Python实现手写数字图像的展示与分析
发布时间: 2024-03-14 22:53:22 阅读量: 50 订阅数: 21 

Python实现基于svm的手写数字图像识别.zip
# 1. **介绍**
## 1.1 引言
在当今数字化时代,图像处理和数字识别技术广泛应用于各个领域,如人工智能、医学图像分析、安全监控等。其中,手写数字图像的展示与分析是计算机视觉中的一个重要领域。本文将介绍如何利用Python实现手写数字图像的展示与分析,通过图像处理和数字识别算法,实现对手写数字的自动识别。
## 1.2 目的与意义
本文旨在通过展示如何使用Python进行手写数字图像的处理与识别,帮助读者了解数字图像处理的基本流程和常用方法。通过本文的学习,读者可以掌握如何进行数据预处理、特征提取、图像处理和数字识别算法的实现。
## 1.3 Python在图像处理中的应用概述
Python在图像处理领域应用广泛且易于上手。通过Python强大的图像处理库,如PIL(Pillow)、OpenCV等,我们可以方便地进行图像处理、特征提取和数字识别算法的实现。Python的简洁性和丰富的库资源使得图像处理任务变得高效和便捷。接下来,我们将在接下来的章节中详细介绍如何使用Python实现手写数字图像的展示与分析。
# 2. 准备工作
在进行手写数字图像的展示与分析前,需要完成以下准备工作:
### 2.1 安装Python和相关库
首先,确保已经安装了Python编程语言。接着,通过pip工具安装以下必要的库:
```python
pip install numpy pandas matplotlib scikit-learn
```
### 2.2 数据集介绍与下载
准备使用MNIST(Modified National Institute of Standards and Technology)数据集,这是一个广泛用于训练各种图像处理系统的手写数字数据集。可以通过以下代码下载并加载MNIST数据集:
```python
from sklearn.datasets import fetch_openml
# 下载MNIST数据集
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]
```
### 2.3 数据预处理与特征提取
在加载数据集后,通常需要进行数据预处理和特征提取,以便为后续的图像处理和算法提供准备。具体的数据清洗、归一化、特征选取等操作可以通过代码来实现。
以上是准备工作的基本步骤,接下来我们将着重介绍如何展示手写数字图像数据,包括可视化、分布情况绘制和统计分析。
# 3. 数据展示
在进行手写数字图像的展示与分析之前,首先需要对数据进行可视化和统计分析,以便更好地理解数据的特征和分布情况。
#### 3.1 手写数字图像数据的可视化
我们将使用matplotlib库来展示手写数字图像数据集中的一部分样本,以便直观地观察数字的书写风格和特点。下面是展示前10个数字图像的示例代码:
```python
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
# 加载手写数字数据集
digits = load_digits()
# 可视化前10个数字图像
fig, axes = plt.subplots(2, 5, figsize=(10, 4))
for i, ax in enumerate(axes.flat):
ax.imshow(digits.images[i], cmap='binary')
ax.set_title(f"Label: {digits.target[i]}")
ax.axis('off')
plt.show()
```
在上述代码中,我们加载了手写数字数据集,并使用matplotlib展示了前10个数字图像及其对应的标签,以灰度图像的形式呈现出来。
#### 3.2 绘制手写数字图像的分布情况
为了更好地了解手写数字图像数据集中各个数字的分布情况,我们可以绘制柱状图来展示不同数字在数据集中的数量。下面是绘制手写数字图像分布情况的示例代码:
```python
import matplotlib.pyplot as plt
import numpy as np
# 统计各数字在数据集中的数量
unique, counts = np.unique(digits.target, return_counts=True)
# 绘制柱状图
plt.bar(unique, counts, align='center', alpha=0.5)
plt.xticks(unique)
plt.xlabel('Digits')
plt.ylabel('Count')
plt.title('Distribution of Digits in Dataset')
plt.show()
```
通过上述代码,我们可以清晰地看到数据集中每个数字的样本数量,从而对数据的分布有一个直观的认识。
#### 3.3 数据集的统计分析
除了可视化数字图像数据外,对数据集进行统计分析也是十分重要的。我们可以计算数据集的均值、标准差等统计量,以便了解整体数据的特征。以下是数据集统计分析的示例代码:
```python
import numpy as np
# 计算数据集的均值和标准差
mean_val = np.mean(digits.data, axis=0)
std_val = np.std(digits.data, axis=0)
print(f"Mean of dataset: {mean_val}")
print(f"Standard deviation of dataset: {std_val}")
```
在上述代码中,我们计算了数据集中特征的均值和标准差,从而获得了关于数据分布和变化程度的信息。这些统计量有助于我们更全面地理解数据集的特性。
# 4. **图像处理与特征提取**
在本章中,我们将介绍如何利用Python进行手写数字图像的图像处理与特征提取。这些步骤对于数字识别算法的训练和预测非常关键。
#### 4.1 图像二值化与降噪处理
首先,我们将手写数字图像进行二值化处理,即将灰度图像转换为黑白图像,以便更好地提取数字特征。我们可以使用OpenCV库来实现这一步骤。
```python
import cv2
import numpy as np
# 读取灰度图像
img_gray = cv2.imread('digit_image.png', cv2.IMREAD_GRAYSCALE)
# 图像二值化处理
_, img_binary = cv2.threshold(img_gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 显示二值化后的图像
cv2.imshow('Binary Image', img_binary)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
通过上面的代码,我们可以将手写数字图像转换为黑白二值图像,便于后续处理。
#### 4.2 边缘检测算法
接下来,我们可以利用边缘检测算法来进一步提取数字图像的特征。常见的边缘检测算法有Sobel、Canny等,这里我们以Canny算法为例进行边缘检测。
```python
# Canny边缘检测
img_edges = cv2.Canny(img_binary, 100, 200)
# 显示边缘检测结果
cv2.imshow('Edges Image', img_edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
以上代码展示了Canny边缘检测算法对手写数字图像的应用,通过边缘信息可以更好地描述数字的形状。
#### 4.3 特征提取方法介绍
特征提取是数字识别算法中非常重要的一步,它能够从图像中提取出有助于区分不同数字的特征。常用的特征提取方法包括Histogram of Oriented Gradients (HOG)、Scale-Invariant Feature Transform (SIFT)等。
```python
# 使用HOG特征提取
hog = cv2.HOGDescriptor()
features = hog.compute(img_gray)
# 显示HOG特征
print("HOG Features:", features)
```
通过上述代码,我们可以利用HOG算法从手写数字图像中提取出特征,用于后续的数字识别训练。
在本章中,我们介绍了图像处理中常用的二值化、边缘检测以及特征提取方法,这些步骤为后续的数字识别算法提供了重要的数据基础。
# 5. **数字识别算法实现**
在本章节中,我们将介绍如何使用Python实现手写数字图像的识别算法。我们将分别讨论K近邻算法、支持向量机(SVM)算法以及深度学习神经网络模型的实现过程。
### 5.1 K近邻算法
K近邻算法是一种基本的分类与回归方法,通过计算不同样本之间的距离来确定待分类样本的类别。我们可以使用scikit-learn库中的KNeighborsClassifier类来实现K近邻算法。
```python
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 创建K近邻分类器
knn = KNeighborsClassifier(n_neighbors=3)
# 模型训练
knn.fit(X_train, y_train)
# 模型预测
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("K近邻算法准确率:", accuracy)
```
### 5.2 支持向量机(SVM)算法
支持向量机(SVM)是一种强大的监督学习算法,可以用于分类和回归任务。我们使用scikit-learn库中的SVC类来实现支持向量机算法。
```python
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 创建SVM分类器
svm = SVC(kernel='linear')
# 模型训练
svm.fit(X_train, y_train)
# 模型预测
y_pred = svm.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("支持向量机算法准确率:", accuracy)
```
### 5.3 深度学习神经网络模型
深度学习神经网络在图像识别领域取得了巨大成功。我们可以使用TensorFlow或者Keras等深度学习框架来构建神经网络模型进行数字识别。
```python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 构建神经网络模型
model = Sequential([
Dense(128, activation='relu', input_shape=(784,)),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 模型训练
model.fit(X_train, y_train, epochs=10, batch_size=32)
# 评估模型
_, accuracy = model.evaluate(X_test, y_test)
print("深度学习神经网络模型准确率:", accuracy)
```
通过以上代码实现了K近邻算法、支持向量机算法和深度学习神经网络模型的实现与训练,我们可以比较它们在数字识别任务上的表现,进一步评估不同算法的性能。
# 6. **实验与分析**
在这一章节中,我们将展示如何进行手写数字图像的识别算法实验,并对实验结果进行详细分析和讨论。我们将按照以下步骤展开:
#### 6.1 模型训练与评估
首先,我们将使用前面章节中介绍的K近邻算法、支持向量机(SVM)算法和深度学习神经网络模型对手写数字图像数据集进行训练。接着,我们将利用训练好的模型对测试集进行预测,并评估各模型的准确率、召回率等指标。
```python
# 代码示例:模型训练与评估
# 1. 使用K近邻算法进行训练和预测
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
y_pred_knn = knn.predict(X_test)
# 2. 使用SVM算法进行训练和预测
from sklearn.svm import SVC
svm = SVC(kernel='linear', C=1.0, random_state=0)
svm.fit(X_train, y_train)
y_pred_svm = svm.predict(X_test)
# 3. 使用深度学习神经网络模型进行训练和预测
import tensorflow as tf
# 搭建神经网络模型
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10)
y_pred_nn = model.predict_classes(X_test)
```
#### 6.2 算法性能比较
我们将对三种算法(K近邻算法、SVM算法、深度学习神经网络模型)在测试集上的性能进行比较分析,包括准确率、召回率、F1值等指标。通过比较不同算法的性能表现,可以帮助我们选择最适合手写数字图像识别的算法模型。
```python
# 代码示例:算法性能比较
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 计算K近邻算法性能指标
accuracy_knn = accuracy_score(y_test, y_pred_knn)
precision_knn = precision_score(y_test, y_pred_knn, average='macro')
recall_knn = recall_score(y_test, y_pred_knn, average='macro')
f1_knn = f1_score(y_test, y_pred_knn, average='macro')
# 计算SVM算法性能指标
accuracy_svm = accuracy_score(y_test, y_pred_svm)
precision_svm = precision_score(y_test, y_pred_svm, average='macro')
recall_svm = recall_score(y_test, y_pred_svm, average='macro')
f1_svm = f1_score(y_test, y_pred_svm, average='macro')
# 计算神经网络模型性能指标
accuracy_nn = accuracy_score(y_test, y_pred_nn)
precision_nn = precision_score(y_test, y_pred_nn, average='macro')
recall_nn = recall_score(y_test, y_pred_nn, average='macro')
f1_nn = f1_score(y_test, y_pred_nn, average='macro')
```
#### 6.3 结果展示与讨论
最后,我们将展示各个算法模型在测试集上的性能表现,并结合实际应用场景对结果进行深入分析和讨论。通过对实验结果的展示和讨论,我们可以更好地理解不同算法在手写数字图像识别中的优劣势,为进一步优化算法和模型提供参考。
通过这一章节的实验与分析,我们能够全面了解手写数字图像识别算法在Python中的实际运用,以及不同算法之间的比较和性能评估,为后续的研究和应用提供重要参考依据。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在探讨如何使用Python实现手写数字识别,而不借助sklearn的knn算法。通过深入的数据预处理和展示分析手段,着重讨论数据预处理在手写数字识别中的重要性。随后,我们将探讨如何优化手写数字识别模型的损失函数,以提高识别准确率。同时,专栏还将介绍如何利用Python实现手写数字图像的展示与分析,帮助读者更好地理解模型训练过程。最后,我们将重点关注如何实现手写数字识别模型的自动化训练,使整个识别过程更加高效和便捷。通过本专栏的学习,读者能够深入了解手写数字识别的原理与实践,为深入研究和应用该领域提供有力支持。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
理解SN29500-2010:IT专业人员的标准入门手册

# 摘要
SN29500-2010标准作为行业规范,对其核心内容和历史背景进行了概述,同时解析了关键条款,如术语定义、管理体系要求及信息安全技术要求等。本文还探讨了如何在实际工作中应用该标准,包括推广策略、员工培训、监督合规性检查,以及应对标准变化和更新的策略。文章进一步分析了SN29500-2010带来的机遇和挑战,如竞争优势、技术与资源
红外遥控编码:20年经验大佬揭秘家电控制秘籍
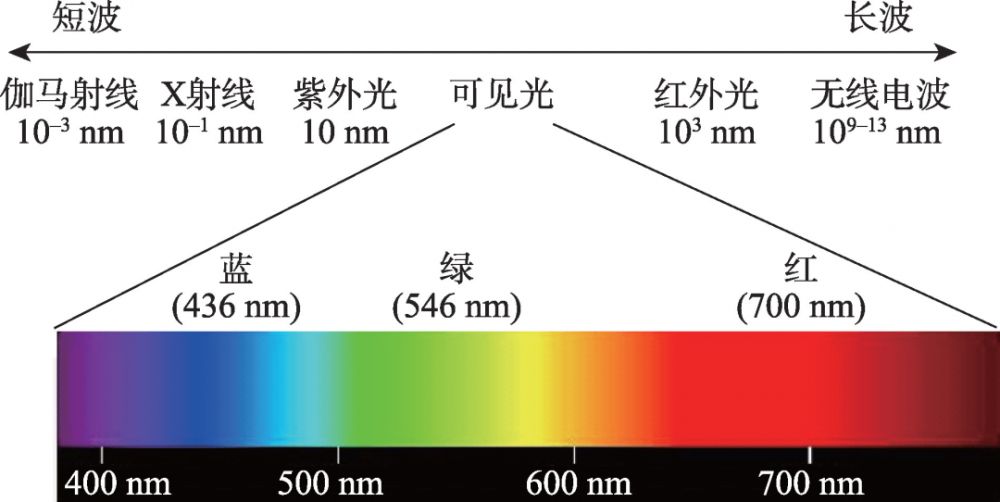
# 摘要
红外遥控技术作为无线通信的重要组成部分,在家电控制领域占有重要地位。本文从红外遥控技术概述开始,详细探讨了红外编码的基础理论,包括红外通信的原理、信号编码方式、信号捕获与解码。接着,本文深入分析了红外编码器与解码器的硬件实现,以及在实际编程实践中的应用。最后,本文针对红外遥控在家电控制中的应用进行了案例研究,并展望了红外遥控技术的未来趋势与创新方向,特别是在智能家居集成和技术创新方面。文章旨在为读者提
【信号完整性必备】:7系列FPGA SelectIO资源实战与故障排除
# 摘要
随着数字电路设计复杂度的提升,FPGA(现场可编程门阵列)已成为实现高速信号处理和接口扩展的重要平台。本文对7系列FPGA的SelectIO资源进行了深入探讨,涵盖了其架构、特性、配置方法以及在实际应用中的表现。通过对SelectIO资源的硬件组成、电气标准和参数配置的分析,本文揭示了其在高速信号传输和接口扩展中的关键作用。同时,本文还讨论了信号完整性
C# AES加密:向量化优化与性能提升指南
# 摘要
本文深入探讨了C#中的AES加密技术,从基础概念到实现细节,再到性能挑战及优化技术。首先,概述了AES加密的原理和数学基础,包括其工作模式和关键的加密步骤。接着,分析了性能评估的标准、工具,以及常见的性能瓶颈,着重讨论了向量化优化技术及其在AES加密中的应用。此外,本文提供了一份实践指南,包括选择合适的加密库、性能优化案例以及在安全性与性能之间寻找平衡点的策略。最后,展望了AES加密技术的未来趋势,包括新兴加密算法的演进和性能优化的新思路。本研究为C#开发者在实现高效且安全的AES加密提供了理论基础和实践指导。
# 关键字
C#;AES加密;对称加密;性能优化;向量化;SIMD指令
RESTful API设计深度解析:Web后台开发的最佳实践

# 摘要
本文全面探讨了RESTful API的设计原则、实践方法、安全机制以及测试与监控策略。首先,介绍了RESTful API设计的基础知识,阐述了核心原则、资源表述、无状态通信和媒体类型的选择。其次,通过资源路径设计、HTTP方法映射到CRUD操作以及状态码的应用,分析了RESTful API设计的具体实践。
【Buck电路布局绝招】:PCB设计的黄金法则
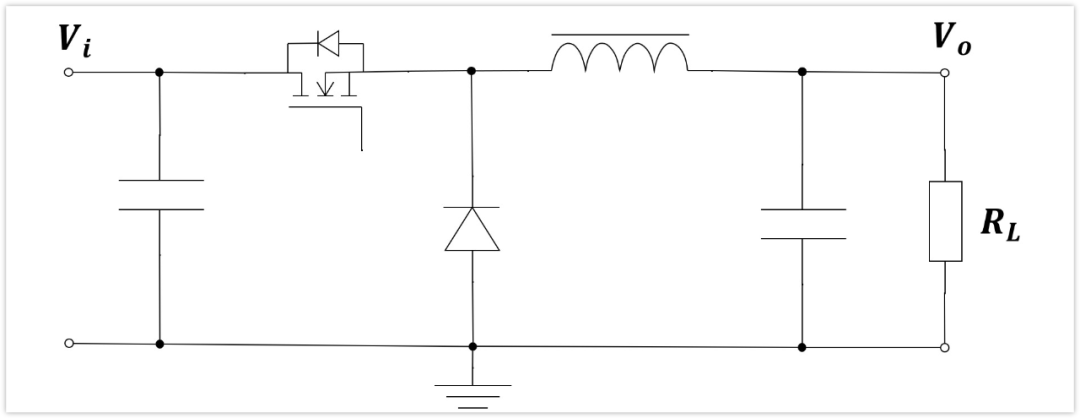
# 摘要
Buck转换器是一种广泛应用于电源管理领域的直流-直流转换器,它以高效和低成本著称。本文首先阐述了Buck转换器的工作原理和优势,然后详细分析了Buck电路布局的理论基础,包括关键参数、性能指标、元件选择、电源平面设计等。在实践技巧方面,本文提供了一系列提高电路布局效率和准确性的方法,并通过案例分析展示了低噪声、高效率以及小体积高功率密度设计的实现。最后,本文展望了Buck电
揭秘苹果iap2协议:高效集成与应用的终极指南
# 摘要
本文系统介绍了IAP2协议的基础知识、集成流程以及在iOS平台上的具体实现。首先,阐述了IAP2协议的核心概念和环境配置要点,包括安装、配置以及与iOS系统的兼容性问题。然后,详细解读了IAP2协议的核心功能,如数据交换模式和认证授权机制,并通过实例演示了其在iOS应用开发和数据分析中的应用技巧。此外,文章还探讨了IAP2协议在安全、云计算等高级领域的应用原理和案例,以及性能优化的方法和未来发展的方向。最后,通过大
ATP仿真案例分析:故障相电压波形A的调试、优化与实战应用
# 摘要
本文对ATP仿真软件及其在故障相电压波形A模拟中的应用进行了全面介绍。首先概述了ATP仿真软件的发展背景与故障相电压波形A的理论基础。接着,详细解析了模拟流程,包括参数设定、步骤解析及结果分析方法。本文还深入探讨了调试技巧,包括ATP仿真环境配置和常见问题的解决策略。在此基础上,提出了优化策略,强调参数优化方法和提升模拟结果精确性的重要性。最后,通过电力系统的实战应用案例,本文展示了故障分析、预防与控制策略的实际效果,并通过案例研究提炼出有价值的经验与建议。
# 关键字
ATP仿真软件;故障相电压波形;模拟流程;参数优化;故障预防;案例研究
参考资源链接:[ATP-EMTP电磁暂
【流式架构全面解析】:掌握Kafka从原理到实践的15个关键点

# 摘要
流式架构作为处理大数据的关键技术之一,近年来受到了广泛关注。本文首先介绍了流式架构的概念,并深入解析了Apache Kafka作为流式架构核心组件的引入背景和基础知识。文章深入探讨了Kafka的架构原理、消息模型、集群管理和高级特性,以及其在实践中的应用案例,包括高可用集群的实现和与大数据生态以及微
【SIM卡故障速查速修秘籍】:10分钟内解决无法识别问题

# 摘要
本文旨在为读者提供一份全面的SIM卡故障速查速修指导。首先介绍了SIM卡的工作原理及其故障类型,然后详细阐述了故障诊断的基本步骤和实践技巧,包括使用软件工具和硬件检查方法。本文还探讨了常规和高级修复策略,以及预防措施和维护建议,以减少SIM卡故障的发生。通过案例分析,文章详细说明了典型故障的解决过程。最后,展望了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )