MyBatis框架的基本配置与CRUD操作
发布时间: 2024-02-22 06:28:02 阅读量: 44 订阅数: 24 

mybatis基础CRUD
# 1. MyBatis框架简介
## 1.1 MyBatis框架概述
MyBatis 是一个优秀的持久层框架,它对 JDBC 的操作数据库的过程进行封装,使开发者只需关注 SQL 本身,而不需要花费精力去处理例如连接数据库、创建 Statement、处理结果集等基本工作。MyBatis通过 XML 或注解的方式将要执行的 SQL 接口、输入参数、结果映射等映射在一起。
## 1.2 MyBatis框架的优势与特点
- **灵活性高**: MyBatis 提供了非常灵活的映射方式,支持动态 SQL、存储过程调用等。
- **SQL与Java代码分离**: 通过 XML 或注解的方式,使 SQL 与 Java 代码分离,降低了耦合性。
- **性能高**: MyBatis 使用简单的 XML 或注解配置,避免了重复代码,使得开发效率高,性能也得到了很好的保证。
以上是MyBatis框架简介的内容,我们将在接下来的章节中深入探讨MyBatis框架的基本配置、CRUD操作、查询操作、新增操作、更新与删除操作等主题。
# 2. MyBatis框架的基本配置
MyBatis框架的基本配置主要包括导入相关依赖、配置数据源和SqlSessionFactory。下面将详细介绍每个配置步骤。
### 2.1 导入MyBatis相关依赖
首先,在项目的构建工具中(如Maven、Gradle),需要添加MyBatis框架相关的依赖项。例如,对于Maven项目,可以在`pom.xml`文件中添加如下依赖:
```xml
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
<!-- 添加数据库驱动依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
</dependencies>
```
### 2.2 配置MyBatis的数据源
在MyBatis框架中,数据源的配置通常是通过`DataSource`对象实现的。可以使用第三方连接池(如Druid、HikariCP)来管理数据源,也可以直接配置数据库连接信息。
下面是一个简单的数据源配置示例(Java代码):
```java
import org.apache.ibatis.datasource.unpooled.UnpooledDataSource;
import org.apache.ibatis.transaction.TransactionFactory;
import org.apache.ibatis.transaction.jdbc.JdbcTransactionFactory;
import javax.sql.DataSource;
DataSource dataSource = new UnpooledDataSource("com.mysql.cj.jdbc.Driver", "jdbc:mysql://localhost:3306/mybatis_db", "username", "password");
TransactionFactory transactionFactory = new JdbcTransactionFactory();
```
### 2.3 配置MyBatis的SqlSessionFactory
配置`SqlSessionFactory`是MyBatis中的核心步骤,它负责创建`SqlSession`对象,用于执行SQL语句。下面是配置`SqlSessionFactory`的示例代码(Java):
```java
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
```
在以上示例中,`reader`是MyBatis配置文件的读取器,通过读取配置文件来构建`SqlSessionFactory`对象。
通过以上配置步骤,MyBatis框架就可以基本运行起来,接下来可以进行CRUD操作等数据库操作。
# 3. MyBatis框架的CRUD操作
在MyBatis框架中,CRUD操作是非常常见的操作,也是开发中经常会遇到的内容。下面我们将详细介绍如何在MyBatis框架中进行CRUD操作。
#### 3.1 编写实体类
首先,我们需要定义与数据库表对应的实体类。实体类中的属性应该与数据库表中的字段对应,可以使用注解或者XML配置来映射字段与属性之间的关系。
```java
// 示例实体类User.java
public class User {
private Long id;
private String username;
private String password;
// 省略getter和setter方法
}
```
#### 3.2 编写Mapper接口
接下来,我们需要编写Mapper接口,用于定义数据库操作的方法,如查询、插入、更新、删除等。Mapper接口中的方法名和参数应该与SQL语句对应。
```java
// 示例Mapper接口UserMapper.java
public interface UserMapper {
User getUse
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以“基于SSM的教务管理系统”为主题,详细介绍了在毕业设计中如何利用SSM框架构建教务管理系统。从SSM框架的概览与入门开始,逐步深入到Spring框架的IOC和DI原理、AOP的实现与应用,再到MyBatis框架的配置与操作,最终探讨SSM框架整合与相关配置实践。通过讲解架构设计、数据库设计、权限管理、用户角色权限、模块划分等内容,为读者呈现了一个完整的系统开发流程。同时,也介绍了测试、前端设计、数据交互、性能优化等方面的实践经验,帮助读者更好地掌握SSM框架应用的全过程,为毕业设计或实际项目开发提供指导与参考。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C#网络编程揭秘】:TCP_IP与UDP通信机制全解析
# 摘要
本文全面探讨了C#网络编程的基础知识,深入解析了TCP/IP架构下的TCP和UDP协议,以及高级网络通信技术。首先介绍了C#中网络编程的基础,包括TCP协议的工作原理、编程模型和异常处理。其次,对UDP协议的应用与实践进行了讨论,包括其特点、编程模型和安全性分析。然后,详细阐述了异步与同步通信模型、线程管理,以及TLS/SSL和NAT穿透技术在C#中的应用。最后,通过实战项目展示了网络编程的综合应用,并讨论了性能优化、故障排除和安全性考量。本文旨在为网络编程人员提供详尽的指导和实用的技术支持,以应对在实际开发中可能遇到的各种挑战。
# 关键字
C#网络编程;TCP/IP架构;TCP
深入金融数学:揭秘随机过程在金融市场中的关键作用

# 摘要
随机过程理论是分析金融市场复杂动态的基础工具,它在期权定价、风险管理以及资产配置等方面发挥着重要作用。本文首先介绍了随机过程的定义、分类以及数学模型,并探讨了模拟这些过程的常用方法。接着,文章深入分析了随机过程在金融市场中的具体应用,包括Black-Scholes模型、随机波动率模型、Value at Risk (VaR)和随机控制理论在资产配置中的应
CoDeSys 2.3中文教程高级篇:自动化项目中面向对象编程的5大应用案例
# 摘要
本文全面探讨了面向对象编程(OOP)的基础理论及其在CoDeSys 2.3平台的应用实践。首先介绍面向对象编程的基本概念与理论框架,随后深入阐释了OOP的三大特征:封装、继承和多态,以及设计原则,如开闭原则和依赖倒置原则。接着,本文通过CoDeSys 2.3平台的实战应用案例,展示了面向对象编程在工业自动化项目中
【PHP性能提升】:专家解读JSON字符串中的反斜杠处理,提升数据清洗效率
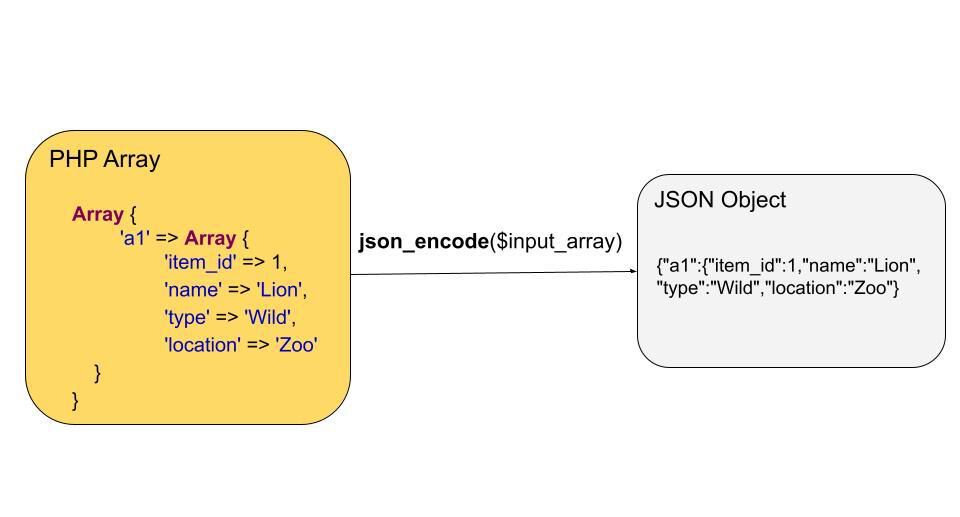
# 摘要
本文深入探讨了在PHP环境中处理JSON字符串的重要性和面临的挑战,涵盖了JSON基础知识、反斜杠处理、数据清洗效率提升及进阶优化等关键领域。通过分析JSON数据结构和格式规范,本文揭示了PHP中json_encode()和json_decode()函数使用的效率和性能考量。同时,本文着重讨论了反斜杠在JSON字符串中的角色,以及如何高效处理以避免常见的数据清洗性能
成为行业认可的ISO 20653专家:全面培训课程详解

# 摘要
ISO 20653标准作为铁路行业的关键安全规范,详细规定了安全管理和风险评估流程、技术要求以及专家认证路径。本文对ISO 20653标准进行了全面概述,深入分析了标准的关键要素,包括其历史背景、框架结构、安全管理系统要求以及铁路车辆安全技术要求。同时,本文探讨了如何在企业中实施ISO 20653标准,并分析了在此过程中可能遇到的挑战和解决方案。此外,文章还强调了持续专业发展的重要性
Arm Compiler 5.06 Update 7实战指南:专家带你玩转LIN32平台性能调优

# 摘要
本文详细介绍了Arm Compiler 5.06 Update 7的特点及其在不同平台上的性能优化实践。文章首先概述了Arm架构与编译原理,并针对新版本编译器的新特性进行了深入分析。接着,介绍了如何搭建编译环境,并通过编译实践演示了基础用法。此外,文章还
【62056-21协议深度解析】:构建智能电表通信系统的秘诀
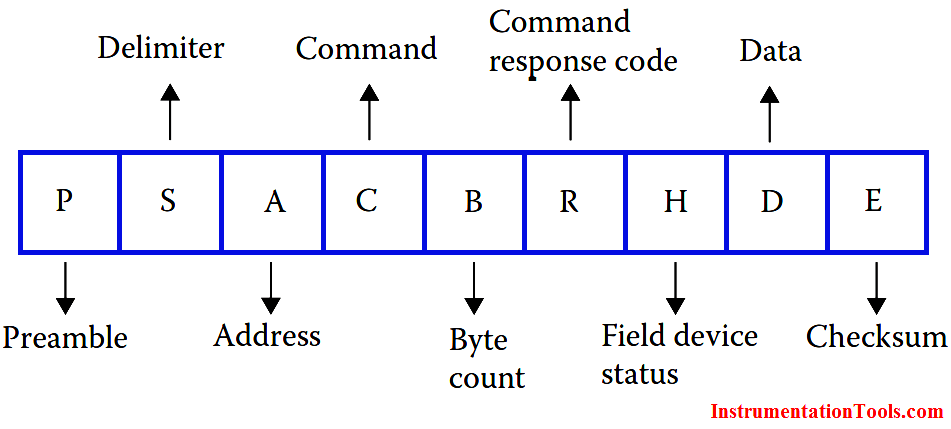
# 摘要
本文对62056-21通信协议进行了全面概述,分析了其理论基础,包括帧结构、数据封装、传输机制、错误检测与纠正技术。在智能电表通信系统的实现部分,探讨了系统硬件构成、软件协议栈设计以及系统集成与测试的重要性。此外,本文深入研究了62056-21协议在实践应用中的案例分析、系统优化策略和安全性增强措
5G NR同步技术新进展:探索5G时代同步机制的创新与挑战

# 摘要
本文全面概述了5G NR(新无线电)同步技术的关键要素及其理论基础,探讨了物理层同步信号设计原理、同步过程中的关键技术,并实践探索了同步算法与
【天龙八部动画系统】:骨骼动画与精灵动画实现指南(动画大师分享)
# 摘要
本文系统地探讨了骨骼动画与精灵动画的基本概念、技术剖析、制作技巧以及融合应用。文章从理论基础出发,详细阐述了骨骼动画的定义、原理、软件实现和优化策略,同时对精灵动画的分类、工作流程、制作技巧和高级应用进行了全面分析。此外,本文还探讨了骨骼动画与精灵动画的融合点、构建跨平台动画系统的策略,并通过案例分
【Linux二进制文件执行权限问题快速诊断与解决】:一分钟搞定执行障碍
# 摘要
本文针对Linux环境下二进制文件执行权限进行了全面的分析,概述了权限的基本概念、构成和意义,并探讨了执行权限的必要性及其常见问题。通过介绍常用的权限检查工具和方法,如使用`ls`和`stat`命令,文章提供了快速诊断执行障碍的步骤和技巧,包括文件所有者和权限设置的确认以及脚本自动化检查。此外,本文还深入讨论了特殊权限位、文件系统特性、非标准权限问题以及安全审计的重要性。通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )