




罗斯模型实战篇:统计模拟中的进程复制与重命名优化


通信与网络中的贝尔罗斯推出HDF天线技术
摘要
罗斯模型作为一种先进的统计模拟工具,已在多个领域展现出其理论与实践价值。本文首先概述了罗斯模型及其统计模拟的基础知识,并深入探讨了模型的理论框架和编程实现。接着,本文重点分析了统计模拟中的进程复制策略,阐述了其基本原理及在模拟中的重要性,并提出了设计与优化高效进程复制策略的方法。此外,还研究了文件重命名机制的基础知识及其在统计模拟中的应用,探索了编程和系统层面的优化技巧。最后,通过实战应用案例分析,本文展示了罗斯模型在实际问题中的应用效果以及进程复制和重命名优化对统计模拟效率的影响。整体而言,本文为理解和应用罗斯模型、进程复制策略与文件重命名优化提供了全面的理论支持和实践指导。
关键字
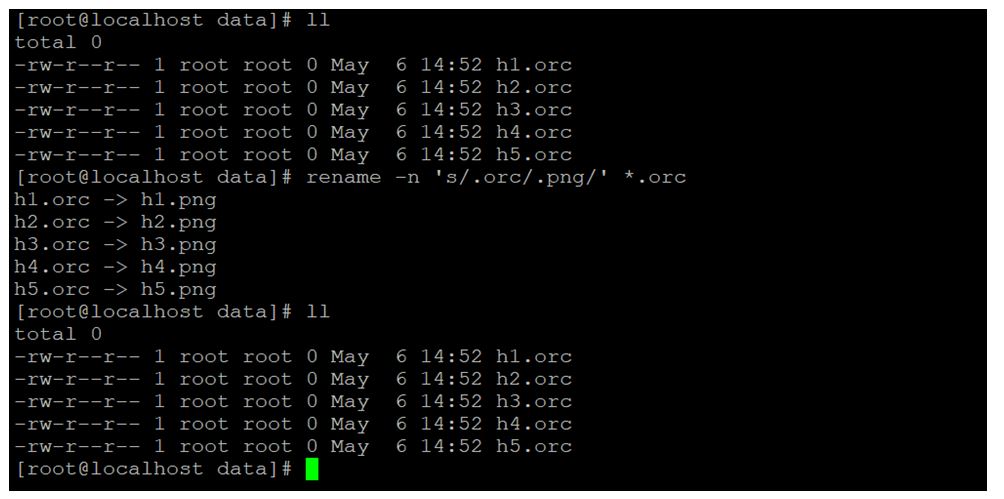
罗斯模型;统计模拟;进程复制策略;文件重命名;编程实现;优化技巧
参考资源链接:Simufact.welding4.0焊接热源模型校核与计算进程复制
1. 罗斯模型与统计模拟概述
在当代IT领域,统计模拟技术愈发成为解决复杂问题不可或缺的工具。在众多模型中,罗斯模型以其独特的统计特性和广泛的应用领域独树一帜。本章旨在为读者提供罗斯模型与统计模拟的入门概览,帮助读者建立初步的理论基础和实践方向。
1.1 统计模拟的概念和重要性
统计模拟,通常指使用随机抽样和统计模型来预测和分析复杂系统的可能性。它通过模拟来近似现实世界中的随机过程,从而为决策者提供关于未来可能情景的见解。罗斯模型,作为一种高级的统计技术,能够通过模拟手段,预测变量间的关系以及它们随时间变化的趋势。
1.2 罗斯模型在行业中的应用
罗斯模型在不同行业有着广泛的应用,从金融风险分析到生物统计、从社交网络分析到供应链管理等,都能看到它的身影。这主要是因为它能够帮助分析师处理不确定性和动态变化,这对于理解复杂系统的动态行为至关重要。通过本章节的介绍,读者将了解到罗斯模型的基本原理,以及如何利用它进行初步的统计模拟。
2. 罗斯模型的理论基础与实现
2.1 罗斯模型理论框架
2.1.1 模型的数学描述
罗斯模型(Ross Model)是一种基于概率论和随机过程的数学模型,常用于风险管理和金融产品的定价。模型的核心思想是将潜在损失的概率分布分解为若干简单的部分,从而便于理解和计算。在数学上,罗斯模型可以通过以下公式进行描述:
- L = Σ (P_i * C_i)
其中,L 表示潜在损失,P_i 是第 i 种情况发生的概率,C_i 是与之对应的损失金额。这种模型的关键在于能够合理地估计 P_i 和 C_i 的值,并将这些值与实际的风险管理和决策过程联系起来。
2.1.2 模型参数的确定与意义
模型参数的确定是罗斯模型实现中的关键步骤。参数的确定方法通常涉及统计分析和假设检验。例如,损失概率 P_i 可以通过历史数据和概率密度函数来确定;损失金额 C_i 可以基于保险赔付历史来估计。
参数的意义在于它们决定了模型的预测能力和实用性。一个准确的罗斯模型需要准确的参数作为支撑,才能在风险评估和金融产品定价中发挥作用。例如,在信用风险评估中,参数的确定直接关系到违约概率的准确度,进而影响贷款定价和资本充足率的计算。
2.2 罗斯模型的编程实现
2.2.1 编程语言选择与环境搭建
在罗斯模型的实现中,编程语言的选择依赖于模型的复杂度、计算效率和可维护性等因素。Python 通常是一个不错的选择,因为它具有丰富的数学和统计库,如 NumPy、SciPy 和 pandas,同时也支持面向对象编程和函数式编程,便于模型的快速原型设计和开发。
环境搭建是编程实现的第一步。使用 Python 时,开发者可能需要安装 Anaconda 分发版,它集成了大量科学计算所需的包。在命令行中运行以下命令,即可安装 Anaconda:
- wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh
- bash Anaconda3-2020.07-Linux-x86_64.sh
2.2.2 模型核心算法的代码实现
在搭建好开发环境后,接下来是罗斯模型核心算法的编程实现。这里我们可以通过一个简单的 Python 代码示例来展示如何计算罗斯模型中的潜在损失 L:

在这个代码示例中,我们定义了一个名为 ross_model 的函数,它接收两个列表作为参数:损失概率和损失金额。函数通过列表解析式将每个概率与其对应的损失金额相乘

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
OpenResty缓存管理:4个策略让你的应用响应如飞
SVG动画SEO优化大揭秘:提高网页可见性的6个动画策略
【S7-PLCSIM与实际PLC同步】:最佳实践与实战技巧,无缝部署
【表空间扩展实战】:Oracle如何安全避免ORA-01654
【STC8单片机串口通信深度剖析】:从初始化到故障排除的全攻略
自动化脚本编写与管理技巧:LECP Server脚本编程指南
【DXF块与引用深入解析】:DXFLib-v0.9.1.zip助你精通DXF结构
ATF54143芯片调试宝典:常见问题速查与解决
【备份与恢复指南】:三启动U盘在数据安全中的关键作用


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















