Pygments进阶指南:专家级代码高亮与输出格式定制
发布时间: 2024-10-08 13:22:45 阅读量: 37 订阅数: 28 

YOLO算法-城市电杆数据集-496张图像带标签-电杆.zip
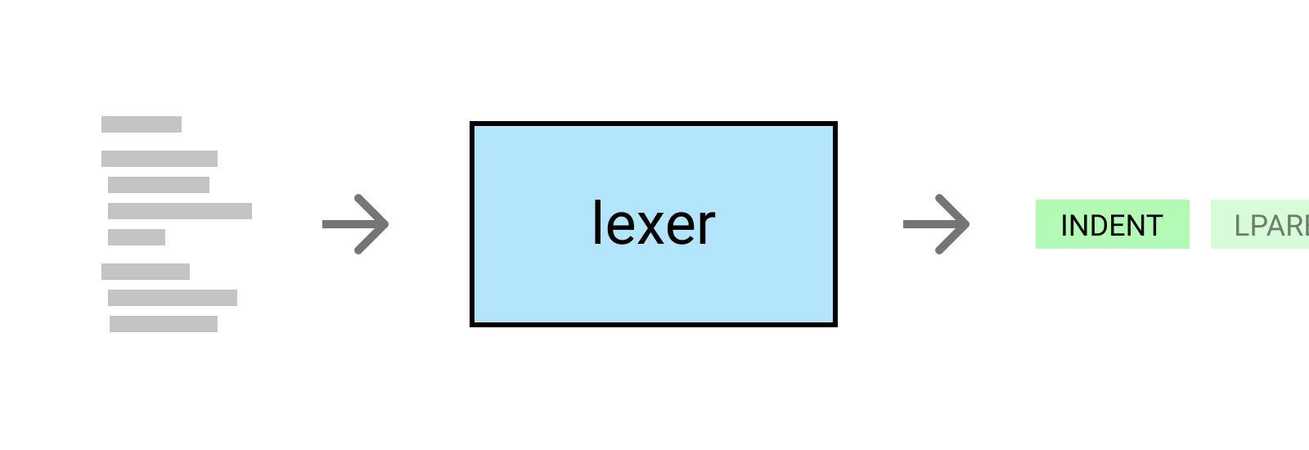
# 1. Pygments简介及安装配置
Python语言由于其清晰的语法和强大的社区支持,已经成为编程世界的重要组成部分。Pygments是Python领域内一个广受欢迎的代码高亮库,它支持多种编程语言,并拥有丰富的插件生态系统。无论你是在制作技术文档、编写教程还是为用户提供代码示例,Pygments都能以清晰的格式展示代码片段,增强可读性。
在本章节中,我们将介绍Pygments的基本概念、安装方法和配置步骤,帮助你快速开始使用这个强大的工具。首先,我们会对Pygments进行一个概览,解释它的作用和重要性。接着,我们将讨论如何在不同环境下安装Pygments,并提供基本的配置方法,确保你能顺利运行自己的第一个代码高亮示例。
## 安装Pygments
安装Pygments最简单的方法是使用Python的包管理工具`pip`。打开终端或命令提示符,并运行以下命令:
```sh
pip install Pygments
```
这段命令会下载并安装Pygments以及其依赖,安装完成后,你可以通过Python的交互式解释器导入Pygments来检查安装是否成功:
```python
import pygments
```
如果没有错误信息显示,那么Pygments已经正确安装在你的环境中了。至此,你已经具备了使用Pygments的基础,接下来的章节将深入介绍其核心组件和高级特性。
# 2. Pygments的核心组件与工作原理
Pygments作为一款功能强大的语法高亮工具,其核心组件包括词法分析器(Lexer)、格式化器(Formatter)以及过滤器(Filter)。这些组件协同工作,将代码文本转换为带有语法高亮的文本输出。深入理解这些组件及其工作原理,对于定制和优化代码高亮输出至关重要。
### 2.1 词法分析器(Lexer)深入理解
词法分析器(Lexer)是Pygments中负责将代码文本分解为有意义的代码单元(tokens)的部分。这些代码单元是语法分析的基础,决定了如何对代码文本进行高亮显示。
#### 2.1.1 词法分析器的类型和选择
Pygments为多种编程语言提供了内置的词法分析器。根据语言的不同,lexer的类型也各不相同。例如,Python源代码使用`PythonLexer`,而HTML文档则使用`HTMLLexer`。对于一些不常见的或者新出现的编程语言,Pygments允许用户选择通用的词法分析器,例如`TextLexer`,这可以作为一种临时方案。
在选择词法分析器时,应根据实际需要的精确度和代码的特定语言特性来决定。对于精确高亮和特定语言特性要求较高的场景,最好使用特定的lexer。
```python
from pygments import lexers
from pygments.lexers.special import TextLexer
# 选择lexer
lexer = lexers.get_lexer_by_name('python')
# 或者对于未知语言可以使用
lexer = TextLexer()
```
#### 2.1.2 自定义词法分析器的实践
在某些特殊场景下,Pygments自带的词法分析器可能无法满足需求。这时,可以编写自定义的词法分析器。通过继承`RegexLexer`类,并定义相应的模式,可以创建特定的lexer。以下是自定义一个简单词法分析器的示例代码:
```python
from pygments.lexer import RegexLexer
from pygments.token import Text, Comment, Operator
class SimpleLexer(RegexLexer):
name = 'SimpleLexer'
aliases = ['simple']
filenames = ['*.simple']
tokens = {
'root': [
(r'\s+', Text),
(r'//.*?$', Comment.Single),
(r'[^/\s]+', Operator),
(r'/[*](.|\n)*?[*]/', Comment.Multi),
(r'[+*/]', Operator),
],
}
# 使用自定义词法分析器
simple_lexer = SimpleLexer()
```
上述代码定义了一个简单的lexer,它可以识别简单的注释和运算符。当然,实际开发中自定义lexer会更加复杂,以满足特定语言的语法高亮需求。
### 2.2 格式化器(Formatter)与样式(Style)
格式化器(Formatter)和样式(Style)是Pygments中负责控制输出格式和高亮样式的部分。它们定义了如何将解析后的tokens渲染成具有特定颜色和格式的文本。
#### 2.2.1 格式化器的种类和功能
Pygments提供了多种格式化器,包括HTML、RTF、LaTeX、ANSI等。每种格式化器都具备不同的输出格式和功能特性,用户可以根据自己的需求选择合适的格式化器。
- **HTML格式化器**:支持输出为带有内联CSS的HTML,也可以输出为使用外部CSS样式表的HTML。
- **RTF格式化器**:用于生成RTF格式的文档。
- **LaTeX格式化器**:生成可以用于LaTeX文档的代码高亮。
- **ANSI格式化器**:用于在终端中以ANSI颜色代码的形式输出高亮文本。
```python
from pygments.formatters import HtmlFormatter
# HTML格式化器示例
html_formatter = HtmlFormatter(full=True, style='monokai', noclasses=False)
```
#### 2.2.2 样式定义及样式的个性化修改
样式(Style)定义了代码高亮的视觉表现。Pygments内建多种样式,也可以通过定义新的样式类来定制高亮的颜色和字体风格。以下是一个自定义样式的示例:
```python
from pygments.style import Style
from pygments.token import Token
class CustomStyle(Style):
default_style = ''
styles = {
Token: 'bg:#ffffff #000000',
***ment: 'italic:#808080',
***ment.Hashbang: 'bold:#800000',
Token.Operator: '#000000',
Token.Operator.Word: 'bold:#000000',
Token.Punctuation: 'bold:#000000',
Token.Name: 'bold:#000000',
Token.Name.Attribute: '#000000',
Token.Name.Tag: 'bold:#000000',
Token.Literal: 'bg:#f0f0f0 #000000',
Token.String: 'bg:#f0f0f0 #000000',
}
# 应用自定义样式
style = CustomStyle()
```
用户可以通过继承`Style`类并定义自己的样式类来创建独特的代码高亮风格。上面的样式示例定义了一个简洁的黑色和白色主题,所有的注释文本都设为灰色。
### 2.3 过滤器(Filter)的使用与开发
过滤器(Filter)是Pygments中用于在词法分析和格式化阶段之后进一步处理输出的组件。通过使用过滤器,可以实现代码高亮的进一步定制。
#### 2.3.1 内置过滤器的功能和用法
Pygments内置了多种过滤器,例如去除空行的`HStripFilter`、去除行首空格的`HLStripFilter`,以及将`<br>`标签转换为换行符的`LineToBlockFilter`等。这些过滤器可以直接用于格式化后的输出,以便进行额外的处理。
```python
from pygments.filters import HStripFilter
from pygments.formatters import TerminalTrueColorFormatter
# 使用HStripFilter过滤器去除每行的开头空格
filtered_html_formatter = TerminalTrueColorFormatter(full=True, filters=[HStripFilter])
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库 Pygments 中的 pygments.formatters 模块,提供了全面的指南,涵盖了代码高亮的各个方面。从基础概念到高级技术,本专栏深入剖析了 Pygments 的内部机制,提供了实用技巧和最佳实践。通过深入的分析和示例,读者将了解格式化器机制、编程语言兼容性、性能优化、安全隐患和扩展机制。本专栏旨在帮助开发者掌握 Pygments 库,创建个性化的高亮样式,并将其应用于各种场景,包括 Web 开发、自动化脚本、交互式环境和代码静态分析。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Masm32基础语法精讲:构建汇编语言编程的坚实地基

# 摘要
本文详细介绍了Masm32汇编语言的基础知识和高级应用。首先概览了Masm32汇编语言的基本概念,随后深入讲解了其基本指令集,包括数据定义、算术与逻辑操作以及控制流指令。第三章探讨了内存管理及高级指令,重点描述了寄存器使用、宏指令和字符串处理等技术。接着,文章转向模块化编程,涵盖了模块化设计原理、程序构建调
TLS 1.2深度剖析:网络安全专家必备的协议原理与优势解读
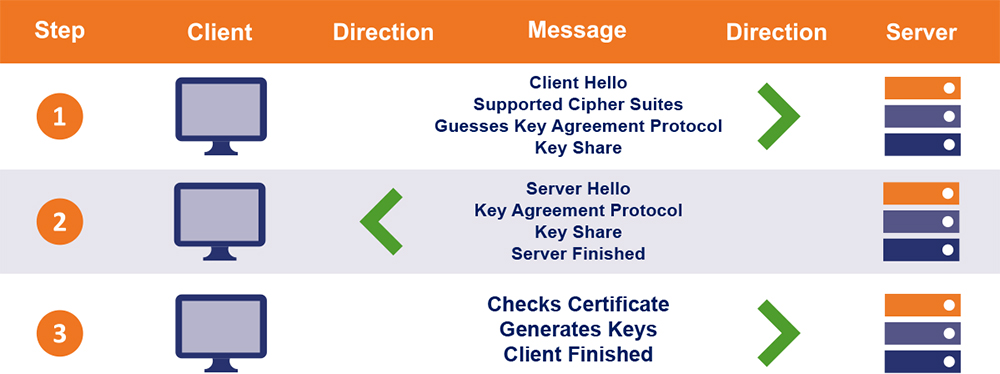
# 摘要
传输层安全性协议(TLS)1.2是互联网安全通信的关键技术,提供数据加密、身份验证和信息完整性保护。本文从TLS 1.2协议概述入手,详细介绍了其核心组件,包括密码套件的运作、证书和身份验证机制、以及TLS握手协议。文章进一步阐述了TLS 1.2的安全优势、性能优化策略以及在不同应用场景中的最佳实践。同时,本文还分析了TLS 1.2所面临的挑战和安全漏
案例分析:TIR透镜设计常见问题的即刻解决方案

# 摘要
TIR透镜设计是光学技术中的一个重要分支,其设计质量直接影响到最终产品的性能和应用效果。本文首先介绍了TIR透镜设计的基础理论,包括光学全内反射原理和TIR透镜设计的关键参数,并指出了设计过程中的常见误区。接着,文章结合设计实践,分析了设计软件的选择和应用、实际案例的参数分析及设计优化,并总结了实验验证的过程与结果。文章最后探讨了TIR透镜设计的问题预防与管理策
ZPL II高级应用揭秘:实现条件打印和数据库驱动打印的实用技巧
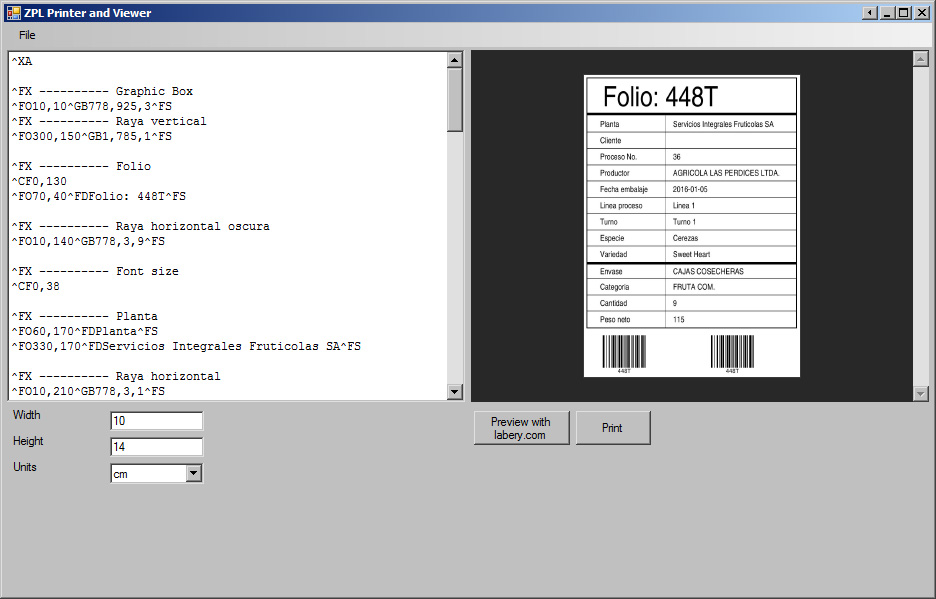
# 摘要
本文对ZPL II打印技术进行了全面的介绍,包括其基本概念、条件打印技术、数据库驱动打印的实现与高级应用、打印性能优化以及错误处理与故障排除。重点分析了条件打印技术在不同行业中的实际应用案例,并探讨了ZPL II技术在行业特定解决方案中的创新应用。同时,本文还深入讨论了自动化打印作业的设置与管理以及ZPL II打印技术的未来发展趋势,为打印技术的集成和业
泛微E9流程设计高级技巧:打造高效流程模板
# 摘要
本文系统介绍了泛微E9在流程设计方面的关键概念、基础构建、实践技巧、案例分析以及未来趋势。首先概述了流程模板设计的基础知识,包括其基本组成和逻辑构建,并讨论了权限配置的重要性和策略。随后,针对提升流程设计的效率与效果,详细阐述了优化流程设计的策略、实现流程自动化的方法以及评估与监控流程效率的技巧。第四章通过高级流程模板设计案例分析,分享了成功经验与启示。最后,展望了流程自动化与智能化的融合
约束管理101:掌握基础知识,精通高级工具

# 摘要
本文系统地探讨了约束管理的基础概念、理论框架、工具与技术,以及在实际项目中的应用和未来发展趋势。首先界定了约束管理的定义、重要性、目标和影响,随后分类阐述了不同类型的约束及其特性。文中还介绍了经典的约束理论(TOC)与现代技术应用,并提供了约束管理软件工具的选择与评估。本文对约束分析技术进行了详细描述,并提出风险评估与缓解策略。在实践应用方面,分析了项目生
提升控制效率:PLC电动机启动策略的12项分析
# 摘要
本论文全面探讨了PLC电动机启动策略的理论与实践,涵盖了从基本控制策略到高级控制策略的各个方面。重点分析了直接启动、星-三角启动、软启动、变频启动、动态制动和智能控制策略的理论基础与应用案例。通过对比不同启动策略的成本效益和环境适应性,本文探讨了策略选择时应考虑的因素,如负载特性、安全性和可靠性,并通过实证研究验证了启动策略对能效的
JBoss负载均衡与水平扩展:确保应用性能的秘诀

# 摘要
本文全面探讨了JBoss应用服务器的负载均衡和水平扩展技术及其高级应用。首先,介绍了负载均衡的基础理论和实践,包括其基本概念、算法与技术选择标准,以及在JBoss中的具体配置方法。接着,深入分析了水平扩展的原理、关键技术及其在容器化技术和混合云环境下的部署策略。随后,文章探讨了JBoss在负载均衡和水平扩展方面的高可用性、性能监控与调优、安全性与扩展性的考量。最后,通过行业案例分析,提供了实际应
【数据采集无压力】:组态王命令语言让实时数据处理更高效
# 摘要
本文全面探讨了组态王命令语言在数据采集中的应用及其理论基础。首先概述了组态王命令语言的基本概念,随后深入分析了数据采集的重要性,并探讨了组态王命令语言的工作机制与实时数据处理的关系。文章进一步细化到数据采集点的配置、数据流的监控技术以及数据处理策略,以实现高效的数据采集。在实践应用章节中,详细讨论了基于组态王命令语言的数据采集实现,以及在特定应用如能耗管理和设备监控中的应用实例。此外,本文还涉及性能优化和
【OMP算法:实战代码构建指南】:打造高效算法原型

# 摘要
正交匹配追踪(OMP)算法是一种高效的稀疏信号处理方法,在压缩感知和信号处理领域得到了广泛应用。本文首先对OMP算法进行概述,阐述其理论基础和数学原理。接着,深入探讨了OMP算法的实现逻辑、性能分析以及评价指标,重点关注其编码实践和性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )