NiFi数据流概述与架构分析
发布时间: 2024-02-23 22:45:27 阅读量: 57 订阅数: 24 

数据流的分析
# 1. NiFi数据流技术概述
## 1.1 NiFi数据流简介
Apache NiFi是一个开源的数据流处理系统,设计用于自动化大型数据流在系统之间的移动和管理。NiFi提供了直观的界面和强大的功能,使用户能够轻松地收集、整理、传输和处理数据流。通过NiFi,用户可以实现数据的实时传输、转换、监控和管理,极大地简化了复杂数据流处理过程。
## 1.2 NiFi的发展历程
NiFi最初由美国国家安全局(NSA)在2006年开发,并在2014年成为Apache顶级项目。随后,NiFi在Apache的社区不断发展完善,吸引了众多开发者和用户的参与和贡献,成为了大数据领域中备受关注的数据流处理工具之一。
## 1.3 NiFi在大数据处理中的应用
NiFi在大数据处理方面具有广泛的应用场景,包括但不限于:
- 实时数据采集与传输
- 数据清洗、加工和转换
- 数据治理和安全性管理
- 数据监控与故障排查
- 数据分析和实时决策支持
通过NiFi强大的功能和灵活的可扩展性,用户可以轻松构建各种复杂的数据流处理任务,满足不同行业和领域的需求。NiFi的出现大大简化了大数据处理的复杂性,提升了数据流处理的效率和质量。
# 2. NiFi架构设计与核心组件
NiFi作为一个开源的数据流处理工具,其架构设计十分灵活并且功能强大。在这一章节中,我们将深入探讨NiFi的架构设计以及其核心组件的作用和功能。
### 2.1 NiFi架构概述
NiFi采用了基于流的架构设计,提供了可视化的用户界面来配置数据流处理任务。其架构主要包括以下几个关键组件:
- **NiFi应用节点(NiFi Application)**:NiFi应用节点是整个数据流处理系统的运行环境,负责数据流的控制和调度。
- **流程(Flow)**:流程是NiFi中的数据处理流程单元,包含一系列的数据处理组件及其连接关系。
- **流程管理器(Flow Controller)**:流程管理器负责管理多个流程以及它们之间的数据流转。
- **数据流文件仓库(FlowFile Repository)**:数据流文件仓库用于存储数据流中的文件对象,确保数据在处理过程中的可靠性和一致性。
### 2.2 流程和流程管理器
在NiFi中,流程是数据处理的核心单元,每个流程由多个处理器(Processor)组成,并且可以通过连接关系来定义数据的传输路径。流程管理器则负责对多个流程进行管理和协调,确保数据在系统中的流转和处理。
下面是一个简单的NiFi流程示例,用于从一个文件夹中读取数据,并将数据写入另一个文件夹中:
```python
# 导入NiFi相关模块
from nifi.flow import NiFiFlow
from nifi.processor import GetFile, PutFile
# 创建一个NiFi流程
flow = NiFiFlow()
# 添加数据读取处理器
get_file_processor = GetFile("Read Data")
flow.add_processor(get_file_processor)
# 添加数据写入处理器
put_file_processor = PutFile("Write Data")
flow.add_processor(put_file_processor)
# 连接数据读取处理器和数据写入处理器
flow.add_connection(get_file_processor, put_file_processor)
# 运行NiFi流程
flow.run()
```
在这段代码中,我们首先创建了一个NiFi流程,并且添加了数据读取处理器和数据写入处理器。然后通过`flow.add_connection()`方法将两个处理器连接起来,定义数据传输路径。最后通过`flow.run()`方法运行整个流程。
### 2.3 控制器服务和报告任务
除了流程和流程管理器,NiFi还提供了控制器服务和报告任务等组件,用于增强系统的功能和监控能力。
- **控制器服务(Controller Service)**:控制器服务提供了可复用的服务组件,如数据库连接池、加密解密服务等,在数据处理过程中可以被多个处理器共享使用。
- **报告任务(Reporting Task)**:报告任务用于定期生成系统运行状态报告,帮助用户监控数据流处理的性能和健康状况。
通过这些核心组件的协作和配合,NiFi实现了一个高效、可靠的数据流处理平台,广泛应用于大数据处理和实时数据流处理场景中。
# 3. NiFi数据流的基本概念和特性
在本章中,将介绍NiFi数据流的基本概念和特性,深入解析NiFi数据流的可靠性保证以及其可扩展性和灵活性。
#### 3.1 数据流的基本概念解析
NiFi数据流是指数据在系统内部各个组件之间流动的过程。NiFi数据流通常包括数据收集、传输、清洗、转换和输出等环节。数据流通常以数据流程图的形式展示,图中包括各个数据源、处理器、连接器等元素,以及它们之间的关系和数据流向。
在NiFi中,数据流的基本概念包括:
- 数据流程图:描述数据流处理的图形化展示,包括数据源、处理器、连接器等元素,以及它们之间的关系和数据流向。
- 数据流处理器:数据流处理器是NiFi中用于实现数据处理逻辑的组件,每个处理器可以完成特定的数据处理操作,例如数据抽取、转换、过滤、聚合等。
- 连接器:连接器用于连接数据流处理器间的数据流,将数据从一个处理器传递到另一个处理器,是数据流处理的桥梁。
- 数据流源:数据流源指数据流的来源,可以是本地文件、远程服务器、消息队列等数据源。
- 数据流目的地:数据流目的地指数据流的最终输出目标,可以是数据库、远程服务器、消息队列等数据存储或下游处理系统。
#### 3.2 数据流的可靠性保证
在NiFi数据流中,可靠性是非常重要的特性之一。NiFi通过以下方式保证数据流的可靠性:
- **事务性数据流处理**:NiFi支持事务性数据流处理,确保数据在处理过程中的原子性、一致性、隔离性和持久性,从而保证数据处理的可靠性。
- **数据流检测和重试机制**:NiFi能够检测数据流处理过程中的错误和异常情况,并提供重试机制,确保数据能够成功处理并流向下游系统。
#### 3.3 NiFi的可扩展性和灵活性
NiFi具有良好的可扩展性和灵活性,能够满足不同规模和复杂度的数据处理需求。NiFi的可扩展性和灵活性体现在以下方面:
- **插件化的架构**:NiFi的处理器、连接器等组件采用插件化的设计,用户可以根据实际需求开发定制化的处理器和连接器,并集成到NiFi中,从而扩展NiFi的功能。
- **水平扩展和集群部署**:NiFi支持水平扩展和集群部署,能够通过增加节点实现系统的横向扩展,同时支持负载均衡和故障恢复,保证数据流处理的高可用性和性能。
以上是NiFi数据流的基本概念和特性,包括数据流的基本概念解析、可靠性保证以及可扩展性和灵活性。这些特性使得NiFi成为处理大数据流的强大工具,在实际项目中具有广泛的应用场景。
接下来,我们将深入探讨NiFi数据流的数据处理流程,包括数据收集和传输、数据清洗和转换,以及数据分发和输出。
# 4. NiFi数据流的数据处理流程
在NiFi数据流中,数据处理流程是至关重要的一环,它涵盖了数据的收集、传输、清洗、转换、分发和输出等环节。本章将详细介绍NiFi数据流的数据处理流程,包括各环节的实现方式、技术细节和应用场景。
#### 4.1 数据流的数据收集和传输
数据收集是数据处理流程的第一步,NiFi提供了丰富的数据采集方式,包括文件系统、网络资源、数据库、消息队列等。下面是一个使用NiFi从文件系统中收集数据并传输到目标系统的示例Python代码:
```python
from nipyapi import canvas, nifi
from nipyapi.templates import get_template_by_name
from nipyapi.version import __version__
# 获取NiFi模板
template = get_template_by_name('MyDataFlowTemplate')
# 实例化模板
new_pg = canvas.get_process_group(canvas.get_root_pg_id(), 'MyDataFlowTemplate')
# 获取源数据
source_data = get_data_from_source()
# 创建数据流文件
with open('data.txt', 'w') as file:
file.write(source_data)
# 将数据写入NiFi
for processor in new_pg.processors:
if processor.component.name == 'PutFile':
put_file_processor = processor
nifi.create_connection(put_file_processor, template)
```
#### 4.2 数据流的数据清洗和转换
数据清洗和转换是数据处理的核心环节之一,在NiFi中可以通过Processor来实现数据的清洗处理。下面是一个简单的Java代码示例,演示了如何使用NiFi对数据进行清洗处理:
```java
import org.apache.nifi.processor.ProcessContext;
import org.apache.nifi.processor.Relationship;
import org.apache.nifi.processor.io.OutputStreamCallback;
import org.apache.nifi.processor.io.StreamCallback;
public class DataCleanseProcessor extends AbstractProcessor {
@Override
public void onTrigger(ProcessContext context, ProcessSession session) throws ProcessException {
FlowFile flowFile = session.get();
if (flowFile != null) {
// 清洗数据的具体逻辑
// ...
// 将清洗后的数据写回到FlowFile
FlowFile cleanedFlowFile = session.write(flowFile, new StreamCallback() {
@Override
public void process(InputStream inputStream, OutputStream outputStream) throws IOException {
// 清洗后的数据写入流
// ...
}
});
session.transfer(cleanedFlowFile, SUCCESS);
}
}
}
```
#### 4.3 数据流的数据分发和输出
数据处理完成后,需要将数据分发到目标系统或输出至存储设备。NiFi提供了丰富的数据输出方式,包括数据库、消息队列、文件系统等。下面是一个使用NiFi将数据输出至MySQL数据库的示例代码片段:
```python
import pymysql
# 连接数据库
db = pymysql.connect("localhost", "user", "password", "database")
cursor = db.cursor()
# 获取数据
data = get_data_to_insert()
# 将数据插入数据库
for record in data:
sql = "INSERT INTO table_name VALUES ({})".format(record)
cursor.execute(sql)
# 提交并关闭数据库连接
db.commit()
db.close()
```
通过以上实例,我们可以清楚地了解NiFi数据流的数据处理流程,包括数据收集、清洗转换和输出等环节。NiFi作为一个高效、可靠的数据流处理工具,在实际项目中发挥着重要作用。
# 5. NiFi数据流的安全性和性能优化
在NiFi数据流的实际应用中,安全性和性能优化是非常重要的考虑因素。本章将重点讨论NiFi数据流的安全认证、权限管理、性能优化策略以及故障处理与容错机制。通过对这些方面的深入理解,可以更好地应用NiFi数据流技术于实际项目中。
### 5.1 NiFi数据流的安全认证与权限管理
NiFi提供了多种安全认证机制,包括基于用户名/密码的认证、基于Kerberos的认证、基于LDAP的认证等。可以根据实际需求选择合适的认证方式,并通过NiFi的用户界面进行配置和管理。此外,NiFi还提供了细粒度的权限管理,可以对不同用户或用户组的操作进行灵活的控制,保障数据流的安全性。
```java
// Java代码示例:NiFi数据流安全认证配置
NiFiProperties properties = new NiFiProperties();
properties.setProperty("nifi.security.user.login.identity.provider", "ldap-provider");
properties.setProperty("nifi.security.needClientAuth", "false");
properties.setProperty("nifi.security.user.authorizer", "file-provider");
```
### 5.2 数据流的性能优化策略和实践
为了优化NiFi数据流的性能,可以采取一系列策略和实践。例如,合理设计数据流的拓扑结构、配置合适的并发线程数、优化数据流处理算法、合理使用缓存和磁盘等。另外,可以通过NiFi的监控和分析工具,对数据流的性能进行实时监测和调优。
```python
# Python代码示例:NiFi数据流性能优化配置
nifi_properties = {
"concurrent_threads": 10,
"input_buffer_size": "1GB",
"output_buffer_size": "512MB",
"flow_file_repository": "/path/to/flow-file-repo",
...
}
```
### 5.3 NiFi数据流中的故障处理与容错机制
在实际应用中,NiFi数据流可能会面临各种故障和异常情况,例如网络中断、系统故障、数据处理错误等。NiFi提供了多种容错机制,包括事务性数据流处理、数据流检测与重试、故障转移和恢复等,以保障数据流的可靠性和稳定性。
```javascript
// JavaScript代码示例:NiFi数据流故障处理与容错配置
var failureThreshold = 5;
var retryBackoffTime = 3000; // in milliseconds
var maxRetryAttempts = 3;
```
通过以上安全性和性能优化的策略与实践,可以使NiFi数据流在实际项目中发挥更好的作用,保障数据处理的安全性、稳定性和高效性。
# 6. NiFi数据流在实际项目中的应用案例
在这一章中,我们将分享几个NiFi数据流在实际项目中的应用案例,以展示NiFi在不同行业领域的灵活运用和实际效果。
### 6.1 金融行业数据处理案例
在金融行业,数据处理通常涉及大量的实时数据传输、清洗和处理,NiFi作为一个可靠、高效的数据流工具,被广泛应用于金融数据处理领域。例如,一家银行需要将各个分行的交易数据实时集成到中心数据分析平台,利用NiFi搭建的数据流可以轻松实现数据的抽取、转换和加载(ETL),确保数据的准确性和实时性。
```java
// Java示例代码:使用NiFi进行金融数据实时处理
public class FinanceDataFlow {
public static void main(String[] args) {
// 创建NiFi数据流处理器
DataFlowProcessor processor = new DataFlowProcessor();
// 设置数据源和目标
DataSource source = new BankTransactionDataSource();
DataDestination destination = new CentralAnalyticsPlatform();
// 构建数据流
DataFlow flow = new DataFlow(source, destination);
// 执行数据流处理
processor.execute(flow);
}
}
```
在以上示例中,我们展示了如何使用NiFi构建金融数据流处理的Java代码。通过NiFi的流程管理器和控制器服务,金融机构可以实现数据的安全传输和处理,提升数据处理效率和质量。
### 6.2 电商行业数据流实时处理案例
电子商务行业的特点是数据量大且实时性要求高,NiFi在电商行业中也有广泛的应用场景。举例来说,一家电商平台需要分析用户行为数据并实时调整推荐商品,NiFi可以帮助实现从用户点击行为到实时推荐的数据处理流程。
```python
# Python示例代码:电商数据实时处理流程
def ecommerce_data_processing():
# 创建NiFi数据流处理器
processor = DataFlowProcessor()
# 设置数据源和目标
source = UserClickBehaviorSource()
destination = RealTimeRecommendationEngine()
# 构建数据流
flow = DataFlow(source, destination)
# 执行数据流处理
processor.execute(flow)
```
以上是一个简单的Python示例代码,展示了NiFi在电商行业数据实时处理中的应用。通过NiFi的数据清洗和转换功能,电商企业可以快速响应用户行为变化,提升用户体验和交易转化率。
### 6.3 其他行业应用案例分享
除了金融和电商行业,NiFi数据流还在各种行业中得到广泛应用。例如,在制造业中,NiFi可以用于生产数据实时监控和质量控制;在医疗保健领域,NiFi可用于医疗数据集成和分析等。不同行业的应用案例展示了NiFi的通用性和灵活性,为企业数据处理提供了可靠的解决方案。
通过以上案例的分享,我们可以看到NiFi数据流在不同行业中的实际应用效果,为企业提供了强大的数据处理和分析能力,助力业务发展和创新。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏关注Apache NiFi数据流处理,涵盖了多方面的主题。首先,通过《Apache NiFi入门指南》,帮助读者快速了解NiFi的基本概念和操作方法。接着,深入探讨了在NiFi数据流中的数据转换技术,数据合并与分流技术,以及数据安全与身份验证的重要性。同时,重点讨论了如何高效利用NiFi进行数据传输与同步,在NiFi中实施性能优化与调优,并探讨NiFi在实时流数据处理中的应用与挑战。通过本专栏的阅读,读者将全面了解Apache NiFi的功能和应用,掌握数据流处理中的关键技术和技巧,从而更加高效地进行数据处理和流转。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CListCtrl行高设置终极指南】:从细节到整体,确保每个环节的完美

# 摘要
CListCtrl是一种常用的列表控件,在用户界面设计中扮演重要角色。本文围绕CListCtrl行高设置展开了详细的探讨,从基本概念到高级应用,深入解析了行高属性的工作原理,技术要点以及代码实现步骤。文章还涉及了多行高混合显示技术、性能优化策略和兼容性问题。通过实践案例分析,本文揭示了常见问题的诊断与解决方法,并探讨了行高设置的
从理论到实践:AXI-APB桥性能优化的关键步骤

# 摘要
本文首先介绍了AXI-APB桥的基础架构及其工作原理,随后深入探讨了性能优化的理论基础,包括性能瓶颈的识别、硬件与软件优化原理。在第三章中,详细说明了性能测试与分析的工具和方法,并通过具体案例研究展示了性能优化的应用。接下来,在第四章中,介绍了硬件加速、缓存
邮件管理自动化大师:SMAIL中文指令全面解析

# 摘要
本文详细介绍了SMAIL邮件管理自动化系统的全面概述,基础语法和操作,以及与文件系统的交互机制。章节重点阐述了SMAIL指令集的基本组成、邮件的基本处理功能、高级邮件管理技巧,以及邮件内容和附件的导入导出操作。此外,文章还探讨了邮件自动化脚本的实践应用,包括自动化处理脚本、邮件过滤和标签自动化、邮件监控与告警。最后一章深入讨论了邮件数据的分析与报告生成、邮件系统的集成与扩展策
车载网络测试新手必备:掌握CAPL编程与应用

# 摘要
CAPL(CAN Application Programming Language)是一种专门为CAN(Controller Area Network)通信协议开发的脚本语言,广泛应用于汽车电子和车载网络测试中。本文首先介绍了CAPL编程的基础知识和环境搭建方法,然后详细解析了CAPL的基础语法结构、程序结构以及特殊功能。在此基础上,进一步探讨了CAPL的高级编程技巧,包括模块化
一步到位!CCU6嵌入式系统集成方案大公开

# 摘要
本文全面介绍了CCU6嵌入式系统的设计、硬件集成、软件集成、网络与通信集成以及综合案例研究。首先概述了CCU6系统的架构及其在硬件组件功能解析上的细节,包括核心处理器架构和输入输出接口特性。接着,文章探讨了硬件兼容性、扩展方案以及硬件集成的最佳实践,强调了高效集成的重要性和集成过程中的常见问题。软件集成部分,分析了软件架构、
LabVIEW控件定制指南:个性化图片按钮的制作教程
# 摘要
LabVIEW作为一种图形编程环境,广泛应用于数据采集、仪器控制及工业自动化等领域。本文首先介绍了LabVIEW控件定制的基础,然后深入探讨了创建个性化图片按钮的理论和实践。文章详细阐述了图片按钮的界面设计原则、功能实现逻辑以及如何通过LabVIEW控件库进行开发。进一步,本文提供了高级图片按钮定制技巧,包括视觉效果提升、代码重构和模块化设计,以及在复杂应用中的运用
【H3C 7503E多业务网络集成】:VoIP与视频流配置技巧
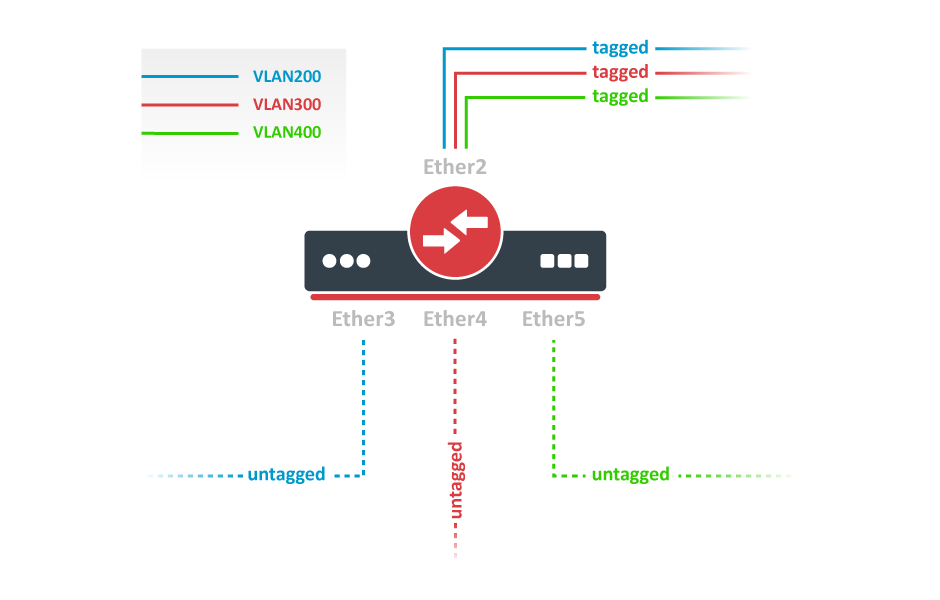
# 摘要
本论文详细介绍了H3C 7503E多业务路由器的功能及其在VoIP和视频流传输领域的应用。首先概述了H3C 7503E的基本情况,然后深入探讨了VoIP技术原理和视频流传输技术的基础知识。接着,重点讨论了如何在该路由器上配置VoIP和视频流功能,包括硬
Word中代码的高级插入:揭秘行号自动排版的内部技巧
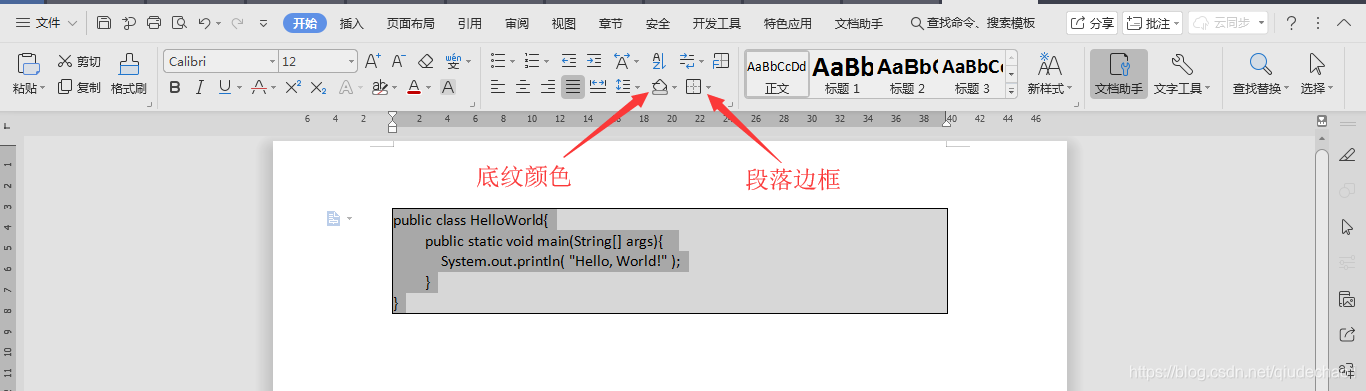
# 摘要
在技术文档和软件开发中,代码排版对于提升文档的可读性和代码的维护性至关重要。本文首先探讨了在Microsoft Word中实现代码排版的常规方法,包括行号自动排版
【PHY62系列SDK技能升级】:内存优化、性能提升与安全加固一步到位

# 摘要
本文针对PHY62系列SDK在实际应用中所面临的内存管理挑战进行了系统的分析,并提出了相应的优化策略。通过深入探讨内存分配原理、内存泄漏的原因与检测,结合内存优化实践技巧,如静态与动态内存优化方法及内存池技术的应用,本文提供了理论基础与实践技巧相结合的内存管理方案。此外,本文还探讨了如何通过性能评估和优化提升系统性能,并分析了安全加固措施,包括安全编程基础、数据加密、访问控制
【JMeter 负载测试完全指南】:如何模拟真实用户负载的实战技巧
# 摘要
本文对JMeter负载测试工具的使用进行了全面的探讨,从基础概念到高级测试计划设计,再到实际的性能测试实践与结果分析报告的生成。文章详细介绍了JMeter测试元素的应用,测试数据参数化技巧,测试计划结构的优化,以及在模拟真实用户场景下的负载测试执行和监控。此外,本文还探讨了JMeter在现代测试环境中的应用,包括与CI/CD的集成,云服务与分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )