Python在商品市场分析中的应用:供需分析与价格预测
发布时间: 2025-01-05 13:55:27 阅读量: 7 订阅数: 13 

星之语明星周边产品销售网站的设计与实现-springboot毕业项目,适合计算机毕-设、实训项目、大作业学习.zip

# 摘要
本文系统地探讨了Python在数据分析领域的基础应用、数据预处理、供需分析、价格预测以及实际案例研究。通过对Python语言核心特性的介绍,分析了其在数据分析中的关键作用,包括数据清洗、转换、探索及可视化技巧。文中进一步阐述了Python在供应链数据整合、需求预测、供给能力评估等方面的具体实践,展示了机器学习和深度学习技术在价格预测中的应用,并讨论了模型开发、训练、评估和部署的流程。最后,本文基于案例研究,讨论了Python数据分析的现状,并前瞻了未来技术趋势、挑战和研究方向,如数据隐私、安全性和新兴技术的伦理考量。
# 关键字
Python;数据分析;数据预处理;供需分析;价格预测;机器学习
参考资源链接:[使用Python进行量化金融分析:深度学习与实战](https://wenku.csdn.net/doc/64657f2e543f844488aa406a?spm=1055.2635.3001.10343)
# 1. Python基础及其在数据分析中的作用
## 简介
Python作为一门跨领域的编程语言,在数据分析领域发挥着重要作用。它不仅拥有简洁易读的语法,还拥有强大的社区支持和大量的数据处理库,使得数据分析的门槛大大降低。
## Python在数据分析中的作用
Python的模块化设计使其在处理和分析大量数据时表现卓越。通过NumPy、Pandas和SciPy等库,Python能够快速进行数值计算和数据操作,成为数据科学家的首选工具。Matplotlib和Seaborn库的加入更是让数据可视化变得简单而直观。在数据分析过程中,Python扮演着数据清洗、处理、分析和展示的关键角色。
## Python的优势
Python的优势在于其开源和社区支持,这意味着不断有新的工具和库被开发出来,以支持最新的数据分析技术。此外,Python与机器学习和深度学习库如scikit-learn、TensorFlow和PyTorch的无缝集成,使得构建高级分析模型变得轻而易举。Python的灵活性也意味着它能够与SQL、Excel等传统数据处理工具轻松集成,为数据分析师提供了一个强大的工作环境。
# 2. Python数据预处理技巧
## 2.1 数据清洗与整理
### 2.1.1 缺失值处理
在数据分析过程中,遇到含有缺失值的场景是常见且不可避免的。这些缺失值可能是因为多种原因,比如数据收集时的遗漏、数据传输的失败或者在数据导入过程中产生的问题。Python中处理缺失值有多种方法,我们可以通过以下步骤来实现数据清洗和整理:
1. **识别缺失值**:首先需要找出数据集中的缺失值,可以使用Pandas库提供的方法。例如,`isnull()`函数可以返回一个布尔型DataFrame,标识数据中的缺失值位置。
```python
import pandas as pd
# 加载数据集
df = pd.read_csv('dataset.csv')
# 识别数据中的缺失值
missing_values = df.isnull()
```
2. **处理缺失值**:处理缺失值的方法有多种,比如删除含有缺失值的行或列、用平均值或中位数填充、或者用其他模型进行预测填充。
```python
# 删除含有缺失值的行
df_dropped = df.dropna()
# 使用平均值填充数值型数据的缺失值
df_filled = df.fillna(df.mean())
# 使用中位数填充数值型数据的缺失值
df_filled_median = df.fillna(df.median())
```
3. **缺失值的影响**:理解缺失值处理对数据分析和结果的影响是关键。例如,删除含有缺失值的记录可能会导致数据量显著减少,而填充则可能会引入偏差。
4. **缺失值处理策略的选择**:选择合适的缺失值处理策略依赖于数据的特性和分析的目标。在一些情况下,可能需要进行更复杂的数据填充,比如使用模型预测或者根据业务逻辑手动定义缺失值。
### 2.1.2 异常值识别与处理
异常值是偏离正常值范围的数据点,可能是由真实的异常情况产生,也可能是数据收集和输入过程中的错误。正确地识别和处理异常值对于数据分析至关重要。以下是异常值识别与处理的一般步骤:
1. **统计方法**:使用统计度量如四分位数间距(IQR)和均值、标准差等来识别异常值。
```python
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
# 识别异常值范围外的数据点
df_filtered = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)]
```
2. **可视化方法**:利用箱线图、散点图等可视化工具直观地标识和分析异常值。
```python
import matplotlib.pyplot as plt
# 制作箱线图
plt.figure(figsize=(10,6))
plt.boxplot(df['column_name'], vert=False)
plt.title('Boxplot')
plt.show()
```
3. **处理策略**:异常值的处理策略包括删除、变换和保留。删除异常值可能会影响数据的完整性,而变换和保留则需要根据具体情况来判断是否合理。
## 2.2 数据转换与归一化
### 2.2.1 数据编码方法
数据编码是将非数值型数据转换为数值型数据的过程,它是数据预处理中极其重要的一步。以下是常见的数据编码方法:
1. **独热编码(One-Hot Encoding)**:将分类变量转换成一组二进制变量,每个分类值对应一个列,适用于无序分类数据。
```python
# 将分类列转换为独热编码
df_encoded = pd.get_dummies(df['categorical_column'], drop_first=True)
```
2. **标签编码(Label Encoding)**:将分类值转换为整数,适用于有序分类数据。
```python
from sklearn.preprocessing import LabelEncoder
# 对分类数据进行标签编码
label_encoder = LabelEncoder()
df['encoded_column'] = label_encoder.fit_transform(df['categorical_column'])
```
3. **二进制编码(Binary Encoding)**:先将数据标签转换为二进制表示,再将二进制数分割为几个部分,并将它们表示为一个数值。
```python
from category_encoders import binary
# 使用二进制编码
binary_encoder = binary.BinaryEncoder(cols=['categorical_column'])
df_encoded = binary_encoder.fit_transform(df)
```
### 2.2.2 归一化与标准化技术
归一化和标准化是调整数值数据的范围和分布的方法,它们对于算法的性能和收敛速度有着直接的影响。以下是一些常见的技术:
1. **最小-最大归一化(Min-Max Normalization)**:将数据缩放到一个特定的范围,通常是0到1之间。
```python
from sklearn.preprocessing import MinMaxScaler
# 对数据进行归一化
scaler = MinMaxScaler()
df_normalized = scaler.fit_transform(df[['numeric_column']])
```
2. **标准化(Standardization)**:将数据转换为具有0均值和单位方差的分布。
```python
from sklearn.preprocessing import StandardScaler
# 对数据进行标准化
scaler = StandardScaler()
df_standardized = scaler.fit_transform(df[['numeric_column']])
```
3. **L1和L2归一化**:L1和L2归一化是对向量进行处理,使得向量的L1范数或L2范数为1,常用在需要数据为单位向量的场景,如文本数据处理。
## 2.3 数据探索与可视化
### 2.3.1 描述性统计分析
描述性统计分析是数据分析的起点,提供对数据集基本特征的快速概览。以下是一些基本的描述性统计分析方法:
1. **基本统计量**:包括均值、中位数、标准差、偏度、峰度等。
```python
# 获取描述性统计量
df_description = df.describe()
```
2. **分组统计**:如果数据集包含分类变量,可以使用`groupby`方法按类别分组,然后计算每个组的统计量。
```python
# 按分类变量分组并获取统计量
grouped_stats = df.groupby('categorical_column').describe()
```
### 2.3.2 利用图表发现数据间关系
图表是发现和展示数据间关系的重要工具。以下是几种常见的图表类型:
1. **散点图(Scatter Plot)**:用于显示两个变量之间的关系。
```python
# 制作散点图
plt.scatter(df['variable1'], df['variable2'])
plt.xlabel('Variable 1')
plt.ylabel('Variable 2')
plt.title('Scatter Plot')
plt.show()
```
2. **箱线图(Box Plot)**:用于展示数据分布情况,特别适用于识别异常值。
```python
# 制作箱线图
plt.figure(figsize=(10,6))
plt.boxplot(df['variable1'], vert=False)
plt.title('Boxplot')
plt.show()
```
3. **直方图(Histogram)**:用于展示数据分布的频率。
```python
# 制作直方图
plt.hist(df['variable1'], bins=20)
plt.title('Histogram')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
```
## 2.4 数据预处理实践案例
### 2.4.1 数据预处理流程演示
在本节中,我们将演示一个数据预处理的完整流程。首先,通过代码展示如何加载数据、识别缺失值和异常值,并进行处理。
```python
import pandas as pd
import numpy as np
# 加载数据集
df = pd.read_csv('example_dataset.csv')
# 缺失值处理
df.fillna(df.mean(), inplace=True) # 用均值填充缺失值
# 异常值处理
# 这里使用简单的方法,仅作为一个示例
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
df = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)]
# 继续其他预处理步骤,如数据编码、归一化等
```
### 2.4.2 实际应用中数据预处理的复杂性
在实际应用中,数据预处理的复杂性远超以上示例。真实的数据往往需要处理多种类型的数据问题,包括但不限于数据类型转换、数据降维、文本数据清洗等。数据预处理流程可能需要多次迭代和调整。
```python
# 数据类型转换
df['text_column'] = df['text_column'].astype(str)
# 数据降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
df[['principal_component_1', 'principal_component_2']] = pca.fit_transform(df.drop('target_column', axis=1))
# 文本数据清洗
df['text_column'] = df['text_column'].str.lower().str.replace(r'[^\w\s]', '')
```
通过这些步骤,我们可以把原始的数据集转换成结构良好、适合机器学习模型训练的格式。总之,数据预处理是数据分析和机器学习工作中不可或缺的环节,对于最终分析结果的质量有着深远的影响。
# 3. Python在供需分析中的实践应用
## 3.1 供应链数据的收集与整合
### 3.1.1 Web爬虫技术
在当今的商业环境中,有效地收集和整合供应链数据是至关重要的。Python的Web爬虫技术,特别是使用requests和BeautifulSoup库,为数据收集提供了便捷的途径。以下是一个简单的例子,展示如何使用Python来爬取网页上的产品信息。
```python
import requests
from bs4 import BeautifulSoup
# 目标网页的URL
url = 'http://example.com/products'
# 发送HTTP请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 使用Be
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python金融数据分析入门》专栏提供了一条清晰的进阶路径,从初学者到专家,涵盖Python在金融领域的广泛应用。专栏深入探讨了Python在金融市场预测、风险管理、高频交易、投资组合管理、信用评分、欺诈检测、数据可视化、股票市场分析、债券市场分析、商品市场分析、保险行业和财富管理中的应用。通过模型构建、优化、策略和工具,该专栏提供了实用指南,帮助金融专业人士充分利用Python的强大功能,提高决策制定、风险管理和投资绩效。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【正交编码器专家解读】:揭秘D触发器在鉴相电路中的核心作用
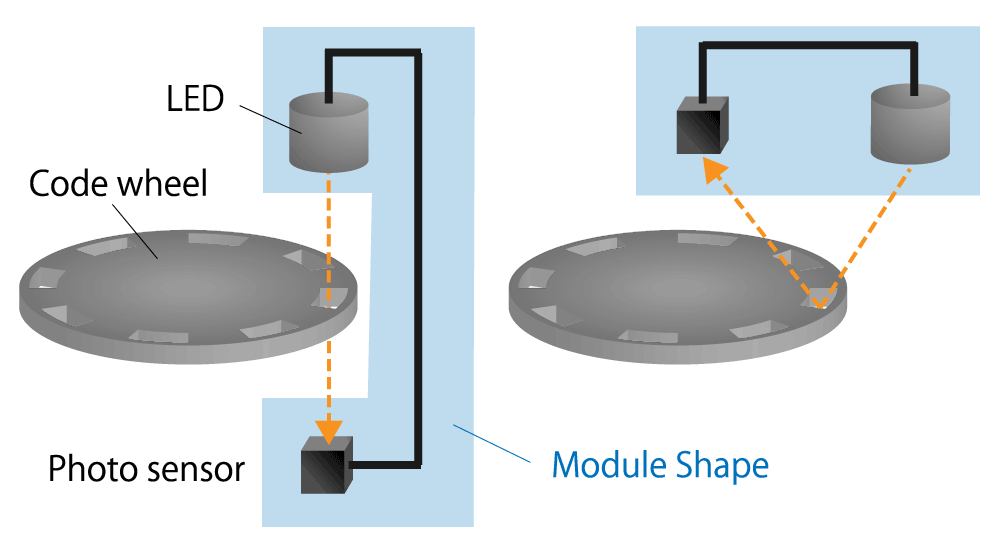
# 摘要
正交编码器和D触发器是数字电路设计中的关键技术
【软件质量提升】:自动化测试框架的高级技巧
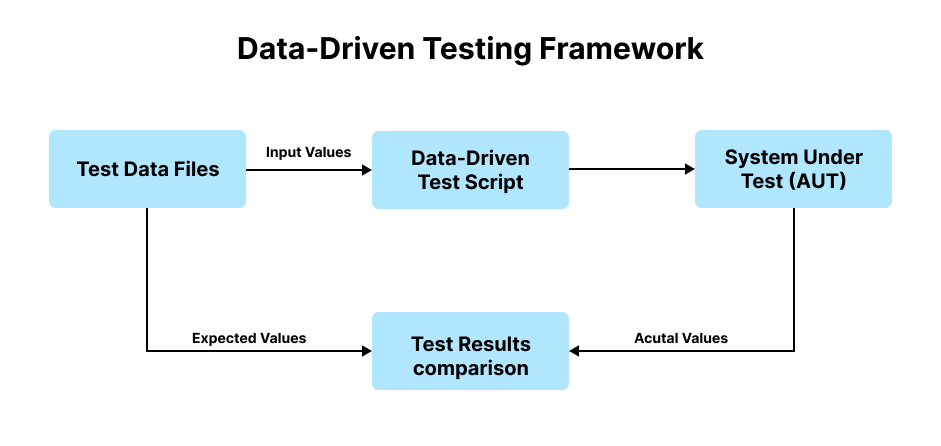
# 摘要
本文对自动化测试框架进行了全面的探讨。首先概述了自动化测试框架的基本概念和理论基础,涵盖了测试驱动开发(TDD)和行为驱动开发(BDD)等关键原理。接着,文章分类讨论了不同类型的测试框架,如单元测试、集成测试和端到端测试,并分析了测试框架的关键组件,如测试用例管理和报告生成。在实践技巧部分,本文着重介绍了设计高效的测试用例,包括可重用组件的构建和测试数据环境的管理。文章第四部分讨论了
CoDeSys+2.3跨平台开发实战:在不同操作系统中轻松部署应用!
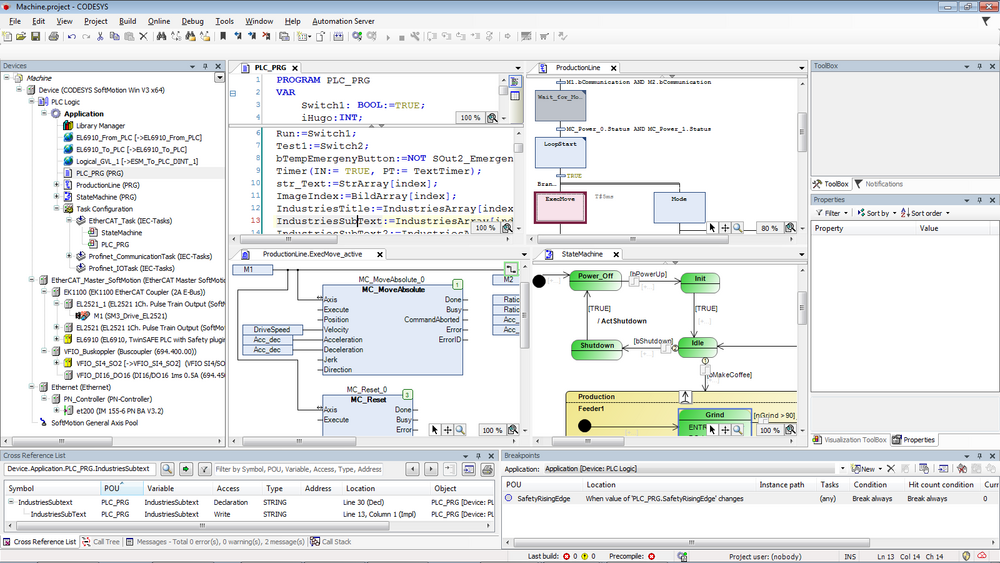
# 摘要
CoDeSys+2.3是一个支持跨平台开发的自动化软件解决方案,它提供了强大的编程环境和工具链。本文介绍了CoDeSys+2.3的基本概念、开发环境的搭建过程,以及在不同操作系统下的安装和配置方法。同时,本文深入探讨了CoDeSys+2.3的编程技巧、项目结构组织,以及如何实现跨平台项目管理和版本控制。此外,本文还涉及了
【ArcEngine高级应用】:解决查询结果闪烁的终极解决方案

# 摘要
本文针对ArcEngine的查询机制进行了深入分析,探讨了其数据模型、标准查询方法以及查询结果的处理和呈现方式。重点研究了查询结果闪烁问题的理论基础,分析了其成因并提出了性能优化策略,包括渲染管线优化、硬件加速的应用、分层渲染技术和双缓冲技术等。实践操作部分详细介绍了查询优化实践、缓存机制的应用,并通过实际案例分析展示了解决方案的效果。
热传导故障排除宝典:Ansys分析实例与解决策略
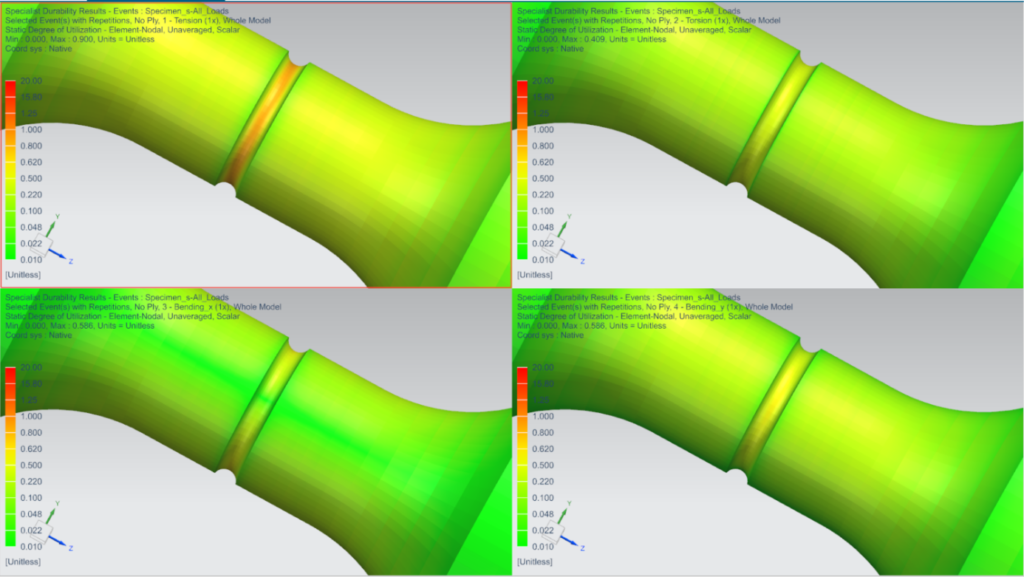
# 摘要
本论文系统地探讨了热传导理论基础与数值分析方法,并通过Ansys软件的应用,深入解析了热传导模拟的建模流程、边界条件设置、热流体耦合分析以及热应力与热变形问题。通过案例分析,我们展示了热传导模拟实践应用,并总结了故障排除策略,包括问题诊断、故障排查和结果验证。高级热传导分析案例研究涉及多物理场耦合处理、瞬态热传导和非线性分析,展望
【存储管理优化】:提升多用户文件系统的空间利用率与性能

# 摘要
本论文综合探讨了存储管理优化的多个关键方面,从多用户文件系统的基础理论入手,分析了在多用户环境下存储管理面临的挑战及性能评估与优化目标。接着,本文深入介绍了提高存储空间利用率的多种技术手段,如压缩技术、磁盘配额及监控和文件去重与归档。此外,文章还探讨了系统性能调优的策略与实践,包括缓存机制优化、I/O调度算法的选择与调整以及资源配额与负载均衡技术的应
【银行数据模型优化全攻略】:揭秘TeraData十大主题模型提升数据处理效率的终极秘籍
# 摘要
随着信息技术的发展,银行数据模型优化已成为提高业务效率和管理水平的关键。本文首先概述了银行数据模型优化的必要性和总体情况。接着详细介绍了TeraData的基础知识和数据模型,特别强调了TeraData中十大主题模型的应用和优化策略。第四章深入讨论了性能评估、实际案例分析和持续性改进流程。最后一章展望了大数据、人工智能和云计算技术与
【性能监控秘技】:CMWrun测试执行中的性能监控与优化
# 摘要
性能监控是确保系统稳定性和效率的关键环节,而CMWrun作为一种性能监控工具,在理论与实践方面均显示出其重要性。本文首先介绍了性能监控的基础知识及CMWrun工具的概述,随后深入探讨了CMWrun在实际性能监控应用中的配置、实时监控、数据分析、问题诊断和性能瓶颈优化。进一步地,文章分析了CMWrun在性能测试中的高级应用,包括数据深度分析、自动化性能优
【dSPACE MicroAutoBoxII完全攻略】:一步到位掌握硬件软件架构与故障排查

# 摘要
本文详细介绍了dSPACE MicroAutoBoxII的软硬件架构及其应用。首先,文章概述了MicroAutoBoxII的硬件组成,包括其主要组件、扩展能力和安装配置。其次,软件架构部分讨论了操作系统选择、开发环境搭建以及软件组件和API接口的功能。进一步地,本文探讨了在实践案例中如何进行故障
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )