异步消息队列与事件驱动架构
发布时间: 2024-01-09 17:44:12 阅读量: 44 订阅数: 41 

事件驱动的异步Socket
# 1. 异步消息队列的概念和作用
## 1.1 异步消息队列的定义
异步消息队列是一种用于解耦和异步处理消息的中间件。它允许发送方(生产者)将消息发送到队列中,而不必直接等待接收方(消费者)处理。生产者和消费者可以独立于彼此运行,并通过消息队列进行通信。
## 1.2 异步消息队列的使用场景
异步消息队列在许多应用程序中都有广泛的应用,特别是在分布式系统和高并发场景中。以下是一些常见的使用场景:
- 异步任务处理:将耗时的任务放入消息队列,由消费者进行处理,可以提高系统的响应速度和并发处理能力。
- 解耦系统组件:通过消息队列,不同的系统组件可以通过发送和接收消息来进行解耦,减少了不同组件之间的依赖性。
- 流量控制和削峰填谷:在高并发场景下,通过将请求放入消息队列,可以控制系统的处理速度,避免系统过载,实现削峰填谷的效果。
- 日志处理:将日志消息放入队列,由消费者进行处理和存储,可以实现日志的异步处理,提高系统的性能。
## 1.3 异步消息队列的优势
使用异步消息队列有以下几个优势:
- 提高系统的可靠性:在消息队列中,即使消费者不可用,生产者仍然可以将消息发送到队列中,待消费者可用时进行处理,降低了因消费者故障导致消息丢失的风险。
- 支持系统的扩展性:通过引入消息队列,可以将消息的生产和消费过程解耦,使分布式系统更容易扩展和维护。
- 实现异步处理:生产者无需等待消费者的处理结果,可以持续发送消息,提高系统的并发处理能力和响应速度。
- 实现流量控制和削峰填谷:通过消息队列,可以控制系统的处理速度,避免系统过载,提高系统的稳定性和性能。
通过以上章节内容,读者可以了解异步消息队列的概念、使用场景和优势。在后续章节中,我们将介绍常见的异步消息队列技术、核心概念和架构设计,以及它们与事件驱动架构的关系。
# 2. 常见的异步消息队列技术
在实际应用中,有很多种异步消息队列技术可供选择。下面将介绍几种常见的异步消息队列技术。
### 2.1 RabbitMQ
RabbitMQ 是一个使用 Erlang 语言编写的开源消息代理软件,它实现了高性能、可扩展的AMQP(高级消息队列协议)标准。以下是使用 RabbitMQ 的示例代码:
```python
import pika
# 连接到 RabbitMQ 服务器
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 创建消息队列
channel.queue_declare(queue='hello')
# 发布消息
channel.basic_publish(exchange='', routing_key='hello', body='Hello, RabbitMQ!')
# 关闭连接
connection.close()
```
代码解析:
- `pika` 是 RabbitMQ 的 Python 客户端库,需要先安装。
- `connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))` 用于建立与 RabbitMQ 服务器的连接。
- `channel = connection.channel()` 在连接上创建一个通道。
- `channel.queue_declare(queue='hello')` 创建一个名为 "hello" 的消息队列。
- `channel.basic_publish(exchange='', routing_key='hello', body='Hello, RabbitMQ!')` 发布一条消息到名为 "hello" 的消息队列。
- `connection.close()` 关闭与 RabbitMQ 服务器的连接。
### 2.2 Apache Kafka
Apache Kafka 是一个高吞吐量、可持久化、分布式的发布订阅消息系统。它将消息以日志的形式存储,并提供高效的读写机制。以下是使用 Apache Kafka 的示例代码:
```java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
String bootstrapServers = "localhost:9092";
String topic = "my_topic";
Properties props = new Properties();
props.put("bootstrap.servers", bootstrapServers);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>(topic, "Hello, Kafka!"));
producer.close();
}
}
```
代码解析:
- 首先需要引入 Kafka 的 Java 客户

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏名为《python异步编程详解》,旨在深入探讨Python中的异步编程技术。文章内容包括理解异步编程基础、使用协程提升程序性能、深入了解asyncio库与事件循环、任务调度与并发控制、实现异步编程中的回调机制、异步IO操作与文件处理技巧、使用异步网络编程提升通信性能、异常和错误处理、异步计算模式与多进程协作、共享资源管理、线程和进程池的使用、处理HTTP请求与响应、异步消息队列与事件驱动架构、大规模并发爬虫、优化数据库访问、数据缓存的最佳实践、机器学习应用、微服务架构中的异步通信,以及构建实时数据处理系统。通过本专栏,读者将全面了解Python中的异步编程技术,并能运用于各种应用场景中,提升程序性能和效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电力电子技术基础:7个核心概念与原理让你快速入门
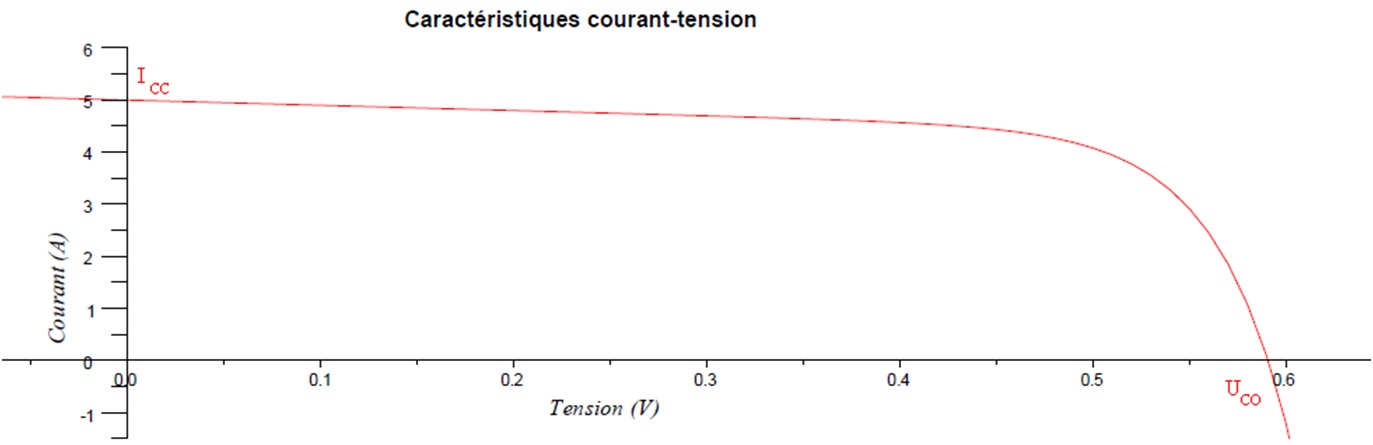
# 摘要
电力电子技术作为电力系统与电子技术相结合的交叉学科,对于现代电力系统的发展起着至关重要的作用。本文首先对电力电子技术进行概述,并深入解析其核心概念,包括电力电子变换器的分类、电力半导体器件的特点、控制策略及调制技术。进一步,本文探讨了电路理论基础、功率电子变换原理以及热管理与散热设计等基础理论与数学模型。文章接
PDF格式全面剖析:内部结构深度解读与高级操作技巧

# 摘要
PDF格式因其跨平台性和保持文档原貌的优势,在数字出版、办公自动化、法律和医疗等多个行业中得到广泛应用。本文首先概述了PDF格式的基本概念及其内部结构,包括文档组成元素、文件头、交叉引用表和PDF语法。随后,文章深入探讨了进行PDF文档高级操作的技巧,如编辑内容、处理表单、交互功能以及文档安全性的增强方法。接着,
【施乐打印机MIB效率提升秘籍】:优化技巧助你实现打印效能飞跃

# 摘要
施乐打印机中的管理信息库(MIB)是提升打印设备性能的关键技术,本文对MIB的基础知识进行了介绍,并理论分析了其效率。通过对MIB的工作原理和与打印机性能关系的探讨,以及效率提升的理论基础研究,如响应时间和吞吐量的计算模型,本文提供了优化打印机MIB的实用技巧,包括硬件升级、软件和固件调
FANUC机器人编程新手指南:掌握编程基础的7个技巧

# 摘要
本文提供了FANUC机器人编程的全面概览,涵盖从基础操作到高级编程技巧,以及工业自动化集成的综合应用。文章首先介绍了FANUC机器人的控制系统、用户界面和基本编程概念。随后,深入探讨了运动控制、I/O操作
【移远EC200D-CN固件升级速通】:按图索骥,轻松搞定固件更新

# 摘要
本文全面概述了移远EC200D-CN固件升级的过程,包括前期的准备工作、实际操作步骤、升级后的优化与维护以及案例研究和技巧分享。文章首先强调了进行硬件与系统兼容性检查、搭建正确的软件环境、备份现有固件与数据的重要性。其次,详细介绍了固件升级工具的使用、升级过程监控以及升级后的验证和测试流程。在固件升级后的章节中,本文探讨了系统性能优化和日常维护的策略,并分享了用户反馈和升级技巧。
【二次开发策略】:拉伸参数在tc itch中的应用,构建高效开发环境的秘诀

# 摘要
本文旨在详细阐述二次开发策略和拉伸参数理论,并探讨tc itch环境搭建和优化。首先,概述了二次开发的策略,强调拉伸参数在其中的重要作用。接着,详细分析了拉伸参数的定义、重要性以及在tc itch环境中的应用原理和设计原则。第三部分专注于tc itch环境搭建,从基本步骤到高效开发环境构建,再到性能调
CANopen同步模式实战:精确运动控制的秘籍
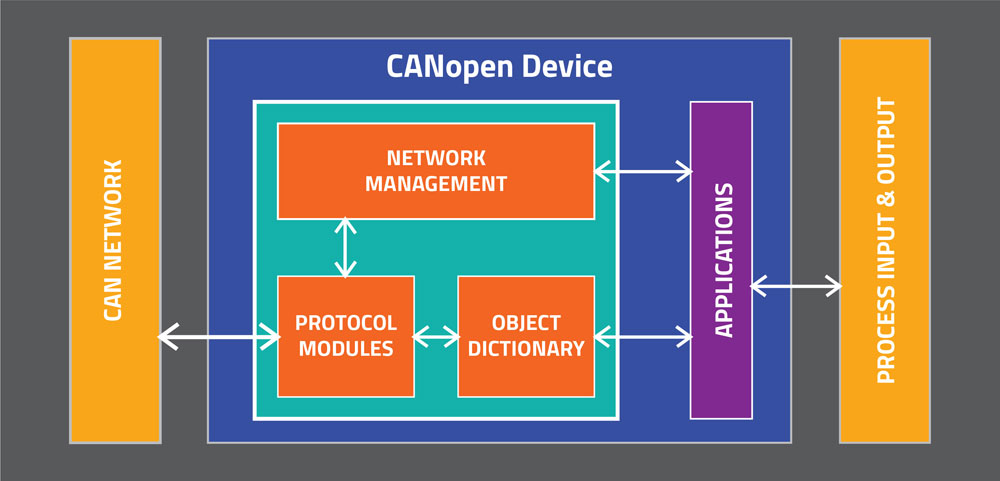
# 摘要
CANopen是一种广泛应用在自动化网络通信中的协议,其中同步模式作为其重要特性,尤其在对时间敏感的应用场景中扮演着关键角色。本文首先介绍了CANopen同步模式的基础知识,然后详细分析了同步机制的关键组成部分,包括同步消息(SYNC)的原理、同步窗口(SYNC Window)的配置以及同步计数器(SYNC Counter)的管理。文章接着
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )