扩展MVC5中的ViewModels:呈现巧租房系统更灵活的数据
发布时间: 2024-02-24 22:08:30 阅读量: 28 订阅数: 26 
# 1. 理解MVC5中的ViewModels
## 1.1 MVC5框架概述
在Web开发中,MVC(Model-View-Controller)架构是一种常见的设计模式,它将应用程序分为三个核心部分:模型(Model)、视图(View)和控制器(Controller)。MVC5是ASP.NET框架中最新的MVC版本,它提供了一种结构化的方式来构建Web应用程序。
## 1.2 ViewModel在MVC5中的作用和重要性
ViewModel在MVC5中扮演着连接控制器和视图的关键角色。它充当了一个数据传输对象的作用,将模型中的数据转换成视图所需的格式,同时也接收视图的交互数据并传递给控制器。ViewModel的设计能够使得视图更加灵活,同时也能够有效地进行数据校验和验证。
## 1.3 MVC5中ViewModels的基本使用方法
在MVC5中,创建和使用ViewModels通常遵循一定的模式,包括定义ViewModel类、与视图模板的关联以及在控制器中使用ViewModels来进行数据传递和交互。在本节中,我们将详细介绍如何在MVC5中使用ViewModels,并且会列举一些最佳实践的示例代码。
以上是第一章内容的标题以及简要概述,接下来我们将深入探讨MVC5中ViewModels的具体内容。
# 2. 构建灵活的数据呈现
在MVC5中,设计模式是构建灵活数据呈现不可或缺的一部分。设计模式提供了一种在软件设计过程中常见问题的解决方案,同时也提高了代码的可重用性和可维护性。在本章中,我们将深入探讨MVC5中常用的设计模式,以及如何将其应用于构建灵活的数据呈现。
### 2.1 MVC5中常用的设计模式
#### Model-View-Controller(MVC)模式
MVC模式是MVC5框架的核心设计模式之一。它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。模型负责处理应用程序的业务逻辑和数据操作,视图负责展示界面给用户,控制器负责处理用户请求并调度对应的模型和视图。
#### 观察者模式
观察者模式是一种行为设计模式,它定义了对象之间的一对多依赖关系,当一个对象的状态发生改变时,其所有依赖对象都会收到通知并自动更新。在MVC5中,视图可以作为观察者,当模型的数据发生变化时,视图会自动更新以反映最新的数据。
### 2.2 设计模式在构建灵活数据呈现中的应用
设计模式在构建灵活数据呈现方面发挥着重要作用。例如,利用观察者模式可以实现数据与界面的自动同步,提高用户体验。同时,利用工厂模式可以帮助创建不同类型的ViewModels,使数据呈现更加灵活和可扩展。
### 2.3 如何利用设计模式来优化ViewModels的使用
在构建ViewModels时,我们可以结合设计模式来优化代码结构和提高性能。例如,使用工厂模式可以根据不同的需求动态创建ViewModels实例,使用装饰器模式可以在运行时扩展ViewModels的功能,从而实现灵活的数据呈现。
设计模式的运用不仅可以使代码更加结构化和易于维护,还可以提高开发效率和代码质量。在下一节中,我们将进一步讨论如何扩展现有的ViewModels以更好地满足业务需求。
# 3. 扩展现有的ViewModels
在Web应用开发中,经常会遇到需要对现有的ViewModels进行扩展以满足新需求的情况。本章将探讨如何分析现有ViewModels的需求,并介绍扩展ViewModels的方法和技巧,最后对扩展后的ViewModels的数据呈现效果进行分析。
#### 3.1 对现有ViewModels的需求分析
在实际开发中,随着业务需求的变化,往往需要对现有的ViewModels进行扩展以适应新的数据展示需求。在进行扩展之前,首先需要对现有ViewModels的结构和数据进行仔细分析,确定需要新增的字段或功能,确保扩展后的ViewModels能够满足新的数据呈现需求。
#### 3.2 扩展ViewModels的方法和技巧
一种常见的方法是通过创建新的ViewModels类来扩展现有的ViewModels。新的ViewModels类可以继承现有ViewModels类的属性和方法,并添加新的属性和方法来满足新需求。另一种方法是通过ViewModels组合,即在现有ViewModels中添加新的属性或集合来扩展ViewModels的功能。
下面以Java语言为例,演示如何扩展现有的ViewModels类:
```java
// 现有的ViewModels类
public class UserViewModel {
private String username;
private String email;
// 省略getter和setter方法
}
// 扩展后的ViewModels类
public class ExtendedUserViewModel extends UserViewModel {
private int age;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
```
#### 3.3 扩展ViewModels后的数据呈现效果分析
扩展ViewModels后,可以根据新的数据结构和功能来展示数据。在页面上显示扩展后的ViewModels数据时,可以利用新添加的字段或方法进行数据展示和处理,提供更加丰富和灵活的数据呈现效果。通过扩展ViewModels,能够更好地适应业务的变化和扩展需求,提升Web应用的灵活性和可维护性。
本章介绍了如何扩展现有的ViewModels以满足新的数据呈现需求,强调了需求分析的重要性,以及对现有ViewModels进行扩展的方法和技巧。通过扩展ViewModels,能够有效地优化数据呈现效果,提升Web应用的用户体验和功能扩展性。
# 4. 应用领域驱动设计(DDD)原则
领域驱动设计(Domain Driven Design,DDD)是一种软件开发方法,旨在将软件设计的关注点放在处理复杂业务逻辑上。在Web应用程序中,应用DDD原则有助于更好地组织数据和业务逻辑,提高代码的可维护性和可扩展性。
#### 4.1 DDD在Web应用中的意义
在Web应用中,DDD可以帮助开发团队更好地理解业务需求,并将这些需求转化为可靠的软件模型。通过聚焦领域对象和业务规则的设计,可以使代码更易于理解、扩展和维护。
#### 4.2 如何将DDD原则应用于扩展ViewModels
将DDD原则应用于扩展ViewModels的过程中,首先需要对业务领域进行深入的分析,确定领域对象、值对象和业务规则。然后在ViewModels中结合这些概念,构建出符合业务需求的数据模型。
```java
// 示例代码:应用DDD原则扩展ViewModels
// 领域模型:订单
public class Order {
private int orderId;
private List<OrderItem> items;
private Customer customer;
// 省略Getter和Setter方法
}
// 值对象:订单明细
public class OrderItem {
private int productId;
private String productName;
private int quantity;
// 省略Getter和Setter方法
}
// ViewModel:订单ViewModel
public class OrderViewModel {
private int orderId;
private List<OrderItemViewModel> items;
private String customerName;
// 省略Getter和Setter方法
}
// ViewModel:订单明细ViewModel
public class OrderItemViewModel {
private int productId;
private String productName;
private int quantity;
// 省略Getter和Setter方法
}
```
#### 4.3 DDD原则对数据呈现灵活性的影响
应用DDD原则后,ViewModels更贴近业务领域模型,使数据呈现更加灵活和准确。通过合理设计领域对象和值对象,可以减少业务逻辑与数据呈现之间的耦合,提高系统的可维护性和扩展性。
在实际应用中,开发团队应该深入理解业务需求,结合DDD原则和ViewModels设计模式,构建出符合业务需求的灵活数据呈现方案,从而提升Web应用的质量和用户体验。
# 5. 利用依赖注入实现灵活的ViewModels
在本章中,我们将探讨如何利用依赖注入来实现灵活的ViewModels,提高数据呈现的效率和灵活性。
#### 5.1 依赖注入在MVC5中的应用
依赖注入是一种设计模式,通过该模式,类的依赖关系不在类内部创建,而是由外部容器负责创建。在MVC5中,依赖注入通常通过第三方容器(如Autofac、Ninject等)来实现,以实现模块的解耦和可维护性。
#### 5.2 构建可扩展的ViewModels的依赖注入实践
下面是一个使用Autofac实现依赖注入的示例代码:
```csharp
// 定义接口
public interface IDataProvider
{
List<Item> GetItems();
}
// 实现接口
public class DataProvider : IDataProvider
{
public List<Item> GetItems()
{
// 从数据库或其他数据源获取数据
return new List<Item>();
}
}
// 注册依赖关系
var builder = new ContainerBuilder();
builder.RegisterType<DataProvider>().As<IDataProvider>();
var container = builder.Build();
// 在Controller中使用依赖注入
public class HomeController : Controller
{
private readonly IDataProvider _dataProvider;
public HomeController(IDataProvider dataProvider)
{
_dataProvider = dataProvider;
}
public ActionResult Index()
{
var items = _dataProvider.GetItems();
return View(items);
}
}
```
#### 5.3 依赖注入对数据呈现的灵活性及效率的影响分析
通过依赖注入,我们可以将数据访问与ViewModels的逻辑解耦,提高代码的可测试性和可维护性。同时,依赖注入也可以提高数据呈现的效率,避免重复实例化对象,提升系统性能。
综上所述,依赖注入是实现灵活的ViewModels的重要手段,能够有效提高代码质量和开发效率。在实际项目中,合理应用依赖注入技术,可以为Web应用带来更好的用户体验和系统性能。
# 6. 案例分析与总结
在本章节中,我们将通过一个基于扩展的ViewModels的实际案例——巧租房系统来进行分析,并对全文的技术应用进行总结与展望。
### 6.1 基于扩展的ViewModels的巧租房系统实例分析
#### 场景介绍:
假设我们要开发一个巧租房系统,用户可以通过系统查看各种出租房源信息、发布自己的出租信息以及进行房屋租赁等操作。我们将使用扩展的ViewModels来优化数据呈现和操作逻辑。
#### 代码实现(Python版本):
```python
# 定义基本房屋信息ViewModel
class HouseViewModel:
def __init__(self, address, price, area):
self.address = address
self.price = price
self.area = area
# 扩展房屋信息ViewModel,增加房东联系方式
class ExtendedHouseViewModel(HouseViewModel):
def __init__(self, address, price, area, landlord_contact):
super().__init__(address, price, area)
self.landlord_contact = landlord_contact
# 模拟获取房屋信息的函数
def get_house_info():
# 假设从数据库中获取房屋信息
house_data = {
"address": "123 Main St",
"price": 1000,
"area": 80,
"landlord_contact": "123-456-7890"
}
return house_data
# 使用扩展后的ViewModel获取房屋信息
house_data = get_house_info()
house_view_model = ExtendedHouseViewModel(house_data["address"], house_data["price"], house_data["area"], house_data["landlord_contact"])
# 输出房屋信息
print(f"Address: {house_view_model.address}")
print(f"Price: ${house_view_model.price}")
print(f"Area: {house_view_model.area} sq. ft.")
print(f"Landlord Contact: {house_view_model.landlord_contact}")
```
#### 代码总结:
通过扩展ViewModel,我们可以更灵活地处理房屋信息,并在需要时添加额外的信息(如房东联系方式)。这样可以使数据呈现更加完善,同时保持代码结构清晰。
#### 结果说明:
以上代码演示了如何利用扩展的ViewModel来展示房屋信息,并成功输出了房屋的地址、价格、面积以及房东联系方式。
### 6.2 本文技术应用总结与展望
在本文中,我们深入探讨了在MVC5中ViewModels的作用和重要性,介绍了设计模式、扩展现有ViewModels、领域驱动设计原则、依赖注入等在构建灵活数据呈现中的应用。通过案例分析,我们展示了如何利用扩展的ViewModels实现房屋信息的定制化展示。
未来,我们可以进一步探讨更多复杂场景下ViewModels的应用、优化数据呈现的方法以及与其他技术的结合,为Web应用开发提供更多可能性。
这就是本文的案例分析与总结部分,通过实例展示了扩展ViewModels的实际应用场景和效果,同时对全文的技术应用进行了总结和展望。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏"MVC5 EF6实战:巧租房系统开发"将深入探讨在MVC5框架下结合EF6技术进行巧租房系统的开发过程。从Controller的详细解析到数据持久化操作的实现,再到数据验证与安全管理、用户身份验证与授权管理等方面的讨论,逐步扩展至ViewModels的灵活运用和前端开发效率的提升。此外,针对EF6的数据查询、存储过程与函数的应用、异步编程与并发控制等高级技巧也将得到充分探讨,以提升系统性能与响应速度。专栏内容还将涉及jQuery与Ajax的动态页面交互、JavaScript与MVC5的结合开发等,旨在为读者呈现如何打造一个功能强大、安全可靠、灵活高效的巧租房系统的全方位指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
市场营销的未来:随机森林助力客户细分与需求精准预测

# 1. 市场营销的演变与未来趋势
市场营销作为推动产品和服务销售的关键驱动力,其演变历程与技术进步紧密相连。从早期的单向传播,到互联网时代的双向互动,再到如今的个性化和智能化营销,市场营销的每一次革新都伴随着工具、平台和算法的进化。
## 1.1 市场营销的历史沿
细粒度图像分类挑战:CNN的最新研究动态与实践案例

# 1. 细粒度图像分类的概念与重要性
随着深度学习技术的快速发展,细粒度图像分类在计算机视觉领域扮演着越来越重要的角色。细粒度图像分类,是指对具有细微差异的图像进行准确分类的技术。这类问题在现实世界中无处不在,比如对不同种类的鸟、植物、车辆等进行识别。这种技术的应用不仅提升了图像处理的精度,也为生物多样性
自然语言处理新视界:逻辑回归在文本分类中的应用实战

# 1. 逻辑回归与文本分类基础
## 1.1 逻辑回归简介
逻辑回归是一种广泛应用于分类问题的统计模型,它在二分类问题中表现尤为突出。尽管名为回归,但逻辑回归实际上是一种分类算法,尤其适合处理涉及概率预测的场景。
## 1.2 文本分类的挑战
文本分类涉及将文本数据分配到一个或多个类别中。这个过程通常包括预处理步骤,如分词、去除停用词,以及特征提取,如使用词袋模型或TF-IDF方法
支持向量机在语音识别中的应用:挑战与机遇并存的研究前沿

# 1. 支持向量机(SVM)基础
支持向量机(SVM)是一种广泛用于分类和回归分析的监督学习算法,尤其在解决非线性问题上表现出色。SVM通过寻找最优超平面将不同类别的数据有效分开,其核心在于最大化不同类别之间的间隔(即“间隔最大化”)。这种策略不仅减少了模型的泛化误差,还提高了模型对未知数据的预测能力。SVM的另一个重要概念是核函数,通过核函数可以将低维空间线性不可分的数据映射到高维空间,使得原本难以处理的问题变得易于
梯度下降在线性回归中的应用:优化算法详解与实践指南

# 1. 线性回归基础概念和数学原理
## 1.1 线性回归的定义和应用场景
线性回归是统计学中研究变量之间关系的常用方法。它假设两个或多个变
RNN可视化工具:揭秘内部工作机制的全新视角

# 1. RNN可视化工具简介
在本章中,我们将初步探索循环神经网络(RNN)可视化工具的核心概念以及它们在机器学习领域中的重要性。可视化工具通过将复杂的数据和算法流程转化为直观的图表或动画,使得研究者和开发者能够更容易理解模型内部的工作机制,从而对模型进行调整、优化以及故障排除。
## 1.1 RNN可视化的目的和重要性
可视化作为数据科学中的一种强
K-近邻算法多标签分类:专家解析难点与解决策略!

# 1. K-近邻算法概述
K-近邻算法(K-Nearest Neighbors, KNN)是一种基本的分类与回归方法。本章将介绍KNN算法的基本概念、工作原理以及它在机器学习领域中的应用。
## 1.1 算法原理
KNN算法的核心思想非常简单。在分类问题中,它根据最近的K个邻居的数据类别来进行判断,即“多数投票原则”。在回归问题中,则通过计算K个邻居的平均
决策树在金融风险评估中的高效应用:机器学习的未来趋势
# 1. 决策树算法概述与金融风险评估
## 决策树算法概述
决策树是一种被广泛应用于分类和回归任务的预测模型。它通过一系列规则对数据进行分割,以达到最终的预测目标。算法结构上类似流程图,从根节点开始,通过每个内部节点的测试,分支到不
LSTM股票市场预测实录:从成功与失败中学习
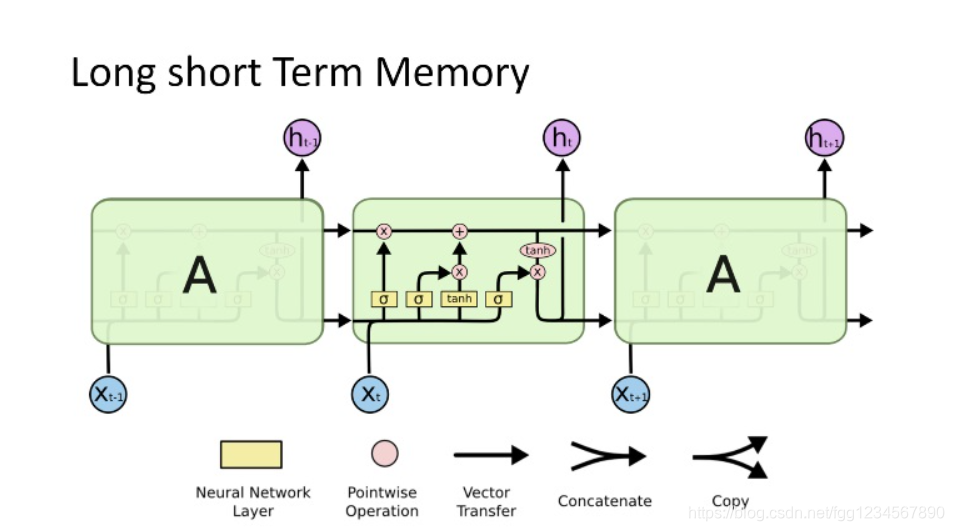
# 1. LSTM神经网络概述与股票市场预测
在当今的金融投资领域,股票市场的波动一直是投资者关注的焦点。股票价格预测作为一项复杂的任务,涉及大量的变量和
神经网络硬件加速秘技:GPU与TPU的最佳实践与优化

# 1. 神经网络硬件加速概述
## 1.1 硬件加速背景
随着深度学习技术的快速发展,神经网络模型变得越来越复杂,计算需求显著增长。传统的通用CPU已经难以满足大规模神经网络的计算需求,这促使了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )