【Python包管理秘籍】:Setuptools使用指南,从入门到精通
发布时间: 2024-10-07 14:08:05 阅读量: 103 订阅数: 21 
# 1. Python包管理概述
在现代软件开发中,代码的模块化和可重用性变得至关重要。Python作为一门语言,其包管理机制为代码的模块化和共享提供了强大的支持。本章节我们将探讨Python包管理的基本概念,包括什么是Python包,以及如何通过Python包来组织和管理代码。这将为我们深入理解下一章Setuptools的工作原理打下基础。我们会从Python包的定义开始,进一步讨论如何使用Python的包管理工具来安装和管理这些包,从而为读者构建一个清晰的Python包管理和Setuptools使用的概览。
# 2. Setuptools基础
## 2.1 Setuptools的安装和配置
### 2.1.1 安装Setuptools的步骤
Setuptools 是一个扩展的Python包管理系统,它提供了一种方便的方式来安装、升级和管理Python包。它使用 `setup.py` 文件描述包的元数据和配置。安装Setuptools的推荐方法是通过Python的包管理工具pip。
在Linux或macOS中,您可以使用以下命令来安装或升级Setuptools:
```bash
pip install --upgrade setuptools
```
在Windows上,安装步骤类似,但可能需要以管理员权限运行pip:
```powershell
python -m pip install --upgrade setuptools
```
为了确保正确安装,可以运行以下命令检查Setuptools版本:
```bash
python -m setuptools --version
```
安装完成后,您将能够使用 `setup.py` 文件来构建和分发Python包。
### 2.1.2 Setuptools的配置文件分析
Setuptools可以读取一个叫做 `setup.cfg` 的配置文件,它允许包的维护者以一种简单的方式来定制构建过程。这个文件一般位于包的根目录。
一个典型的 `setup.cfg` 文件可能包含以下内容:
```ini
[metadata]
name = example_package
version = 0.1
author = Your Name
author_email = your.***
[options]
packages = example_package
install_requires =
requests >= 2.0
beautifulsoup4 >= 4.0
[files]
packages =
example_package
example_package.subpackage
```
这个配置文件定义了包的元数据和依赖关系,还指明了要包含哪些文件和目录。通过这种方式,您可以在不修改 `setup.py` 文件的情况下调整配置,使得维护和更新变得更加容易。
## 2.2 创建第一个Python包
### 2.2.1 初始化Python包结构
创建一个新的Python包首先需要初始化包的结构。这通常包括创建包目录、初始化文件和 `setup.py` 文件。例如,创建一个名为 `example_package` 的包,您可以执行以下命令:
```bash
mkdir example_package
cd example_package
touch __init__.py
touch setup.py
```
在这个目录中,`__init__.py` 表示这个目录是一个Python模块,而 `setup.py` 将用来定义包的具体信息。
### 2.2.2 使用setup.py定义包信息
`setup.py` 文件是定义Python包核心信息的地方。以下是一个简单的 `setup.py` 文件示例:
```python
from setuptools import setup, find_packages
setup(
name="example_package",
version="0.1",
author="Your Name",
author_email="your.***",
description="A small example package",
packages=find_packages(),
install_requires=[
# 依赖列表
],
)
```
在这个例子中,`find_packages()` 函数自动找到所有包含 `__init__.py` 文件的包和子包。`install_requires` 参数列出了包的依赖。当别人安装您的包时,这些依赖也会自动安装。
## 2.3 打包和分发
### 2.3.1 构建源码包和wheel包
在分发您的Python包之前,您需要构建源码包和wheel包。源码包包含了包的所有源代码和 `setup.py` 文件,而wheel包是一个预构建的分发格式,可以加速安装过程。
使用Setuptools,您可以使用以下命令构建这两种类型的包:
```bash
python setup.py sdist bdist_wheel
```
上述命令将创建源码包和wheel包在 `dist/` 目录下。构建成功后,您可以将这些包分发给其他人或上传到PyPI。
### 2.3.2 上传包到PyPI
一旦您的包构建好,并准备好对外公开,您可以选择上传到Python Package Index (PyPI)。PyPI是Python包的官方索引,几乎所有的Python用户都从这里安装第三方包。
上传前,请确保您已经注册了一个PyPI账户,并且安装了 `twine`,这是推荐上传包的工具:
```bash
pip install twine
```
然后,使用以下命令上传您的包:
```bash
twine upload dist/*
```
您将需要输入您的PyPI账户的用户名和密码。上传成功后,任何人都可以使用以下命令安装您的包:
```bash
pip install example_package
```
以上步骤涵盖了Setuptools的基础知识,从安装和配置,到创建包、打包和分发。通过这些步骤,您将具备基本的能力来创建和管理Python包。在下一章中,我们将探讨Setuptools的高级特性,这将帮助您更好地扩展和优化您的包。
# 3. Setuptools的高级特性
## 3.1 依赖管理
### 3.1.1 定义和解析依赖
在软件开发中,依赖管理是一个至关重要的环节。对于Python包来说,确保项目可以正确地解析并安装所有必要的依赖是至关重要的。Setuptools提供了依赖管理的功能,允许开发者在`setup.py`文件中声明项目所需的依赖。
通过在`setup.py`的`install_requires`参数中列出依赖,Setuptools能够处理这些依赖的解析和安装:
```python
from setuptools import setup, find_packages
setup(
name='example_package',
version='0.1',
packages=find_packages(),
install_requires=[
'requests>=2.23.0',
'beautifulsoup4',
],
)
```
在上面的代码块中,`install_requires`列出了两个依赖项:`requests`和`beautifulsoup4`。其中`requests`指定了最小版本号`2.23.0`。这意味着在安装`example_package`时,Setuptools会检查这些依赖项是否已经安装在目标系统上,如果没有,则会自动从PyPI或指定的索引URL中下载并安装这些依赖。
依赖解析时也会考虑指定的Python版本和操作系统要求。如果依赖项有特定版本的Python或操作系统的限制,Setuptools会根据运行环境进行筛选,确保只安装适合当前环境的依赖。
### 3.1.2 处理依赖冲突
依赖管理的另一面是处理潜在的依赖冲突。冲突可能发生在两个或多个依赖项需要不同版本的同一个包,或者当一个包不兼容另一个包的API时。Setuptools在安装依赖时会尝试解决这些冲突,但是并非总是能够成功。
为了处理依赖冲突,Setuptools提供了一些策略选项。例如,可以使用`extras_require`来区分可选依赖,这样只有在明确指定的情况下才会安装这些依赖项:
```python
setup(
name='example_package',
version='0.1',
extras_require={
'dev': ['pytest', 'tox'],
'docs': ['sphinx'],
},
)
```
此外,可以使用其他工具如`pip-tools`或`pip-compile`,这些工具可以锁定依赖项版本并生成一致的`requirements.txt`文件,从而避免在不同环境中的依赖冲突。
通过合理配置依赖项及其版本,可以有效地减少运行时错误和潜在的兼容性问题,提高项目的稳定性。
## 3.2 入口点和插件机制
### 3.2.1 入口点的概念和用法
入口点(entry points)是Setuptools提供的一种扩展点机制,允许其他包通过一个标准化的接口来发现并使用本包提供的组件。这些组件可以是命令行工具、插件、服务或任何可以通过名称引用的实体。
入口点在`setup.py`文件的`entry_points`参数中定义,通常用于声明插件、控制台脚本或应用程序插槽:
```python
setup(
name='example_package',
version='0.1',
entry_points={
'console_scripts': [
'example-cli = example_package.cli:main',
],
'my_package.plugins': [
'plugin_a = example_package.plugin_a:PluginA',
],
},
)
```
在上面的例子中,`console_scripts`定义了一个控制台脚本,这个脚本将`example-cli`这个名字关联到`example_package`包中的`cli.py`模块里的`main`函数。当安装了这个包之后,就可以在命令行中直接调用`example-cli`来运行程序了。
`my_package.plugins`是一个插件点,这里定义了一个名为`plugin_a`的插件,它引用了`example_package`包中的`plugin_a.py`模块以及该模块中的`PluginA`类。其他程序可以通过`entry_points`提供的名称找到并加载这个插件。
### 3.2.2 创建和使用插件系统
创建插件系统可以让其他开发者扩展你的包的功能,而不必修改包内部代码。为了创建插件系统,我们需要定义一组入口点,让其他开发者可以为这些入口点编写插件,并在`setup.py`中注册这些插件。
这里有一个简单的示例,说明如何注册一个插件点并使用它:
```python
from setuptools import setup, find_packages
setup(
name='example_package',
version='0.1',
packages=find_packages(),
entry_points={
'example_package.plugins': [
'plugin_1 = example_package.plugins.plugin_1:Plugin1',
],
},
)
# plugin_1.py
class Plugin1:
def run(self):
print("Plugin1 is running")
# 使用插件
from example_package.plugins.plugin_1 import Plugin1
def main():
plugin = Plugin1()
plugin.run()
if __name__ == "__main__":
main()
```
在这个例子中,我们定义了一个名为`example_package.plugins`的插件点,并注册了一个插件`plugin_1`。在包的其他部分,我们可以通过简单的导入语句来使用这个插件。当调用`main`函数时,插件`Plugin1`的`run`方法将被执行。
通过这种方式,其他开发者可以遵循一定的约定来为`example_package.plugins`编写自己的插件,并且在他们的项目中使用相同的`setup.py`模板来注册这些插件。这样就可以构建一个动态的生态系统,其中包的原始作者不需要直接参与,但是其他开发者可以贡献代码。
## 3.3 命令扩展与自定义
### 3.3.1 Setuptools内置命令介绍
Setuptools不仅提供了基本的安装和打包功能,还内置了一些有用的命令,可以通过`setup.py`使用。这些命令允许开发者执行如构建源码包、运行测试、生成文档等常见的任务。
以下是一些常见的Setuptools内置命令及其用途:
- `install`:安装指定的包。
- `develop`:安装开发模式,对源代码的更改会实时反映。
- `sdist`:创建源码分发包。
- `bdist_wheel`:创建wheel分发包。
- `test`:运行测试套件。
- `build`:构建包的构建目录。
- `check`:运行所有检查来确保代码符合PEP 517。
- `upload`:上传包到PyPI。
要使用这些命令,只需在命令行中调用`python setup.py <command>`,其中`<command>`是你想要执行的命令名。例如,要上传包到PyPI,可以使用:
```sh
python setup.py sdist bdist_wheel upload
```
### 3.3.2 编写自定义命令扩展
除了内置的命令,Setuptools还允许开发者通过自定义命令扩展其功能。这些命令可以是包特定的实用工具,也可以是与特定工作流程相关的操作。
自定义命令扩展通常涉及定义一个继承自`***mand`的类,并实现必要的方法:
```python
from setuptools import setup, Command
class MyCustomCommand(Command):
description = "My custom setuptools command"
user_options = []
def initialize_options(self):
pass
def finalize_options(self):
pass
def run(self):
print("Running my custom setuptools command")
setup(
name='example_package',
version='0.1',
cmdclass={
'my_custom_command': MyCustomCommand,
},
)
```
在上面的代码中,我们创建了一个名为`MyCustomCommand`的新命令,并在`setup.py`中通过`cmdclass`字典将其注册为`my_custom_command`。这样,在命令行中执行:
```sh
python setup.py my_custom_command
```
将会触发`MyCustomCommand`类的`run`方法,输出一条消息到控制台。
自定义命令非常适合自动化项目特有的工作流程,比如部署脚本、数据迁移、环境设置等。通过在`setup.py`中注册这些命令,你可以确保它们可以方便地在整个团队中共享和使用。
### 3.3.2 编写自定义命令扩展(续)
为了进一步展示自定义命令的灵活性,我们可以构建一个更加复杂的命令,它具备参数解析和执行逻辑。例如,假设我们想添加一个命令来自动化数据库迁移,我们可以这样实现:
```python
from setuptools import setup, ***
***mand.sdist import sdist
class GenerateMigrationScript(Command):
description = "Generate a new database migration script"
user_options = [
('message=', 'm', 'Message describing the migration'),
]
def initialize_options(self):
self.message = None
def finalize_options(self):
if self.message is None:
self.message = "No message provided"
def run(self):
# Here we would implement the logic to generate a migration script
# with the given message.
print(f"Generating migration script with message: '{self.message}'")
# Code to actually generate the script...
# ...
# Then register the command
setup(
name='example_package',
version='0.1',
cmdclass={
'generate_migration': GenerateMigrationScript,
},
)
```
在上面的代码中,`GenerateMigrationScript`类实现了自定义的`generate_migration`命令。这个命令接受一个参数`--message`(或`-m`),用于描述迁移的目的。`run`方法将被调用执行具体的逻辑,这里只是简单地打印出了将要执行的操作。
开发者可以像使用其他Setuptools命令一样使用这个自定义命令:
```sh
python setup.py generate_migration --message="Add new user table"
```
这个命令将会调用`run`方法,并带有`message`参数,我们可以根据这个参数来生成相应的数据库迁移脚本。
通过编写自定义命令,开发者可以极大地扩展Setuptools的功能,使其更加贴合特定项目的需求。这样的命令通常可以非常有效地集成到项目的持续集成和交付(CI/CD)流程中,提高工作效率。
# 4. Setuptools在实践中的应用
在这一章节中,我们将深入探讨Setuptools在实际开发工作流中的应用,包括如何搭建和配置开发环境,如何实现版本控制和维护向后兼容性,以及如何有效进行包的维护和更新。这些内容不仅涵盖了基础知识,还深入到实际开发和维护的细节中,对于希望提升其Python包管理技能的开发者来说是不可或缺的。
## 4.1 开发环境的搭建与配置
开发一个Python包通常需要一个干净且可复现的环境,以避免不同项目之间的依赖冲突。创建虚拟环境是Python开发中的一个标准步骤,它允许开发人员在一个隔离的环境中安装和测试代码,而不影响系统级的安装包。
### 4.1.1 创建虚拟环境
使用Python的内置模块`venv`可以轻松创建一个虚拟环境。下面是一个创建虚拟环境的基本示例:
```bash
# 在项目目录中创建一个名为venv的虚拟环境目录
python -m venv venv
# 激活虚拟环境(Windows)
venv\Scripts\activate
# 激活虚拟环境(Unix或MacOS)
source venv/bin/activate
```
执行以上步骤后,你的命令行提示符将显示虚拟环境名称,表示已经成功激活了虚拟环境。
### 4.1.2 开发和测试用包的安装
安装项目包到虚拟环境中一般有两种方式:直接安装正在开发中的包或通过requirements文件安装。
#### 直接安装开发包
在开发过程中,可以直接将包安装到虚拟环境中,以便测试修改。如果包目录已经包含`setup.py`文件,可以使用以下命令:
```bash
pip install -e .
```
这里的`-e`参数代表可编辑模式(editable mode),任何对源代码的修改都会立即反映在安装包中,无需重新安装。
#### 通过requirements文件安装
在发布软件前,创建一个`requirements.txt`文件可以确保其它开发人员或部署环境可以复现相同的依赖环境。你可以通过以下命令生成依赖文件:
```bash
pip freeze > requirements.txt
```
然后在新的开发环境中安装相同依赖:
```bash
pip install -r requirements.txt
```
### 4.1.3 依赖管理
依赖管理是确保软件稳定运行的关键。`setup.py`文件允许你指定项目所依赖的包和版本。例如:
```python
# setup.py文件的片段
install_requires=[
'requests>=2.25.1',
'beautifulsoup4',
'numpy==1.19.5'
]
```
上面的例子中,我们声明了三个依赖:`requests`、`beautifulsoup4` 和 `numpy`,并给出了具体的版本要求。
### 4.1.4 配置测试环境
测试是确保代码质量的重要环节。你可以使用`pytest`等测试框架来编写和执行测试用例。一般而言,测试用例会放在一个`tests`目录下。运行测试用例的命令如下:
```bash
pytest tests/
```
## 4.2 包的版本控制和兼容性
版本控制和兼容性是维护长期项目中的关键因素。能够管理好这些方面意味着能向用户提供清晰的升级路径,并且能有效应对不同版本带来的潜在问题。
### 4.2.1 使用setuptools_scm管理版本
`setuptools_scm`是一个自动化版本管理工具,它允许开发者通过源代码控制来管理版本,无需手动编辑`setup.py`文件中的版本号。使用`setuptools_scm`的配置示例如下:
```python
# setup.py中的配置
from setuptools_scm import get_version
setup(
use_scm_version={
"write_to": "your_package/_version.py",
"write_to_template": '__version__ = "{version}"',
},
# ...
)
```
### 4.2.2 处理向后兼容性问题
在更新版本时,保持向后兼容性是非常重要的。处理这类问题的一个常见方法是采用语义版本控制。版本号通常由三个部分组成:主版本号、次版本号和补丁号,分别为MAJOR.MINOR.PATCH。这样的划分允许用户知道一个新版本是否破坏了现有功能。
此外,还可以提供特定的兼容性层来解决API变化,例如通过弃用警告(deprecation warnings)来引导用户如何升级。
## 4.3 维护和更新包
随着项目的发展,维护一个包可能包括更新文档、修复bug、发布新版本等。有效管理这些过程对于维护一个健康和活跃的项目至关重要。
### 4.3.1 更新包的流程和注意事项
更新包通常包含以下步骤:
1. 修改代码和文档。
2. 在虚拟环境中进行彻底的测试。
3. 修改`setup.py`文件中的版本号。
4. 更新`CHANGELOG.md`文件,列出新版本的变更。
5. 创建一个新的源码包和wheel包。
6. 上传新版本到PyPI。
在更新过程中,注意要确保所有依赖依然兼容,并且新旧代码之间保持一致性。另外,如果有必要,可以考虑使用语义版本控制策略,并使用如`bumpversion`这样的工具来自动化版本号的更新。
### 4.3.2 处理用户反馈和bug修复
在处理用户反馈和bug修复时,应该按照以下步骤进行:
1. 为每个bug创建一个单独的issue或Pull Request(PR)。
2. 分支工作流程,从主分支拉出修复分支。
3. 修复bug并编写相应的单元测试。
4. 提交修复到分支,并推送到远程仓库。
5. 请求代码审查,确保代码质量。
6. 将修复合并到主分支,并关闭相应的issue或PR。
代码审查是一个重要环节,它不仅帮助确保代码质量,还有助于代码风格的一致性,并且是知识共享的好机会。对于代码审查,可以使用如`GitHub`或`GitLab`内置的代码审查工具,也可以采用如`Review Board`等更专业的工具。
# 5. Setuptools的优化与最佳实践
Setuptools 不仅可以用于创建和分发 Python 包,还提供了一系列优化和最佳实践来提升开发效率,确保代码质量和提高包的安全性。本章节将详细介绍性能优化策略、社区贡献与团队协作、安全性和代码审查等方面的实践。
## 5.1 性能优化策略
随着项目规模的扩大和依赖关系的增加,性能优化变得尤为重要。以下是一些Setuptools的性能优化策略。
### 5.1.1 减少依赖和包大小
为了减少包的大小和依赖,可以采取以下措施:
- **分析依赖**:使用工具如 `pip-tools` 来审计和精简依赖列表。
- **移除未使用的代码和资源**:通过分析包的内容,删除不必要的资源和文件。
- **使用依赖替代**:某些情况下,一个库可以替代多个较小的库。
### 5.1.2 加速构建和安装过程
为了加快构建和安装速度,可以考虑以下方法:
- **缓存机制**:利用缓存机制,对不经常变更的依赖或编译文件进行缓存。
- **并行构建**:使用 `python setup.py build --parallel` 来启用并行编译。
- **减少构建步骤**:仔细检查 `setup.py` 文件,减少不必要的构建步骤。
## 5.2 社区贡献与团队协作
开源项目需要良好的社区贡献和团队协作机制,以确保项目的健康发展。
### 5.2.1 贡献Setuptools的流程
- **Fork仓库**:在 GitHub 上fork官方仓库,开始贡献流程。
- **遵循贡献指南**:阅读并遵循项目贡献指南进行开发。
- **提交Pull Request**:完成改动后,在自己的仓库提交Pull Request等待审核。
### 5.2.2 多人协作下的版本控制
在多人协作环境下,建议使用以下策略:
- **明确版本控制规则**:确保每个成员都了解如何正确使用分支和提交规范。
- **使用Pull/Merge Requests**:通过合并请求进行代码审查和讨论,避免直接在主分支上推送代码。
- **自动化测试和持续集成**:使用 CI/CD 流程确保代码质量。
## 5.3 安全性和代码审查
安全是开发过程中的重要组成部分,代码审查是发现和修复潜在问题的重要手段。
### 5.3.1 检查和避免常见的安全漏洞
- **使用安全检查工具**:如 `bandit`、`safety`、`vulture` 等工具进行安全漏洞扫描。
- **限制第三方库的权限**:对第三方库进行权限和风险评估。
- **更新依赖**:定期更新依赖库以修复已知的安全问题。
### 5.3.2 代码审查的工具和流程
- **代码审查工具**:使用 `gitchk`、`Reviewable` 等工具来辅助代码审查。
- **审查流程**:建立清晰的审查流程,确保每个提交都经过审查。
- **反馈和改进**:在审查中提出建议,并跟踪修复情况。
通过本章的内容,我们已经讨论了Setuptools优化的多个方面,包括性能、社区贡献、团队协作以及安全性与代码审查。了解这些实践将帮助开发者和团队更高效地构建和维护Python包,提升整体的开发体验。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 包管理工具 Setuptools,从入门到精通,涵盖了各种主题。从包管理基础到高级技巧,如自动化构建、脚本编写、插件机制和版本控制。专栏还介绍了跨平台构建、依赖管理、打包策略和元数据解析。此外,还提供了代码示例、最佳实践和 Setuptools 与 PyPI 和 pip 的协同作用。通过本专栏,读者将成为 Python 包管理专家,能够创建、构建和分发可维护和可扩展的 Python 程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Catia曲线曲率分析深度解析:专家级技巧揭秘(实用型、权威性、急迫性)
# 摘要
本文全面介绍了Catia软件中曲线曲率分析的理论、工具、实践技巧以及高级应用。首先概述了曲线曲率的基本概念和数学基础,随后详细探讨了曲线曲率的物理意义及其在机械设计中的应用。文章第三章和第四章分别介绍了Catia中曲线曲率分析的实践技巧和高级技巧,包括曲线建模优化、问题解决、自动化定制化分析方法。第五章进一步探讨了曲率分析与动态仿真、工业设计中的扩展应用,以及曲率分析技术的未来趋势。最后,第六章对Catia曲线曲率分析进行了
【MySQL日常维护】:运维专家分享的数据库高效维护策略
# 摘要
本文全面介绍了MySQL数据库的维护、性能监控与优化、数据备份与恢复、安全性和权限管理以及故障诊断与应对策略。首先概述了MySQL基础和维护的重要性,接着深入探讨了性能监控的关键性能指标,索引优化实践,SQL语句调优技术。文章还详细讨论了数据备份的不同策略和方法,高级备份工具及技巧。在安全性方面,重点分析了用户认证和授权机制、安全审计以及防御常见数据库攻击的策略。针对故障诊断,本文提供了常
EMC VNX5100控制器SP硬件兼容性检查:专家的完整指南

# 摘要
本文旨在深入解析EMC VNX5100控制器的硬件兼容性问题。首先,介绍了EMC VNX5100控制器的基础知识,然后着重强调了硬件兼容性的重要性及其理论基础,包括对系统稳定性的影响及兼容性检查的必要性。文中进一步分析了控制器的硬件组件,探讨了存储介质及网络组件的兼容性评估。接着,详细说明了SP硬件兼容性检查的流程,包括准备工作、实施步骤和问题解决策略。此外
【IT专业深度】:西数硬盘检测修复工具的专业解读与应用(IT专家的深度剖析)
# 摘要
本文旨在全面介绍硬盘的基础知识、故障检测和修复技术,特别是针对西部数据(西数)品牌的硬盘产品。第一章对硬盘的基本概念和故障现象进行了概述,为后续章节提供了理论基础。第二章深入探讨了西数硬盘检测工具的理论基础,包括硬盘的工作原理、检测软件的分类与功能,以及故障检测的理论依据。第三章则着重于西数硬盘修复工具的使用技巧,包括修复前的准备工作、实际操作步骤和常见问题的解决方法。第四章与第五章进一步探讨了检测修复工具的深入应
【永磁电机热效应探究】:磁链计算如何影响电机温度管理
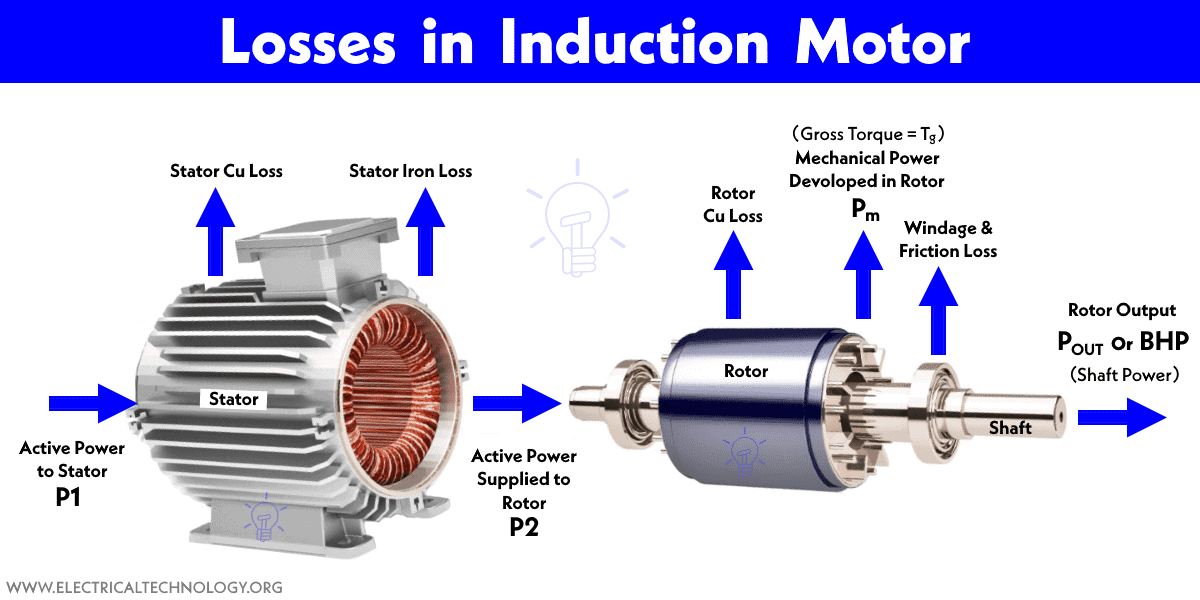
# 摘要
本论文对永磁电机的基础知识及其热效应进行了系统的概述。首先,介绍了永磁电机的基本理论和热效应的产生机制。接着,详细探讨了磁链计算的理论基础和计算方法,以及磁链对电机温度的影响。通过仿真模拟与分析,评估了磁链计算在电机热效应分析中的应用,并对仿真结果进行了验证。进一步地,本文讨论了电机温度管理的实际应用,包括热效应监测技术和磁链控制策略的
【代码重构在软件管理中的应用】:详细设计的革新方法

# 摘要
代码重构是软件维护和升级中的关键环节,它关注如何提升代码质量而不改变外部行为。本文综合探讨了代码重构的基础理论、深
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【CentOS 7时间同步终极指南】:掌握NTP配置,提升系统准确性
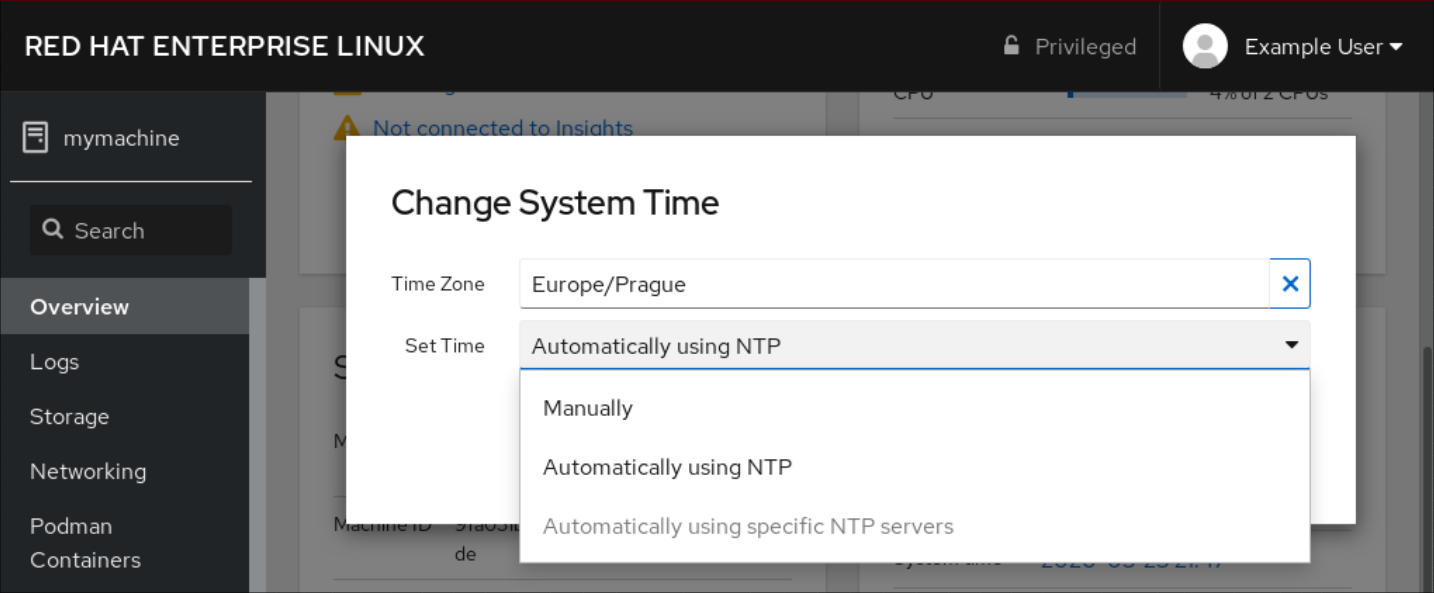
# 摘要
本文深入探讨了CentOS 7系统中时间同步的必要性、NTP(Network Time Protocol)的基础知识、配置和高级优化技术。首先阐述了时
轮胎充气仿真深度解析:ABAQUS模型构建与结果解读(案例实战)

# 摘要
轮胎充气仿真是一项重要的工程应用,它通过理论基础和仿真软件的应用,能够有效地预测轮胎在充气过程中的性能和潜在问题。本文首先介绍了轮胎充气仿真的理论基础和应用,然后详细探讨了ABAQUS仿真软件的环境配置、工作环境以及前处理工具的应用。接下来,本文构建了轮胎充气模型,并设置了相应的仿真参数。第四章分析了仿真的结果,并通过后处理技术和数值评估方法进行了深入解读。最后,通过案例实战演练,本文演示了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )