sgmllib在大数据集中的应用与挑战:如何克服并发挥其潜力
发布时间: 2024-10-04 22:37:19 阅读量: 1 订阅数: 6 
# 1. sgmllib的理论基础和功能概述
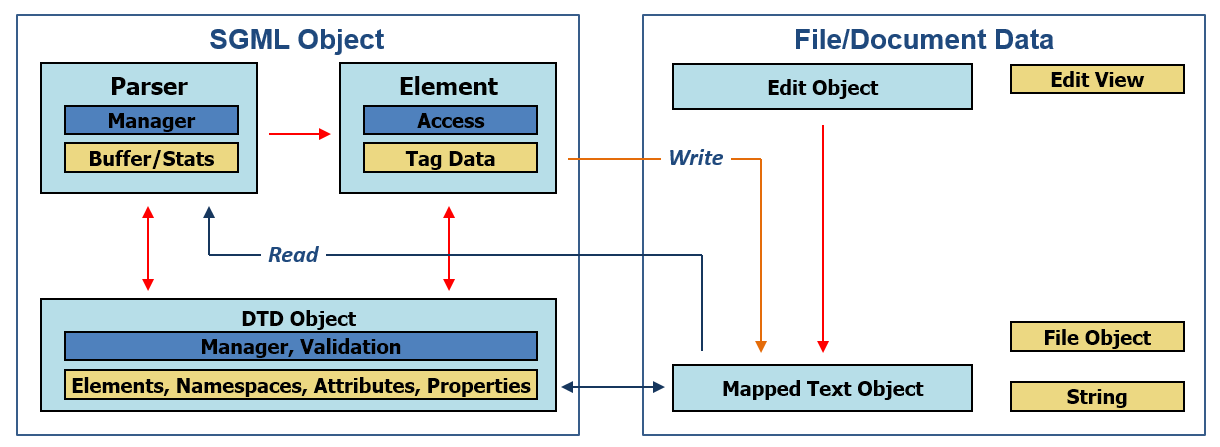
sgmllib是Python标准库中的一个模块,它提供了一种简单的方法来解析SGML(标准通用标记语言)和XML(可扩展标记语言)文档。SGML是一种用于定义标记语言的语言,而XML是一种SGML的简化子集,广泛用于网络数据交换和存储。sgmllib的设计旨在简化解析过程,通过一个事件驱动的接口,使得程序员能够以编程方式解析SGML和XML文档。
## 1.1 sgmllib的理论基础
sgmllib基于SGML的规范,利用状态机来处理文档。每个SGML标签都被视为一个事件,sgmllib会触发相应的事件处理程序。这种状态机方法使得sgmllib非常适合用于流式处理文档,即在读取文档的同时进行解析,无需将整个文档加载到内存中。
## 1.2 sgmllib的主要功能
sgmllib的主要功能包括:
- **标签解析**:sgmllib可以识别SGML和XML文档中的标签,并允许用户处理这些标签。
- **字符数据处理**:对于标签内的文本内容,sgmllib可以单独处理。
- **实体引用**:支持对SGML实体引用的解析和替换。
- **错误处理**:在遇到不符合规范的标记时,sgmllib能够报告错误,并允许开发者定义错误处理程序。
## 1.3 sgmllib的应用场景
由于其轻量级和简洁性,sgmllib适用于需要快速解析SGML或XML文档的场景,特别是在内存和处理能力有限的环境中。例如,它可以用于简单的数据转换任务、快速原型开发,或者作为其他更复杂的解析器的底层引擎。
```python
import sgmllib
class XMLParser(sgmllib.SGMLParser):
def start_element(self, attrs):
print('Start element:', self.lasttag, attrs)
def end_element(self, attrs):
print('End element:', self.lasttag)
def char_data(self, data):
print('Data:', repr(data))
parser = XMLParser()
parser.feed('<foo>bar</foo>')
```
以上代码是一个简单的使用sgmllib解析XML的例子,展示了如何继承SGMLParser类来创建一个自定义的解析器。代码中定义了三个事件处理方法:`start_element`、`end_element`和`char_data`,分别用于处理标签开始、标签结束和标签内的文本数据。通过`feed`方法传递XML字符串,解析器会触发相应的事件处理程序。
# 2. sgmllib在大数据集中的应用实践
## 2.1 sgmllib的文本解析功能
sgmllib是一个轻量级的XML/SGML解析库,它提供了一系列用于解析和处理结构化文本的工具。在本节中,我们将深入探讨sgmllib的文本解析功能,包括其解析规则和方法,以及在文本处理中的实际应用。
### 2.1.1 sgmllib的解析规则和方法
sgmllib是基于事件驱动的解析器,它通过定义一系列事件,如开始标签、字符数据、结束标签等,来处理文本。解析过程中,它会将输入的文本按照定义好的事件进行拆分,并调用相应的处理函数。
sgmllib的解析规则遵循SGML(标准通用标记语言)标准,它能够识别元素的开始和结束标签,并处理它们之间的内容。这种解析机制允许sgmllib在处理复杂的结构化文本时具有较高的灵活性。
```python
from sgmllib import SGMLParser
class MySGMLParser(SGMLParser):
# 定义处理开始标签的函数
def start_element(self, attrs):
print('开始标签:', self.current_data)
# 定义处理字符数据的函数
def handle_data(self, data):
self.current_data = data
print('字符数据:', data)
# 定义处理结束标签的函数
def end_element(self, element):
print('结束标签:', element)
# 使用解析器解析文本
parser = MySGMLParser()
parser.feed('<p>这是一个段落。</p>')
```
以上是一个简单的sgmllib的使用例子,我们定义了一个解析器类MySGMLParser,它继承自SGMLParser,并重写了几个事件处理函数。通过`feed`方法输入文本后,解析器会触发定义好的事件,并输出对应的标签和数据。
### 2.1.2 sgmllib在文本处理中的实际应用
sgmllib的文本解析功能在处理大量结构化文本数据时表现尤为出色。例如,在处理HTML或XML数据时,sgmllib能够逐个元素地解析数据,提取有用信息,并进行进一步的处理和分析。
在实际应用中,我们可以将sgmllib与其他工具相结合,用于数据提取、内容索引、格式转换等多种场景。例如,使用sgmllib可以提取网页中的链接、文本内容或其他特定的数据,并将它们存储在数据库中供后续分析使用。
```python
import urllib.request
import re
from sgmllib import SGMLParser
class URLCollector(SGMLParser):
def start_element(self, attrs):
if self.lasttag == 'a' and 'href' in attrs:
self.urls.append(attrs['href'])
def feed(self, data):
SGMLParser.feed(self, data)
self.current_data = ''
def handle_data(self, data):
self.current_data = data
def extract_urls(url):
response = urllib.request.urlopen(url)
data = response.read()
parser = URLCollector()
parser.feed(data)
return parser.urls
# 提取指定网页的URL链接
urls = extract_urls('***')
print(urls)
```
在此例中,我们定义了一个URLCollector解析器,它专门用于从HTML中提取`<a>`标签内的`href`属性值,即链接地址。这种方法可以应用于网页爬虫,用于收集网站中的链接。
## 2.2 sgmllib的数据处理能力
sgmllib不仅提供了文本解析功能,还具备一定的数据处理能力。在本节中,我们将探讨sgmllib支持的数据类型和转换方式,以及它在数据处理中的实际应用。
### 2.2.1 sgmllib的数据类型和转换方式
sgmllib支持多种数据类型的操作,包括字符串、列表、字典等。对于复杂的数据结构,sgmllib提供了相应的转换方法,使得开发者能够将解析得到的数据转换成其他形式,便于后续处理和使用。
例如,sgmllib可以将解析得到的元素属性转换成字典,从而方便进行属性值的读取和修改。同时,它还提供了将文本数据转换为数值类型的功能,这对于数据分析和统计工作来说非常有用。
```python
from sgmllib import SGMLParser
class DataConverter(SGMLParser):
def start_element(self, attrs):
# 将属性转换为字典
self.attrs = dict(attrs)
def handle_data(self, data):
# 将数据转换为整数
try:
self.data = int(data)
except ValueError:
self.data = data
# 实例化解析器并解析数据
parser = DataConverter()
parser.feed('<item value="42">The Answer</item>')
print(parser.attrs) # 输出属性字典
print(parser.data) # 输出数据值
```
在上述代码中,我们通过解析一个简单的XML元素,将元素的属性和数据分别转换成字典和整数类型,方便后续的使用和处理。
### 2.2.2 sgmllib在数据处理中的实际应用
在数据处理方面,sgmllib能够将结构化文本数据转换成更加结构化的形式,例如,它可以将XML文件中的数据转换为Python中的列表或字典结构,进一步用于数据分析或机器学习模型的训练。
为了更好地说明这一点,我们以将XML格式的天气数据转换为Python字典为例进行说明。这样的转换使得数据的访问和操作更为直接和方便。
```python
import xml.etree.ElementTree as ET
from sgmllib import SGMLParser
class WeatherDataParser(SGMLParser):
def start_element(self, attrs):
if self.lasttag == 'weather':
self.weather_data = []
def end_element(self, element):
if element == 'weather':
self.data['weather'] = self.weather_data
def handle_data(self, data):
self.weather_data.append(data)
# 解析XML格式的天气数据
xml_data = '<weather><temperature>18</temperature><humidity>68</humidity></weather>'
pa
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【XML SAX定制内容处理】:xml.sax如何根据内容定制处理逻辑,专业解析
# 1. XML SAX解析基础
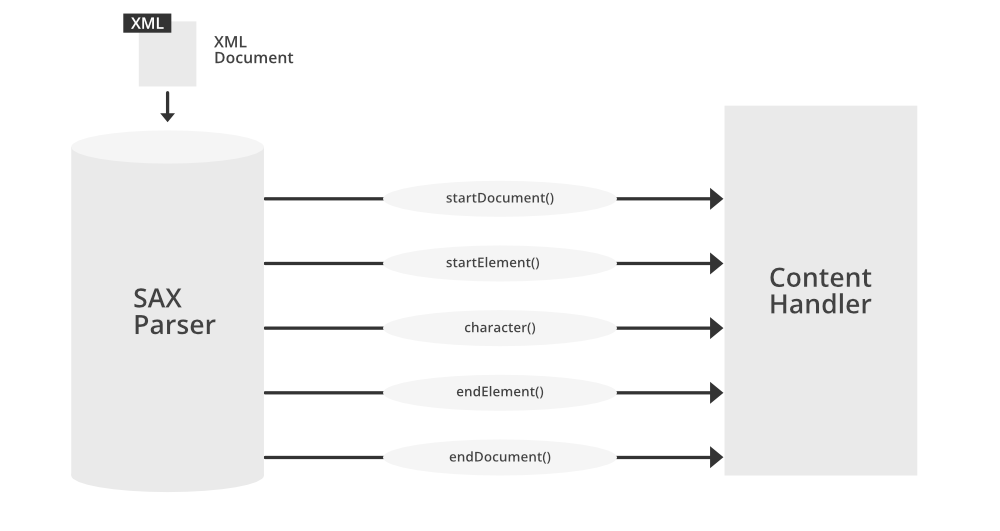
## 1.1 SAX解析简介
简单应用程序接口(Simple API for XML,SAX)是一种基于事件的XML解析技术,它允许程序解析XML文档,同时在解析过程中响应各种事件。与DOM(文档对象模型)不同,SAX不需将整个文档加载到内存中,从而具有较低的内存消耗,特别适合处理大型文件。
##
Polyglot在音视频分析中的力量:多语言字幕的创新解决方案

# 1. 多语言字幕的需求和挑战
在这个信息全球化的时代,跨语言沟通的需求日益增长,尤其是随着视频内容的爆发式增长,对多语言字幕的需求变得越来越重要。无论是在网络视频平台、国际会议、还是在线教育领域,多语言字幕已经成为一种标配。然而,提供高质量的多语言字幕并非易事,它涉及到了文本的提取、
【备份与恢复篇】:数据安全守护神!MySQLdb在备份与恢复中的应用技巧
# 1. MySQL数据库备份与恢复基础
数据库备份是确保数据安全、防止数据丢失的重要手段。对于运维人员来说,理解和掌握数据库备份与恢复的知识是必不可少的。MySQL作为最流行的开源数据库管理系统之一,其备份与恢复机制尤其受到关注。
## 1.1 数据备份的定义
数据备份是一种数据复制过
【多语言文本摘要】:让Sumy库支持多语言文本摘要的实战技巧
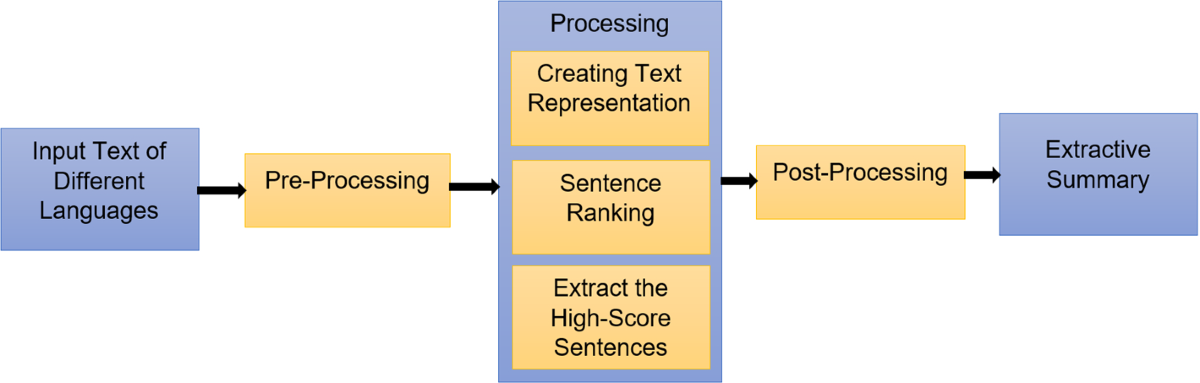
# 1. 多语言文本摘要的重要性
## 1.1 当前应用背景
随着全球化进程的加速,处理和分析多语言文本的需求日益增长。多语言文本摘要技术使得从大量文本信息中提取核心内容成为可能,对提升工作效率和辅助决策具有重要作用。
## 1.2 提升效率与
三维图像处理简易教程:用SimpleCV掌握立体视觉技术

# 1. 三维图像处理的基本概念
在探讨三维图像处理的世界之前,我们需要对这一领域的基础概念有一个清晰的认识。三维图像处理涉及计算机视觉、图形学和图像处理的多个子领域,它包括从多个二维图像中提取三维信息,进而实现对现实世界中对象的重建和分析。这一过程涉及到深度信息的获取、处理和应用,是机
【过滤查询艺术】:django.db.models.query高级过滤,让数据挖掘更精准!

# 1. Django数据库查询基础
数据库是现代Web应用的基石。本章我们将介绍Django中的基本数据库查询技术,这些是开发Django应用时必须掌握的技能。我们将从最基础的查询开始,逐步引导您了解如何使用Django ORM进行数据库操作。
## Django ORM简介
Dja
sgmllib源码深度剖析:构造器与析构器的工作原理

# 1. sgmllib源码解析概述
Python的sgmllib模块为开发者提供了一个简单的SGML解析器,它可用于处理HTML或XML文档。通过深入分析sgmllib的源代码,开发者可以更好地理解其背后的工作原理,进而在实际工作中更有效地使用这一工具。
## 1.1 sgmllib的使用场景
【Django信号与自定义管理命令】:扩展Django shell功能的7大技巧
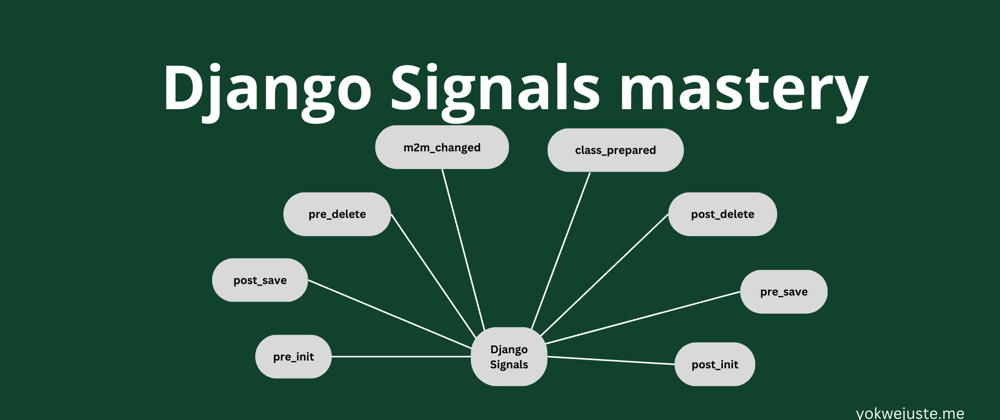
# 1. Django信号与自定义管理命令简介
Django作为一个功能强大的全栈Web框架,通过内置的信号和可扩展的管理命令,赋予了开
文本挖掘的秘密武器:FuzzyWuzzy揭示数据模式的技巧

# 1. 文本挖掘与数据模式概述
在当今的大数据时代,文本挖掘作为一种从非结构化文本数据中提取有用信息的手段,在各种IT应用和数据分析工作中扮演着关键角色。数据模式识别是对数据进行分类、聚类以及序列分析的过程,帮助我们理解数据背后隐藏的规律性。本章将介绍文本挖掘和数据模式的基本概念,同时将探讨它们在实际应用中的重要性以及所面临的挑战,为读者进一步了解FuzzyWuz
【OpenCV光流法】:运动估计的秘密武器
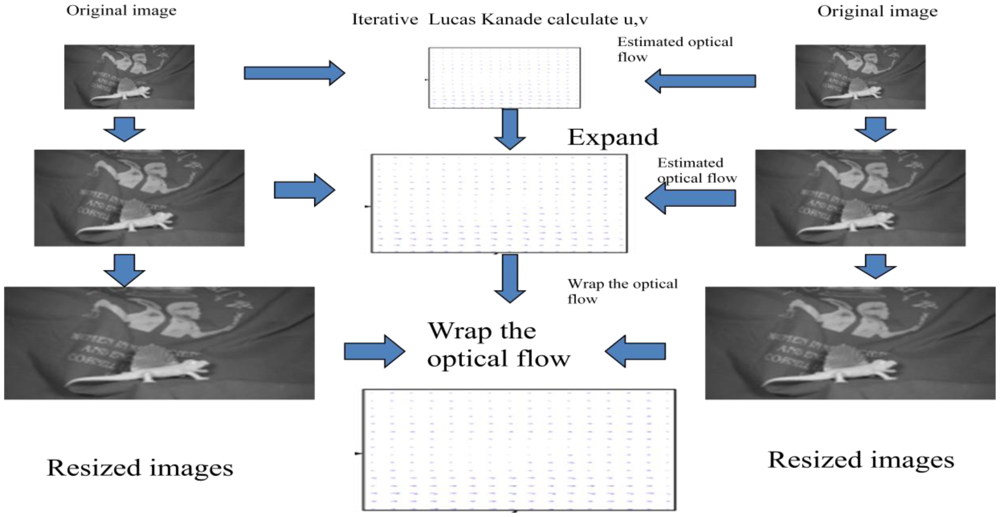
# 1. 光流法基础与OpenCV介绍
## 1.1 光流法简介
光流法是一种用于估计图像序列中像素点运动的算法,它通过分析连续帧之间的变化来推断场景中物体的运动。在计算机视觉领域,光流法已被广泛应用于视频目标跟踪、运动分割、场景重建等多种任务。光流法的核心在于利用相邻帧图像之间的信息,计算出每个像素点随时间变化的运动向量。
## 1.2
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )