Talend数据集成入门指南
发布时间: 2024-02-21 21:38:20 阅读量: 76 订阅数: 17 
# 1. 认识Talend数据集成
## 1.1 什么是数据集成
数据集成是指将来自不同数据源的数据进行整合,以实现数据的统一管理、分析或应用的过程。在大数据时代,数据集成变得尤为重要,能帮助组织提高数据的可靠性、一致性和可用性。
## 1.2 Talend数据集成的概述
Talend是一款强大的开源数据集成工具,提供了可视化的开发环境和丰富的组件库,帮助用户快速构建数据集成作业。通过Talend,用户可以轻松地连接不同的数据源,并进行数据转换、清洗、映射等操作。
## 1.3 为什么选择Talend作为数据集成工具
- Talend拥有直观的图形化界面,减少了复杂的编程过程,降低了学习门槛;
- Talend支持多种数据源,包括关系型数据库、NoSQL数据库、云数据服务等,能够满足不同场景的数据集成需求;
- Talend提供了丰富的组件库和预置的数据转换功能,能够快速实现数据集成作业的开发与部署。
# 2. Talend安装与配置
Talend作为一款强大的数据集成工具,其安装与配置是使用该工具的第一步。在这一章节中,我们将介绍如何下载、安装Talend Studio,并配置工作环境,以便顺利开始数据集成工作。
### 2.1 下载与安装Talend Studio
要安装Talend Studio,首先需要前往[Talend官方网站](https://www.talend.com)下载适用于您操作系统的安装程序。根据操作系统类型,选择合适的安装版本,如Windows、macOS或Linux。
下载完成后,双击安装程序,按照安装向导的步骤进行操作。安装完成后,打开Talend Studio,您就可以开始创建数据集成作业了。
### 2.2 配置Talend Studio环境
在打开Talend Studio之后,您需要配置工作环境,以适应您的数据集成需求。配置工作环境包括设置工作目录、连接到数据源、配置元数据等操作。
在Talend Studio的主界面中,点击菜单栏中的"Window" -> "Preferences",您可以在弹出的窗口中配置各种参数,如默认编码、元数据导入路径、数据库连接等。
### 2.3 连接到数据源
连接到数据源是数据集成的基础,只有成功连接到数据源,才能实现数据的抽取、转换和加载。在Talend Studio中,您可以通过各种组件来连接不同类型的数据源,如关系型数据库、文件、云数据服务等。
在Talend Studio中,创建一个新的连接,您需要提供数据源的相关信息,如主机名、端口号、用户名、密码等。连接成功后,您就可以从数据源中抽取数据,并进行后续的数据处理操作了。
通过以上步骤,您已经成功安装并配置了Talend Studio,同时也连接到了数据源,为后续的数据集成工作奠定了基础。在接下来的章节中,我们将深入探讨Talend数据集成的基础知识和高级技术。
# 3. Talend数据集成基础
在本章中,我们将介绍Talend数据集成的基础知识,包括如何创建第一个数据集成作业,设置数据源与目标,以及使用Talend组件进行数据转换与清洗。
#### 3.1 创建第一个数据集成作业
要创建第一个数据集成作业,首先打开Talend Studio,并按照以下步骤操作:
1. 点击“File” -> “New” -> “Job”来创建一个新的作业。
2. 在作业设计界面,从工具栏中拖拽需要的组件到设计区域,例如输入数据源组件、输出目标组件以及转换组件。
3. 连接这些组件,设置其属性和参数。
4. 编写作业代码,可以使用Java, Python等等语言。
```java
public class MyFirstJob {
public static void main(String[] args) {
// 创建Talend作业
TalendJob job = new TalendJob();
// 设置数据源
DataSource source = new DataSource("source_database");
job.setDataSource(source);
// 设置目标
DataTarget target = new DataTarget("target_database");
job.setDataTarget(target);
// 数据转换与清洗
job.transformData();
// 执行作业
job.runJob();
}
}
```
5. 运行作业并查看结果。
#### 3.2 数据源与目标的设置
在Talend中,您可以轻松地设置数据源和目标。只需在工具栏中选择相应的组件,然后配置其属性,即可连接到数据库、文件、API等各种数据源。
```python
# 设置数据源
def setDataSource(source_name):
source = DataSource(source_name)
source.connect()
source.extractData()
return source
# 设置数据目标
def setDataTarget(target_name):
target = DataTarget(target_name)
target.connect()
return target
```
#### 3.3 使用Talend组件进行数据转换与清洗
Talend提供了丰富的组件来帮助您进行数据转换与清洗操作。您可以使用这些组件来过滤数据、合并数据、计算新字段等等。
```javascript
// 使用Talend组件进行数据转换
function transformData(source, target) {
// 过滤数据
source.filterData();
// 数据转换
source.transformData();
// 清洗数据
target.cleanData();
// 合并数据
target.mergeData(source);
}
```
通过以上步骤,您可以轻松地完成第一个数据集成作业,并对数据进行转换与清洗操作。这将为您后续的数据集成工作打下坚实的基础。
# 4. 高级数据集成技术
在这一章,我们将深入探讨Talend数据集成的高级技术,包括数据映射与转换、定时任务与调度,以及错误处理与数据质量监控。通过学习本章内容,您将能够更好地利用Talend来完成复杂的数据集成任务,并确保数据的质量与准确性。
#### 4.1 数据映射与转换
在实际的数据集成过程中,经常需要对数据进行映射与转换,以满足目标系统的要求。Talend提供了丰富的组件与功能来支持数据的映射与转换,例如数据格式转换、列值计算、条件过滤等。让我们通过一个实际的案例来演示数据映射与转换的操作。
```java
public class DataMappingJob {
public void mapAndTransformData() {
// 读取源数据
SourceData sourceData = readSourceData();
// 数据映射与转换
TransformedData transformedData = mapAndTransform(sourceData);
// 写入目标数据
writeTransformedData(transformedData);
}
// 具体的数据处理逻辑
private SourceData readSourceData() {
// 读取源数据的代码
// ...
}
private TransformedData mapAndTransform(SourceData sourceData) {
// 数据映射与转换的代码
// ...
}
private void writeTransformedData(TransformedData transformedData) {
// 写入目标数据的代码
// ...
}
}
```
代码总结:
- 通过`readSourceData`方法读取源数据。
- 调用`mapAndTransform`方法进行数据映射与转换。
- 最终将转换后的数据通过`writeTransformedData`方法写入目标数据。
结果说明:
通过数据映射与转换,我们可以根据目标系统的要求对数据进行定制化处理,使数据能够完美地适配目标系统的数据结构与规范。
#### 4.2 定时任务与调度
Talend还支持定时任务与调度功能,可以方便地设置定时执行数据集成作业,满足数据更新与同步的需求。接下来,我们通过Java代码来演示如何在Talend中实现定时任务与调度。
```java
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class ScheduledDataIntegrationJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// 调用数据集成作业
DataIntegrationJob job = new DataIntegrationJob();
job.run();
}
}
```
代码总结:
- 创建一个实现`Job`接口的定时任务类`ScheduledDataIntegrationJob`。
- 在`execute`方法中调用实际的数据集成作业`DataIntegrationJob`。
结果说明:
通过定时任务与调度功能,我们可以轻松实现数据集成作业的定期执行,保证数据的及时更新与同步。
#### 4.3 错误处理与数据质量监控
最后,我们来讨论在Talend中如何处理错误并进行数据质量监控。通过以下Java代码,我们可以演示如何在Talend作业中捕获错误并进行相应的处理。
```java
public class ErrorHandlingJob {
public void handleErrorsAndMonitorDataQuality() {
try {
// 执行数据集成作业
DataIntegrationJob job = new DataIntegrationJob();
job.run();
} catch (Exception e) {
// 捕获作业执行过程中的异常
// 发送告警邮件或记录日志
System.out.println("作业执行出现异常:" + e.getMessage());
// ... 发送邮件或记录日志的代码
} finally {
// 监控数据质量
DataQualityMonitor qualityMonitor = new DataQualityMonitor();
qualityMonitor.checkDataQuality();
}
}
}
```
代码总结:
- 在`handleErrorsAndMonitorDataQuality`方法中执行数据集成作业,并捕获可能出现的异常。
- 在`finally`块中,调用`DataQualityMonitor`类的`checkDataQuality`方法,对数据质量进行监控。
结果说明:
通过错误处理与数据质量监控,我们能够及时发现并处理数据集成过程中的异常情况,确保数据的可靠性与准确性。
在本章中,我们了解了Talend数据集成的高级技术,包括数据映射与转换、定时任务与调度,以及错误处理与数据质量监控。这些技术将帮助您更加灵活高效地完成各类数据集成任务,并确保数据的质量与一致性。
# 5. Talend数据集成的实际应用
在这一章节中,我们将探讨Talend数据集成在实际应用中的三个重要场景。通过这些实际案例,你将更好地理解Talend数据集成的强大功能以及如何应用于实际业务中。
#### 5.1 将数据从数据库导入到数据仓库
在这一节中,我们将学习如何使用Talend数据集成工具,将数据从一个数据库导入到数据仓库。我们将使用Talend Studio创建数据集成作业,配置数据源和目标,以及进行数据转换与清洗,最终实现数据库到数据仓库的数据迁移。
```java
// 示例代码
// 连接到数据库
public static void connectToDatabase() {
// 连接数据库的代码
}
// 从数据库读取数据
public static void fetchDataFromDatabase() {
// 从数据库读取数据的代码
}
// 数据转换与清洗
public static void transformAndCleanData() {
// 数据转换与清洗的代码
}
// 将数据导入数据仓库
public static void loadDataIntoDataWarehouse() {
// 将数据导入数据仓库的代码
}
```
代码总结:以上示例代码演示了使用Talend Studio中的Talend组件来实现数据库到数据仓库的数据迁移过程,包括连接数据库、读取数据、数据转换与清洗以及导入数据仓库等步骤。
结果说明:通过Talend数据集成工具,我们成功地将数据从数据库导入到数据仓库,实现了数据迁移的需求。
#### 5.2 数据库之间的数据同步
在这一节中,我们将学习如何使用Talend数据集成工具实现不同数据库之间的数据同步。我们将使用Talend Studio创建一个定时任务作业,配置多个数据源并设置数据同步策略,以及处理数据同步过程中可能出现的错误情况。
```java
// 示例代码
// 配置数据库连接
public static void configureDatabaseConnection() {
// 配置数据库连接的代码
}
// 设置数据同步策略
public static void setDataSyncStrategy() {
// 设置数据同步策略的代码
}
// 定时任务与调度
public static void scheduleDataSyncJob() {
// 设置定时任务与调度的代码
}
// 错误处理与数据质量监控
public static void handleErrorsAndMonitorDataQuality() {
// 错误处理与数据质量监控的代码
}
```
代码总结:以上示例代码演示了使用Talend Studio中的定时任务与调度功能,以及错误处理与数据质量监控功能,来实现数据库之间的数据同步。
结果说明:通过Talend数据集成工具,我们成功地实现了不同数据库之间的数据同步,并且能够监控数据质量和处理可能出现的错误情况。
#### 5.3 与云数据服务集成
在这一节中,我们将学习如何使用Talend数据集成工具与云数据服务进行集成。我们将以AWS S3为例,演示如何使用Talend Studio连接到AWS S3,进行数据读写操作,以及实现数据集成与云服务的交互。
```java
// 示例代码
// 连接到AWS S3
public static void connectToAWSS3() {
// 连接到AWS S3的代码
}
// 读取数据并写入AWS S3
public static void readWriteDataToAWSS3() {
// 读取数据并写入AWS S3的代码
}
// 实现数据集成与云服务的交互
public static void integrateWithDataServices() {
// 实现数据集成与云服务的交互的代码
}
```
代码总结:以上示例代码演示了如何使用Talend Studio连接到AWS S3,进行数据读写操作,以及实现数据集成与云服务的交互。
结果说明:通过Talend数据集成工具,我们成功地与AWS S3进行了数据集成,实现了与云数据服务的交互,为业务应用提供了更多的数据支持和灵活性。
通过这一章节的学习,我们可以更深入地了解Talend数据集成工具在实际应用中的丰富功能和应用场景。
# 6. 最佳实践与进阶技巧
在数据集成领域,除了掌握基本的操作技巧外,还需要学习一些最佳实践和进阶技巧,以提高工作效率和数据处理质量。本章将介绍一些关于Talend数据集成的最佳实践和进阶技巧,帮助您更好地运用Talend Studio进行数据集成功能。
#### 6.1 Talend数据集成的最佳实践
在实际项目中,遵循一些最佳实践可以帮助您更高效地完成数据集成任务。以下是一些Talend数据集成的最佳实践:
1. **合理规划作业设计**:在设计作业时,要考虑数据流转的逻辑,合理划分多个子任务,方便维护和排错。
2. **重用作业**:将通用的数据集成作业抽取为组件,以便在不同的作业中重复使用,提高代码重用率。
3. **合理配置日志**:及时记录作业的日志信息,方便排查错误和监控作业执行状态。
4. **定期清理历史数据**:及时清理历史数据,避免数据量过大影响作业性能。
#### 6.2 提高数据集成效率的技巧
在处理大数据量或复杂数据集成任务时,提高效率尤为重要。以下是一些提高数据集成效率的技巧:
1. **并行处理数据**:在Talend Studio中可以配置并行度,提高数据处理速度。
2. **使用索引**:对数据源进行索引优化,加快数据访问速度。
3. **避免数据冗余**:在数据清洗阶段要及时删除冗余数据,避免数据量过大。
4. **合理使用缓存**:适当使用缓存存储中间结果,减少数据源读取次数。
#### 6.3 进阶话题:使用Talend集成大数据或实时流数据
除了传统的数据集成场景外,Talend还支持集成大数据和实时流数据处理。进阶用户可以学习如何使用Talend Studio进行大数据集成和实时流数据处理,拓展数据集成的应用范围。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏以"Talend数据集成"为主题,旨在为读者提供全面的指导和技术支持。从入门到进阶,包括Talend Studio的基本操作、数据集成的基本概念和常用术语、数据连接的建立与管理、数据加工与转换技巧、各类数据源的集成等内容,涵盖了数据集成任务的监控、性能优化、高级模式与实时处理等方面。此外,专栏还介绍了如何与大数据平台集成、版本管理、数据质量分析与清洗、ETL技术深入解析等内容。同时,专栏还探讨了数据集成与云平台的集成与应用,为读者展示数据集成领域的最新趋势和技术应用。无论您是初学者还是经验丰富的数据工程师,这里都将为您提供有益的指导和实践经验。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】python远程工具包paramiko使用
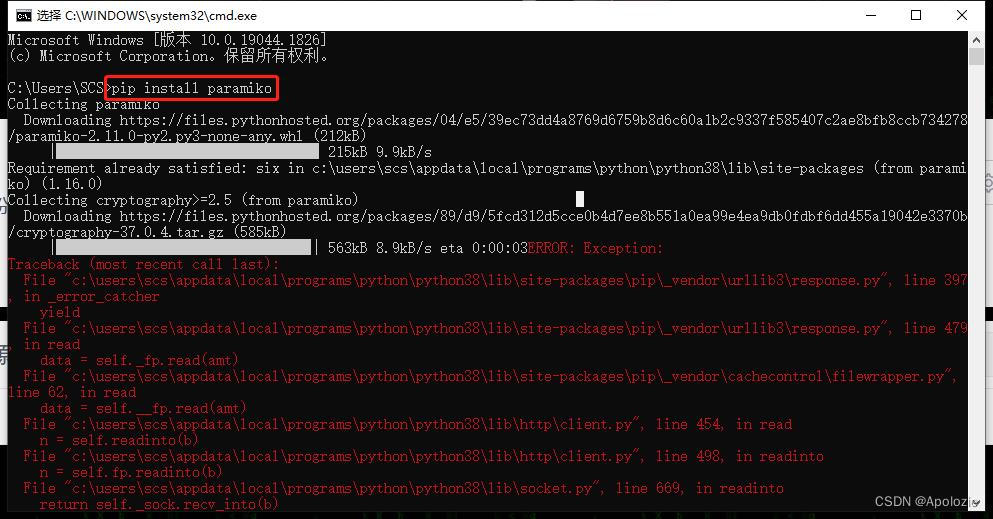
# 1. Python远程工具包Paramiko简介**
Paramiko是一个用于Python的SSH2协议的库,它提供了对远程服务器的连接、命令执行和文件传输等功能。Paramiko可以广泛应用于自动化任务、系统管理和网络安全等领域。
# 2. Paramiko基础
### 2.1 Paramiko的安装和配置
**安装 Paramiko**
```python
pip install
【实战演练】通过强化学习优化能源管理系统实战
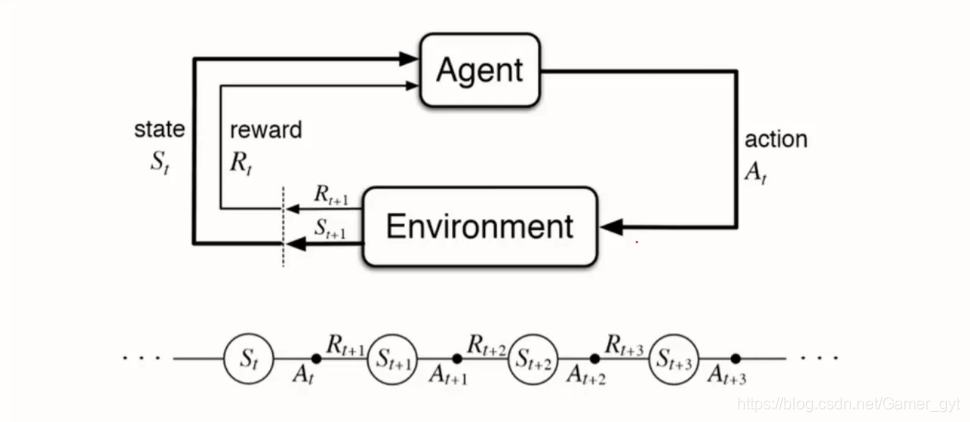
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【基础】简单GUI编程:使用Tkinter
# 1. Tkinter GUI编程简介**
Tkinter 是 Python 中一个跨平台的 GUI 库,它允许开发人员使用 Python 脚本创建图形用户界面 (GUI)。Tkinter 依赖于 Tk 核心库,它是一个 C 语言编写的跨平台窗口系统。
Tkinter 提供了一组丰富的控件,如按钮、标签、文本框和框架,用于构建 GUI。这些控件可以组合和排列,以创建复杂的和用户友好的界面。Tkinter 还支持
【实战演练】python云数据库部署:从选择到实施
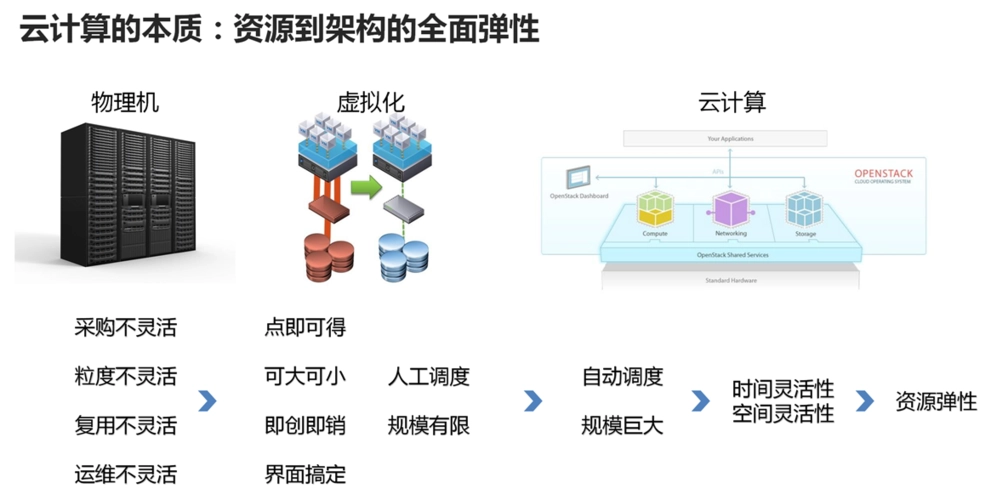
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】使用Docker与Kubernetes进行容器化管理
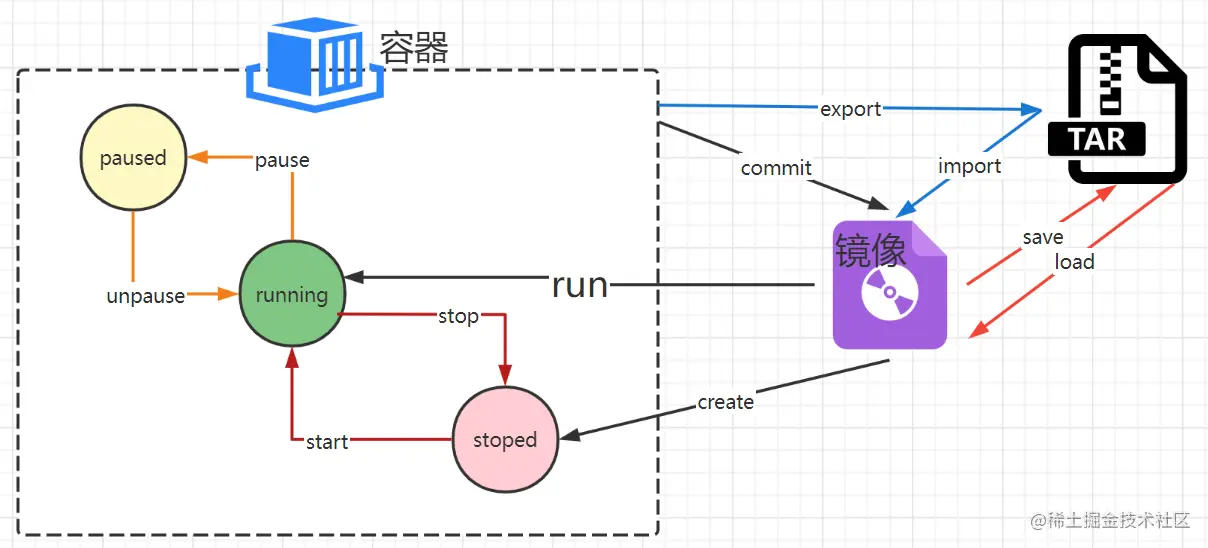
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )