




R语言矩阵运算指南:多维数据处理与应用


基于MATLAB的风光氢多主体能源系统合作运行:纳什谈判与ADMM算法的应用
摘要
R语言作为一种优秀的统计计算工具,在矩阵运算方面具有强大的功能和灵活性。本文从基础到高级,全面介绍了R语言在矩阵运算中的关键技术和实践应用。章节一和二为读者提供了矩阵运算的基础知识,涵盖矩阵和数组的创建、操作以及向量化技术。随着章节的深入,本文详细探讨了特殊矩阵的构造、矩阵分解技术和高维数组的处理技巧,这些都是R语言在数据分析、机器学习和图像处理等领域的重要应用。最后,本文还探讨了矩阵运算的性能优化和提升,包括性能分析、并行计算框架的运用以及高性能计算库的应用,旨在帮助读者更好地进行复杂数据的矩阵运算和分析工作。
关键字
R语言;矩阵运算;多维数据处理;向量化;矩阵分解;高性能计算
参考资源链接:R语言实现SPEI指标与SPI、ET0干旱指数计算
1. R语言矩阵运算基础
在数据科学和统计分析中,矩阵运算是一项基础而核心的技能。R语言作为专为统计分析设计的编程语言,自然对矩阵运算提供了强大而灵活的支持。本章将带领读者了解R语言中矩阵运算的基本概念,包括如何创建和操作矩阵,以及进行基础的矩阵计算。
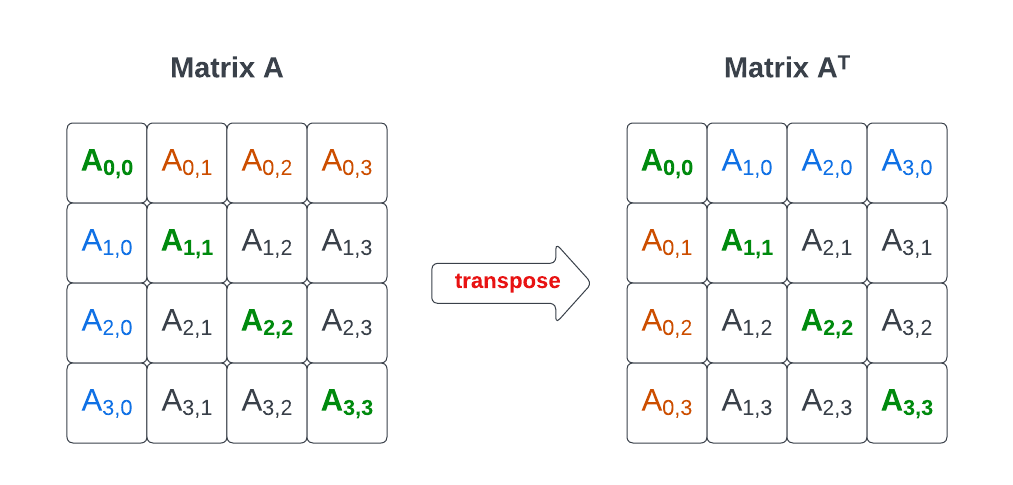
首先,我们将学习如何创建矩阵,包括使用matrix()函数定义矩阵的行和列,以及如何将数据向量转换为矩阵格式。之后,我们会详细探讨矩阵的基本操作,如提取子矩阵、转置矩阵以及矩阵的行列操作等。掌握这些基础操作对于后续章节中讨论更高级的矩阵运算和数据分析至关重要。
- # 创建一个3x3的矩阵示例
- m <- matrix(1:9, nrow = 3, ncol = 3)
- print(m)
- # 提取子矩阵
- sub_matrix <- m[2:3, 1:2]
- print(sub_matrix)
- # 矩阵转置
- transpose_m <- t(m)
- print(transpose_m)
通过这些基本的代码示例,我们可以看到R语言在矩阵运算上的简洁和直观性。下一章中,我们将继续深入探讨R语言中多维数据的处理和向量化操作,进一步解锁R语言在数据分析中的强大能力。
2. R语言中的多维数据处理
2.1 矩阵和数组的创建与操作
2.1.1 矩阵和数组的基本创建方法
在R语言中,矩阵(matrix)和数组(array)是进行多维数据处理的基础数据结构。矩阵是二维的,而数组可以是多维的。创建这些结构的基本方法之一是使用matrix()和array()函数。
以下是一个创建矩阵的示例代码:
- # 创建一个3x3的矩阵,包含1到9的数字
- matrix_data <- matrix(1:9, nrow = 3, ncol = 3)
- print(matrix_data)
此代码创建了一个3行3列的矩阵,并以列主序的方式填充了1到9的整数。类似的,我们使用array()函数来创建数组:
- # 创建一个数组,其维度为2x3x2,同样使用1到12的数字填充
- array_data <- array(1:12, dim = c(2, 3, 2))
- print(array_data)
dim参数允许我们指定数组的维度。在这个例子中,我们创建了一个二维数组,其维度为2行3列,且具有2个“层”。在R语言中,数组的维度通过dim参数传递给一个整数向量来指定,向量中的每个元素对应一个维度。
2.1.2 矩阵和数组的索引与切片
一旦创建了矩阵或数组,我们经常需要根据索引来访问或修改其元素。R语言中的索引从1开始,这是值得注意的一点,因为许多编程语言都是从0开始。
索引矩阵的一个简单例子:
- # 索引特定位置的元素
- element <- matrix_data[2, 3] # 获取矩阵中第2行第3列的元素
- print(element)
我们可以使用切片操作来获取矩阵或数组的一部分:
- # 获取矩阵的第二行
- row_slice <- matrix_data[2, ]
- print(row_slice)
- # 获取数组的第二层
- array_slice <- array_data[ , , 2]
- print(array_slice)
2.1.3 矩阵和数组的维度调整
有时候需要调整矩阵或数组的维度。在R中,可以使用dim()函数对矩阵的维度进行调整,而数组可以通过dim()函数直接修改其维度属性。
- # 改变矩阵的维度
- dim(matrix_data) <- c(9, 1)
- print(matrix_data)
- # 添加数组的新维度
- dim(array_data) <- c(2, 3, 2, 1)
- print(array_data)
这些调整允许矩阵和数组在多维数据处理中变得更加灵活,以适应不同的数据结构和分析需求。
要深入理解矩阵和数组的操作,需要记住几个关键点。首先是理解维度和索引的概念,这有助于快速准确地访问和操作数据。其次是实际运用,通过编写代码来处理不同的数据结构,这对于R语言中多维数据处理的掌握至关重要。
2.2 R语言中的向量化操作
2.2.1 向量化操作的优势
向量化是R语言中一种强大的数据操作方式,与传统的循环操作相比,它可以显著提高代码的执行效率。向量化操作是对整个向量或矩阵进行计算,而不需要使用显式循环。这意味着,R内部可以优化这些操作,从而执行得更快。
考虑一个向量加法的例子:
- # 创建两个长度相同的向量
- vector_a <- 1:10
- vector_b <- 10:1
- # 使用循环进行向量加法
- sum_loop <- numeric(length(vector_a))
- for (i in seq_along(vector_a)) {
- sum_loop[i] <- vector_a[i] + vector_b[i]
- }
- # 使用向量化进行向量加法
- sum_vectorized <- vector_a + vector_b
- # 比较两种方法的结果和执行时间
- identical(sum_loop, sum_vectorized) # 应该返回 TRUE
使用microbenchmark包可以比较循环和向量化操作的性能:
- # 需要先安装microbenchmark包
- library(microbenchmark)
- microbenchmark(
- loop = for (i in seq_along(vector_a)) {vector_a[i] + vector_b[i]},
- vectorized = vector_a + vector_b,
- times = 100
- )
通常,你会观察到向量化操作的速度远远超过循环操作,特别是在处理大规模数据时。
2.2.2 向量化的矩阵运算示例
向量化在矩阵运算中同样适用。考虑矩阵乘法:

2.2.3 向量化与循环运算的性能比较
在R中,向量化的优势不仅体现在代码的简洁性上,还体现在执行效率上。通过使用microbenchmark包,我们可以比较向量化和循环操作的性能差异:
- # 需要先安装microbenchmark包
- library(microbenchmark)
- microbenchmark(
- loop = {
- # 这里放置循环代码
- },
- vectorized = {
- # 这里放置向量化代码
- },
- times = 100
- )
在大多数情况下,向量化操作的执行时间会明显短于循环操作。
向量化操作是R语言中进行高效数据分析的关键技术之一。熟练掌握向量化的概念和应用对于提升数据处理和分析能力是必不可少的。通过实际示例,我们可以看到向量化不仅简化了代码,还极大地提高了程序的执行效率。
2.3 矩阵运算在数据分析中的应用
2.3.1 数据预处理中的矩阵应用
矩阵在数据预处理阶段发挥着重要作用,尤其是在处理和准备结构化数据以供分析时。一种常见的用例是处理缺失值。在R中,可以使用矩阵操作来快速识别和处理这些缺失值。
- # 创建一个含有缺失值的矩阵
- matrix_wi

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
 百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
【精准测试】:确保分层数据流图准确性的完整测试方法
Cygwin系统监控指南:性能监控与资源管理的7大要点
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
【T-Box能源管理】:智能化节电解决方案详解
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方


专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















