【Kafka快速精通秘籍】:Java高效消息处理实践指南
发布时间: 2024-09-30 08:58:36 阅读量: 21 订阅数: 30 
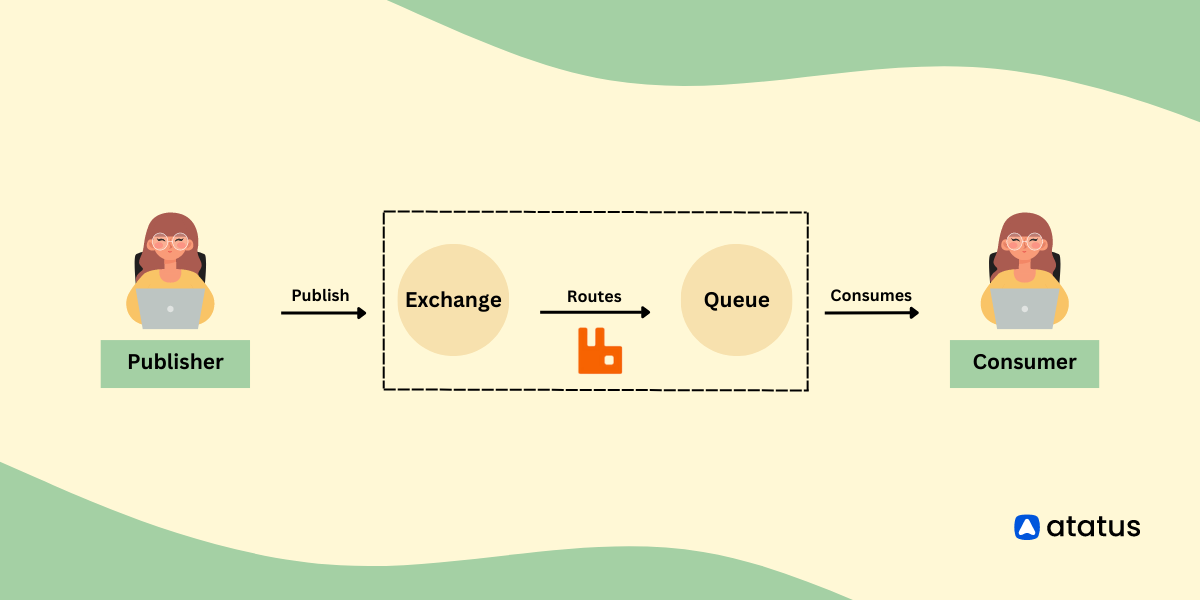
# 1. Kafka基础入门
## 1.1 Kafka简介
Apache Kafka是一个分布式的流处理平台,最初由LinkedIn公司开发,它主要用于构建实时数据管道和流应用程序。Kafka的设计目标是在大规模分布式系统中提供高吞吐量和低延迟的数据处理能力。
## 1.2 Kafka的核心概念
在Kafka中,有几个核心概念需要理解:
- **Brokers**:Kafka集群包含一个或多个服务器,这些服务器被称为Brokers。
- **Topics**:发布到Kafka集群的消息被归类到一个或多个主题(Topics)中。
- **Producers**:消息的生产者,负责把数据发送到Kafka的Topic中。
- **Consumers**:消息的消费者,订阅一个或多个主题,并处理发布的消息。
## 1.3 Kafka的工作流程
消息首先由生产者Producers发送到指定的Topic中,然后由Kafka Broker进行处理和存储。消费者Consumers从Broker中拉取(或订阅)它们感兴趣的数据流进行处理。
下面是一个简单的生产者示例代码,用于向Kafka发送消息:
```java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class SimpleProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "***mon.serialization.StringSerializer");
props.put("value.serializer", "***mon.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "key", "value");
producer.send(record);
producer.close();
}
}
```
在本章节中,我们将从零开始了解Kafka的基础知识,为深入学习和应用Kafka打下坚实的基础。
# 2. 深入理解Kafka架构
在大数据的流转中,Kafka扮演了一个信息高速公路的重要角色。它的高性能、可扩展性、以及容错能力为数据的生产和消费提供了一个可靠的平台。本章节将深入解析Kafka的内部架构,揭示其核心组件的工作原理,以及生产者和消费者如何与之交互,最后探讨其存储机制和文件系统的实现细节。
## 2.1 Kafka核心组件解析
### 2.1.1 Broker与Topic的交互原理
Kafka中的Broker可以理解为消息代理服务器,每个Broker负责维护一部分消息数据,并且对外提供服务。Broker在消息传递的过程中起到了重要的枢纽作用。一个Topic代表一类消息,而每个Topic会被分割成多个Partition,分布在不同的Broker上。
#### **交互过程**
当一个消息生产者(Producer)需要发送消息时,首先会根据消息键(Key)来确定消息应该被发送到哪个Partition上。这个决策过程可以是随机的,也可以根据特定的算法来决定,例如使用哈希函数。
一旦消息发送到Broker上,它将被追加到该Partition的末尾。每个Partition的消息都是有序的,并且每个Broker都会记录自己的日志文件(Log file),确保消息持久化存储。
消费者(Consumer)订阅特定的Topic,然后从指定的Partition中拉取消息。如果消费者位于一个消费者群组(Consumer Group)中,Kafka可以实现负载均衡,允许群组中的每个消费者消费不同的Partition,从而实现并行处理消息。
```mermaid
flowchart LR
Producer --消息--> Broker
Broker --消息--> Topic
Topic -.-> Partition[Partition]
Partition --消息--> Consumer
```
### 2.1.2 Partition的分布策略
Kafka的高性能很大程度上取决于Partition的设计。一个Topic可以跨越多个Broker,而Topic下的每个Partition则会均匀地分布在不同的Broker上,从而实现水平扩展。
#### **均匀分布**
均匀分布的目的是为了平衡负载。为了达到这个目标,Kafka会尽量确保每个Broker上承载的Partition数量相同。Kafka通过增加Partition的复制因子(Replica Factor)来保证高可用性,每个Partition可以有多个副本分布在不同的Broker上。
分区的均匀分布对维护集群的稳定性至关重要。它有助于避免因为某些Broker的负载过高而产生瓶颈。
```mermaid
graph LR
A[Broker 1] -->|Partition 1<br>Replica 1| B[Broker 2]
A -->|Partition 2<br>Replica 1| C[Broker 3]
B -->|Partition 2<br>Replica 2| C
B -->|Partition 3<br>Replica 1| A
C -->|Partition 1<br>Replica 2| A
C -->|Partition 3<br>Replica 2| B
```
## 2.2 Kafka生产者和消费者模型
### 2.2.1 消息生产者的设计与实现
Kafka生产者负责将数据发送到Broker。其设计理念包括高效的消息排序、负载均衡、容错和消息去重等。
#### **负载均衡**
生产者为了实现负载均衡,会使用一种分区器(Partitioner),通常是根据消息键(Key)来决定消息应该发送到哪个Partition。如果消息没有键,生产者会使用轮询(Round-Robin)算法均匀地将消息发送到不同的Partition。
生产者在发送消息时,可以选择同步(sync)或异步(async)发送。同步发送会等待服务器的响应,保证消息的可靠性,但是会降低性能。而异步发送可以提高性能,但是可能会导致消息的丢失。
```java
ProducerRecord<String, String> record = new ProducerRecord<>("my_topic", "key", "value");
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("Message sent successfully: " + metadata.offset());
} else {
exception.printStackTrace();
}
}
});
```
在上面的Java代码示例中,`send()`方法是异步的,它接受一个`Callback`参数。一旦消息被发送,回调函数会被触发。
### 2.2.2 消息消费者的机制与优化
消费者负责从Broker拉取消息。消费者会加入到一个消费者群组,由群组中的协调器(Coordinator)负责管理。群组内的消费者会共享Partition的消费权。
#### **群组协调和分区重平衡**
消费者与Broker之间的通信基于心跳机制,当消费者失效时,Broker可以检测到并触发分区重平衡(Rebalance)。重平衡保证了消费的公平性和容错性,确保所有活跃的消费者可以重新分配Partition的消费。
消费者可以通过调整拉取间隔(Poll Interval)和批量大小(Batch Size)来优化性能。适当增加这些参数可以减少网络I/O的次数,但同时也会增加内存的使用和消息处理的延迟。
```java
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "***mon.serialization.StringDeserializer");
props.put("value.deserializer", "***mon.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my_topic"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
// Process the record
}
}
} finally {
consumer.close();
}
```
在上述代码中,消费者首先订阅了一个名为`my_topic`的Topic,然后循环调用`poll()`方法来不断拉取消息并进行处理。
## 2.3 Kafka的存储机制与文件系统
### 2.3.1 日志结构和索引机制
Kafka的消息存储采用日志结构,这意味着消息是顺序追加到日志文件中的。这种顺序写入的模式具有很高的写入性能,因为磁盘的顺序读写比随机读写要快得多。
#### **消息格式和索引**
每条消息都包含了键(Key)、值(Value)和时间戳等信息。除了消息本身,Kafka还使用索引来定位消息在日志文件中的位置。索引文件将时间戳或偏移量映射到日志文件的物理位置。
索引是稀疏的,也就是说,并不是每条消息都有一个索引条目。默认情况下,Kafka会为每个日志段的第`n`条消息创建索引条目,其中`n`由`log.index.interval.bytes`参数配置。
```mermaid
graph LR
A[Message 1] -->|Offset 0| B[Log Segment]
C[Message 2] -->|Offset 8192| B
D[Message 3] -->|Offset 16384| B
B -.->|Sparse Index| E[Log Index]
```
### 2.3.2 数据保留与清理策略
Kafka为消息保留提供了多种策略,如按时间保留(Time-Based Retention)和按大小保留(Size-Based Retention)。这些策略确保了过期数据的及时清理,避免无限制地占用磁盘空间。
#### **保留策略**
当消息过期后,它们会被标记为可删除。当满足保留策略条件时,这些标记将被实际删除。Kafka还支持基于日志段的清理(Log Compaction),用于仅保留具有最新键值的消息,适用于某些键值存储场景。
为了提高数据保留的效率,Kafka提供了多种清理策略和配置参数,用户可以根据自己的业务需求进行选择和优化。
```yaml
log.retention.hours=168 # 保留消息的小时数,默认值为168小时,即一周
log.retention.bytes=-1 # 每个日志段的最大大小,默认值为-1,表示无限制
```
以上配置参数指定了Kafka中消息保留的时间长度和大小限制。
以上章节内容深入解析了Kafka的核心架构,包括Broker与Topic的交互原理、Partition的分布策略、生产者和消费者模型,以及Kafka的存储机制与文件系统。通过这些详细内容的介绍,我们不仅了解了Kafka的基本组件和交互方式,而且掌握了这些组件在实际应用中如何进行优化。接下来的章节将继续深入到Kafka Java客户端的实战使用中,展示如何利用Kafka强大的编程接口来构建高效可靠的应用程序。
# 3. ```
# 第三章:Kafka Java客户端实战
随着分布式系统和微服务架构的普及,Kafka作为一种高吞吐量的分布式消息系统,在企业级应用中的角色越来越重要。而Java作为一种广泛使用的编程语言,对于Kafka的支持和使用是必不可少的。本章将深入探索Kafka Java客户端的各种高级用法,以及如何利用Kafka Streams进行流处理。
## 3.1 Kafka Java Producer的高级用法
### 3.1.1 批量处理与消息压缩
为了提高Kafka的生产效率,Kafka Producer允许将多条消息聚合在一起发送到服务器。这种批量处理的机制可以显著提升网络和磁盘的使用效率。而在发送消息时,Kafka还支持多种消息压缩方式,如GZIP、Snappy等,从而进一步降低网络传输的成本。
```java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.ProducerConfig;
***mon.serialization.StringSerializer;
import java.util.Properties;
public class ProducerBatchExample {
public static void main(String[] args) {
Properties props = new Properties();
// 配置Producer的属性
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 启用批处理
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 启用压缩
props.put(***PRESSION_TYPE_CONFIG, "snappy");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
try {
for (int i = 0; i < 1000; i++) {
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));
}
} finally {
producer.close();
}
}
}
```
在上述代码中,我们设置了批量大小为16384字节,并启用了Snappy压缩。需要注意的是,虽然压缩可以降低网络传输成本,但同时也会增加CPU的使用率。
### 3.1.2 异步消息发送与回调处理
对于对消息发送时延要求不高的场景,Kafka Producer支持异步发送消息。通过异步发送,我们可以释放生产者的线程,让它去做更多的工作,同时避免了网络和IO的阻塞性质。发送异步消息时,通常会配合回调函数使用,以便在消息成功发送或发生错误时,进行相应的处理。
```java
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.printf("Sent message to topic %s with offset %d%n", ***ic(), metadata.offset());
} else {
exception.printStackTrace();
}
}
});
```
在回调处理函数中,我们可以根据`exception`参数来判断消息是否发送成功,并进行相应的处理。如果`exception`为null,则表示消息发送成功,否则表示发送失败。
## 3.2 Kafka Java Consumer的进阶技巧
### 3.2.1 消费者群组和分区重平衡
Kafka Consumer以群组的形式消费数据,每个消费者属于一个消费者群组。当有新的消费者加入或离开群组时,Kafka会触发分区重平衡过程,确保所有分区均匀地分配给群组中的消费者。理解重平衡机制对于保证高可用性和负载均衡至关重要。
```java
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
***mon.serialization.StringDeserializer;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerRebalanceExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 开启自动提交offset
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// 分区被移出消费群组时调用
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// 分区被分配到消费群组时调用
}
});
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
} finally {
consumer.close();
}
}
}
```
在此代码片段中,我们通过`subscribe`方法订阅了一个主题,并传入了自定义的`ConsumerRebalanceListener`以监听分区的重分配事件。分区重平衡机制允许消费者群组在动态变化时(比如消费者宕机或者有新消费者加入时),能够重新分配分区,保证数据消费的均匀性。
### 3.2.2 消费速度控制与消息偏移管理
为了保证数据处理的可靠性,Kafka Consumer提供了对消费速度的精细控制,并允许开发者管理消息的偏移量。通过控制消费速度,我们可以避免消息处理速度跟不上生产者速度的情况,防止消费者落后太多而需要重放消息。
```***
***icPartition;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerControlledOffsetExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "***mon.serialization.StringDeserializer");
props.put("value.deserializer", "***mon.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.assign(Arrays.asList(new TopicPartition("my-topic", 0)));
long lastOffsetProcessed = -1;
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
// 处理消息
lastOffsetProcessed = record.offset();
}
// 手动提交偏移量
***mitSync(Collections.singletonMap(new TopicPartition("my-topic", 0), new OffsetAndMetadata(lastOffsetProcessed + 1)));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
```
在该示例中,我们通过手动调用`commitSync`方法来控制偏移量的提交,从而精确控制消费速度。每次消费完一条消息后,我们都会提交下一条消息的偏移量,这样可以有效防止数据的重复消费。
## 3.3 Kafka Streams与Java
### 3.3.1 Kafka Streams的架构概述
Kafka Streams是Kafka提供的一个用于构建实时流处理应用的客户端库。它能够从Kafka主题中读取数据,进行处理后,再将结果输出到另一个主题。Kafka Streams建立在Kafka的消费者和生产者之上,提供了强大的状态管理、时间窗口处理和弹性恢复等功能。
### 3.3.2 实现流处理应用的案例分析
假设我们要构建一个简单的流处理应用,该应用需要统计每个用户每分钟的订单数量。使用Kafka Streams可以这样实现:
```***
***mon.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
***ology;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.TimeWindows;
import java.util.Properties;
public class OrdersPerMinute {
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "orders-per-minute");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("my-topic");
textLines.mapValues(value -> "user_" + value.split(",")[1])
.groupByKey()
.windowedBy(TimeWindows.of(60000))
.count()
.toStream()
.to("user-orders-count");
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
}
}
```
在此代码中,我们首先构建了一个流处理拓扑结构,然后配置了应用的ID、Kafka集群地址、键和值的序列化方式。之后,我们创建了一个KStream来从指定主题读取订单数据流,通过一系列操作将数据流转换成每分钟每个用户订单数量的统计信息,并输出到一个新的主题。
以上就是Kafka Java客户端实战的一些高级用法和技巧。通过本章的介绍,我们了解了如何高效地使用Kafka Java Producer和Consumer进行消息的生产与消费,并探索了Kafka Streams实现复杂流处理应用的可能性。
```
# 4. Kafka消息系统优化
Kafka消息系统优化是确保消息服务高性能、高可用性和可扩展性的关键。本章节将深入探讨Kafka性能调优、集群监控与告警以及容错与灾难恢复策略,这些都是保证Kafka在生产环境中稳定运行的重要因素。
## 4.1 Kafka性能调优
Kafka的性能调优是一个涉及多个方面的过程,包括网络IO、磁盘IO、JVM参数调整等。优化Kafka性能以应对不同的工作负载,能够显著提升系统的吞吐量。
### 4.1.1 网络IO与磁盘IO的优化
网络IO和磁盘IO是影响Kafka性能的两个主要因素。合理地配置Kafka的网络参数和文件系统参数,可以有效地提升消息处理速度和系统的稳定性。
```shell
# 网络参数配置示例
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=***
```
```shell
# Linux文件系统参数调整
vm.swappiness=1
```
通过增加socket缓冲区的大小,可以减少网络IO的阻塞,提升消息发送和接收的效率。同时,调整Linux内核的`vm.swappiness`参数能够减少不必要的交换分区使用,提升磁盘IO性能。
### 4.1.2 JVM和GC调优对Kafka的影响
Java虚拟机(JVM)调优是影响Kafka性能的另一个重要因素。根据Kafka的使用模式和硬件资源,合理配置JVM堆大小以及选择合适的垃圾回收(GC)策略,可以显著提升Kafka实例的运行效率。
```shell
# JVM堆大小设置
-Xms4G
-Xmx4G
```
```shell
# GC策略选择示例
-XX:+UseG1GC
-XX:MaxGCPauseMillis=20
```
在内存足够的前提下,增加JVM堆的大小可以允许Kafka处理更多的消息而不会频繁触发GC。选择G1垃圾回收器并设置合理的最大暂停时间,可以在保证应用响应性的同时,进行有效的垃圾回收。
## 4.2 Kafka集群的监控与告警
Kafka集群的监控是保证系统稳定运行的重要手段。通过监控集群的性能指标和运行状态,可以及时发现并解决问题。
### 4.2.1 常用的监控工具与指标
Kafka提供了JMX接口,可以利用多种监控工具如JConsole、Grafana等来监控其性能指标。
- **集群指标**:broker数量、分区数、副本数、leader选举次数等。
- **主题指标**:消息吞吐量、消息延迟、分区大小、分区状态等。
- **客户端指标**:生产者和消费者的请求延迟、吞吐量、请求失败率等。
### 4.2.2 高级监控系统搭建实践
搭建一个高级监控系统不仅可以监控Kafka集群,还能关联到其他系统,以提供更全面的运营视图。
使用Prometheus和Grafana搭建监控系统,可以实现数据的可视化展示:
```yaml
# Prometheus配置文件示例
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'kafka'
static_configs:
- targets: ['<kafka-broker-host>:9090']
```
通过编写适当的查询语句和配置仪表板,可以实时监控Kafka集群的状态,并通过告警规则及时通知运维团队。
## 4.3 Kafka容错与灾难恢复
容错和灾难恢复是保证Kafka高可用性的重要环节。通过合理配置多副本机制、选举策略、数据备份和恢复策略,可以在部分节点失败时保证数据不丢失和集群的正常运行。
### 4.3.1 多副本机制与leader选举
Kafka通过多副本机制确保了数据的高可用性。副本同步策略和leader选举机制是实现这一目标的核心。
```shell
# 配置示例
default.replication.factor=3
num.replica.fetchers=4
```
设置较高的默认副本因子和合理的副本抓取器数量,可以提升副本之间的同步效率。
### 4.3.2 数据备份与恢复策略
数据备份可以通过定期快照或使用Kafka自带的备份工具进行。恢复策略依赖于备份数据的完整性和可用性。
```shell
# 使用kafka-backup工具进行备份
kafka-backup backup --topic <topic-name> --backup-dir <backup-directory>
```
通过定期备份重要数据,并确保备份文件的远程存储,可以在数据丢失时快速恢复。
在本章节中,我们详细介绍了Kafka消息系统优化的策略和操作,从性能调优、监控告警到容错恢复,每一步都是为了提升系统的稳定性和可靠性。Kafka作为一个分布式消息系统,通过这些优化措施,可以为用户提供一个健壮的消息传递平台。
# 5. Kafka与其他系统的集成
在IT系统中,数据和消息的集成已成为系统间通信的关键。Kafka作为一个高性能、可扩展的消息系统,已成为各种架构设计中不可或缺的一部分。这一章,我们将深入探讨Kafka如何与其他系统集成,包括流行的Spring Boot框架、大数据生态系统以及微服务架构。
## 5.1 Kafka与Spring Boot的整合
### 5.1.1 Spring Boot中Kafka的自动配置
Spring Boot提供了丰富的自动配置功能,使得开发者能够快速集成Kafka。Spring Boot通过spring-kafka模块实现了与Kafka的无缝集成。它提供了KafkaTemplate和KafkaMessageListenerContainer等工具,简化了消息的生产和消费过程。
要启用Kafka支持,您需要在Spring Boot项目中添加`spring-kafka`依赖项。接着,Spring Boot将自动配置Kafka的连接工厂、消费者和生产者,而无需进行复杂的配置。
```xml
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
```
一旦添加了依赖,您就可以使用`@KafkaListener`注解来标记方法,使其成为消息监听器。类似地,您可以使用`KafkaTemplate`来发送消息,而无需担心底层的连接管理和消息序列化。
### 5.1.2 实现消息驱动的应用
在Spring Boot中实现消息驱动的应用非常简单。开发者可以通过`@EnableKafka`注解来启用Kafka配置类,并使用`@KafkaListener`注解创建消息监听器。
这里是一个简单的例子,展示了如何创建一个消息驱动的消费者:
```java
@EnableKafka
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
@Component
public class KafkaConsumerExample {
@KafkaListener(topics = "test-topic", groupId = "test-group")
public void listenGroupFoo(String message) {
System.out.println("Received message in group foo: " + message);
}
}
```
以上代码定义了如何创建一个消费者实例,并用`@KafkaListener`注解指定了监听的topic和group。
## 5.2 Kafka在大数据生态中的角色
### 5.2.1 Kafka与Apache Hadoop的集成
Kafka与Apache Hadoop的集成,使得它能够扮演大数据处理流程中的消息和事件源的角色。Hadoop生态系统中的各种工具,如Flume和Sqoop,都可以与Kafka结合,以实现高效的数据流处理。
Flume是一个可靠、可配置的系统,用于有效地收集、聚合和移动大量日志数据。Flume可以配置成从多个源收集数据,并将其聚合到Kafka中,从而可以被各种大数据分析工具消费。
```xml
# Flume配置文件示例
agent.sources = r1
agent.sources.r1.type = avro
agent.sources.r1.bind = localhost
agent.sources.r1.port = 10000
agent.sources.r1.channels = c1
agent.channels = c1
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
agent.sinks = k1
agent.sinks.k1.type = ***
***ic = test
agent.sinks.k1.brokerList = localhost:9092
agent.sinks.k1.requiredAcks = 1
agent.sinks.k1.batchSize = 20
agent.sinkgroups = g1
agent.sinkgroups.g1.sinks = k1
agent.sinkgroups.g1.capacity = 1000
agent.sinkgroups.g1.transactionCapacity = 100
agent.sourcegroups = sg1
agent.sourcegroups.sg1.sources = r1
agent.sourcegroups.sg1.sinks = k1
```
以上示例展示了如何配置Flume以将数据发送到Kafka。
### 5.2.2 Kafka与Spark Streaming的集成示例
Apache Spark是另一个流行的大数据处理工具,Kafka可以作为数据源与Spark Streaming集成。这样可以实现数据的实时处理和分析。
Kafka的高吞吐量和低延迟特性使得它成为一个理想的选择,能够处理大规模数据流。下面的代码演示了如何在Spark Streaming应用中集成Kafka作为数据输入源。
```scala
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName("KafkaIntegration")
val ssc = new StreamingContext(conf, Seconds(2))
val topicsSet = Set("test-topic")
val kafkaParams = Map[String, String]("metadata.broker.list" -> "localhost:9092")
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
messages.map(_._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
```
在这个示例中,我们创建了一个Spark Streaming上下文,并使用`KafkaUtils.createDirectStream`方法直接从Kafka读取数据流。然后我们对消息内容进行处理,如分割单词并计数,最后输出结果。
## 5.3 Kafka与微服务架构的融合
### 5.3.1 事件驱动微服务架构概述
在微服务架构中,服务之间的通信是关键。事件驱动的微服务架构使用消息队列来实现服务间的解耦和异步通信。Kafka作为消息系统的一部分,在此架构中发挥着重要作用,成为不同服务间进行事件通知和信息传递的桥梁。
### 5.3.2 Kafka在服务间通信的应用实例
在微服务架构中,Kafka可以用来实现服务间的通信。例如,假设一个电子商务平台的订单服务在创建订单后,需要通知库存服务去更新库存数量。这种情况下,Kafka可以作为一个中心化的消息总线来帮助实现这种通信。
```java
// 生产者代码示例
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessageToInventoryService(String message) {
ProducerRecord<String, String> record = new ProducerRecord<>("inventory-topic", message);
kafkaTemplate.send(record);
}
// 消费者代码示例
@KafkaListener(topics = "inventory-topic")
public void consume(ConsumerRecord<String, String> record) {
String message = record.value();
// 更新库存逻辑
}
```
在上述例子中,订单服务作为生产者发送消息给Kafka,然后库存服务作为消费者从Kafka中接收并处理该消息。
以上章节内容展现了Kafka的强大能力,它能与其他技术栈无缝集成,无论是在传统的Java应用中,还是在现代的大数据处理以及微服务架构中,都发挥了不可替代的作用。
# 6. Kafka实战案例分析
## 6.1 消息队列在订单系统中的应用
在现代电子商务系统中,订单处理是业务的核心环节之一。消息队列可以在高并发的订单处理流程中发挥巨大作用。利用消息队列的异步处理机制,可以提高系统的整体吞吐量和处理速度。
### 6.1.1 构建高并发订单处理流程
高并发订单处理流程的关键在于将用户下单和订单处理解耦,使得前端用户界面可以专注于接收用户订单,而后端处理系统则可以并行地处理这些订单。通过Kafka,我们可以将订单消息发送到一个或多个订单处理的消费者组。
```java
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class.getName());
KafkaProducer<String, Order> producer = new KafkaProducer<>(properties);
Order order = new Order(1001, "用户ID", "商品ID", 1, LocalDateTime.now());
producer.send(new ProducerRecord<>("orders", order));
producer.close();
```
在上述Java代码片段中,我们创建了一个Kafka Producer,并发送了一个订单消息。订单消息被发送到了"orders"这个Topic,之后由消费者进行消费处理。
### 6.1.2 消息顺序性保证与事务处理
尽管Kafka提供了消息的分区,保证了同一个分区内的消息顺序,但在整个订单系统中,消息顺序的保证则需要额外的机制。一种常见的做法是为每个订单创建一个特定的分区。而事务处理通常需要引入两阶段提交(2PC)等协议来保证消息的原子性。
## 6.2 Kafka在日志分析中的作用
在分布式系统中,收集和分析日志是一个复杂的问题。Kafka能够有效地收集来自不同服务的日志信息,并将它们集中存储起来,以便进行实时分析。
### 6.2.1 日志收集与实时分析
Kafka的一个典型使用场景是作为日志收集系统。各种服务可以将日志消息发送到Kafka,然后由Kafka分发给日志分析系统,如ELK Stack(Elasticsearch, Logstash, Kibana)。
```shell
# 使用命令行工具向Kafka发送日志信息
echo "2023-01-11T10:20:30.123Z,ERROR,User Service,Invalid user ID" | kafka-console-producer.sh --broker-list localhost:9092 --topic logs
```
上述shell命令通过kafka-console-producer.sh工具将一条日志信息发送到名为"logs"的Topic中。
### 6.2.2 大规模日志数据处理优化策略
对于大规模日志数据的处理,需要考虑合理的分区策略,以及日志的压缩和清理策略,以优化存储和查询性能。Kafka支持日志压缩,这在一定程度上减少了重复数据的存储,并帮助保持日志文件的大小在可控范围内。
## 6.3 实现复杂的流处理应用
Kafka Streams是Apache Kafka提供的一个轻量级的流处理库,用于构建实时数据处理应用。Kafka Streams能够处理数据的实时计算,包括窗口计算、连接操作、聚合操作等。
### 6.3.1 基于Kafka Streams的状态存储与查询
Kafka Streams支持本地状态存储,允许开发者在流处理应用中使用状态,如数据累加、连接操作等。
```java
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Order> orderStream = builder.stream("orders");
KTable<String, Long> orderCount = orderStream
.mapValues(Order::getUserId)
.groupByKey()
.count();
orderCount.toStream().print(Printed.toSysOut());
```
上述Java代码片段展示了一个简单的Kafka Streams程序,它从"orders"这个Topic读取订单信息,并统计每个用户的订单数量。
### 6.3.2 处理时间窗口与事件时间窗口的案例
在流处理中,窗口操作是处理时间序列数据的关键。Kafka Streams支持不同类型的窗口,包括处理时间窗口(Processing Time Window)和事件时间窗口(Event Time Window)。
```java
KStream<String, Order> orderStream = builder.stream("orders");
TimeWindows tumblingWindow = TimeWindows.of(Duration.ofMinutes(5));
orderStream
.groupByKey()
.windowed(tumblingWindow)
.count()
.toStream()
.print(Printed.toSysOut());
```
上述代码定义了一个5分钟的滚动窗口,用于计算每5分钟内订单的数量。这样的窗口操作对于分析日志和监控实时数据非常有用。
通过以上几个案例,我们可以看到Kafka在不同场景下的应用以及它处理复杂流处理任务的能力。在后续的章节中,我们将深入探讨Kafka在其他系统集成和优化方面的实际应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Java 消息库的方方面面,为开发者提供了全面的指南。从入门级教程到高级应用,专栏涵盖了 RabbitMQ、Kafka、ActiveMQ、Spring Boot 消息整合等热门消息库。此外,还深入剖析了消息传递机制、事务管理、监控技术以及在微服务架构中的应用。通过实战技巧、案例详解和深入分析,本专栏旨在帮助 Java 开发者掌握消息处理的精髓,构建高效、可靠的消息系统,为微服务架构的解耦和系统稳定性提供坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
大样本理论在假设检验中的应用:中心极限定理的力量与实践

# 1. 中心极限定理的理论基础
## 1.1 概率论的开篇
概率论是数学的一个分支,它研究随机事件及其发生的可能性。中心极限定理是概率论中最重要的定理之一,它描述了在一定条件下,大量独立随机变量之和(或平均值)的分布趋向于正态分布的性
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
【品牌化的可视化效果】:Seaborn样式管理的艺术

# 1. Seaborn概述与数据可视化基础
## 1.1 Seaborn的诞生与重要性
Seaborn是一个基于Python的统计绘图库,它提供了一个高级接口来绘制吸引人的和信息丰富的统计图形。与Matplotlib等绘图库相比,Seaborn在很多方面提供了更为简洁的API,尤其是在绘制具有多个变量的图表时,通过引入额外的主题和调色板功能,大大简化了绘图的过程。Seaborn在数据科学领域得
数据清洗的概率分布理解:数据背后的分布特性

# 1. 数据清洗的概述和重要性
数据清洗是数据预处理的一个关键环节,它直接关系到数据分析和挖掘的准确性和有效性。在大数据时代,数据清洗的地位尤为重要,因为数据量巨大且复杂性高,清洗过程的优劣可以显著影响最终结果的质量。
## 1.1 数据清洗的目的
数据清洗
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
正态分布与信号处理:噪声模型的正态分布应用解析

# 1. 正态分布的基础理论
正态分布,又称为高斯分布,是一种在自然界和社会科学中广泛存在的统计分布。其因数学表达形式简洁且具有重要的统计意义而广受关注。本章节我们将从以下几个方面对正态分布的基础理论进行探讨。
## 正态分布的数学定义
正态分布可以用参数均值(μ)和标准差(σ)完全描述,其概率密度函数(PDF)表达式为:
```math
f(x|\mu,\sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} e
【置信区间进阶课程】:从理论到实践的深度剖析

# 1. 置信区间的统计学基础
## 统计学中的中心极限定理
在统计学中,中心极限定理是一个至关重要的概念,它为我们在样本量足够大时,可以用正态分布去近似描述样本均值的分布提供了理论基础。这一理论的数学表述虽然复杂,但其核心思想简单:不论总体分布如何,只要样本量足够大,样本均值的分布就趋向于正态分布。
## 置信区间的概念与意义
置信区间提供了一个区间估
【线性回归时间序列预测】:掌握步骤与技巧,预测未来不是梦
# 1. 线性回归时间序列预测概述
## 1.1 预测方法简介
线性回归作为统计学中的一种基础而强大的工具,被广泛应用于时间序列预测。它通过分析变量之间的关系来预测未来的数据点。时间序列预测是指利用历史时间点上的数据来预测未来某个时间点上的数据。
## 1.2 时间序列预测的重要性
在金融分析、库存管理、经济预测等领域,时间序列预测的准确性对于制定战略和决策具有重要意义。线性回归方法因其简单性和解释性,成为这一领域中一个不可或缺的工具。
## 1.3 线性回归模型的适用场景
尽管线性回归在处理非线性关系时存在局限,但在许多情况下,线性模型可以提供足够的准确度,并且计算效率高。本章将介绍线
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
从Python脚本到交互式图表:Matplotlib的应用案例,让数据生动起来

# 1. Matplotlib的安装与基础配置
在这一章中,我们将首先讨论如何安装Matplotlib,这是一个广泛使用的Python绘图库,它是数据可视化项目中的一个核心工具。我们将介绍适用于各种操作系统的安装方法,并确保读者可以无痛地开始使用Matplotlib
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )