在AWS上创建和配置DynamoDB数据库
发布时间: 2024-02-25 13:51:30 阅读量: 160 订阅数: 27 

数据库安装创建及配置
# 1. 介绍DynamoDB数据库
DynamoDB是一种全托管的NoSQL数据库服务,由亚马逊提供,具有高可用性、可扩展性和灵活性。在本章中我们将介绍DynamoDB数据库的基本概念、特点和优势,以及其适用的场景和优缺点。
## 1.1 什么是DynamoDB数据库
Amazon DynamoDB是一种快速且灵活的NoSQL数据库服务,可用于各种规模的应用程序,从小型应用到大型企业级系统。它支持键-值和文档数据模型,具有自动扩展功能,无需管理基础设施,并可以实现高性能和低延迟的数据访问。
## 1.2 DynamoDB的特点和优势
- **全托管服务**:无需管理数据库的基础设施,包括硬件和软件的维护。
- **无限扩展**:DynamoDB可以自动扩展以适应应用程序的需求,无需进行手动调整。
- **低延迟**:提供高性能且具有低延迟的数据访问,适用于各种实时应用程序。
- **强一致性**:支持强一致性和灵活的一致性模型,满足不同业务需求。
- **安全性**:提供数据加密、访问控制和监控功能,确保数据安全性和隐私性。
## 1.3 适用场景及优缺点分析
### 适用场景:
- **实时数据存储**:适用于需要快速读写的实时数据存储场景,如游戏数据、用户活动日志等。
- **大规模数据分析**:可用于存储和分析海量数据,支持复杂的查询和聚合操作。
- **会话存储**:适用于存储会话数据,如用户登录状态、购物车信息等。
- **消息队列**:可作为消息队列的存储后端,实现高性能的消息传递和处理。
### 优缺点分析:
- **优点**:高可用性、无限扩展、低延迟、强一致性、安全性高。
- **缺点**:相对较高的成本、复杂的数据建模和查询方式、有一定的学习成本。
在接下来的章节中,我们将介绍如何在AWS上创建和配置DynamoDB数据库,以及一些使用和最佳实践。
# 2. 准备工作
在开始在AWS上创建和配置DynamoDB数据库之前,需要进行一些准备工作以确保顺利进行。本章将介绍如何进行相关准备工作,包括创建AWS账号和登录控制台、确认权限和访问密钥设置,以及了解AWS服务和控制台界面。让我们逐步进行准备,为后续操作做好准备。
### 2.1 创建AWS账号和登录控制台
在使用AWS的任何服务之前,您需要首先创建一个AWS账号。以下是创建AWS账号的步骤:
1. 访问[AWS官方网站](https://aws.amazon.com/)。
2. 点击“创建免费账号”按钮并按照提示进行注册。
3. 填写账户信息、联系信息和付款信息。
4. 创建您的账号后,您将获得一个用于登录的用户ID和密码。
登录到AWS管理控制台的步骤如下:
1. 访问[AWS管理控制台](https://aws.amazon.com/console/)。
2. 输入您的账号ID或别名,然后单击“下一步”。
3. 输入您的密码,然后单击“登录”。
### 2.2 确认权限和访问密钥设置
在使用AWS服务时,确保您具有适当的权限和访问密钥设置是非常重要的。您可以按照以下步骤进行设置:
1. 登录到AWS管理控制台。
2. 转到“我的安全凭证”页面。
3. 选择“访问密钥(访问密钥ID和密钥)”选项卡。
4. 单击“创建新的访问密钥”并保存生成的访问密钥ID和密钥。
### 2.3 了解AWS服务和控制台界面
在开始创建和配置DynamoDB数据库之前,建议您对AWS提供的各项服务以及控制台界面有一定的了解。AWS控制台提供了直观的操作界面,方便您管理各种云服务。在本教程中,我们将重点介绍DynamoDB服务的相关操作,因此熟悉控制台的布局和功能将有助于您更好地使用这一服务。
以上是准备工作的具体步骤和建议,确保您在进行后续操作时能够顺利进行。接下来,我们将进入第三章,详细介绍在AWS上创建DynamoDB数据库的步骤。
# 3. 在AWS上创建DynamoDB数据库
在这一部分,我们将详细说明如何在AWS上创建DynamoDB数据库,包括进入AWS控制台并选择DynamoDB服务、创建新的DynamoDB数据库以及设置表名称、主键和容量配置等步骤。
#### 3.1 进入AWS控制台并选择DynamoDB服务
首先,打开您的浏览器,登录您的AWS账号,然后按照以下步骤进入AWS控制台并选择DynamoDB服务:
1. 点击右上角的“服务”(Services)菜单。
2. 在搜索栏中输入“DynamoDB”,然后点击搜索结果中的“DynamoDB”服务。
#### 3.2 创建新的DynamoDB数据库
接下来,我们将创建一个新的DynamoDB数据库。请按照以下步骤操作:
1. 在DynamoDB控制台上方选择“创建表”(Create table)按钮。
2. 输入您的表名称,并指定主键。主键是用来唯一标识每个项目的属性。
3. 选择您的主键类型,可以是字符串、数字等。
4. 设置读取和写入容量配置,根据您的需求进行调整。
#### 3.3 设置表名称、主键和容量配置
最后,在创建新的DynamoDB数据库时,请注意以下事项:
- 表名称应具有描述性,并且易于识别。
- 主键对于访问和识别数据非常重要,因此请根据您的需求选择合适的主键类型。
- 容量配置会直接影响数据库的性能和成本,根据实际需求进行调整。
通过以上步骤,您已成功在AWS上创建了一个新的DynamoDB数据库,并设置了表名称、主键和容量配置。接下来,您可以开始设计数据表结构和属性,以及进行后续的配置和操作。
# 4. 配置DynamoDB数据库
在这一章中,我们将详细介绍如何配置DynamoDB数据库,包括设计数据表结构和属性、设定读取和写入容量单位,以及设置索引、条件和表级别配置。
#### 4.1 设计数据表结构和属性
在配置DynamoDB数据库之前,首先要设计数据表的结构和属性。在创建表时,需要定义主键,主键可以是单个属性的简单主键,也可以是由两个属性组成的复合主键。除此之外,还可以定义其他属性作为表的属性列,每个属性具有其数据类型(如字符串、数字、布尔值等)。以下是一个使用Python SDK创建DynamoDB表的示例:
```python
import boto3
# 创建DynamoDB资源
dynamodb = boto3.resource('dynamodb')
# 创建表
table = dynamodb.create_table(
TableName='Books',
KeySchema=[
{
'AttributeName': 'Author',
'KeyType': 'HASH' # Partition key
},
{
'AttributeName': 'Title',
'KeyType': 'RANGE' # Sort key
}
],
AttributeDefinitions=[
{
'AttributeName': 'Author',
'AttributeType': 'S'
},
{
'AttributeName': 'Title',
'AttributeType': 'S'
}
],
ProvisionedThroughput={
'ReadCapacityUnits': 5,
'WriteCapacityUnits': 5
}
)
```
##### 代码总结:
- 创建DynamoDB资源并定义表的结构
- 定义主键为Author和Title,并设置属性类型
- 设置读取和写入容量单位为5
##### 结果说明:
上述代码将创建一个名为Books的DynamoDB表,表中包含Author和Title两个属性,读取和写入的容量单位都为5。
#### 4.2 设定读取和写入容量单位
在DynamoDB中,需要为表的读取和写入操作设置吞吐容量单位。读取容量单位表示每秒可以从表中读取的项目数,写入容量单位表示每秒可以写入到表中的项目数。根据实际需要,可以在控制台或使用SDK为表设置不同的读取和写入容量单位,来满足不同的业务需求。以下是一个使用Java SDK为DynamoDB表设置吞吐容量的示例:
```java
AmazonDynamoDB client = AmazonDynamoDBClientBuilder.standard().build();
ProvisionedThroughput throughput = new ProvisionedThroughput()
.withReadCapacityUnits(10L)
.withWriteCapacityUnits(5L);
UpdateTableRequest request = new UpdateTableRequest()
.withTableName("Books")
.withProvisionedThroughput(throughput);
UpdateTableResult result = client.updateTable(request);
```
##### 代码总结:
- 创建AmazonDynamoDB客户端并设置吞吐容量
- 使用UpdateTableRequest更新表的读取和写入容量
- 读取容量单位为10,写入容量单位为5
##### 结果说明:
以上代码将更新名为Books的DynamoDB表,将读取容量单位设置为10,写入容量单位设置为5。
#### 4.3 设置索引、条件和表级别配置
除了基本的表结构和容量配置外,还可以根据需求为DynamoDB表设置索引、条件以及表级别配置。索引可以加速查询操作,条件可以过滤查询结果,表级别配置可以控制数据的存储和访问行为。以下是一个使用Go SDK创建DynamoDB索引的示例:
```go
svc := dynamodb.New(session.New())
params := &dynamodb.UpdateTableInput{
TableName: aws.String("Books"),
AttributeDefinitions: []*dynamodb.AttributeDefinition{
{
AttributeName: aws.String("Genre"),
AttributeType: aws.String("S"),
},
},
GlobalSecondaryIndexUpdates: []*dynamodb.GlobalSecondaryIndexUpdate{
{
Create: &dynamodb.CreateGlobalSecondaryIndexAction{
IndexName: aws.String("GenreIndex"),
KeySchema: []*dynamodb.KeySchemaElement{
{
AttributeName: aws.String("Genre"),
KeyType: aws.String("HASH"),
},
},
Projection: &dynamodb.Projection{
ProjectionType: aws.String(dynamodb.ProjectionTypeAll),
},
ProvisionedThroughput: &dynamodb.ProvisionedThroughput{
ReadCapacityUnits: 10,
WriteCapacityUnits: 5,
},
},
},
},
}
_, err := svc.UpdateTable(params)
```
##### 代码总结:
- 使用dynamodb.New创建DynamoDB服务
- 使用UpdateTableInput更新表设置,包括定义属性和创建全局二级索引
- 索引名为GenreIndex,主键为Genre,读取容量为10,写入容量为5
##### 结果说明:
以上代码将为名为Books的DynamoDB表创建一个名为GenreIndex的全局二级索引,用于加速基于Genre属性的查询操作。
通过以上步骤,我们可以灵活配置DynamoDB表的结构、容量、索引和条件,以满足不同的应用场景和需求。
# 5. 使用DynamoDB数据库
在这一章中,我们将深入了解如何在AWS上使用已经创建和配置好的DynamoDB数据库。我们将包括编写和执行数据操作代码,监控和调整数据库性能,以及数据备份和恢复策略。
#### 5.1 编写和执行数据操作代码
在使用DynamoDB数据库时,我们通常需要编写代码来执行数据的增加、删除、查询和更新操作。下面是使用Python语言和Boto3库来实现这些操作的示例代码:
```python
import boto3
# 创建DynamoDB客户端
dynamodb = boto3.resource('dynamodb')
# 选择要操作的数据表
table = dynamodb.Table('example_table')
# 添加数据
table.put_item(
Item={
'id': '1',
'name': 'Alice',
'age': 25,
'email': 'alice@example.com'
}
)
# 查询数据
response = table.get_item(
Key={
'id': '1'
}
)
item = response['Item']
print(item)
# 更新数据
table.update_item(
Key={
'id': '1'
},
UpdateExpression='SET age = :val',
ExpressionAttributeValues={
':val': 26
}
)
# 删除数据
table.delete_item(
Key={
'id': '1'
}
)
```
以上代码演示了如何使用Python语言和Boto3库来连接DynamoDB数据库,并实现常见的数据操作。这些操作包括添加数据、查询数据、更新数据和删除数据。
#### 5.2 监控和调整数据库性能
在实际使用中,我们需要监控DynamoDB数据库的性能,以确保其能够满足业务需求和运行稳定。AWS提供了CloudWatch服务,可以用于监控DynamoDB的吞吐量、错误率、请求次数等指标,并可以设置警报来实现实时监控。
如果发现数据库性能不足,可以通过增加读取和写入容量单位来调整数据库性能。当然,这也会影响到数据库的成本,因此在调整性能时需要权衡成本和性能之间的关系。
#### 5.3 数据备份和恢复策略
为了保障数据安全,我们需要制定合适的数据备份和恢复策略。AWS提供了DynamoDB的备份和恢复功能,可以定期备份数据并设置恢复点,以应对意外数据丢失或损坏的情况。
可以使用AWS控制台或者CLI来管理DynamoDB的备份策略,定期创建备份并设置合适的保留周期和恢复方式,以确保数据的安全性和可靠性。
以上是在使用DynamoDB数据库时的一些常见操作和策略,通过合理的数据操作和数据库性能监控调整,以及完善的数据备份和恢复策略,可以更好地利用DynamoDB来支持业务需求并确保数据安全。
# 6. 最佳实践和注意事项
在使用DynamoDB数据库时,为了保证系统的稳定性和性能表现,以下是一些最佳实践和注意事项:
#### 6.1 DynamoDB的最佳实践
- **选择合适的主键**:主键设计是DynamoDB中至关重要的一环,合理选择主键可以有效提高检索效率和分区均衡。
- **合理利用索引**:根据应用需求设置合适的索引以支持数据的快速查询和检索。
- **利用批量操作**:使用批量写入和读取操作可以减少请求次数,提高数据访问效率。
- **避免全表扫描**:尽量避免全表扫描操作,使用查询和索引来快速定位目标数据。
- **定期优化表结构**:随着数据量增长,定期评估和优化表结构以适应更高的读写吞吐量需求。
#### 6.2 安全性和权限管理指南
- **使用IAM角色**:合理配置IAM角色和权限以限制对DynamoDB的访问和操作,避免数据泄露和误操作。
- **加密存储**:对于敏感数据,建议启用DynamoDB的加密功能,确保数据在传输和存储过程中的安全性。
- **日志监控**:定期监控DynamoDB的访问日志和操作记录,及时发现异常情况并进行处理。
- **网络安全**:配置VPC、安全组等网络安全设置,限制数据库的访问权限,减少受到网络攻击的风险。
#### 6.3 成本控制和优化建议
- **合理配置读写容量**:根据实际业务需求和访问模式,合理设置读写容量单位,避免资源浪费和额外费用。
- **使用AutoScaling**:结合AutoScaling功能,动态调整数据库的读写容量,根据负载情况自动扩展或缩减容量。
- **冷热数据分离**:将不经常访问的数据迁移至冷数据存储,降低热存储成本。
- **定期审查成本**:定期审查DynamoDB的使用情况和费用明细,及时调整容量和配置以控制成本。
通过遵循以上最佳实践和注意事项,可以有效提高DynamoDB数据库的稳定性、安全性和性能表现,确保系统能够长期稳定高效地运行。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨AWS DynamoDB数据库,涵盖了从在AWS上创建和配置DynamoDB数据库,到在Node.js中使用DynamoDB进行基本数据操作,再到使用DynamoDB实现CRUD操作的全过程。我们将分享DynamoDB中的数据模型设计和最佳实践,以及如何通过AWS控制台和命令行接口管理DynamoDB。此外,我们还将讨论DynamoDB的性能优化和容量规划,以及数据安全和访问控制策略。专栏最后将探索如何利用DynamoDB进行分布式应用程序开发,以及基于DynamoDB的数据分析与报告。无论您是初学者还是有经验的开发人员,本专栏都将为您提供全面而深入的指南,帮助您更好地理解和利用AWS DynamoDB数据库。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
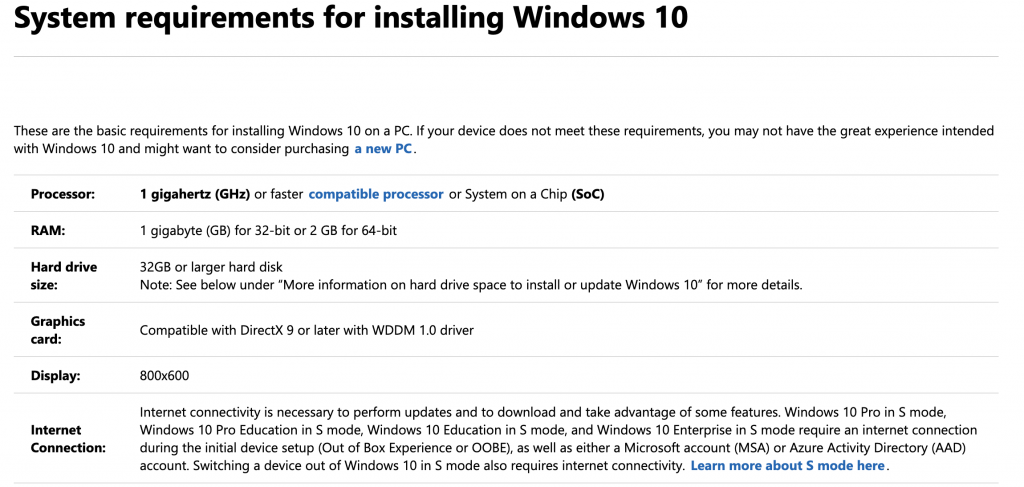
【系统兼容性深度揭秘】:Win10 x64上的TensorFlow与CUDA完美匹配指南
# 摘要
本文详细探讨了在深度学习框架中系统兼容性的重要性,并深入介绍了CUDA的安装、配置以及TensorFlow环境的搭建过程。文章分析了不同版本CUDA与GPU硬件及NVIDIA驱动程序的兼容性需求,并提供了详细的安装步骤和故障排除方法。针对TensorFlow的安装与环境搭建,文章阐述了版本选择、依赖
先农熵数学模型:计算方法深度解析

# 摘要
先农熵模型作为一门新兴的数学分支,在理论和实际应用中显示出其独特的重要性。本文首先介绍了先农熵模型的概述和理论基础,阐述了熵的起源、定义及其在信息论中的应用,并详细解释了先农熵的定义和数学角色。接着,文章深入探讨了先农熵模型的计算方法,包括统计学和数值算法,并分析了软件实现的考量。文中还通过多个应用场景和案例,展示了先农熵模型在金融分析、生物信息学和跨学科研究中的实际应用。最后,本文提出了
【24小时精通电磁场矩量法】:从零基础到专业应用的完整指南

# 摘要
本文系统地介绍了电磁场理论与矩量法的基本概念和应用。首先概述了电磁场与矩量法的基本理论,包括麦克斯韦方程组和电磁波的基础知识,随后深入探讨了矩量法的理论基础,特别是基函数与权函数选择、阻抗矩阵和导纳矩阵的构建。接着,文章详述了矩量法的计算步骤,涵盖了实施流程、编程实现以及结果分析与验证。此外,本文还探讨了矩量法在天线分析、微波工程以及雷达散射截面计算等不同场景的应用,并介绍了高频近似技术、加速技术和
RS485通信原理与实践:揭秘偏置电阻最佳值的计算方法
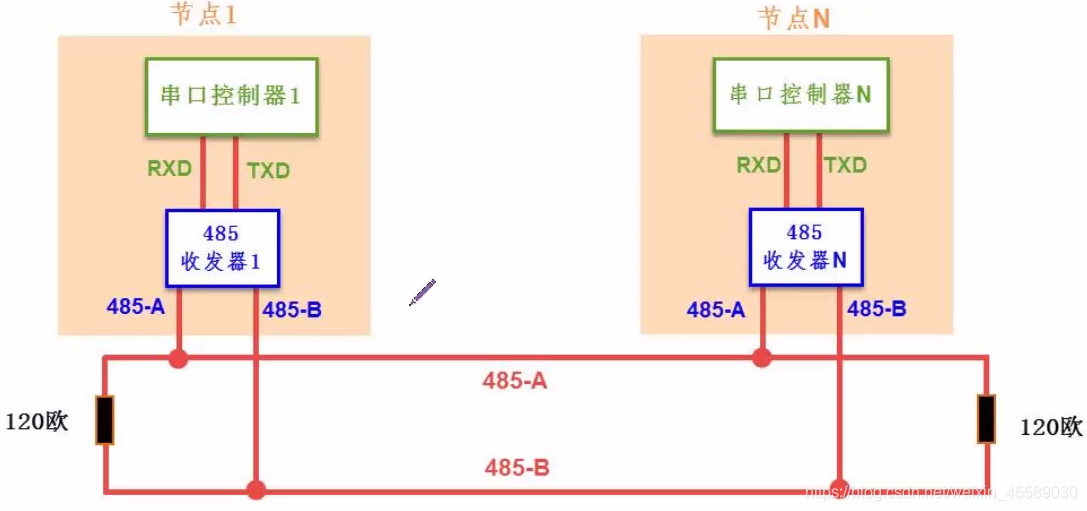
# 摘要
RS485通信作为一种广泛应用的串行通信技术,因其较高的抗干扰能力和远距离传输特性,在工业控制系统和智能设备领域具有重要地位。
【SOEM多线程编程秘籍】:线程同步与资源竞争的管理艺术

# 摘要
本文针对SOEM多线程编程提供了一个系统性的学习框架,涵盖多线程编程基础、同步机制、资源竞争处理、实践案例分析以及进阶技巧,并展望了未来发展趋势。首先,介绍了多线程编程的基本概念和线程同步机制,包括同步的必要性、锁的机制、同步工具的使用等。接着,深入探讨了资源竞争的识别、预防策略和调试技巧。随后
SRIO Gen2在嵌入式系统中的实现:设计要点与十大挑战分析

# 摘要
本文对SRIO Gen2技术在嵌入式系统中的应用进行了全面概述,探讨了设计要点、面临的挑战、实践应用以及未来发展趋势。首先,文章介绍了SRIO Gen2的基本概念及其在嵌入式系统中的系统架构和硬件设计考虑。随后,文章深入分析了SRIO Gen2在嵌入式系统中遇到的十大挑战,包括兼容性、性能瓶颈和实时性能要求。在实践应用方面,本文讨论了硬件设计、软件集成优化以及跨平台部署与维护的策略。最后,文章展望了SRI
【客户满意度提升神器】:EFQM模型在IT服务质量改进中的效果

# 摘要
本论文旨在深入分析EFQM模型在提升IT服务质量方面的作用和重要性。通过对EFQM模型基本原理、框架以及评估准则的阐述,本文揭示了其核心理念及实践策略,并探讨了如何有效实施该模型以改进服务流程和建立质量管理体系。案例研究部分强调了EFQM模型在实际IT服务中的成功应用,以及它如何促进服务创新和持续改进。最后,本论文讨论了应用EFQM模型时可能遇到的挑战,以及未来的发展趋势,包括
QZXing进阶技巧:如何优化二维码扫描速度与准确性?

# 摘要
随着移动设备和电子商务的迅速发展,QZXing作为一种广泛应用的二维码扫描技术,其性能直接影响用户体验。本文首先介绍了QZXing的基础知识及其应用场景,然后深入探讨了QZXing的理论架构,包括二维码编码机制、扫描流程解析,以及影响扫描速度与准确性的关键因素。为了优化扫描速度,文章提出了一系列实践策略,如调整解码算法、图像预处理技术,以及线程和并发优化。此外,本文还探讨了提升扫描准
【架构设计的挑战与机遇】:保险基础数据模型架构设计的思考

# 摘要
保险业务的高效运行离不开科学合理的架构设计,而基础数据模型作为架构的核心,对保险业务的数据化和管理至关重要。本文首先阐述了架构设计在保险业务中的重要性,随后介绍了保险基础数据模型的理论基础,包括定义、分类及其在保险领域的应用。在数据模型设计实践中,本文详细讨论了设计步骤、面向对象技术及数据库选择与部署
【AVR编程效率提升宝典】:遵循avrdude 6.3手册,实现开发流程优化
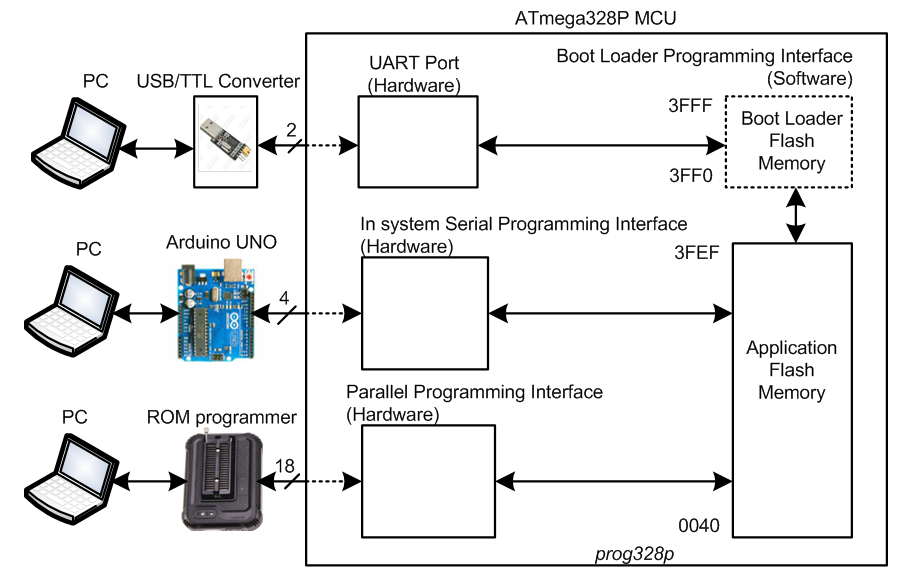
# 摘要
本文深入探讨了AVR编程和开发流程,重点分析了avrdude工具的使用与手册解读,从而为开发者提供了一个全面的指南。文章首先概述了avrdude工具的功能和架构,并进一步详细介绍了其安装、配置和在AVR开发中的应用。在开发流程优化方面,本文探讨了如何使用avrdude简化编译、烧录、验证和调
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )