Ubuntu环境下的Python 3.9快速安装指南:一步到位成为专家级用户
发布时间: 2025-01-09 16:13:13 阅读量: 9 订阅数: 6 

ubuntu安装python3.9 ubuntu安装python3.9
# 摘要
本文旨在介绍Ubuntu环境下Python 3.9的安装、配置以及编程实践。文章首先概述了Ubuntu与Python的基本信息,随后详细介绍了在Ubuntu下安装Python 3.9的步骤,包括准备、通过官方源安装和使用第三方工具。接着,本文转入环境配置,包括环境变量设置、虚拟环境创建和pip包管理工具的使用。基础编程实践涵盖了Python 3.9的基本语法、模块与包的使用,以及函数编程技巧。高级应用技巧部分讨论了面向对象编程、异常处理、文件操作和并发编程。最后,文章通过项目实战部分,包括Web项目构建、数据分析与可视化、以及Python在DevOps中的应用,展示了如何将所学知识应用于实际项目中,进一步加深理解和实践能力。
# 关键字
Ubuntu;Python 3.9;环境配置;编程实践;高级应用;项目实战
参考资源链接:[Ubuntu 22.04 安装Python 3.9:详述编译过程与避坑指南](https://wenku.csdn.net/doc/3k3rhd4kv3?spm=1055.2635.3001.10343)
# 1. Ubuntu环境与Python简介
## Ubuntu环境简介
Ubuntu是一个以桌面应用为主的开源操作系统,它基于Debian发行版,采用Linux内核。Ubuntu易于使用,社区支持强大,适合开发者进行软件开发和测试工作。在Ubuntu系统中,用户能够通过终端进行软件包管理,安装和更新软件,以及进行系统维护。
## Python的起源和特点
Python是一种高级编程语言,由Guido van Rossum在1989年圣诞节期间开始设计,第一个公开发行版发行于1991年。Python设计哲学强调代码的可读性和简洁的语法,使用Python编写的代码更接近英语书写,因此它被广泛应用于教学、科学计算、数据处理、人工智能、网络爬虫等领域。Python是一种解释型语言,它支持多种编程范式,包括面向对象、命令式、函数式和过程式编程。
## Python在Ubuntu上的应用
在Ubuntu上使用Python,不仅能够帮助开发者利用Python强大的标准库和第三方库来快速开发应用程序,还能通过Python脚本来自动化系统管理任务,从而提高工作效率。Python在Ubuntu上的应用同样延伸到了数据科学、机器学习、网络开发等多个领域,使其成为IT专业人士不可或缺的工具之一。
随着技术的不断进步,Python社区也在不断成长,Python 3的持续更新为程序员提供了更多新特性和功能。接下来的章节,我们将详细了解在Ubuntu环境下安装和配置Python 3.9的详细步骤,以及如何开始你的Python编程之旅。
# 2. Python 3.9在Ubuntu下的安装
## 2.1 安装前的准备工作
### 2.1.1 检查系统兼容性
在尝试安装Python 3.9之前,有必要确认您的Ubuntu系统版本是否兼容Python 3.9。大多数现代的Ubuntu版本,例如Ubuntu 18.04 LTS或更新的版本,都能够支持Python 3.9。可以通过以下命令检查系统版本:
```bash
lsb_release -a
```
该命令将输出系统的详细信息,包括Ubuntu的版本号。确认版本号之后,您可以通过以下命令查看已安装的Python版本:
```bash
python3 --version
```
或者
```bash
python3.9 --version
```
如果上述命令返回了Python 3.9或更高版本的输出,则说明您的系统已经安装了兼容的Python版本。如果没有安装,或者安装的版本不符合您的需求,那么您可能需要进行Python的安装或升级。
### 2.1.2 更新系统软件包
在安装Python之前,建议更新系统软件包列表和已安装的软件包,以确保系统中所有软件包都是最新的。这可以通过以下命令完成:
```bash
sudo apt update
sudo apt upgrade
```
第一行命令`sudo apt update`会检查并更新软件源列表,而第二行命令`sudo apt upgrade`则会对系统中所有可升级的软件包进行升级。这一步骤不仅确保了系统稳定,也使得安装Python的环境更加干净。
## 2.2 通过官方源安装Python 3.9
### 2.2.1 配置软件源
Python 3.9的安装包可以通过Ubuntu官方软件源获得。首先,您需要添加包含Python 3.9的官方PPA(个人软件包存档)到您的系统中。以下是添加PPA并更新软件包列表的命令:
```bash
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
```
添加PPA后,系统会自动更新软件包列表。现在,您可以安装Python 3.9了。
### 2.2.2 下载和安装Python 3.9
接下来,通过以下命令安装Python 3.9:
```bash
sudo apt install python3.9
```
安装完成后,您可以通过输入`python3.9 --version`来验证Python 3.9是否正确安装。如果一切顺利,它应该会显示出类似于"Python 3.9.x"的版本信息,其中x代表具体的更新号。
在某些情况下,您可能需要设置Python 3.9为默认的Python版本。可以通过创建符号链接完成这一操作:
```bash
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.9 1
```
然后,您可以使用`update-alternatives`命令来管理多个Python版本,并设置默认版本:
```bash
sudo update-alternatives --config python3
```
接下来,系统会要求您选择一个版本作为默认的Python 3版本。选择适当的数字即可完成设置。
## 2.3 使用第三方工具安装Python 3.9
### 2.3.1 探索第三方安装工具
虽然通过官方PPA安装Python是推荐的方法,但有时候您可能需要使用第三方工具来安装或管理Python版本。一个常用的工具是`pyenv`,它允许您在同一系统中安装和切换多个版本的Python。
首先,您需要安装`pyenv`。可以通过以下命令安装:
```bash
curl https://pyenv.run | bash
```
安装完成后,添加`pyenv`的初始化脚本到您的shell配置文件中(比如`~/.bashrc`或`~/.zshrc`):
```bash
export PATH="$HOME/.pyenv/bin:$PATH"
eval "$(pyenv init --path)"
eval "$(pyenv virtualenv-init -)"
```
重新加载配置文件后,您就可以开始使用`pyenv`了。
### 2.3.2 安装过程详解与注意事项
使用`pyenv`安装Python 3.9的过程非常简单。首先,确保`pyenv`命令已经生效,然后运行:
```bash
pyenv install 3.9.0
```
请注意,在命令中使用确切的Python版本号,如本例中的"3.9.0"。安装完成后,设置该版本为全局默认Python:
```bash
pyenv global 3.9.0
```
使用第三方工具时,需要注意它们的维护状态和社区支持。`pyenv`通常更新维护得比较好,但是为了确保最佳兼容性和最新功能,建议使用稳定的版本,而不是直接从主分支安装最新开发中的代码。
在使用`pyenv`过程中,您可能会遇到需要安装Python构建依赖项的情况。这可以通过以下命令安装:
```bash
pyenv install --list
```
查看可用版本后,您可以针对特定版本安装所需的依赖:
```bash
sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev python-openssl git
```
以上列出的命令和步骤可以帮助您在Ubuntu系统中顺利安装Python 3.9。无论您选择通过官方PPA还是第三方工具`pyenv`安装,重要的是遵循每一步的详细说明,并根据系统情况适当调整。安装完成后,您就可以开始探索Python 3.9带来的新特性和改进了。
# 3. Python 3.9环境配置
#### 3.1 配置Python 3.9的环境变量
##### 3.1.1 理解环境变量的作用
环境变量是操作系统用于存储有关环境配置信息的变量。它们对程序执行环境至关重要,因为许多程序,尤其是命令行工具,会根据这些变量来配置它们的行为。在Python环境中,环境变量用于定义解释器的位置、库的位置以及项目的依赖关系等。
在Ubuntu系统中,环境变量通常存储在`/etc/environment`文件中,或者通过`~/.bashrc`(对于bash shell)或`~/.zshrc`(对于zsh shell)这样的用户级配置文件来设置。正确配置Python的环境变量,可以确保在任何目录下使用`python3.9`命令来启动Python解释器。
##### 3.1.2 设置和验证环境变量
设置Python 3.9环境变量通常需要更新系统环境变量,以便可以全局访问Python 3.9。以下是设置环境变量的步骤:
1. 打开终端。
2. 使用文本编辑器打开`~/.bashrc`文件(或相应的shell配置文件)。
3. 在文件的末尾添加以下行:
```bash
export PATH=$PATH:/usr/bin/python3.9
```
4. 保存并关闭文件。
5. 在终端中执行以下命令使更改生效:
```bash
source ~/.bashrc
```
为了验证Python 3.9环境变量是否已正确设置,可以执行以下命令:
```bash
which python3.9
```
如果一切配置正确,该命令应该返回Python 3.9解释器的路径。此外,可以通过运行`python3.9 --version`来确认安装的Python版本。
#### 3.2 创建和管理虚拟环境
##### 3.2.1 虚拟环境的概念和优势
虚拟环境是一种允许用户在隔离的环境中安装和管理Python包的工具。每个虚拟环境都包含自己的Python解释器,其包含的库和依赖关系与系统其他部分以及其他虚拟环境隔离。
使用虚拟环境的优势包括:
- **隔离性**:各个项目之间不会相互影响,可以使用不同版本的库。
- **灵活性**:可以在不同的虚拟环境中测试代码,而不会干扰到全局安装的Python。
- **可重复性**:可以确保所有开发者在相同条件下工作,有助于避免“在我的机器上可以运行”的问题。
##### 3.2.2 使用virtualenv和venv管理工具
在Python 3.9中,`venv`模块被用作创建虚拟环境的官方推荐工具。然而,对于更早的Python版本,`virtualenv`是一个广泛使用的第三方工具。以下是如何使用这两个工具来创建和管理虚拟环境的步骤:
**使用venv创建虚拟环境:**
1. 打开终端。
2. 使用以下命令创建一个新的虚拟环境(这里以`myenv`为例):
```bash
python3.9 -m venv myenv
```
3. 激活虚拟环境:
```bash
source myenv/bin/activate
```
一旦虚拟环境被激活,终端提示符通常会显示环境名称,表明你当前正在该虚拟环境中操作。
**使用virtualenv创建虚拟环境:**
1. 如果还没有安装`virtualenv`,可以使用以下命令安装:
```bash
pip install virtualenv
```
2. 创建虚拟环境:
```bash
virtualenv myenv
```
3. 激活虚拟环境:
```bash
source myenv/bin/activate
```
虚拟环境的使用流程相同,无论选择`venv`还是`virtualenv`。当完成开发工作后,可以通过以下命令停用虚拟环境:
```bash
deactivate
```
#### 3.3 Python包管理工具pip的使用
##### 3.3.1 pip的基本用法
`pip`是Python包安装和管理的默认工具。它提供了一个命令行界面,用于安装和管理Python包。在Python 3.9环境中使用pip的基本用法包括:
- 安装包:
```bash
pip install package-name
```
- 升级包:
```bash
pip install --upgrade package-name
```
- 卸载包:
```bash
pip uninstall package-name
```
- 搜索包:
```bash
pip search package-name
```
- 查看已安装的包:
```bash
pip list
```
##### 3.3.2 高级包管理技巧和故障排除
在使用pip时,可能会遇到一些问题,比如权限错误、包依赖冲突等。以下是一些高级的包管理技巧和故障排除方法:
1. **使用用户模式安装包以避免权限错误**:
```bash
pip install --user package-name
```
2. **使用requirements.txt文件管理依赖**:
创建一个名为`requirements.txt`的文件,列出所有依赖的包及其版本号:
```
package-name==1.2.3
another-package>=4.5.6
```
然后,通过以下命令安装所有依赖:
```bash
pip install -r requirements.txt
```
3. **解决包依赖冲突**:
当安装某个包时,如果它依赖的另一个包与已安装的版本不兼容,pip会报错。可以使用以下命令强制pip忽略已安装的版本:
```bash
pip install --ignore-installed package-name
```
4. **使用国内镜像源加快下载速度**:
有时pip默认的PyPI源下载速度较慢,可以切换到国内的镜像源,例如清华大学的镜像源:
```bash
pip install package-name -i https://pypi.tuna.tsinghua.edu.cn/simple
```
通过掌握这些技巧,你可以更加高效和安全地管理Python项目中的依赖和包。
# 4. Python 3.9编程实践基础
随着我们对Ubuntu和Python有了一个初步的了解,并在系统上安装和配置了Python 3.9环境之后,现在我们进入Python编程实践的阶段。第四章是学习Python 3.9编程实践的基础部分,旨在帮助读者掌握Python基础语法、模块和包的使用,以及函数编程的概念和技术。
## 4.1 Python 3.9基础语法介绍
Python被誉为易读性极高的编程语言,其基础语法简洁明了,非常适合初学者入门。接下来我们逐步深入了解Python的基础语法。
### 4.1.1 数据类型和变量
Python是一种动态类型的语言,这意味着你在定义变量时不需要显式声明变量的数据类型。Python会根据变量的值来推断其类型。
- 整型(int):用于表示整数,例如 `1, 2, 1000`。
- 浮点型(float):用于表示小数,例如 `1.23, 3.14`。
- 字符串(str):用于表示文本数据,例如 `"hello", "Python 3.9"`。
- 列表(list):用于表示有序的元素集合,可以包含不同的数据类型。
- 元组(tuple):用于表示不可变的有序集合。
- 字典(dict):用于表示键值对集合,通过键来存储和获取值。
变量的定义非常简单,只需要指定变量名并赋予值即可:
```python
# 整型变量
a = 10
# 浮点型变量
b = 20.5
# 字符串变量
c = "Hello, Python 3.9!"
# 列表变量
d = [1, 2, 3]
# 元组变量
e = (1, 2, 3)
# 字典变量
f = {'name': 'Alice', 'age': 25}
```
Python中的变量在赋值后自动推断类型,不需要声明。一个变量可以随时改变其类型,这是Python灵活性的一个体现。
### 4.1.2 控制流结构
控制流结构是程序中用来控制语句执行顺序的语句。Python提供了多种控制流语句,包括但不限于`if`语句、`for`循环、`while`循环等。
- `if`语句用于执行条件分支。
```python
if condition:
# 如果condition为真,则执行这里的代码
pass
else:
# 如果condition为假,则执行这里的代码
pass
```
- `for`循环用于遍历序列,比如列表或字符串。
```python
fruits = ['apple', 'banana', 'cherry']
for fruit in fruits:
print(fruit)
```
- `while`循环用于在条件满足时重复执行代码块。
```python
i = 0
while i < 5:
print(i)
i += 1
```
在这些控制流结构中,`break`和`continue`语句可以用来中断循环。`break`语句完全结束循环,而`continue`语句跳过当前循环的剩余部分,开始下一次迭代。
### 代码解释与逻辑分析
在本节中,我们介绍了Python的基础语法元素,包括数据类型、变量、以及控制流结构。通过示例代码,我们展示了如何定义变量、使用基本数据类型以及执行程序的逻辑分支和循环。示例中的`if`语句用来判断一个条件是否成立,并根据条件的真假执行不同的代码块。`for`循环用来遍历一个序列(在本例中为一个列表),而`while`循环则用来重复执行一段代码,直到某个条件不再满足。
在后续的章节中,我们将深入探讨更多的Python编程概念和高级特性,这将为我们解决实际问题打下坚实的基础。现在,读者应该能够理解并编写基本的Python程序,这将为深入学习Python打下良好的起点。
# 5. Python 3.9高级应用技巧
## 5.1 Python 3.9面向对象编程
Python是一种面向对象的编程语言。面向对象编程(OOP)是一种编程范式,它使用“对象”来设计应用程序。对象包含数据(属性)和行为(方法)。在Python中,几乎一切都是对象,包括字符串、数字、函数、模块、类等。
### 5.1.1 类和对象的理解
在Python中,类可以看作是创建对象的蓝图或模板。类定义了创建对象时所必须包含的属性和方法。对象是根据类定义创建的实例。
以下是一个简单的类定义和对象创建的例子:
```python
class Car:
def __init__(self, make, model):
self.make = make
self.model = model
def display_info(self):
return f"This car is a {self.make} {self.model}"
my_car = Car("Toyota", "Corolla")
print(my_car.display_info())
```
在这段代码中,`Car`类有两个属性:`make`和`model`,以及一个方法`display_info`。`__init__`方法是一个特殊的方法,它在创建新对象时自动调用,用于初始化对象的状态。`my_car`是我们创建的`Car`类的一个实例。
### 5.1.2 继承、多态和封装
继承是面向对象编程的一个核心概念,它允许一个类(子类)继承另一个类(父类)的属性和方法。子类可以扩展或重写父类的方法,以实现特定的功能。
多态允许你使用父类的引用指向子类的实例,并调用相同的方法得到不同结果。这意味着子类可以提供父类方法的特殊实现。
封装是将数据(属性)和操作数据的代码(方法)绑定在一起的机制,它可以隐藏对象的内部状态,只通过定义的方法访问数据。
下面的代码示例展示了继承和多态的使用:
```python
class ElectricCar(Car):
def __init__(self, make, model, battery_size):
super().__init__(make, model)
self.battery_size = battery_size
def display_info(self):
return f"{super().display_info()} with a battery size of {self.battery_size} kWh"
my_electric_car = ElectricCar("Tesla", "Model S", 100)
print(my_electric_car.display_info())
```
在上述例子中,`ElectricCar`类继承自`Car`类,并添加了一个新的属性`battery_size`。重写了`display_info`方法以包括电池大小信息。当我们调用`display_info`方法时,我们可以看到多态性的体现,即尽管`my_electric_car`是一个`ElectricCar`实例,调用的方法却是从父类`Car`继承而来。
封装通过使用私有属性和方法(通常使用两个下划线`__`开头)来实现,保护对象不被外部直接访问或修改。例如:
```python
class SecureCar(Car):
def __init__(self, make, model):
self.make = make
self.__model = model # 私有属性
def display_info(self):
return f"This car is a {self.make} {self.__model}"
def get_model(self):
return self.__model
car = SecureCar("BMW", "X5")
print(car.display_info())
print(car.get_model())
```
在这个例子中,`__model`是一个私有属性,不能从类的外部直接访问。`get_model`方法用于安全地提供模型信息。
面向对象编程的高级应用技巧还包括使用特殊的属性和方法,如`__slots__`、`__getattribute__`、`__setattr__`等,这些高级特性可以用来精细控制类的属性访问和行为。
## 5.2 异常处理和文件操作
### 5.2.1 处理程序中的错误和异常
程序运行时可能会遇到各种错误或异常情况,例如除以零、文件不存在等。Python通过异常处理机制来处理这类问题,使得程序可以优雅地处理错误。
Python使用`try...except`语句来捕获和处理异常。`try`块中的代码如果发生异常,会跳过后续的代码执行,转到`except`块中处理。如果`try`块中的代码没有异常,那么`except`块将被忽略。
下面是一个简单的异常处理示例:
```python
try:
result = 10 / 0
except ZeroDivisionError:
print("You can't divide by zero!")
else:
print(f"Result: {result}")
finally:
print("This is executed regardless of whether an exception occurs.")
```
在这个例子中,如果除数为零,`ZeroDivisionError`异常将被捕获,并打印出相应的消息。`else`块在`try`块没有异常发生时执行,而`finally`块无论是否发生异常都会执行。
### 5.2.2 文件和目录的I/O操作
Python提供了内置的文件操作方法,允许你读取文件内容到程序中,或者将数据写入文件保存。文件操作是许多应用程序不可或缺的一部分。
#### 文件读取
```python
with open('example.txt', 'r') as file:
content = file.read()
print(content)
```
上述代码使用`with`语句以只读模式打开一个名为`example.txt`的文件。`with`语句确保文件会在使用后正确关闭。`read()`方法读取文件的全部内容,并将其存储在变量`content`中。
#### 文件写入
```python
with open('output.txt', 'w') as file:
file.write('Hello, Python!\n')
```
这段代码以写入模式打开(或创建)一个名为`output.txt`的文件。如果文件已存在,其内容将被覆盖。`write()`方法将字符串写入文件。
#### 目录操作
目录操作通常使用`os`模块来完成。以下是一个遍历目录中的文件的例子:
```python
import os
directory = 'some_directory'
if os.path.exists(directory) and os.path.isdir(directory):
for filename in os.listdir(directory):
print(filename)
else:
print(f"The specified directory does not exist.")
```
这里,`os.path.exists()`检查给定路径是否存在,`os.path.isdir()`检查是否为目录。`os.listdir()`列出目录中的所有文件名。
## 5.3 Python 3.9的并发编程
### 5.3.1 进程和线程的基础
并发编程允许程序同时进行多个任务,提高效率和响应速度。Python通过`multiprocessing`和`threading`模块支持进程和线程。
#### 进程
进程是程序的一次执行。在操作系统中,每个进程都有自己的地址空间、内存和其他资源。在Python中,可以使用`multiprocessing`模块创建多个进程。
```python
import multiprocessing
def print_number(number):
print(number)
if __name__ == '__main__':
processes = []
for i in range(5):
process = multiprocessing.Process(target=print_number, args=(i,))
processes.append(process)
process.start()
for process in processes:
process.join()
```
上面的例子创建了5个进程,每个进程打印一个数字。
#### 线程
线程是程序中的执行流。线程共享进程的资源,因此它们比进程更轻量级。Python中创建线程可以使用`threading`模块。
```python
import threading
def print_number(number):
print(number)
if __name__ == '__main__':
threads = []
for i in range(5):
thread = threading.Thread(target=print_number, args=(i,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
```
这里创建了5个线程,每个线程同样是打印一个数字。
### 5.3.2 异步编程和asyncio
异步编程允许程序在等待操作完成时继续执行其他任务。Python 3.5中引入了`async`和`await`关键字来支持异步编程。`asyncio`模块提供了一种实现异步I/O密集型程序的方法。
```python
import asyncio
async def count():
print("One")
await asyncio.sleep(1)
print("Two")
async def main():
await asyncio.gather(count(), count(), count())
asyncio.run(main())
```
在这个例子中,`count`函数是一个异步函数,它执行打印任务和等待操作。`main`函数并发地运行3个`count`函数。`asyncio.gather`确保所有任务都被启动,并等待它们全部完成。
Python的异步编程使得开发网络服务、数据库交互以及其他I/O密集型应用时能更有效地利用资源,尤其在高并发场景下可以显著提高性能。
以上章节中介绍的内容,分别涵盖了面向对象编程中的类与对象、继承、多态、封装等概念,异常处理的基本使用,以及进程、线程和异步编程的基础知识。这些高级应用技巧在构建复杂应用时,能够帮助开发者编写出结构良好、可维护性强且效率更高的代码。
# 6. Python 3.9项目实战
## 6.1 构建Python Web项目
当我们深入Python的高级应用领域时,构建Web项目成为一个重要的实践方向。一个现代的Web项目通常需要一个成熟的框架来提供强大的后端支持,而Python在这方面具有多种选择,包括Flask、Django等。
### 6.1.1 选择合适的Web框架
选择Web框架时,需要考虑项目的复杂度、开发效率、可扩展性等因素。例如:
- **Flask**:轻量级框架,适合快速开发小型项目或API服务。
- **Django**:全功能框架,自带ORM系统,适合大型项目,遵循MVC架构。
在这个实战部分,我们选择Flask进行实战项目搭建,因为它简单易学且灵活。
### 6.1.2 项目搭建和部署
创建Flask Web项目的步骤相对简单,但需要几个关键步骤来确保一切就绪。下面是一个基本的项目搭建和部署流程:
1. 安装Flask:
```bash
pip install Flask
```
2. 创建一个名为 `app.py` 的Python文件,用于存放Web应用程序代码:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def home():
return 'Hello, World!'
if __name__ == '__main__':
app.run(debug=True)
```
3. 运行应用程序:
```bash
python app.py
```
此时,你的Web服务将在默认的5000端口上运行。你可以在浏览器中访问 `http://127.0.0.1:5000` 来看到 "Hello, World!" 的输出。
4. 部署到服务器:你可以使用WSGI服务器如Gunicorn来部署你的应用到生产环境,例如:
```bash
gunicorn -w 4 app:app
```
5. 使用Nginx作为反向代理服务器来托管你的应用,如下所示的Nginx配置示例(`/etc/nginx/sites-available/app`):
```nginx
server {
listen 80;
server_name example.com;
location / {
include proxy_params;
proxy_pass http://unix:/run/gunicorn.sock;
}
}
```
最后,重新加载Nginx配置文件来启用新配置,并确保你的域名指向了部署应用的服务器IP地址。
## 6.2 数据分析与可视化实战
Python在数据分析和可视化领域也有着强大的工具,如Pandas、NumPy、SciPy和Matplotlib等。
### 6.2.1 利用pandas处理数据
Pandas是数据分析最重要的库之一,它提供了快速、灵活和表达能力强的数据结构,专门设计用来处理表格和时间序列数据。
#### Pandas基本使用
1. 安装Pandas:
```bash
pip install pandas
```
2. 使用Pandas读取CSV文件:
```python
import pandas as pd
data = pd.read_csv('data.csv')
```
3. 数据筛选:
```python
filtered_data = data[data['column_name'] > value]
```
4. 数据聚合:
```python
aggregated_data = data.groupby('column_name').agg(['mean', 'sum'])
```
### 6.2.2 使用matplotlib进行数据可视化
Matplotlib是一个用于创建静态、动画和交互式可视化的Python库。它能够生成图表、直方图、功率谱、条形图、误差图、散点图等。
#### Matplotlib基本使用
1. 安装Matplotlib:
```bash
pip install matplotlib
```
2. 创建简单的折线图:
```python
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4], [10, 20, 30, 40])
plt.xlabel('x axis label')
plt.ylabel('y axis label')
plt.title('Simple Plot')
plt.show()
```
3. 创建条形图:
```python
plt.bar(['A', 'B', 'C', 'D'], [10, 20, 30, 40])
plt.show()
```
4. 子图绘制:
```python
fig, axs = plt.subplots(1, 2) # 创建一个1行2列的子图布局
axs[0].plot([1, 2, 3], [10, 20, 30])
axs[1].bar(['A', 'B', 'C'], [10, 20, 30])
plt.show()
```
## 6.3 Python在DevOps中的应用
Python不仅适用于数据分析和Web开发,而且它在DevOps领域也越来越受欢迎,特别是在脚本编写和自动化任务中。
### 6.3.1 自动化脚本编写
Python脚本可以用于自动化各种DevOps任务,从环境配置到部署和监控。Python的简洁语法和强大的库支持使得编写自动化脚本变得简单高效。
#### 示例:使用Fabric进行自动化部署
1. 安装Fabric:
```bash
pip install fabric
```
2. 创建一个简单的Fabric脚本(`fabfile.py`),用于部署应用:
```python
from fabric import task
@task
def deploy():
local('git pull') # 获取最新的代码
local('python3 manage.py migrate') # 运行数据库迁移
local('python3 manage.py collectstatic --noinput') # 静态文件收集
local('gunicorn -w 4 myproject.wsgi:application') # 运行应用
```
3. 运行部署命令:
```bash
fab deploy
```
### 6.3.2 配置管理工具的应用
Python是许多流行的配置管理工具的首选语言,如Ansible,它允许用户使用Python编写剧本(playbooks),自动化配置和管理任务。
#### 示例:使用Ansible管理服务器配置
1. 安装Ansible:
```bash
pip install ansible
```
2. 创建一个Ansible剧本(`deploy.yml`),用于安装并配置Web服务器:
```yaml
- name: Configure Web Server
hosts: webservers
become: yes
tasks:
- name: Install Nginx
apt:
name: nginx
state: latest
- name: Start Nginx
service:
name: nginx
state: started
enabled: yes
```
3. 运行Ansible剧本:
```bash
ansible-playbook deploy.yml
```
通过这些步骤,我们可以看到Python不仅能够用于编写业务逻辑代码,而且它在自动化和DevOps中的应用也是十分广泛和强大的。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【阀门流量测试方法:标准测试与数据分析】
# 摘要
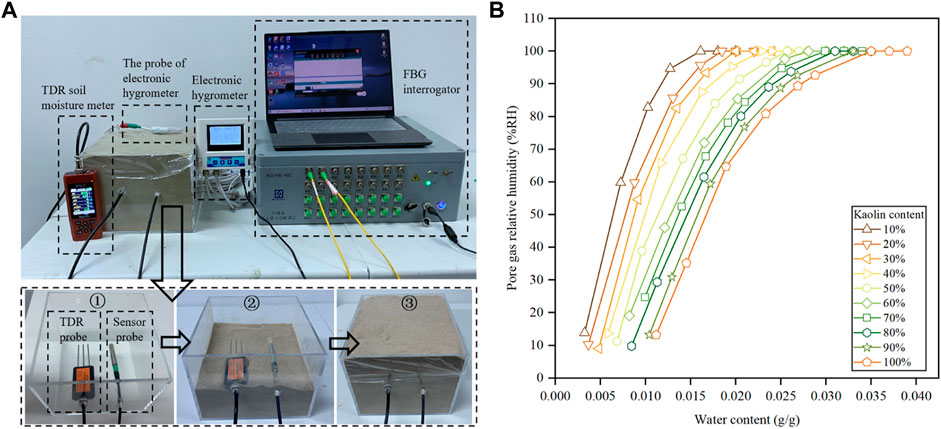
本文系统地介绍了阀门流量测试的基础知识、标准测试流程、数据分析方法和工具以及自动化与智能化的发展趋势。首先,本文阐述了阀门流量测试的理论和实践,重点探讨了国际和国内的标准规范、测试参数的选择、测试设备的种类和校准流程。随后,文章深入分析了数据分析的理论基础、工具应用、测试结果的分析与解释。案例研究部分具体展示了一个典型阀门测试的全流程,包括测试
16位快速加法器逻辑深度解析:电路设计大师的秘传心法

# 摘要
本文介绍了16位快速加法器的概念、理论基础、设计实现以及高级技术。首先概述了16位快速加法器的重要性和应用背景。接着,详细阐述了其理论基础,包括二进制加法原理、快速加法器工作原理及其设计挑战。第三章重点介绍了16位快速加法器的设计实现,探讨了电路设计工具、核心算法实现和电路图的模拟测试。第四章深入探讨了高级技术,如进位生成与传递的优化技巧和快速加法器的变种技术。最后,分析了16位快速加法器的未来发展趋势和在现
MATLAB教程升级版:控制系统中传递函数与状态空间模型的灵活应用策略

# 摘要
本文从控制系统的基础知识讲起,详细介绍了MATLAB在控制系统设计与分析中的应用。章节首先回顾了控制系统的基本概念和MATLAB软件的基础知识。接着,深入探讨了传递函数的理论基础和在MATLAB中的实现,包括系统稳定性分析和频域分析等。然后,文章转向状态空间模型的理论和MATLAB表达,涉及模型构建、转换和系统设计应用。第四章将传递函数和状态空间模型结合起来,讨论了联合应用
【图算法专家速成】:《数据结构习题集》中的图问题与详细解答

# 摘要
图算法作为计算机科学与数学领域中的基础理论,是解决复杂网络问题的关键技术。本文系统性地梳理了图算法的基础理论,并详细解读了多种图的遍历算法,包括深度
从零开始到项目管理大师:Abaqus CAE界面创建与管理技巧

# 摘要
本文旨在详细介绍Abaqus CAE这一先进的仿真软件,包括其界面布局、交互方式、项目管理、建模技巧、分析流程以及高级功能。文章从基础设置开始,逐步深入到界面元素定制、文件管理、视图控制以及交互式建模和分析。随后,本文深入探讨了分析步骤的定义、边界条件的设定、后处
硬件连接不再难:STM32与CAN总线配置详解

# 摘要
本文旨在为技术人员提供关于STM32微控制器与CAN总线集成的全面指南。首先概述了STM32和CAN总线的基本概念,然后深入探讨了CAN总线协议的技术基础、数据帧结构和错误处理机制。接着,文章详细介绍了STM32微控制器的基础知识、开发环境的搭建以及固件库和中间
Stata绘图高级技巧:掌握创建复杂统计与交互式图表的专家秘籍
# 摘要
本文详细介绍了Stata软件在数据可视化方面的应用,包括绘图基础、高级应用以及与其他工具的集成。文章首先提供了一个Stata绘图的基础概览,并深入探讨了其绘图语法的结构与元素。接着,文章深入讲解了统计图表的高级应用,如复杂数据的图形表示、交互式图表的创建,以及图表的动态更新与演示。此外,还通过实战演练展示了真实数据集的图形
森兰SB70变频器控制原理深度解析:技术内幕与应用技巧

# 摘要
本文详细介绍了森兰SB70变频器的全面信息,包括其工作原理、核心技术、实际应用案例以及高级编程与应用。首先概述了变频器的基本功能和控制原理,强调了SPWM技术和矢量控制对性能优化的重要性。随后,文章探讨了变频器在工业驱动系统中的应用,如负载特性分析和节能效益评估。此外,文中还涉及了变频器的参数配置、调试维护、网络控制以及与PLC的集成应用。案例分析部分提供了特定行业应用的深入分析和问题解决策略。最后
机器人路径规划解题秘籍:掌握算法,轻松应对课后挑战

# 摘要
本文系统地探讨了机器人路径规划的基础理论、算法详解、优化策略以及实践案例,并展望了未来的技术挑战和应用前景。首先介绍了路径规划的基本概念,然后深入
VME总线技术深度解析:掌握64位VME协议的关键5要素

# 摘要
VME总线技术作为嵌入式系统领域的重要标准,经历了多年的发展,依然在多个行业中扮演着关键角色。本文首先对VME总线技术进行了概述,详细介绍了64位VME协议的物理和电气特性,包括连接器和插槽设计,以及信号完整性和电气规范。随后,重点分析了VME总线的关键技术组件,如地址空间、数据传输协议和中断机制。文章进一步探讨了VME总线在现代嵌入式系统中的应用,特别是在实时系统和军事航空电子领域中的重要性和应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )