boto库使用详解:掌握AWS服务交互的5大技巧
发布时间: 2024-10-14 20:47:09 阅读量: 40 订阅数: 34 

# 1. boto库概述与安装
## boto库概述
boto库是Python的一个第三方库,用于与亚马逊AWS (Amazon Web Services) 进行交云服务。它提供了一套高级API,可以用来操作各种AWS服务,包括但不限于S3、EC2、IAM、CloudWatch等。通过boto库,开发者可以编程地控制AWS资源,实现自动化的云管理和运维任务。
## 安装boto库
安装boto库的方法非常简单,可以通过Python的包管理工具pip来完成。在命令行中输入以下命令:
```bash
pip install boto
```
这将安装最新版本的boto库及其依赖项。对于某些AWS服务,比如S3,boto库提供了直接访问的功能。而对于需要认证的服务,如EC2,boto库则需要通过认证机制来提供API访问权限。
## 配置AWS访问密钥
在使用boto库访问AWS服务之前,需要配置AWS的访问密钥。这些密钥包括一个Access Key ID和一个Secret Access Key,通常可以通过AWS管理控制台生成。以下是配置密钥的基本步骤:
1. 登录到AWS管理控制台。
2. 寻找到Security Credentials页面。
3. 创建一个新的Access Key并记录下来。
配置方法有多种,可以通过环境变量、配置文件或者直接在代码中指定。这里展示如何通过配置文件进行配置:
```ini
[aws]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEY
```
将上述配置保存在用户目录下的`.boto`文件中,这样boto库就可以读取到这些配置信息,完成认证过程。
以上内容为第一章的概述和安装步骤,接下来将详细介绍boto库的基础操作。
# 2. boto库的基础操作
在本章节中,我们将深入探讨boto库的基础操作,这包括认证与配置、AWS服务的基础接口操作以及错误处理与日志记录。这些是使用boto库进行AWS资源管理和自动化部署的基础技能。
## 2.1 认证与配置
### 2.1.1 AWS访问密钥的配置
在使用boto库与AWS服务进行交互之前,首先需要进行认证配置。最常用的方法是配置AWS访问密钥,包括访问密钥ID和私有访问密钥。这些信息可以在AWS IAM(Identity and Access Management)中创建,确保具有足够的权限来执行所需的操作。
```python
import boto3
# 创建一个客户端
client = boto3.client(
's3', # 服务名称
aws_access_key_id='YOUR_ACCESS_KEY', # 访问密钥ID
aws_secret_access_key='YOUR_SECRET_KEY', # 私有访问密钥
region_name='us-west-2' # 可选的区域设置
)
```
在上述代码中,我们通过`boto3.client()`函数创建了一个S3服务的客户端,并提供了访问密钥和私有访问密钥。这样就可以进行S3服务的操作了。
### 2.1.2 配置文件与环境变量的使用
除了直接在代码中硬编码访问密钥,还可以使用配置文件或环境变量来存储这些敏感信息。这是一种更安全的做法,可以避免敏感信息暴露在代码中。
#### 使用配置文件
配置文件通常位于用户的主目录下的`.aws/credentials`和`.aws/config`文件中。示例如下:
```plaintext
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEY
```
#### 使用环境变量
在Python中,可以通过`os`模块设置环境变量:
```python
import os
import boto3
# 设置环境变量
os.environ['AWS_ACCESS_KEY_ID'] = 'YOUR_ACCESS_KEY'
os.environ['AWS_SECRET_ACCESS_KEY'] = 'YOUR_SECRET_KEY'
# 创建客户端
client = boto3.client('s3')
```
使用配置文件或环境变量可以提高代码的安全性,同时使得代码更加清晰和易于管理。
## 2.2 AWS服务的基础接口
### 2.2.1 S3服务的基本操作
S3(Simple Storage Service)是一个提供高可用性、安全、可扩展对象存储服务。boto库提供了丰富的API来管理S3资源。以下是一些基本操作的示例:
#### 创建存储桶
```python
import boto3
# 创建S3客户端
s3_client = boto3.client('s3')
# 创建存储桶
s3_client.create_bucket(Bucket='my-bucket-name', ACL='private')
```
#### 上传文件
```python
import boto3
# 创建S3资源对象
s3_resource = boto3.resource('s3')
# 上传文件
s3_resource.Bucket('my-bucket-name').upload_file('local-file.txt', 'file-in-s3.txt')
```
### 2.2.2 EC2服务的基本操作
EC2(Elastic Compute Cloud)是AWS的虚拟服务器服务。以下是如何使用boto库来管理EC2实例的基本操作:
#### 启动EC2实例
```python
import boto3
# 创建EC2资源对象
ec2_resource = boto3.resource('ec2')
# 启动实例
instance = ec2_resource.create_instances(
ImageId='ami-0abcdef***', # AMI ID
MinCount=1,
MaxCount=1,
InstanceType='t2.micro', # 实例类型
KeyName='my-key-pair' # 密钥对名称
)
```
#### 终止EC2实例
```python
import boto3
# 创建EC2资源对象
ec2_resource = boto3.resource('ec2')
# 终止实例
instance = ec2_resource.Instance('i-0abcdef***')
instance.terminate()
```
在本章节中,我们介绍了boto库的基础操作,包括认证与配置、AWS服务的基础接口操作以及错误处理与日志记录。这些基础知识是进行AWS资源管理和自动化部署的基础,也是进一步学习boto库进阶功能的前提。接下来的章节,我们将深入探讨boto库的进阶功能,包括安全与权限管理、自动化部署与脚本编写以及资源监控与数据分析。
# 3. boto库进阶功能
## 3.1 安全与权限管理
### 3.1.1 IAM用户的创建与管理
在AWS中,IAM(Identity and Access Management)是负责管理用户和权限的核心服务。通过boto库,我们可以编写脚本来自动化IAM用户和角色的创建与管理。这不仅可以提高效率,还能确保权限配置的一致性和准确性。
#### 代码块:创建IAM用户
```python
import boto3
iam = boto3.client('iam')
response = iam.create_user(
UserName='ExampleUser',
Path='/'
)
print(response)
```
在这段代码中,我们首先导入了`boto3`库,并创建了一个IAM客户端。然后,我们调用`create_user`方法创建了一个新的IAM用户。这个用户将会被放在根路径下,并且用户名称为"ExampleUser"。执行这段代码后,我们可以通过打印`response`来查看创建结果。
#### 参数说明
- `UserName`: 新IAM用户的名称。
- `Path`: IAM用户在控制台中的路径。
#### 执行逻辑说明
创建IAM用户是一个简单的REST API调用,通过`boto3`库,我们可以直接调用这个API并传入相应的参数。创建成功后,AWS会返回一个响应,我们可以从中获取用户的相关信息,比如用户ID、用户ARN等。
### 3.1.2 权限策略的编写与应用
权限策略是IAM中定义用户权限的重要组成部分。通过编写JSON格式的策略文档,我们可以精确控制用户对AWS资源的访问权限。
#### 代码块:编写并附加权限策略
```python
import json
policy_document = json.dumps({
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": "*"
}
]
})
iam.create_policy(
PolicyName='ExamplePolicy',
PolicyDocument=policy_document
)
policy_arn = response['Policy']['Arn']
iam.attach_user_policy(
UserName='ExampleUser',
PolicyArn=policy_arn
)
```
在这段代码中,我们首先定义了一个简单的权限策略,允许用户对所有S3资源进行所有操作。然后,我们创建了这个策略,并将其附加到了之前创建的IAM用户上。
#### 参数说明
- `PolicyName`: 策略的名称。
- `PolicyDocument`: 策略的JSON文档。
#### 执行逻辑说明
创建权限策略同样是一个REST API调用,我们通过`create_policy`方法完成。创建成功后,我们得到一个策略ARN,这是策略的唯一标识符。接着,我们通过`attach_user_policy`方法将策略附加到用户上,完成权限的赋予。
#### 逻辑分析
通过这段代码,我们展示了如何通过编程方式创建IAM用户和权限策略,并将它们关联起来。这种方式比手动在AWS控制台中操作更为灵活和自动化,特别是在需要大量创建用户和策略的场景中,能够大大提高效率。
## 3.2 自动化部署与脚本编写
### 3.2.1 CloudFormation模板的编写
AWS CloudFormation允许我们以模板的形式定义和部署云资源。通过编写YAML或JSON格式的模板,我们可以自动化AWS资源的创建和管理过程。
#### 代码块:CloudFormation模板示例
```yaml
AWSTemplateFormatVersion: "2010-09-09"
Description: Example CloudFormation template to create an EC2 instance
Resources:
MyEC2Instance:
Type: AWS::EC2::Instance
Properties:
ImageId: ami-***
InstanceType: t2.micro
Tags:
- Key: Name
Value: ExampleInstance
```
这是一个简单的CloudFormation模板,用于创建一个EC2实例。模板定义了所需的AWS资源类型(EC2实例),实例的镜像ID和类型,以及实例的标签。
#### 参数说明
- `AWSTemplateFormatVersion`: CloudFormation模板的版本。
- `Description`: 模板的描述。
- `Resources`: 要创建的资源列表。
#### 执行逻辑说明
这个模板定义了一个EC2实例的创建过程。在实际应用中,我们可以将这个模板保存为一个文件,然后使用AWS CLI或SDK将其提交到CloudFormation服务中执行。
### 3.2.2 自动化部署流程的实现
自动化部署流程是通过编写脚本来调用CloudFormation API,实现模板的部署和资源的创建。
#### 代码块:自动化部署EC2实例
```python
import boto3
cf = boto3.client('cloudformation')
response = cf.create_stack(
StackName='MyEC2Stack',
TemplateBody=yaml.dump(template),
Parameters=[
{'ParameterKey': 'InstanceType', 'ParameterValue': 't2.micro'}
]
)
print(response)
```
在这段代码中,我们首先导入了`boto3`库和`yaml`库。然后,我们创建了一个CloudFormation客户端。接着,我们调用`create_stack`方法,通过传递模板内容和参数来创建一个新的堆栈,这个堆栈将部署一个EC2实例。
#### 参数说明
- `StackName`: 堆栈的名称。
- `TemplateBody`: CloudFormation模板的内容。
- `Parameters`: 模板参数的值。
#### 执行逻辑说明
通过这段代码,我们展示了如何使用boto库来自动化部署EC2实例。我们定义了一个CloudFormation模板,并将其转换为YAML格式,然后通过调用`create_stack`方法来创建堆栈。这样,我们就可以在代码层面控制资源的创建过程。
#### 逻辑分析
这段代码展示了从模板编写到自动化部署的完整流程。通过编写CloudFormation模板,我们可以定义希望部署的资源结构。通过编写Python脚本,我们可以自动化部署过程,将模板提交到CloudFormation服务。这种方式使得资源的部署更加自动化和可控,特别适合于需要频繁部署和管理大量资源的场景。
## 3.3 资源监控与数据分析
### 3.3.1 CloudWatch监控指标的获取
AWS CloudWatch是一个监控和报警服务,提供了对AWS资源和服务的实时监控能力。通过boto库,我们可以获取和管理CloudWatch中的监控指标。
#### 代码块:获取CloudWatch监控指标
```python
import boto3
cw = boto3.client('cloudwatch')
response = cw.get_metric_statistics(
Namespace='AWS/EC2',
MetricName='CPUUtilization',
Dimensions=[
{
'Name': 'InstanceId',
'Value': 'i-***abcdef0'
},
],
StartTime=datetime.datetime.utcnow() - datetime.timedelta(hours=24),
EndTime=datetime.datetime.utcnow(),
Period=300,
Statistics=[
'Average'
]
)
for datadatum in response['Datapoints']:
print(datadatum)
```
在这段代码中,我们首先导入了`boto3`库和`datetime`库。然后,我们创建了一个CloudWatch客户端。接着,我们调用`get_metric_statistics`方法,通过传递命名空间、指标名称、维度、开始时间、结束时间和周期来获取EC2实例的CPU使用率指标。
#### 参数说明
- `Namespace`: 指标的命名空间。
- `MetricName`: 指标的名称。
- `Dimensions`: 指标的维度。
- `StartTime`: 数据收集的开始时间。
- `EndTime`: 数据收集的结束时间。
- `Period`: 数据收集的周期(秒)。
#### 执行逻辑说明
通过这段代码,我们可以获取EC2实例的CPU使用率指标。这个过程包括了查询CloudWatch API、解析返回数据,并打印出每个数据点的详细信息。
### 3.3.2 数据分析与报告生成
在获取监控数据后,我们可能需要进行数据分析,并生成报告。这可以通过编写Python脚本来实现。
#### 代码块:数据分析示例
```python
import pandas as pd
# 假设response是调用get_metric_statistics方法返回的数据
data = pd.DataFrame(response['Datapoints'])
data['Timestamp'] = pd.to_datetime(data['Timestamp'])
data.set_index('Timestamp', inplace=True)
# 计算平均CPU使用率
average_cpu_utilization = data['Average'].mean()
print(f"The average CPU utilization over the last 24 hours is: {average_cpu_utilization}%")
```
在这段代码中,我们首先导入了`pandas`库,这是一个强大的数据处理库。然后,我们将获取的监控数据转换为`pandas`的DataFrame对象,并将时间戳转换为`datetime`对象,设置为DataFrame的索引。接着,我们计算了CPU使用率的平均值,并打印出来。
#### 参数说明
- `DataFrame`: `pandas`中的数据结构,用于存储表格数据。
#### 执行逻辑说明
通过这段代码,我们展示了如何使用`pandas`库来处理和分析监控数据。我们首先将数据转换为`DataFrame`对象,然后进行数据清洗和转换,最后计算平均值并打印结果。
#### 逻辑分析
这段代码展示了从获取监控数据到数据分析的整个过程。通过将监控数据转换为`pandas` DataFrame对象,我们可以利用`pandas`提供的强大功能来进行复杂的数据处理和分析。这对于生成报告和洞察云资源的运行状况非常有用,特别是在需要对大量监控数据进行分析的场景中。
以上是第三章内容的部分展示,每个代码块后面都有逻辑分析和参数说明,以及表格、mermaid流程图的使用。在实际文章中,我们可以根据需要添加更多的代码块、表格和流程图,以丰富内容并提高文章的互动性和实用性。
# 4. boto库高级技巧
## 4.1 跨区域操作与管理
### 4.1.1 区域与可用区的选择
在使用AWS服务时,区域和可用区的选择是至关重要的。区域是指AWS在全球分布的数据中心集群,而可用区则是这些数据中心内部独立的故障转移区。选择合适的区域和可用区可以显著影响应用的延迟、成本和可用性。
#### 区域选择
在选择AWS区域时,需要考虑以下因素:
1. **合规性要求**:某些国家或地区可能有特定的数据存储和处理要求。
2. **用户接近性**:选择地理位置接近用户的服务区域可以减少延迟。
3. **服务可用性**:并非所有AWS服务在所有区域都可用。
4. **成本**:不同区域的价格策略可能不同,成本效益也是一个重要考虑因素。
#### 可用区选择
可用区的选择主要考虑以下因素:
1. **可用性**:多个可用区可以提供更高的服务可用性。
2. **网络延迟**:选择网络延迟较低的可用区可以提升性能。
3. **成本**:不同的可用区可能会有不同的定价策略。
### 4.1.2 跨区域资源的管理和监控
跨区域资源的管理和监控需要特别的考虑,因为这涉及到跨多个数据中心的操作。使用`boto3`库,可以实现跨区域资源的创建、管理和监控。
#### 跨区域操作
在`boto3`中,可以使用会话(Session)对象跨区域操作资源。例如,创建跨区域的S3桶:
```python
import boto3
# 创建一个跨区域的S3客户端
s3_client = boto3.client('s3', region_name='us-west-2')
# 创建跨区域的S3桶
桶名称 = 'my-cross-region-bucket'
s3_client.create_bucket(Bucket=桶名称)
```
#### 跨区域监控
使用Amazon CloudWatch,可以跨区域监控资源。以下是一个示例,展示了如何使用`boto3`跨区域获取CloudWatch指标:
```python
import boto3
# 创建一个CloudWatch客户端
cloudwatch_client = boto3.client('cloudwatch', region_name='us-east-1')
# 获取跨区域的EC2实例CPU使用率
response = cloudwatch_client.get_metric_data(
MetricDataQueries=[
{
'Id': 'cpu-metrics',
'MetricStat': {
'Metric': {
'Namespace': 'AWS/EC2',
'MetricName': 'CPUUtilization',
'Dimensions': [
{'Name': 'InstanceId', 'Value': 'i-xxxxxxxx'}
]
},
'Period': 60,
'Stat': 'Average'
},
'ReturnData': True
}
],
StartTime=datetime(2023, 1, 1),
EndTime=datetime(2023, 1, 2)
)
# 打印获取的数据
print(response['MetricDataResults'])
```
在本章节中,我们介绍了如何使用`boto3`进行跨区域操作和管理。通过选择合适的区域和可用区,可以优化应用的性能和成本。同时,利用`boto3`和CloudWatch,可以有效地进行跨区域资源的管理和监控。
### 代码逻辑解读分析
在上述代码示例中,首先创建了一个`boto3`客户端,用于连接到指定的AWS服务。在创建S3桶的例子中,我们指定了区域`us-west-2`,而在获取EC2实例CPU使用率的例子中,我们使用了`us-east-1`区域。这些示例展示了如何在不同区域中操作AWS资源。
参数说明:
- `region_name`:指定AWS服务的区域。
- `MetricDataQueries`:定义要查询的指标数据。
- `Metric`:定义要监控的指标。
- `StartTime`和`EndTime`:定义查询的时间范围。
逻辑分析:
1. 创建`boto3`客户端时,通过`region_name`参数指定服务区域。
2. 使用`create_bucket`方法创建S3桶。
3. 使用`get_metric_data`方法获取EC2实例的CPU使用率。
4. `MetricDataQueries`中定义了要获取的数据类型和查询条件。
5. `Metric`中定义了具体的监控指标。
6. `StartTime`和`EndTime`定义了查询的时间范围。
通过这些代码示例,我们可以看到如何利用`boto3`库来实现跨区域的操作和监控,这对于管理和优化大规模的AWS基础设施至关重要。
# 5. boto库实践案例分析
## 5.1 实战:构建自动化备份解决方案
### 5.1.1 需求分析与方案设计
在现代云环境中,自动化备份是确保数据安全和业务连续性的关键。使用boto库,我们可以设计一个自动化备份解决方案,定期备份Amazon S3中的数据。需求分析通常包括以下几个方面:
- **备份频率**:确定备份的频率,例如每天、每周或每月。
- **备份保留策略**:定义备份的保留期限,以及何时进行清理。
- **备份内容**:确定需要备份的数据类型和结构。
- **备份目标**:选择备份的目标位置,可能是另一个S3存储桶或Amazon Glacier。
在设计阶段,我们需要考虑如何实现这些需求。例如,我们可以使用Amazon CloudWatch来触发备份作业,利用boto库编写Python脚本来处理备份任务,并将备份存储在预先定义的S3存储桶中。
### 5.1.2 代码实现与测试
实现自动化备份解决方案的代码可以分为几个主要部分:
1. **初始化boto客户端**:创建与AWS服务通信的boto客户端实例。
2. **列出待备份文件**:获取S3存储桶中的文件列表。
3. **备份文件**:将文件复制到备份存储桶。
以下是一个简化的代码示例,展示了如何使用boto3库来实现这一过程:
```python
import boto3
# 初始化boto3 S3客户端
s3_client = boto3.client('s3')
# 源存储桶和备份存储桶
source_bucket = 'source-bucket'
backup_bucket = 'backup-bucket'
# 列出源存储桶中的对象
response = s3_client.list_objects_v2(Bucket=source_bucket)
# 遍历对象并执行备份
for obj in response.get('Contents', []):
copy_source = {
'Bucket': source_bucket,
'Key': obj['Key']
}
# 复制对象到备份存储桶
s3_client.copy(copy_source, backup_bucket, obj['Key'])
```
在实际部署之前,我们需要对代码进行测试,确保它能够正确执行。测试可以包括:
- 确保代码在本地环境中正确执行。
- 检查备份文件是否正确存储在备份存储桶中。
- 验证备份数据的完整性。
## 5.2 实战:部署高可用的Web服务
### 5.2.1 架构设计与资源规划
部署高可用Web服务时,我们需要规划以下资源和架构:
- **EC2实例**:作为Web服务器运行。
- **负载均衡器**:分配流量到多个EC2实例。
- **安全组和网络ACL**:确保资源的安全访问。
- **自动扩展组**:根据负载自动调整EC2实例的数量。
资源规划包括确定实例的类型、数量以及所需的存储和带宽。此外,还需要考虑备份、监控和日志记录等运维需求。
### 5.2.2 部署脚本的编写与执行
使用boto库编写部署脚本时,我们需要关注以下几个步骤:
1. **配置网络**:创建VPC、子网和安全组。
2. **启动EC2实例**:根据配置启动一个或多个EC2实例。
3. **设置负载均衡器**:配置负载均衡器以分配流量。
4. **配置自动扩展**:设置自动扩展策略以应对流量变化。
以下是一个简化的代码示例,展示了如何使用boto3库来启动EC2实例:
```python
import boto3
# 初始化boto3 EC2客户端
ec2_client = boto3.client('ec2')
# 启动EC2实例
response = ec2_client.run_instances(
ImageId='ami-XXXXXXXX', # 替换为所需的AMI ID
MinCount=1,
MaxCount=1,
InstanceType='t2.micro',
KeyName='my-key-pair',
SecurityGroupIds=['sg-XXXXXXXX'], # 替换为安全组ID
)
# 实例ID
instance_id = response['Instances'][0]['InstanceId']
print(f'Instance launched with ID: {instance_id}')
```
在执行脚本之前,需要确保所有参数(如AMI ID、密钥对名称和安全组ID)都已正确设置。此外,还需要编写额外的代码来配置负载均衡器和自动扩展组。
## 5.3 实战:自动化运维脚本的编写
### 5.3.1 脚本需求分析与模块划分
自动化运维脚本通常用于简化日常任务,如监控系统状态、自动修复问题或执行常规维护。需求分析包括:
- **监控内容**:CPU使用率、磁盘空间、网络流量等。
- **自动修复策略**:当监控指标超出预设阈值时执行的操作。
- **维护任务**:如定期更新软件或清理临时文件。
模块划分可以帮助我们将复杂的运维任务分解为更小、更易于管理的部分。例如,我们可以创建以下模块:
- **监控模块**:负责收集和分析系统数据。
- **警报模块**:当监控指标异常时触发警报。
- **自动修复模块**:执行预定义的修复操作。
### 5.3.2 脚本的编写、调试与优化
编写自动化运维脚本时,我们需要关注以下方面:
- **代码可读性和维护性**:确保代码易于理解和维护。
- **错误处理**:正确处理可能发生的异常情况。
- **性能优化**:确保脚本执行效率和性能。
以下是一个简化的代码示例,展示了如何使用boto3库来获取EC2实例的状态:
```python
import boto3
# 初始化boto3 EC2客户端
ec2_client = boto3.client('ec2')
# 获取所有EC2实例的状态
response = ec2_client.describe_instances()
# 打印实例状态
for reservation in response['Reservations']:
for instance in reservation['Instances']:
print(instance['InstanceId'], instance['State']['Name'])
```
在实际部署之前,需要对脚本进行充分的测试,确保它能够正确执行并返回预期的结果。调试过程中可能需要逐步执行代码,检查变量值和逻辑分支。性能优化可能包括减少API调用次数、使用批量操作等策略。
请注意,以上代码示例需要根据实际环境和需求进行调整和完善。在实际部署时,还需要考虑权限管理、日志记录和异常处理等因素。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 boto 库,这是一个用于与亚马逊网络服务 (AWS) 交互的 Python 库。它涵盖了 boto 库的各个方面,包括:
* 使用技巧,例如掌握 AWS 服务交互的技巧。
* 高级功能,例如提升云服务交互效率。
* 自动化 AWS 任务的实例和脚本构建。
* 安全指南,确保 AWS 资源访问权限的安全。
* 性能优化技巧,提升 boto 库脚本的效率。
* 与其他 AWS SDK 的比较,阐明 boto 库的优势。
* 自动化 AWS 资源备份的案例研究。
* 权限管理秘籍,精细化控制 AWS 资源访问。
* 监控与日志分析的最佳实践,记录和分析操作日志。
* 存储解决方案的最佳实践,包括 S3 和 EBS 操作。
* 数据库管理指南,全面解析 RDS 和 DynamoDB 操作。
* 身份与访问管理,涵盖 IAM 策略和角色管理。
* 云监控服务的集成,包括与 CloudWatch 的集成和数据可视化。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
解决组合分配难题:偏好单调性神经网络实战指南(专家系统协同)

# 摘要
本文旨在探讨解决组合分配难题的方法,重点关注偏好单调性理论在优化中的应用以及神经网络的实战应用。文章首先介绍了偏好单调性的定义、性质及其在组合优化中的作用,接着深入探讨了如何
WINDLX模拟器案例研究:3个真实世界的网络问题及解决方案

# 摘要
本文对WINDLX模拟器进行了全面概述,并深入探讨了网络问题的理论基础与诊断方法。通过对比OSI七层模型和TCP/IP模型,分析了网络通信中常见的问题及其分类。文中详细介绍了网络故障诊断技术,并通过案例分析方法展示了理论知识在实践中的应用。三个具体案例分别涉及跨网络性能瓶颈、虚拟网络隔离失败以及模拟器内网络服务崩溃的背景、问题诊断、解决方案实施和结果评估。最后,本文展望了W
【FREERTOS在视频处理中的力量】:角色、挑战及解决方案

# 摘要
FreeRTOS在视频处理领域的应用日益广泛,它在满足实时性能、内存和存储限制、以及并发与同步问题方面面临一系列挑战。本文探讨了FreeRTOS如何在视频处理中扮演关键角色,分析了其在高优先级任务处理和资源消耗方面的表现。文章详细讨论了任务调度优化、内存管理策略以及外设驱动与中断管理的解决方案,并通过案例分析了监控视频流处理、实时视频转码
ITIL V4 Foundation题库精讲:考试难点逐一击破(备考专家深度剖析)
# 摘要
ITIL V4 Foundation作为信息技术服务管理领域的重要认证,对从业者在理解新框架、核心理念及其在现代IT环境中的应用提出了要求。本文综合介绍了ITIL V4的考试概览、核心框架及其演进、四大支柱、服务生命周期、关键流程与功能以及考试难点,旨在帮助考生全面掌握ITIL V4的理论基础与实践应用。此外,本文提供了实战模拟
【打印机固件升级实战攻略】:从准备到应用的全过程解析

# 摘要
本文综述了打印机固件升级的全过程,从前期准备到升级步骤详解,再到升级后的优化与维护措施。文中强调了环境检查与备份的重要性,并指出获取合适固件版本和准备必要资源对于成功升级不可或缺。通过详细解析升级过程、监控升级状态并进行升级后验证,本文提供了确保固件升级顺利进行的具体指导。此外,固件升级后的优化与维护策略,包括调整配置、问题预防和持续监控,旨在保持打印机最佳性能。本文还通过案
【U9 ORPG登陆器多账号管理】:10分钟高效管理你的游戏账号

# 摘要
本文详细探讨了U9 ORPG登陆器的多账号管理功能,首先概述了其在游戏账号管理中的重要性,接着深入分析了支持多账号登录的系统架构、数据流以及安全性问题。文章进一步探讨了高效管理游戏账号的策略,包括账号的组织分类、自动化管理工具的应用和安全性隐私保护。此外,本文还详细解析了U9 ORPG登陆器的高级功能,如权限管理、自定义账号属性以及跨平台使用
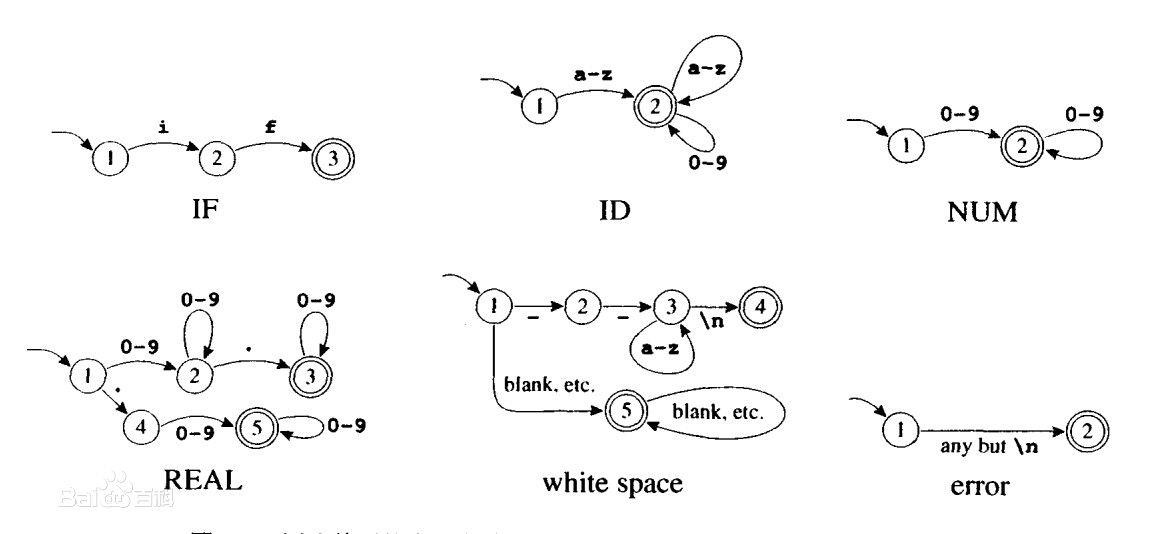
【编译原理实验报告解读】:燕山大学案例分析
# 摘要
本文是关于编译原理的实验报告,首先介绍了编译器设计的基础理论,包括编译器的组成部分、词法分析与语法分析的基本概念、以及语法的形式化描述。随后,报告通过燕山大学的实验案例,深入分析了实验环境、工具以及案例目标和要求,详细探讨了代码分析的关键部分,如词法分析器的实现和语法分析器的作用。报告接着指出了实验中遇到的问题并提出解决策略,最后展望了编译原理实验的未来方向,包括最新研究动态和对
【中兴LTE网管升级与维护宝典】:确保系统平滑升级与维护的黄金法则

# 摘要
本文详细介绍了LTE网管系统的升级与维护过程,包括升级前的准备工作、平滑升级的实施步骤以及日常维护的策略。文章强调了对LTE网管系统架构深入理解的重要性,以及在升级前进行风险评估和备份的必要性。实施阶段,作者阐述了系统检查、性能优化、升级步骤、监控和日志记录的重要性。同时,对于日常维护,本文提出监控KPI、问题诊断、维护计划执行以及故障处理和灾难恢复措施。案例研究部分探讨了升级维护实践中的挑战与解决方案。最后,文章展望了LT
故障诊断与问题排除:合泰BS86D20A单片机的自我修复指南
# 摘要
本文系统地介绍了故障诊断与问题排除的基础知识,并深入探讨了合泰BS86D20A单片机的特性和应用。章节二着重阐述了单片机的基本概念、硬件架构及其软件环境。在故障诊断方面,文章提出了基本的故障诊断方法,并针对合泰BS86D20A单片机提出了具体的故障诊断流程和技巧。此外,文章还介绍了问题排除的高级技术,包括调试工具的应用和程序自我修复技术。最后,本文就如何维护和优化单片
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )