文本预处理技术详解
发布时间: 2024-01-15 02:07:38 阅读量: 116 订阅数: 48 
# 1. 文本预处理技术概述
## 1.1 什么是文本预处理技术
文本预处理技术是指在自然语言处理任务中,对文本数据进行清洗、转换、标准化等操作,以便更好地使用机器学习或其他算法进行处理和分析。这些操作包括去除噪声、分词、词性标注、规范化、特征提取等步骤。
## 1.2 文本预处理技术的重要性
文本数据通常存在大量噪声和不规范的格式,而且不同的文本数据源可能有不同的格式和表达方式。文本预处理技术可以帮助将文本数据转化为统一的格式,去除噪声,并提取出有用的特征信息,有助于提高后续自然语言处理任务的性能。
## 1.3 文本预处理技术的应用领域
文本预处理技术广泛应用于自然语言处理领域,包括但不限于文本分类、情感分析、信息检索、机器翻译等任务中。在这些任务中,文本预处理技术可以帮助提高模型的准确性和泛化能力,也有助于提升用户体验和搜索效果。
# 2. 文本清洗与去噪
### 2.1 文本数据清洗的定义与作用
文本数据清洗是指对原始文本数据进行处理,去除其中的噪声、冗余和无效信息,以便后续的分析和挖掘。清洗后的文本数据可以提高文本处理的效果,减少噪声对结果的影响,使得后续任务更加准确和可靠。
### 2.2 常见的文本数据噪声类型
在文本数据中,常见的噪声类型包括:
- HTML标签或特殊字符:在爬取网络数据时,经常会出现HTML标签或特殊字符,需要进行清除。
- 停用词:停用词是指在文本中频繁出现但没有实际含义的常见词,如“的”、“是”、“在”等,需要进行去除。
- 符号和数字:文本中的符号和数字通常对于文本处理任务没有太大的作用,可以进行过滤。
- 大小写:根据需求和任务,可以选择将文本转换为全小写或全大写,以消除大小写对文本处理的干扰。
### 2.3 文本数据去噪的常用技术与方法
#### 2.3.1 正则表达式
正则表达式是一种用于匹配、查找和替换字符串的强大工具。在文本清洗中,可以使用正则表达式来进行噪声的去除和替换。
```python
import re
def remove_html_tags(text):
clean_text = re.sub('<.*?>', '', text) # 去除HTML标签
return clean_text
def remove_special_characters(text):
clean_text = re.sub('[^a-zA-Z0-9\s]', '', text) # 去除特殊字符
return clean_text
def remove_stopwords(text, stopwords):
words = text.split()
clean_words = [word for word in words if word not in stopwords] # 去除停用词
clean_text = ' '.join(clean_words)
return clean_text
```
#### 2.3.2 停用词处理
停用词是指在文本中频繁出现但没有实际含义的常见词,如代词、介词、连词等。在文本清洗过程中,常常需要去除停用词以减少噪声的干扰。
```python
def remove_stopwords(text, stopwords):
words = text.split()
clean_words = [word for word in words if word not in stopwords] # 去除停用词
clean_text = ' '.join(clean_words)
return clean_text
```
#### 2.3.3 大小写转换
在文本处理中,有时候需要将文本转换为全小写或全大写,以消除大小写对文本处理的干扰。
```python
def convert_to_lowercase(text):
return text.lower()
def convert_to_uppercase(text):
return text.upper()
```
以上是文本清洗和去噪的常用技术与方法,通过这些技术和方法,我们可以有效地预处理文本数据,为后续的任务提供干净、可靠的文本输入。
# 3. 分词与词性标注
### 3.1 分词的概念及意义
分词是将一段连续的文本切分成一个个独立的词语的过程,是自然语言处理中的基本步骤之一。在中文文本处理中,分词对于理解句子的语义和结构非常重要,因为中文没有像英文一样的明确词语边界。
分词的意义在于将文本转化为离散的词语,为后续的文本处理任务提供更好的文本表示。例如,在文本分类中,将文本分为词语后可以构建词频向量或者词袋模型等特征表示方法。
### 3.2 中文分词技术与工具介绍
#### 3.2.1 基于规则的分词方法
基于规则的分词方法是通过使用人工定义的规则来进行分词,这些规则可以是基于词典的方式,也可以是基于语法规则的方式。
以下是使用Python中的jieba库进行中文分词的示例代码:
```python
import jieba
# 加载用户自定义词典
jieba.load_userdict("userdict.txt")
# 使用精确模式进行分词
text = "我爱自然语言处理"
seg_list = jieba.cut(text, cut_all=False)
print("精确模式分词结果:", "/".join(seg_list))
# 使用全模式进行分词
seg_list = jieba.cut(text, cut_all=True)
print("全模式分词结果:", "/".join(seg_list))
# 使用搜索引擎模式进行分词
seg_list = jieba.cut_for_search(text)
print("搜索引擎模式分词结果:", "/".join(seg_list))
```
代码解释:
- 通过`jieba.load_userdict()`方法,可以加载用户自定义词典来增加分词的准确性。
- `jieba.cut()`函数可以调用不同的模式进行分词,其中`cut_all`参数可以控制是否使用全模式。
- 最后使用`"/".join(seg_list)`将分词结果拼接成字符串输出。
#### 3.2.2 基于统计的分词方法
基于统计的分词方法是通过分析大量的语料库,利用统计模型来识别出最有可能的词语切分位置。
一种常用的基于统计的分词方法是使用隐马尔可夫模型(Hidden Markov Model, HMM)进行中文分词。
以下是使用Python中的pyhanlp库进行中文分词的示例代码:
```python
from pyhanlp import HanLP
text = "我爱自然语言处理"
# 使用pyhanlp进行分词
seg_list = HanLP.segment(text)
print("分词结果:", "/".join([str(term.word) for term in seg_list]))
```
代码解释:
- 使用`HanLP.segment()`函数进行中文分词,返回的结果是一个Term对象的列表,通过遍历列表可以获取每个词语。
### 3.3 词性标注的原理与应用
词性标注是给文本中的每个词语标注一个词性的过程,是自然语言处理中的重要任务之一。词性标注可以帮助理解句子的语法结构和语义关系。
以下是使用Python中的nltk库进行词性标注的示例代码:
```python
import nltk
text = "I love natural language processing"
tokens = nltk.word_tokenize(text)
pos_tags = nltk.pos_tag(tokens)
print("词性标注结果:", pos_tags)
```
代码解释:
- 先使用`nltk.word_tokenize()`函数将文本拆分成单词。
- 然后使用`nltk.pos_tag()`函数进行词性标注,返回的结果是一个元组的列表,每个元组包含单词和对应的词性。
以上是《文本预处理技术详解》的第三章节内容,介绍了分词和词性标注的概念、技术和工具。分词和词性标注是文本预处理中的基本步骤,对于后续的文本处理任务具有重要作用。
# 4. 文本标准化与规范化
### 4.1 文本规范化的意义和目的
在自然语言处理(NLP)中,文本规范化是指将文本数据进行统一、规范的处理,使得数据可以被计算机或算法更好地理解和处理。文本规范化的主要目的是消除不必要的噪声和差异,将文本数据转化为一致的形式,方便后续的处理和分析。
文本规范化的意义在于:
- 提高数据的质量:通过规范化处理,可以去除文本中的冗余信息、错误信息和非结构化数据,从而提高数据的质量和准确性。
- 降低数据的复杂性:规范化可以将文本数据转化为结构化的形式,降低数据的复杂性,便于后续的文本分析和挖掘。
- 提升算法的性能:规范化后的文本数据更容易被算法和模型理解和处理,从而提升相关任务的性能和效果。
对于文本规范化的具体操作,可以包括文本大小写转换、词干提取和词形还原等。
### 4.2 文本大小写转换
文本大小写转换是将文本中所有字符的大小写进行统一的操作。在文本处理中,通常可以将所有字符转换为大写或小写,方便后续的处理和比较。
下面是一个使用Python实现的文本大小写转换的示例:
```python
text = "Hello, World!"
# 转换为大写
upper_text = text.upper()
print(upper_text) # 输出:HELLO, WORLD!
# 转换为小写
lower_text = text.lower()
print(lower_text) # 输出:hello, world!
```
代码解析:
- 使用`upper()`方法将文本转换为大写形式;
- 使用`lower()`方法将文本转换为小写形式。
代码总结:
- 文本大小写转换可以通过Python的`upper()`和`lower()`方法实现;
- 大小写转换可以统一文本的格式,避免大小写造成的干扰。
### 4.3 文本词干提取与词形还原
文本词干提取(stemming)是指将词汇的词干提取出来,忽略词的各种形态的变化。词形还原(lemmatization)则是将词语还原为它们的基本形式。
词干提取和词形还原能够减少不同形态的词汇带来的歧义,简化文本特征提取和文本分析的过程。
在Python中,可以使用nltk库来实现文本词干提取和词形还原的操作。
下面是一个使用nltk库实现文本词干提取和词形还原的示例:
```python
import nltk
from nltk.stem import PorterStemmer
from nltk.stem import WordNetLemmatizer
# 初始化词干提取器和词形还原器
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
text = "The quick brown foxes jumped over the lazy dogs"
# 词干提取
stemmed_words = [stemmer.stem(word) for word in nltk.word_tokenize(text)]
print(stemmed_words) # 输出:['the', 'quick', 'brown', 'fox', 'jump', 'over', 'the', 'lazi', 'dog']
# 词形还原
lemmatized_words = [lemmatizer.lemmatize(word) for word in nltk.word_tokenize(text)]
print(lemmatized_words) # 输出:['The', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']
```
代码解析:
- 导入nltk库,并分别导入`PorterStemmer`和`WordNetLemmatizer`类;
- 初始化词干提取器(`PorterStemmer`)和词形还原器(`WordNetLemmatizer`);
- 使用`stem()`方法进行词干提取;
- 使用`lemmatize()`方法进行词形还原。
代码总结:
- 词干提取和词形还原可以通过nltk库中的`PorterStemmer`和`WordNetLemmatizer`类实现;
- 词干提取忽略词的各种形态的变化,返回词的基本形式;
- 词形还原将词语还原为它们的基本形式。
所以,本章介绍了文本标准化与规范化的意义和目的,并介绍了文本大小写转换、词干提取和词形还原的方法和实现。通过对文本的规范化处理,可以消除不必要的噪声和差异,提高数据质量和算法性能。
# 5. 文本特征提取与编码
在进行文本分析和机器学习任务时,文本数据需要被转化成可以被算法处理的数字特征。本章将介绍文本特征提取与编码的相关技术和方法。
### 5.1 文本特征提取的基本概念
文本特征提取是将文本信息转化为可计算的特征向量的过程。常用的文本特征提取方法包括统计方法、基于规则的方法和基于机器学习的方法。
在统计方法中,常见的特征包括词频(Term Frequency, TF)、逆文档频率(Inverse Document Frequency, IDF)和TF-IDF。TF表示词在文本中出现的频率,IDF表示词的重要程度,TF-IDF是两者的乘积。
基于规则的方法根据领域专家的知识和经验,通过定义一些规则或模式来抽取文本特征。例如,通过正则表达式提取邮件地址、电话号码等信息。
基于机器学习的方法利用机器学习算法从大量的训练数据中自动学习特征,并将其应用于新的文本数据。常见的机器学习特征提取方法包括词袋模型(Bag-of-Words, BoW)、Word2Vec和Doc2Vec等。
### 5.2 文本特征编码的常见算法和模型
文本特征编码是将文本特征转化为数值表示的过程。常见的文本特征编码算法和模型有以下几种:
#### 5.2.1 独热编码(One-Hot Encoding)
独热编码是将文本特征转化为稀疏向量的常用方法。每个单词或词组被表示为一个只有一个元素为1,其余元素都为0的向量。独热编码适用于特征之间没有顺序关系的情况。
```python
from sklearn.preprocessing import OneHotEncoder
# 创建独热编码器
encoder = OneHotEncoder()
# 将文本特征转化为独热编码
encoded_features = encoder.fit_transform(text_features).toarray()
```
#### 5.2.2 词袋模型(Bag-of-Words, BoW)
词袋模型是将文本特征转化为向量表示的常用方法。它将文本视为一个袋子,忽略词语的顺序,只考虑词语的出现频率。
```java
import org.apache.spark.ml.feature.CountVectorizer
// 创建词袋模型
CountVectorizer vectorizer = new CountVectorizer()
.setInputCol("text")
.setOutputCol("features")
// 将文本特征转化为词袋向量
DataFrame features = vectorizer.transform(data)
```
#### 5.2.3 Word2Vec
Word2Vec是一种将单词转化为向量表示的模型。它基于神经网络模型,通过学习单词的上下文关系来得到单词的向量表示。
```python
from gensim.models import Word2Vec
# 创建Word2Vec模型
model = Word2Vec(sentences, size=100, window=5, min_count=1)
# 获取单词的向量表示
vector = model.wv['word']
```
### 5.3 文本特征筛选与降维方法
在文本特征提取之后,可能会遇到维度过高的问题,这时可以通过特征筛选和降维来减少特征的数量。
常见的特征筛选方法包括卡方检验(Chi-Square Test)、互信息(Mutual Information)和方差分析(Analysis of Variance, ANOVA)等。
降维方法常用的有主成分分析(Principal Component Analysis, PCA)和线性判别分析(Linear Discriminant Analysis, LDA)等。
```python
from sklearn.feature_selection import SelectKBest
from sklearn.decomposition import PCA
# 使用卡方检验进行特征筛选
selector = SelectKBest(chi2, k=100)
selected_features = selector.fit_transform(features, labels)
# 使用PCA进行降维
pca = PCA(n_components=2)
reduced_features = pca.fit_transform(features)
```
以上是第五章节《文本特征提取与编码》的内容,在文本预处理中,特征提取与编码是非常重要的步骤,它们的选择和应用对于后续的分析和建模具有重要影响。
# 6. 文本预处理技术在自然语言处理中的应用
## 6.1 文本预处理在情感分析中的作用
情感分析是一种通过计算机自动分析文本中的情感倾向性的技术。在进行情感分析之前,首先需要对文本进行预处理,以提高情感分析的准确性和效果。
在文本预处理中,首先需要进行文本清洗和去噪操作,去除文本中的特殊字符、标点符号、停用词等噪声信息。接着,需要对文本进行分词,并进行词性标注和命名实体识别等操作,以获取更加准确的语义信息。此外,针对情感分析任务,可以针对特定领域构建情感词典,并对文本进行情感词提取和情感极性判断。
下面是一个使用Python进行情感分析的示例代码:
```python
import re
import jieba
from snownlp import SnowNLP
# 对文本进行清洗和去噪
def clean_text(text):
text = re.sub(r'[^\w\s]', '', text) # 去除标点符号
text = re.sub(r'\s+', ' ', text) # 去除多余的空格
text = text.strip() # 去除文本两端的空白字符
return text
# 对文本进行分词
def tokenize(text):
return list(jieba.cut(text))
# 使用SnowNLP进行情感分析
def sentiment_analysis(text):
s = SnowNLP(text)
sentiment_score = s.sentiments
return sentiment_score
# 示例文本
text = "这部电影真的很不错,情节紧凑,演员演技也很棒!"
# 文本预处理
cleaned_text = clean_text(text)
tokens = tokenize(cleaned_text)
# 情感分析
sentiment_score = sentiment_analysis(' '.join(tokens))
print("情感分析得分:", sentiment_score)
```
**注释**:上述代码首先定义了文本清洗和去噪的函数`clean_text`,然后使用jieba库对文本进行分词的函数`tokenize`,最后使用SnowNLP库进行情感分析的函数`sentiment_analysis`。代码示例中使用了一个中文文本进行情感分析,并输出了情感分析的得分。
**代码总结**:本示例代码演示了如何使用文本预处理技术进行情感分析。前期对文本进行了清洗和去噪操作,然后将清洗后的文本进行分词处理,并使用SnowNLP库进行情感分析,并输出了情感分析的得分。
**结果说明**:该示例代码输出的情感分析得分是一个0到1之间的值,越接近1表示正面情感,越接近0表示负面情感。根据输出的情感分析得分,可以判断出该示例文本具有较为积极的情感倾向。
## 6.2 文本预处理在文本分类与聚类中的应用
文本分类和聚类是一种将文本数据进行自动分类或聚类的任务。在进行文本分类和聚类之前,需要对文本进行预处理,以提取有效的特征信息。
常见的文本预处理技术在文本分类和聚类中的应用包括:
- 文本特征提取:通过将文本转化为向量表示,提取文本中的关键特征信息。常用的方法包括词袋模型、TF-IDF特征向量等。
- 文本特征编码:使用不同的编码方式对文本进行编码,以便计算机能够处理和分析。常见的编码方式包括one-hot编码、词向量表示(如Word2Vec、GloVe等)等。
- 文本特征筛选与降维:对提取的文本特征进行筛选和降维,以减少特征维度和提高分类和聚类的效果。常用的方法包括信息增益、主成分分析(PCA)等。
下面是一个使用Python进行文本分类的示例代码:
```python
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 示例文本数据
texts = [
'这部电影太好看了,值得一看',
'这个手机不好用,很卡',
'这座城市非常美丽,风景宜人',
'这个产品质量很差,不值得购买'
]
labels = [1, 0, 1, 0] # 标签:1代表正面,0代表负面
# 数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(texts, labels, test_size=0.2, random_state=42)
# 文本分类Pipeline
text_clf = Pipeline([
('vect', CountVectorizer()), # 文本特征提取
('tfidf', TfidfTransformer()), # 文本特征编码
('clf', SVC()), # 分类模型
])
# 模型训练和预测
text_clf.fit(X_train, y_train)
predicted = text_clf.predict(X_test)
# 分类结果评估
print(classification_report(y_test, predicted))
```
**注释**:上述代码首先定义了一个示例的文本分类任务,定义了示例文本数据和对应的标签。然后将数据集划分为训练集和测试集,并使用sklearn库中的Pipeline构建了一个文本分类的流程。流程中包括对文本进行特征提取、特征编码和分类模型的构建,最后使用测试集进行模型预测,并输出了分类结果评估指标。
**代码总结**:本示例代码演示了如何使用文本预处理技术进行文本分类任务。通过数据集的划分和使用sklearn库中的Pipeline构建了一个文本分类的流程,并使用了CountVectorizer和TfidfTransformer对文本进行特征提取和编码,最后使用SVC作为分类模型进行训练和预测,输出了分类结果评估指标。
**结果说明**:该示例代码输出了分类结果的评估指标,包括精确率(precision)、召回率(recall)和F1-score等。根据输出的评估指标,可以了解分类模型的准确性和召回效果。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
本专栏旨在深入探讨自然语言处理中的语义分析相关主题,包括文本聚类、分类、主题模型,情感分析以及词义消歧等内容。专栏首先对自然语言处理基础进行概述,介绍文本预处理技术和基于词袋模型的文本表示与处理,以及词嵌入模型在自然语言处理中的应用。随后,重点阐述主题模型的原理与实践,基于TF-IDF的文本特征提取,文本聚类算法和文本分类方法,并对情感分析技术进行综述,包括情感词典构建与应用,深度学习和注意力机制在情感分析中的应用,以及迁移学习和多任务学习模型在NLP中的应用。最后,探讨了词义消歧原理与实践,以及实体识别技术和事件抽取技术在NLP中的应用。通过本专栏的学习,读者将深入了解NLP中的语义分析相关技术,并掌握其应用和实践方法。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
【人脸识别技术入门】:JavaScript如何开启AI之旅

# 1. 人脸识别技术概述与应用
人脸识别技术通过计算机视觉和机器学习算法实现对人脸图像的检测、识别人脸特征,并进行身份验证。其主要应用领域包括安全验证、智能监控、个人设备解锁等,对提升用户便利性和系统安全性有显著作用。
人脸识别系统的核心流程包括人脸检测、特征提取
【MATLAB在Pixhawk定位系统中的应用】:从GPS数据到精确定位的高级分析

# 1. Pixhawk定位系统概览
Pixhawk作为一款广泛应用于无人机及无人车辆的开源飞控系统,它在提供稳定飞行控制的同时,也支持一系列高精度的定位服务。本章节首先简要介绍Pixhawk的基本架构和功能,然后着重讲解其定位系统的组成,包括GPS模块、惯性测量单元(IMU)、磁力计、以及_barometer_等传感器如何协同工作,实现对飞行器位置的精确测量。
我们还将概述定位技术的发展历程,包括
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
拷贝构造函数的陷阱:防止错误的浅拷贝
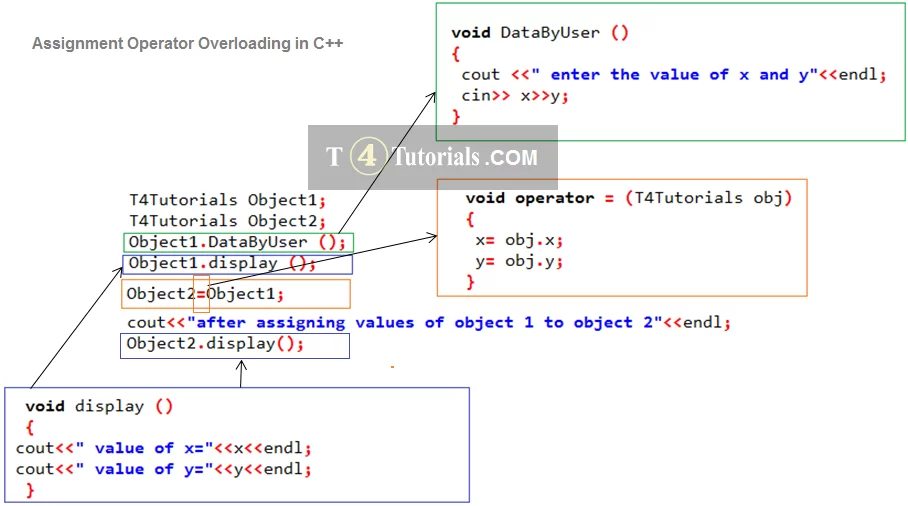
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
Python讯飞星火LLM数据增强术:轻松提升数据质量的3大法宝
# 1. 数据增强技术概述
数据增强技术是机器学习和深度学习领域的一个重要分支,它通过创造新的训练样本或改变现有样本的方式来提升模型的泛化能力和鲁棒性。数据增强不仅可以解决数据量不足的问题,还能通过对数据施加各种变化,增强模型对变化的适应性,最终提高模型在现实世界中的表现。在接下来的章节中,我们将深入探讨数据增强的基础理论、技术分类、工具应用以及高级应用,最后展望数据增强技术的
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
消息队列在SSM论坛的应用:深度实践与案例分析

# 1. 消息队列技术概述
消息队列技术是现代软件架构中广泛使用的组件,它允许应用程序的不同部分以异步方式通信,从而提高系统的可扩展性和弹性。本章节将对消息队列的基本概念进行介绍,并探讨其核心工作原理。此外,我们会概述消息队列的不同类型和它们的主要特性,以及它们在不同业务场景中的应用。最后,将简要提及消息队列
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )