一化(Normalization)**:将数据缩放到一个固定区间,通常是0到1。归一化公式为 \( x' = \frac{(x - \min(x))}{(\max(x) - \min(x))} \),其中 \( \min(x) \) 和 \( \max(x) \) 分别是数据集中元素的最小值和最大值。可以使用 `normalize` 函数在R中归一化数据。
```R
# 示例:归一化一个数据集
normalize <- function(x) {
return ((x - min(x)) / (max(x) - min(x)))
}
normalized_data <- apply(mtcars, 2, normalize)
```
标准化和归一化后的数据在使用clara算法时能够改善聚类性能,并确保所有的变量在同等尺度下被考虑。
## 2.3 clara包的安装与基本使用
### 2.3.1 安装clara包的步骤
在使用clara算法之前,需要先安装clara包。clara包不是R语言的基础包,需要从CRAN(Comprehensive R Archive Network)下载安装。以下是安装clara包的步骤:
```R
# 安装clara包
install.packages("clara")
```
安装完成后,可以使用`library()`函数加载clara包以便在R环境中使用。
```R
# 加载clara包
library(clara)
```
### 2.3.2 clara函数的参数详解
clara包的核心函数是`clara()`,它包含多个参数可以设置以优化聚类结果。
- **data**:需要进行聚类分析的数据集。
- **k**:需要生成的聚类数量,是一个正整数。
- **metric**:距离度量方法,包括"euclidean"(欧几里得距离,默认值)、"manhattan"(曼哈顿距离)等。
- **samples**:数据抽样大小,控制了用于聚类分析的数据子集的大小,默认值是40+2k。
- **pamLike**:一个逻辑值,指示是否采用类似于PAM算法的处理方式。
- **stand**:一个逻辑值,指示是否对数据进行标准化处理。
- **sampledata**:一个逻辑值,指示是否在聚类过程中使用相同的样本子集。
以下是一个简单的clara函数使用示例:
```R
# 使用clara函数进行聚类分析
clustering_result <- clara(mtcars, k = 3, metric = "manhattan", samples = 50)
clustering_result
```
通过上述代码,我们使用了mtcars数据集,并设定聚类数目为3,采用曼哈顿距离,样本大小为50进行聚类分析。得到的结果是一个clara类对象,其中包含了聚类结果的详细信息。
在下一章节,我们将深入探讨clara算法的理论基础和实践应用,解析数据预处理的技巧,并通过具体案例展示clara包在实际问题中的应用。
# 3. clara包在实际问题中的应用案例
在数据科学领域,聚类分析是无监督学习的核心方法之一,而clara(Clustering for Large Applications)包作为R语言中的一个扩展,特别适用于大规模数据集的聚类分析。本章节将通过具体案例,详细探讨clara包在不同行业中的应用,包括客户细分与市场分析、异常检测与防范以及生物信息学中的基因表达数据分析。
## 3.1 客户细分与市场分析
客户细分是理解消费者行为和市场动态的关

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏以 R 语言数据包 clara 为主题,提供了一系列详细教程和实用指南。专栏涵盖了从 R 语言基础、数据探索和可视化到机器学习入门、项目启动、数据清洗和预处理、交互式图形应用构建、数据导出和数据安全等广泛内容。通过使用 clara 包,读者可以掌握 R 语言的核心技巧,提升数据处理效率,并轻松解决实际问题。专栏旨在帮助 R 语言初学者快速入门,并为经验丰富的用户提供高级函数应用的深入指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
微机接口技术深度解析:串并行通信原理与实战应用
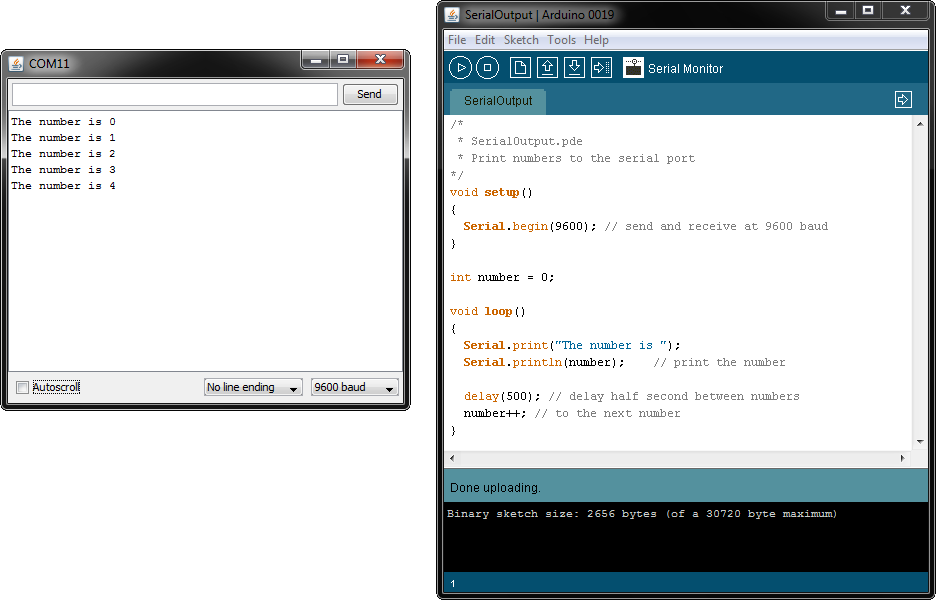
# 摘要
微机接口技术是计算机系统中不可或缺的部分,涵盖了从基础通信理论到实际应用的广泛内容。本文旨在提供微机接口技术的全面概述,并着重分析串行和并行通信的基本原理与应用,包括它们的工作机制、标准协议及接口技术。通过实例介绍微机接口编程的基础知识、项目实践以及在实际应用中的问题解决方法。本文还探讨了接口技术的新兴趋势、安全性和兼容
【进位链技术大剖析】:16位加法器进位处理的全面解析
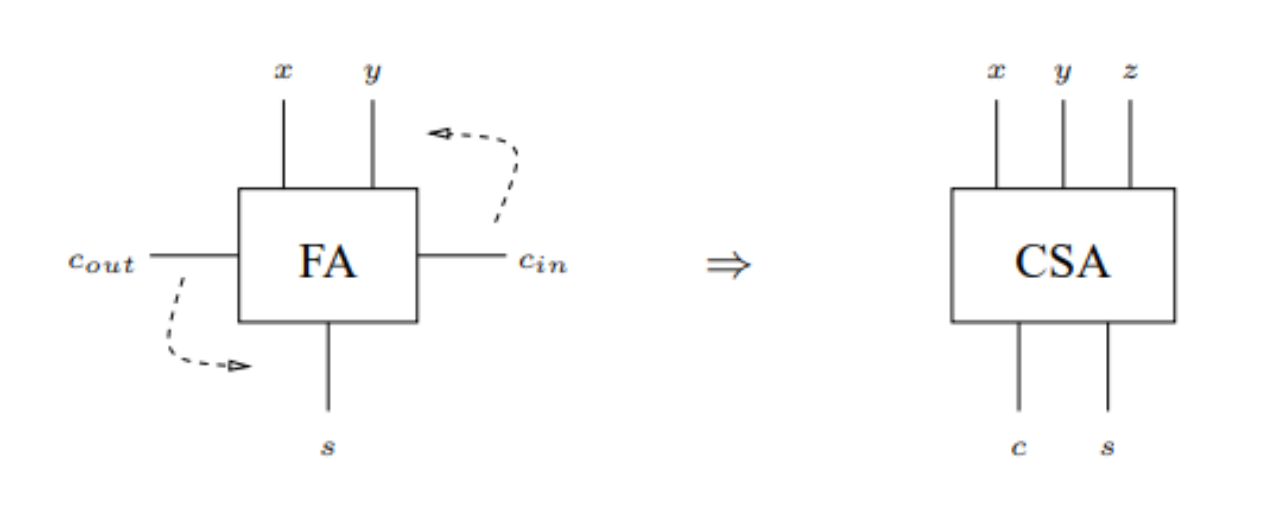
# 摘要
进位链技术是数字电路设计中的基础,尤其在加法器设计中具有重要的作用。本文从进位链技术的基础知识和重要性入手,深入探讨了二进制加法的基本规则以及16位数据表示和加法的实现。文章详细分析了16位加法器的工作原理,包括全加器和半加器的结构,进位链的设计及其对性能的影响,并介绍了进位链优化技术。通过实践案例,本文展示了进位链技术在故障诊断与维护中的应用,并探讨了其在多位加法器设计以及多处理器系统中的高级应用。最后,文章展望了进位链技术的未来,
【均匀线阵方向图秘籍】:20个参数调整最佳实践指南
# 摘要
均匀线阵方向图是无线通信和雷达系统中的核心技术之一,其设计和优化对系统的性能至关重要。本文系统性地介绍了均匀线阵方向图的基础知识,理论基础,实践技巧以及优化工具与方法。通过理论与实际案例的结合,分析了线阵的基本概念、方向图特性、理论参数及其影响因素,并提出了方向图参数调整的多种实践技巧。同时,本文探讨了仿真软件和实验测量在方向图优化中的应用,并介绍了最新的优化算法工具。最后,展望了均匀线阵方向图技术的发展趋势,包括新型材料和技术的应用、智能化自适应方向图的研究,以及面临的技术挑战与潜在解决方案。
# 关键字
均匀线阵;方向图特性;参数调整;仿真软件;优化算法;技术挑战
参考资源链
ISA88.01批量控制:制药行业的实施案例与成功经验

# 摘要
ISA88.01标准为批量控制系统提供了框架和指导原则,尤其是在制药行业中,其应用能够显著提升生产效率和产品质量控制。本文详细解析了ISA88.01标准的概念及其在制药工艺中的重要
实现MVC标准化:肌电信号处理的5大关键步骤与必备工具

# 摘要
本文探讨了MVC标准化在肌电信号处理中的关键作用,涵盖了从基础理论到实践应用的多个方面。首先,文章介绍了
【FPGA性能暴涨秘籍】:数据传输优化的实用技巧
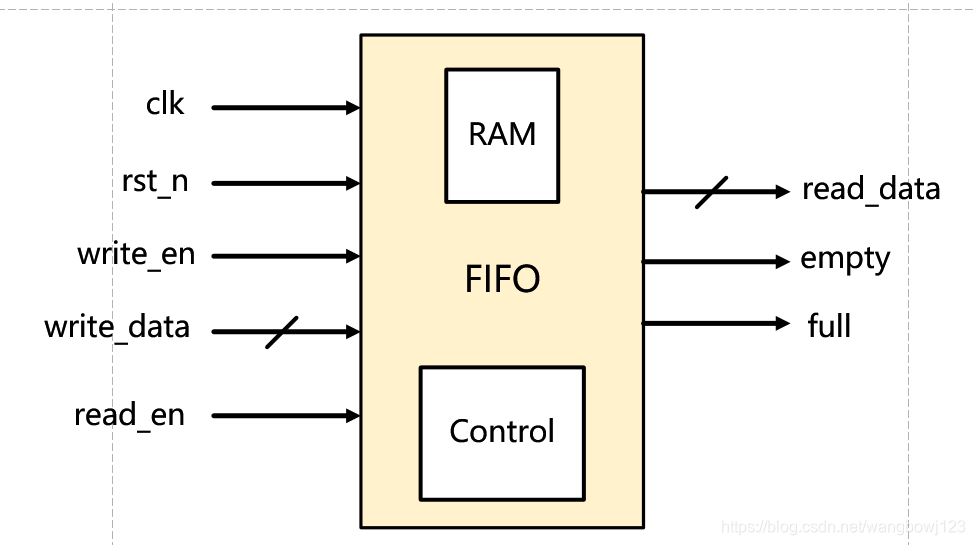
# 摘要
本文全面介绍了FPGA在数据传输领域的应用和优化技巧。首先,对FPGA和数据传输的基本概念进行了介绍,然后深入探讨了FPGA内部数据流的理论基础,包
PCI Express 5.0性能深度揭秘:关键指标解读与实战数据分析

# 摘要
PCI Express(PCIe)技术作为计算机总线标准,不断演进以满足高速数据传输的需求。本文首先概述PCIe技术,随后深入探讨PCI Express 5.0的关键技术指标,如信号传输速度、编码机制、带宽和吞吐量的理论极限以及兼容性问题。通过实战数据分析,评估PCI Express
CMW100 WLAN指令手册深度解析:基础使用指南揭秘
# 摘要
CMW100 WLAN指令是业界广泛使用的无线网络测试和分析工具,为研究者和工程师提供了强大的网络诊断和性能评估能力。本文旨在详细介绍CMW100 WLAN指令的基础理论、操作指南以及在不同领域的应用实例。首先,文章从工作原理和系统架构两个层面探讨了CMW100 WLAN指令的基本理论,并解释了相关网络协议。随后,提供了详细的操作指南,包括配置、调试、优化及故障排除方法。接着,本文探讨了CMW100 WLAN指令在网络安全、网络优化和物联网等领域的实际应用。最后,对CMW100 WLAN指令的进阶应用和未来技术趋势进行了展望,探讨了自动化测试和大数据分析中的潜在应用。本文为读者提供了
三菱FX3U PLC与HMI交互:打造直觉操作界面的秘籍

# 摘要
本论文详细介绍了三菱FX3U PLC与HMI的基本概念、工作原理及高级功能,并深入探讨了HMI操作界面的设计原则和高级交互功能。通过对三菱FX3U PLC的编程基础与高级功能的分析,本文提供了一系列软件集成、硬件配置和系统测试的实践案例,以及相应的故障排除方法。此外,本文还分享了在不同行业应用中的案例研究,并对可能出现的常见问题提出了具体的解决策略。最后,展望了新兴技术对PLC和HMI
【透明度问题不再难】:揭秘Canvas转Base64时透明度保持的关键技术

# 摘要
本文旨在全面介绍Canvas转Base64编码技术,从基础概念到实际应用,再到优化策略和未来趋势。首先,我们探讨了Canvas的基本概念、应用场景及其重要性,紧接着解析了Base64编码原理,并重点讨论了透明度在Canvas转Base64过程中的关键作用。实践方法章节通过标准流程和技术细节的讲解,提供了透明度保持的有效编码技巧和案例分析。高级技术部分则着重于性能优化、浏览器兼容性问题以及Ca
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )