Python爬虫实战:数据采集与处理全流程解析
发布时间: 2024-03-20 19:00:56 阅读量: 43 订阅数: 42 

Python爬虫实战:数据采集、处理与分析
# 1. Python爬虫简介
爬虫作为一种网络爬行程序,被广泛应用于网页数据的采集与分析,通过模拟浏览器行为获取网页数据,具有自动化、高效、快速等优点。Python作为一种简洁易学、功能强大的编程语言,在爬虫领域有着广泛的应用和支持,成为开发者的首选之一。
## 1.1 什么是爬虫及其作用
网络爬虫是一种按照一定规则自动地抓取互联网信息的程序或脚本,常用于搜索引擎、数据分析、数据挖掘等领域。爬虫能够快速准确地从网页中提取所需信息,帮助用户实现自动化的数据采集和处理。
## 1.2 Python在爬虫中的应用优势
Python作为一种简洁易读的高级编程语言,在网络爬虫开发中具有诸多优势:
- 强大的第三方库支持:如Requests、BeautifulSoup、Scrapy等,提供了丰富的功能和工具,方便开发者进行网页数据的采集和处理。
- 语法简洁清晰:Python代码简洁易读,易于维护和调试,适合开发大型爬虫项目。
- 高效的数据处理能力:Python通过Pandas、NumPy等库提供了强大的数据处理和分析功能,能够方便地对采集到的数据进行清洗、处理和分析。
- 社区活跃支持:Python拥有庞大的开发者社区,提供了丰富的教程、文档和支持,使得爬虫开发更加便利和高效。
# 2. 明确目标与需求
在这一章中,我们将讨论如何明确数据采集与处理的目标和需求,以确保我们的爬虫项目能够顺利进行并达到预期效果。
### 2.1 确定数据来源与采集目标
在开始爬虫项目之前,首先需要明确数据的来源是哪里,以及我们的采集目标是什么。这一步是整个爬虫项目的基础,只有明确了数据来源和采集目标,我们才能有针对性地进行爬虫的设计与开发。
在确定数据来源时,可以考虑以下几个途径:
- 网站页面数据
- API接口数据
- 数据库数据
- 文件数据等
同时,在确定采集目标时,需要考虑以下几个方面:
- 需要采集的具体数据字段
- 数据的更新频率和规模
- 数据的格式要求等
### 2.2 定义数据处理需求与格式要求
除了明确数据采集目标外,还需要定义清楚数据处理的需求和格式要求。数据处理包括数据清洗、格式化、存储等步骤,而格式要求则涉及数据的结构、类型、标记等方面。
在定义数据处理需求时,可以考虑以下几个问题:
- 需要对数据进行哪些清洗处理
- 数据的存储方式是什么
- 是否需要进行数据的聚合或关联等
而在定义数据格式要求时,可以考虑以下几个方面:
- 数据的结构是什么样的
- 数据的类型是文本、图片、视频还是其他
- 数据是否需要进行特定格式的标记等
通过明确数据处理需求与格式要求,可以为后续的数据采集与处理工作奠定良好的基础,确保爬虫项目能够顺利进行并达到预期效果。
# 3. 数据采集实战
在本章中,我们将深入探讨实际数据采集的相关操作,包括网页分析、数据结构解析、使用Requests库模拟HTTP请求等。通过以下几个小节的学习,您将获得丰富的经验与技巧。
#### 3.1 网页分析与数据结构解析
在数据采集过程中,首先需要对目标网页进行分析,找出目标数据所在的位置。通常我们会使用BeautifulSoup库来解析HTML或XML结构的网页内容,从而提取我们需要的数据。
```python
# 导入BeautifulSoup库
from bs4 import BeautifulSoup
import requests
# 发送HTTP请求获取网页内容
url = 'http://example.com'
response = requests.get(url)
html_content = response.text
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(html_content, 'html.parser')
# 查找目标数据并提取
title = soup.find('h1').text
paragraphs = soup.find_all('p')
for p in paragraphs:
print(p.text)
```
**代码说明:**
- 通过Requests库发送HTTP请求获取网页内容。
- 使用BeautifulSoup解析HTML内容,通过find和find_all方法查找目标数据。
- 最后将提取到的数据输出或保存。
**结果说明:**
通过以上代码,我们可以轻松地解析目标网页的结构,找到需要采集的数据,为后续数据处理和存储打下基础。
#### 3.2 使用Requests库模拟HTTP请求
在实际爬取数据时,我们需要模拟浏览器发送HTTP请求,以获取网页内容。Requests库是Python中常用的HTTP库,可以方便地实现GET和POST请求等操作。
```python
# 导入Requests库
import requests
# 模拟发送GET请求
url = 'http://example.com'
response = requests.get(url)
print(response.text)
# 模拟发送POST请求
post_data = {'key1': 'value1', 'key2': 'value2'}
response_post = requests.post(url, data=post_data)
print(response_post.text)
```
**代码说明:**
- 使用Requests库发送GET请求获取网页内容,并打印返回的文本信息。
- 使用Requests库发送POST请求,并打印返回的文本信息。
**结果说明:**
通过Requests库模拟HTTP请求,我们可以获取对应网页的内容,进一步进行数据解析和处理。
#### 3.3 实现爬虫的逻辑与流程
在实现爬虫的逻辑与流程中,我们需要考虑如何合理地控制爬取速度、处理异常情况、防止被反爬等问题。以下是一个基本的爬虫逻辑示例:
```python
import time
import requests
def crawler(url):
try:
response = requests.get(url)
if response.status_code == 200:
# 处理数据
print(response.text)
time.sleep(1) # 控制爬取速度
except Exception as e:
print('Error:', e)
# 主程序入口
if __name__ == '__main__':
start_url = 'http://example.com'
crawler(start_url)
```
**代码说明:**
- 定义爬虫函数crawler,使用try...except处理异常情况。
- 控制爬取速度,防止对目标网站造成压力。
- 在主程序中调用爬虫函数,传入起始URL进行爬取。
**结果说明:**
通过以上爬虫逻辑的实现,我们可以按照预定流程爬取目标网站的数据,并对异常情况进行处理,确保爬虫的稳定性与效率。
# 4. 数据处理与清洗
数据处理与清洗是爬虫工作中非常重要的一个环节,它涉及到对爬取到的数据进行解析、清洗和格式化处理,以便后续的分析和应用。在这一章节中,我们将学习如何利用Python中的BeautifulSoup库来解析HTML数据,进行数据清洗与格式化处理,并最终实现数据的存储与导出。
#### 4.1 使用BeautifulSoup解析HTML数据
在数据采集过程中,我们通常会爬取到各种形式的网页数据,而这些数据往往是以HTML格式呈现的。为了提取我们需要的信息,我们可以使用BeautifulSoup库来进行HTML数据的解析。
下面是一个简单示例,演示如何使用BeautifulSoup来解析HTML数据:
```python
from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>这是一个示例网页</title>
</head>
<body>
<div>
<p class="content">这是一段内容。</p>
</div>
<div>
<p class="content">这是另一段内容。</p>
</div>
</body>
</html>
# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')
# 提取标题
title = soup.title.get_text()
print("网页标题:", title)
# 提取所有段落内容
paragraphs = soup.find_all('p')
for p in paragraphs:
print("段落内容:", p.get_text())
```
**代码解析:**
- 使用BeautifulSoup将HTML字符串解析为BeautifulSoup对象。
- 使用`.title.get_text()`方法获取网页标题。
- 使用`.find_all('p')`方法提取所有段落内容。
**代码总结:**
通过BeautifulSoup库,我们可以轻松地解析HTML数据,提取其中的信息并进行后续处理。
**结果说明:**
运行以上代码,将输出网页标题和两段段落内容。
#### 4.2 数据清洗与格式化处理
数据采集得到的数据往往包含各种噪音和无用信息,因此在进行数据分析前,需要对数据进行清洗与格式化处理。
以下是一个简单的数据清洗示例,演示如何利用Python对数据进行清洗:
```python
# 假设我们有一段脏数据需要清洗
dirty_data = "Hello, $%^this* is a sample &text!@#."
# 定义一个函数来清洗数据
def clean_text(text):
import re
cleaned_text = re.sub(r'[^a-zA-Z ]', '', text)
return cleaned_text
# 清洗数据
cleaned_data = clean_text(dirty_data)
print("清洗后的数据:", cleaned_data)
```
**代码解析:**
- 使用正则表达式`re.sub()`方法将非字母字符替换为空格,从而实现数据的清洗。
**代码总结:**
通过利用正则表达式,我们可以清洗文本数据,去除其中的特殊字符和噪音。
**结果说明:**
运行以上代码,将输出清洗后的文本数据。
#### 4.3 数据存储与导出
在数据处理完成后,我们通常会将数据保存到文件或数据库中,以便后续的分析和应用。Python提供了各种模块和库来实现数据的存储和导出。
以下是一个简单示例,演示如何将数据存储到CSV文件中:
```python
import csv
# 假设我们有一组数据
data = [
['Alice', 25, 'Female'],
['Bob', 30, 'Male'],
['Charlie', 35, 'Male']
]
# 将数据存储到CSV文件中
with open('data.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(data)
print("数据已存储到data.csv文件中。")
```
**代码解析:**
- 使用`csv.writer`将数据写入CSV文件中。
**代码总结:**
通过使用csv模块,我们可以将数据以CSV格式存储在文件中。
**结果说明:**
运行以上代码,将数据存储到CSV文件中,并输出提示信息。
# 5. 数据分析与可视化
数据分析与可视化在爬虫数据处理中扮演着至关重要的角色,通过对采集到的数据进行深入分析和图表展示,可以更直观地了解数据的特征和趋势,为后续决策提供有效支持。
#### 5.1 数据分析工具介绍
在Python爬虫实战中,常用的数据分析工具包括NumPy、Pandas和Matplotlib。NumPy是Python中科学计算的基础包,提供了多维数组对象以及对数组进行操作的函数。Pandas是建立在NumPy之上的数据分析工具,提供了快速、灵活、丰富的数据结构和数据分析工具。Matplotlib是Python中常用的绘图库,可用于生成各种类型的图表和可视化效果。
#### 5.2 使用Pandas进行数据处理与分析
Pandas是Python中优秀的数据处理库,提供了Series和DataFrame两种核心数据结构,可以轻松处理各种数据格式、清洗缺失数据、进行数据筛选与分组等操作。下面是一个简单的示例代码:
```python
import pandas as pd
# 创建一个DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']}
df = pd.DataFrame(data)
# 打印DataFrame
print(df)
# 查看数据类型
print(df.dtypes)
# 统计描述性统计信息
print(df.describe())
```
通过Pandas提供的函数和方法,可以方便地对数据进行处理、分析和统计,为数据可视化做好准备。
#### 5.3 数据可视化技术与工具选择
数据可视化是将数据转换为直观易懂的图形展示,常用的数据可视化工具包括Matplotlib、Seaborn、Plotly等。这些工具提供了丰富的图表类型和定制化选项,可以根据数据特点选择合适的可视化方式,如折线图、柱状图、饼图、散点图等。结合数据分析结果,采用适当的可视化方式展现数据,有助于快速把握数据概况和趋势,为进一步的数据解读和决策提供支持。
# 6. 进阶与优化
在这一章中,我们将讨论如何进一步优化爬虫工作流程并提高数据采集效率。同时,我们也会谈及反爬虫策略以及如何实现定时任务和自动化数据采集。
### 6.1 爬虫性能优化与反爬策略
在爬虫的实战操作中,为了提高数据采集效率和稳定性,我们需要考虑一些性能优化的方法。这包括但不限于:
- 使用多线程或异步IO:通过使用多线程或异步IO技术,可以同时处理多个网络请求,加快数据采集速度。
- 设置合理的请求头信息:模拟真实用户行为,避免被网站识别为爬虫并进行封禁。
- 定期更新爬虫代码:网站结构和规则可能会发生变化,及时更新爬虫代码以适应变化。
除此之外,我们还需要了解反爬虫策略,以避免被网站封禁或限制:
- 随机化请求频率:避免在短时间内频繁请求同一网站,可在请求之间加入随机时间间隔。
- 使用代理IP:通过使用代理IP,可以隐藏真实IP地址,降低被识别为爬虫的风险。
- 解析JS动态内容:有些网站会通过JS动态渲染页面内容,需要使用渲染引擎或工具来解析JS生成的数据。
### 6.2 定时任务与自动化数据采集
为了实现定时任务和自动化数据采集,我们可以借助一些工具和技术来简化操作流程:
- 使用定时任务工具:例如crontab(Linux系统)或Windows任务计划器(Windows系统)来定时启动爬虫任务。
- 编写自动化脚本:通过编写脚本来实现数据采集、处理和存储的自动化流程,减少人工干预。
- 考虑使用无头浏览器:对于需要执行JavaScript的网页,可以使用无头浏览器(Headless Browser)来模拟浏览器行为进行数据采集。
通过以上方法,我们能够实现爬虫的自动化运行和数据采集,提高工作效率和数据准确性。
### 6.3 实战案例分享与总结
在本章的最后,我们将分享一些实际案例,展示如何应用优化技术和策略来构建高效的爬虫系统。同时,我们也会对全书内容进行总结,帮助读者更好地掌握Python爬虫实战中的关键知识点和技巧。
希望这些内容能够帮助你更好地理解Python爬虫的进阶与优化技术,提升你的数据采集和处理能力!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python科学计算与数据可视化》专栏涵盖了Python在科学计算和数据可视化领域的广泛应用。从基础入门到高级实践,涵盖了Python语言的基础语法和数据类型,详解了常用的数据结构如列表、元组和字典。读者将学习如何利用Python进行数学运算和科学计算,掌握Pandas、Numpy、Matplotlib等常用库的操作技巧。此外,专栏还涉及数据处理、数据分析、数据可视化等方面的内容,包括对Seaborn、Plotly、Scikit-learn等库的全面讲解和实践应用。此外,还包含了机器学习、深度学习、自然语言处理、推荐系统、爬虫、大数据处理、并行计算、网络编程、RESTful API设计以及云计算等诸多领域的实践案例和技术分享。无论您是初学者还是已经有一定经验的Python开发者,都可以通过本专栏获得丰富的知识和实用的技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子组件可靠性快速入门:IEC 61709标准的10个关键点解析
# 摘要
电子组件可靠性是电子系统稳定运行的基石。本文系统地介绍了电子组件可靠性的基础概念,并详细探讨了IEC 61709标准的重要性和关键内容。文章从多个关键点深入分析了电子组件的可靠性定义、使用环境、寿命预测等方面,以及它们对于电子组件可靠性的具体影响。此外,本文还研究了IEC 61709标准在实际应用中的执行情况,包括可靠性测试、电子组件选型指导和故障诊断管理策略。最后,文章展望了IEC 61709标准面临的挑战及未来趋势,特别是新技术对可靠性研究的推动作用以及标准的适应性更新。
# 关键字
电子组件可靠性;IEC 61709标准;寿命预测;故障诊断;可靠性测试;新技术应用
参考资源
KEPServerEX扩展插件应用:增强功能与定制解决方案的终极指南
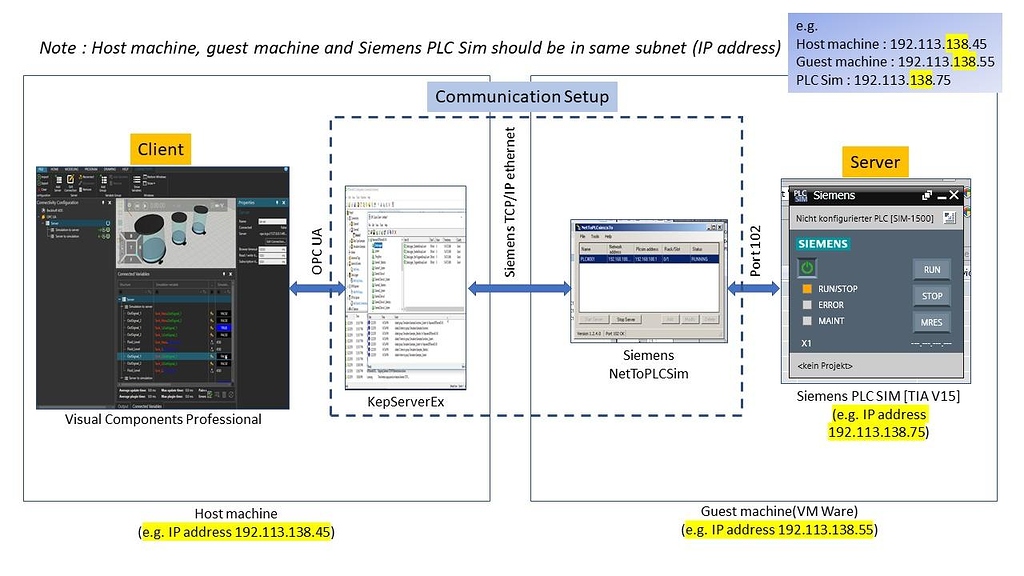
# 摘要
本文全面介绍了KEPServerEX扩展插件的概况、核心功能、实践案例、定制解决方案以及未来的展望和社区资源。首先概述了KEPServerEX扩展插件的基础知识,随后详细解析了其核心功能,包括对多种通信协议的支持、数据采集处理流程以及实时监控与报警机制。第三章通过
【Simulink与HDL协同仿真】:打造电路设计无缝流程

# 摘要
本文全面介绍了Simulink与HDL协同仿真技术的概念、优势、搭建与应用过程,并详细探讨了各自仿真环境的配置、模型创建与仿真、以及与外部代码和FPGA的集成方法。文章进一步阐述了协同仿真中的策略、案例分析、面临的挑战及解决方案,提出了参数化模型与自定义模块的高级应用方法,并对实时仿真和硬件实现进行了深入探讨。最
高级数值方法:如何将哈工大考题应用于实际工程问题
# 摘要
数值方法作为工程计算中不可或缺的工具,在理论研究和实际应用中均显示出其重要价值。本文首先概述了数值方法的基本理论,包括数值分析的概念、误差分类、稳定性和收敛性原则,以及插值和拟合技术。随后,文章通过分析哈工大的考题案例,探讨了数值方法在理论应用和实际问
深度解析XD01:掌握客户主数据界面,优化企业数据管理

# 摘要
客户主数据界面作为企业信息系统的核心组件,对于确保数据的准确性和一致性至关重要。本文旨在探讨客户主数据界面的概念、理论基础以及优化实践,并分析技术实现的不同方法。通过分析客户数据的定义、分类、以及标准化与一致性的重要性,本文为设计出高效的主数据界面提供了理论支撑。进一步地,文章通过讨论数据清洗、整合技巧及用户体验优化,指出了实践中的优化路径。本文还详细阐述了技术栈选择、开发实践和安
Java中的并发编程:优化天气预报应用资源利用的高级技巧
# 摘要
本论文针对Java并发编程技术进行了深入探讨,涵盖了并发基础、线程管理、内存模型、锁优化、并发集合及设计模式等关键内容。首先介绍了并发编程的基本概念和Java并发工具,然后详细讨论了线程的创建与管理、线程间的协作与通信以及线程安全与性能优化的策略。接着,研究了Java内存模型的基础知识和锁的分类与优化技术。此外,探讨了并发集合框架的设计原理和
计算机组成原理:并行计算模型的原理与实践
# 摘要
随着计算需求的增长,尤其是在大数据、科学计算和机器学习领域,对并行计算模型和相关技术的研究变得日益重要。本文首先概述了并行计算模型,并对其基础理论进行了探讨,包括并行算法设计原则、时间与空间复杂度分析,以及并行计算机体系结构。随后,文章深入分析了不同的并行编程技术,包括编程模型、语言和框架,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )