【异常点检测神技】:Seadas异常值检测,数据清洁无瑕!
发布时间: 2024-12-15 04:57:34 阅读量: 1 订阅数: 4 

seadas:SeaDAS SeaWiFS数据分析系统

参考资源链接:[SeaDAS海洋遥感软件操作指南与支持传感器详解](https://wenku.csdn.net/doc/47uh3928zr?spm=1055.2635.3001.10343)
# 1. 异常点检测与数据清洁概述
## 1.1 异常点检测的重要性
在数据科学领域,异常点检测是一种常见的数据清洗技术,用于识别和处理数据集中的非典型值或离群点。正确地识别这些异常点对于数据预处理和后续分析至关重要,因为它们可能代表错误、噪声,或者重要的、需要进一步分析的信息。
## 1.2 数据清洁的作用和目标
数据清洁是确保数据分析准确性和可靠性的基础。通过异常点检测和处理,数据清洁旨在移除或修正数据集中的不一致性、重复项、缺失值和离群值。最终目标是提高数据质量,以便为数据分析、机器学习模型构建和决策支持提供准确、可信的数据基础。
## 1.3 异常点检测的方法和挑战
检测异常点的方法多种多样,从统计方法到机器学习算法,从简单阈值比较到复杂模式识别。选择合适的检测方法要基于数据的类型、结构和分析需求。在实际操作中,面临的挑战包括如何平衡检测的准确性与计算成本,如何处理高维数据,以及如何在大规模数据集中有效执行。随着技术的不断进步,这些问题正在得到解决,同时推动了异常点检测技术的发展。
# 2. Seadas异常值检测基础
## 2.1 Seadas异常值检测原理
### 2.1.1 异常值的定义和分类
异常值,也称为离群点,是指在数据集中与其它数据明显不一致的观测值。在数据分析、数据挖掘和统计学中,识别和处理异常值是一项重要任务,因为异常值可能导致错误的结论或决策。异常值可以被分类为以下几种:
- **全局异常值**:在全数据集中显著偏离其它数据点的值。
- **上下文异常值**:在一个数据集的特定上下文中是异常的值,但在其他上下文中可能不被看作是异常。
- **集体异常值**:一组数据点作为一个整体时偏离了总体分布。
### 2.1.2 Seadas算法的工作机制
Seadas算法是一种基于密度的异常值检测方法。它通过度量数据点周围的邻域密度来工作,密度远离其他点的数据点被判定为异常值。Seadas的核心步骤如下:
1. **确定邻域半径**:首先选择一个半径参数,用于确定数据点周围的邻域。
2. **计算密度**:计算每个数据点的密度,密度是根据邻域内数据点的数量和距离来确定的。
3. **识别异常值**:在密度分布的基础上,找到密度较低的数据点,这些点被认为是异常值。
Seadas算法的精髓在于其对密度的考虑,它允许识别出局部异常值,即那些仅在局部区域显著偏离的数据点。算法还具有无需预先知道异常值个数的优势,能够灵活地应用于各种数据分布。
## 2.2 Seadas工具和环境配置
### 2.2.1 安装Seadas及其依赖
为了使用Seadas,需要在计算环境中安装Seadas以及其依赖的库。以下是在常见的Linux环境下安装Seadas和依赖的基本步骤:
1. 安装依赖库:
```bash
sudo apt-get install python3-pandas python3-numpy
```
2. 从GitHub克隆Seadas的源代码仓库:
```bash
git clone https://github.com/Seadas/Seadas.git
cd Seadas
```
3. 安装Seadas:
```bash
python3 setup.py install
```
在安装过程中,需要确保Python环境以及其依赖库已正确安装,且版本满足Seadas的要求。
### 2.2.2 配置运行环境和参数
为了确保Seadas能够顺畅运行,需要配置其运行环境以及参数。以下示例中,我们定义了运行Seadas时必须指定的一些关键参数:
1. **设置环境变量**:根据Seadas的安装路径,设置必要的环境变量。
```bash
export PATH=$PATH:/path/to/Seadas/bin
```
2. **配置参数文件**:通常Seadas的参数设置可以通过一个配置文件来完成,例如`config.yaml`:
```yaml
radius: 0.1 # 定义邻域半径
min_points: 5 # 最小邻域点数
```
3. **运行Seadas**:使用配置好的参数文件运行Seadas,进行异常值检测:
```bash
Seadas --config config.yaml
```
在配置过程中,根据数据的特性以及用户的分析需求,可能需要调整各种参数以获得最佳的检测效果。
## 2.3 Seadas的基本操作流程
### 2.3.1 数据导入和预处理
Seadas支持多种数据格式导入,包括CSV、JSON、Pandas DataFrame等。数据导入后,通常需要进行一些预处理步骤来确保数据质量和一致性。预处理步骤可能包括数据清洗、数据类型转换、异常值的初步筛选等。
以下是一个数据导入和预处理的代码示例:
```python
import pandas as pd
from Seadas import SeadasDetector
# 加载数据集
df = pd.read_csv('data.csv')
# 数据预处理:去除缺失值
df.dropna(inplace=True)
# 预处理:数据类型转换,确保数据为数值类型
df = df.apply(pd.to_numeric)
# 应用Seadas算法进行异常值检测
detector = SeadasDetector(radius=0.1)
detector.fit(df)
```
在这个过程中,`dropna`和`apply`函数被用来去除数据集中的缺失值并转换数据类型,以提高Seadas算法的检测效率和准确性。
### 2.3.2 检测流程和结果分析
异常值检测流程主要分为三个步骤:模型训练、异常值判定以及结果评估。Seadas算法需要先进行模型训练,即通过输入的数据集来学习数据分布。然后,Seadas算法将数据点分类为正常值或异常值。
以下是一个异常值检测流程的代码示例:
```python
# 对数据集进行异常检测
df['is_outlier'] = detector.predict()
# 结果分析
outliers = df[df['is_outlier'] == 1]
print("Detected outliers:")
print(outliers)
```
在此代码段中,`detector.predict()`方法用于对数据集中的每个点进行预测,输出是否为异常值。通过分析`df['is_outlier']`列,我们可以获得异常点的详细信息,并进一步进行分析或处理。
通过这一系列操作,Seadas提供了一种高效且准确的方式来识别数据中的异常值,并为数据集的质量提升提供支持。
# 3. Seadas异常值检测深入实践
## 3.1 针对不同数据类型的检测策略
### 3.1.1 时序数据的异常点检测
时序数据的异常点检测在金融

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Fluent安装与配置全攻略】:第三章深入详解与最佳实践

参考资源链接:[Fluent 中文帮助文档(1-28章)完整版 精心整理](https://wenku.csdn.net/doc/6412b6cbbe7fbd1778d
【信号完整性与布线】:等长布线的原理与实践,专家级分析
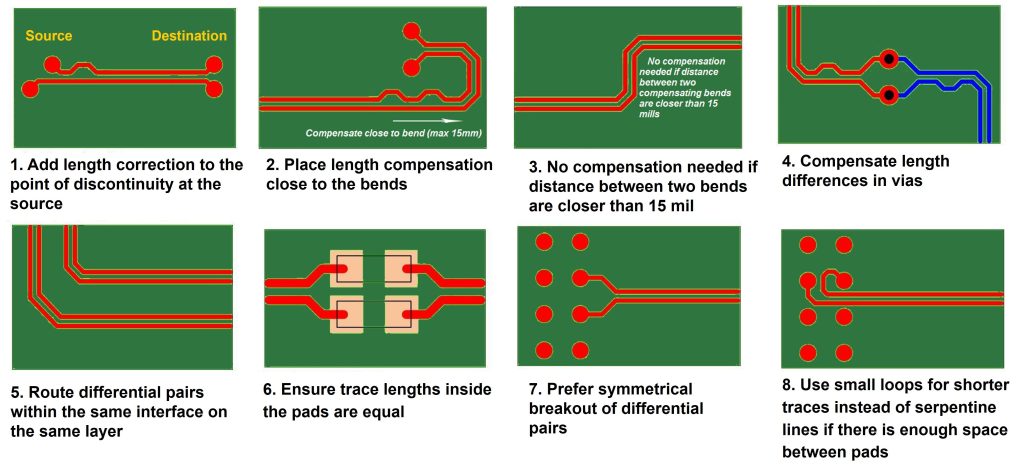
参考资源链接:[PCIe/SATA/USB布线规范:对内等长与延迟优化](https://wenku.csdn.net/doc/6412b727be7fbd1778d49479?spm=1055.2635.3001.10343)
# 1. 信号完整性与布线基础
## 1.1 信号完整性简介
在高速数
WinCC 7.2 Web发布与SCADA系统集成:实现工业自动化无缝对接

参考资源链接:[Wincc7.2Web发布操作介绍.docx](https://wenku.csdn.net/doc/6412b538be7fbd1778d425f9?spm=1055.2635.3001.10343)
# 1. WinCC 7.2 Web发布概述
随着工业4.0的推进,Web发布技术已成为连接企业与工业自动化系统的关键桥梁。WinCC 7.2作为一个工业自动化领域的强大工具,其Web发布功能为企业提供
【代码审查的艺术】:提升代码质量的有效方法

参考资源链接:[DeST学习指南:建筑模拟与操作详解](https://wenku.csdn.net/doc/1gim1dzxjt?spm=1055.2635.3001.10343)
# 1. 代码审查
【9899-202x并发编程革新】:内存模型与原子操作的全新视角
参考资源链接:[C语言标准ISO-IEC 9899-202x:编程规范与移植性指南](https://wenku.csdn.net/doc/4kmc3jauxr?spm=1055.2635.3001.10343)
# 1. 并发编程与内存模型基础
在现代计算机系统设计中,内存模型是构建高效并发程序不可或缺的基础。理解内存模型能帮助开发者编写出更加稳定、高效的并发代码。本章从基础层面探讨并发编程的基本概念,引入内存模型的概念,并简要介绍其在现代计算机系统中的重要性。
## 1.1 并发编程简介
并发编程是多线程或多进程环境下的一种编程范式。随着多核处理器的普及,合理利用并发技术已成为提升程序
【ITK-SNAP多模式应用】:不同类型图像抠图及Mask保存的策略(全面分析)
参考资源链接:[ITK-SNAP教程:图像背景去除与区域抠图实例](https://wenku.csdn.net/doc/64534cabea0840391e779498?spm=1055.2635.3001.10343)
# 1. ITK-SNAP简介及多模式图像处理基础
## 1.1 ITK-SNAP概述
ITK-SNAP是一个广泛应用于医学成像领域的开源软件,它集成了图像分割、3D注册、图像预处理等功能。其直观的用户界面和强大的算法支持,使得它在处理多模式图像时显得尤为出色。
## 1.2 多模式图像处理基础
在医学图像处理中,多模式图像指的是结合使用不同的成像技术得到的一系列图像,
【Windows 7 64位系统秘籍】:精通安装与优化SQL Server 2000的10大技巧

参考资源链接:[Windows7 64位环境下安装SQL Server 2000的步骤](https://wenku.csdn.net/doc/7du6ymw7ni?spm=1055.2635.3001.10343)
# 1
【永磁同步电机:20年经验的终极指南】:深入揭示电机性能与应用的关键

参考资源链接:[永磁同步电机电流与转速环带宽计算详解](https://wenku.csdn.net/doc/nood6mjd91?spm=1055.2635.3001.10343)
# 1. 永磁同步电机的理论基础
永磁同步电机(PMSM)以其高效率、高功率密度和优良的动态性能在现代电机技术中占据着重要地位。本章将对PMSM的基本原理和关键技术要素进行介绍,为后续章节中设计、
【Zynq-7000 SoC新手必读】:5分钟速览UG585,轻松入门Xilinx Zynq

参考资源链接:[ug585-Zynq-7000-TRM.pdf](https://wenku.csdn.net/doc/6401acf3cce7214c316edbe7?spm=1055.2635.3001.10343)
# 1. Zynq-7000 SoC概述
## Zynq-7000 SoC的架构简介
Zynq-700
【九齐单片机定时器_计数器应用】:NYIDE中高级计时技巧

参考资源链接:[NYIDE 8位单片机开发软件中文手册(V3.1):全面教程](https://wenku.csdn.net/doc/1p9i8oxa9g?spm=1055.2635.3001.10343)
# 1. 九齐单片机定时器与计数器基础
## 定时器与计数器概述
九齐单片机(如常见的9series)是微电子
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )