发现隐藏模式:YOLO数据集划分与数据挖掘
发布时间: 2024-08-16 09:35:07 阅读量: 40 订阅数: 24 
# 1. YOLO数据集概述**
YOLO(You Only Look Once)数据集是用于训练和评估目标检测模型的广泛使用的数据集。它包含大量标记的图像,其中包含各种对象及其位置和边界框。YOLO数据集以其多样性和高质量而闻名,使其成为开发和评估目标检测算法的理想选择。
YOLO数据集由加州大学伯克利分校的计算机视觉研究组创建。它最初于2015年发布,此后已多次更新和扩展。最新版本(YOLOv5)包含超过100万张图像和超过1000万个标注对象。
# 2. YOLO数据集划分
### 2.1 划分策略与原则
**2.1.1 训练集、验证集和测试集的比例**
YOLO数据集划分一般遵循80/10/10的原则,即80%的数据用于训练集,10%的数据用于验证集,10%的数据用于测试集。
* **训练集:**用于训练模型,模型将从这些数据中学习模式和特征。
* **验证集:**用于调整模型参数和防止过拟合。在训练过程中,模型在验证集上进行评估,并根据验证集上的表现来调整模型。
* **测试集:**用于评估训练后的模型在未知数据上的性能。测试集与训练集和验证集完全独立,模型在测试集上的表现可以反映其泛化能力。
### 2.1.2 数据集划分方法
YOLO数据集划分方法主要有两种:
* **随机划分:**将数据集随机分成训练集、验证集和测试集。这种方法简单易行,但可能会导致数据分布不均匀。
* **分层划分:**根据数据集中的类别或其他属性,将数据分成不同的层级,然后从每个层级中随机抽取数据组成训练集、验证集和测试集。这种方法可以确保数据集在不同层级上的分布均匀。
### 2.2 数据集划分工具
#### 2.2.1 Python库
* **scikit-learn:**提供了`train_test_split`函数,用于随机划分数据集。
* **imbalanced-learn:**提供了`StratifiedShuffleSplit`函数,用于分层划分数据集。
```python
from sklearn.model_selection import train_test_split
# 随机划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 分层划分数据集
from imblearn.datasets import make_imbalance
X, y = make_imbalance(n_samples=1000, n_features=10, n_classes=2, random_state=42)
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in sss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
```
#### 2.2.2 在线工具
* **Kaggle:**提供了数据集划分工具,可以根据比例和方法随机或分层划分数据集。
* **Google Colab:**提供了`train_test_split`函数,用于随机划分数据集。
```python
# Kaggle数据集划分
import kaggle
kaggle.api.dataset_create_version(
dataset_id="your_dataset_id",
version_id="your_version_id",
files=[
{
"path": "train.csv",
"type": "csv",
"data": train_data,
},
{
"path": "val.csv",
"type": "csv",
"data": val_data,
},
{
"path": "test.csv",
"type": "csv",
"data": test_data,
},
],
)
# Google Colab数据集划分
import pandas as pd
df = pd.read_csv("your_dataset.csv")
train_data, test_data = train_test_split(df, test_size=0.2, random_state=42)
```
# 3.1 数据探索与可视化
**3.1.1 数据分布分析

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 YOLO 数据集划分的各个方面,旨在帮助读者优化模型性能。它涵盖了从入门到高级的主题,包括高效的数据划分策略、常见错误及解决方案、自动化工具、真实案例分析以及数据平衡、超参数优化和迁移学习的影响。通过深入理解数据划分与模型性能之间的关系,读者可以制定出色的划分策略,提高数据质量并释放 YOLO 模型的全部潜力。本专栏还强调了数据标注、数据清洗和数据可视化的重要性,为读者提供了建立健全的数据管理流程所需的全面指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WLC3504配置实战手册:无线安全与网络融合的终极指南

# 摘要
WLC3504无线控制器作为网络管理的核心设备,在保证网络安全、配置网络融合特性以及进行高级网络配置方面扮演着关键角色。本文首先概述了WLC3504无线控制器的基本功能,然后深入探讨了其无线安全配置的策略和高级安全特性,包括加密、认证、访问控制等。接着,文章分析了网络融合功能,解释了无线与有线网络融合的理论与配置方法,并讨论
【802.11协议深度解析】RTL8188EE无线网卡支持的协议细节大揭秘

# 摘要
无线通信技术是现代社会信息传输的重要基础设施,其中802.11协议作为无线局域网的主要技术标准,对于无线通信的发展起到了核心作用。本文从无线通信的基础知识出发,详细介绍了802.11协议的物理层和数据链路层技术细节,包括物理层传输媒介、标准和数据传输机制,以及数据链路层的MAC地址、帧格式、接入控制和安全协议。同时,文章还探讨了RTL8188EE无线网
Allegro 172版DFM规则深入学习:掌握DFA Package spacing的实施步骤
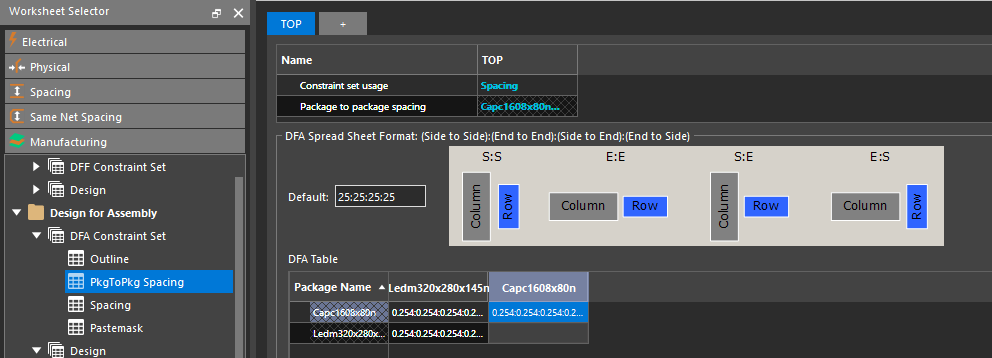
# 摘要
本文围绕Allegro PCB设计与DFM规则,重点介绍了DFA Package Spacing的概念、重要性、行业标准以及在Allegro软件中的实施方法。文章首先定义了DFA Packag
【AUTOSAR TPS深度解析】:掌握TPS在ARXML中的5大应用与技巧

# 摘要
本文系统地介绍了AUTOSAR TPS(测试和验证平台)的基础和进阶应用,尤其侧重于TPS在ARXML(AUTOSAR扩展标记语言)中的使用。首先概述了TPS的基本概念,接着详细探讨了TPS在ARXML中的结构和组成、配置方法、验证与测试
【低频数字频率计设计核心揭秘】:精通工作原理与优化设计要点

# 摘要
数字频率计作为一种精确测量信号频率的仪器,其工作原理涉及硬件设计与软件算法的紧密结合。本文首先概述了数字频率计的工作原理和测量基础理论,随后详细探讨了其硬件设计要点,包括时钟源选择、计数器和分频器的使用、高精度时钟同步技术以及用户界面和通信接口设计。在软件设计与算法优化方面,本文分析了不同的测量算法以
SAP用户管理精进课:批量创建技巧与权限安全的黄金平衡

# 摘要
随着企业信息化程度的加深,有效的SAP用户管理成为确保企业信息安全和运营效率的关键。本文详细阐述了SAP用户管理的各个方面,从批量创建用户的技术和方法,到用户权限分配的艺术,再到权限安全与合规性的要求。此外,还探讨了在云和移动环境下的用户管理高级策略,并通过案例研究来展示理论在实践中的应用。文章旨在为SAP系统管理员提供一套全面的用户管理解决方案,帮助他们优化管理流程,提
【引擎选择秘籍】《弹壳特攻队》挑选最适合你的游戏引擎指南

# 摘要
本文全面分析了游戏引擎的基本概念与分类,并深入探讨了游戏引擎技术核心,包括渲染技术、物理引擎和音效系统等关键技术组件。通过对《弹壳特攻队》游戏引擎实战案例的研究,本文揭示了游戏引擎选择和定制的过程,以及如何针对特定游戏需求进行优化和多平台适配。此外,本文提供了游戏引擎选择的标准与策略,强调了商业条款、功能特性以及对未来技术趋势的考量。通过案例分析,本
【指示灯识别的机器学习方法】:理论与实践结合
# 摘要
本文全面探讨了机器学习在指示灯识别中的应用,涵盖了基础理论、特征工程、机器学习模型及其优化策略。首先介绍了机器学习的基础和指示灯识别的重要性。随后,详细阐述了从图像处理到颜色空间分析的特征提取方法,以及特征选择和降维技术,结合实际案例分析和工具使用,展示了特征工程的实践过程。接着,讨论了传统和深度学习模
【卷积块高效实现】:代码优化与性能提升的秘密武器
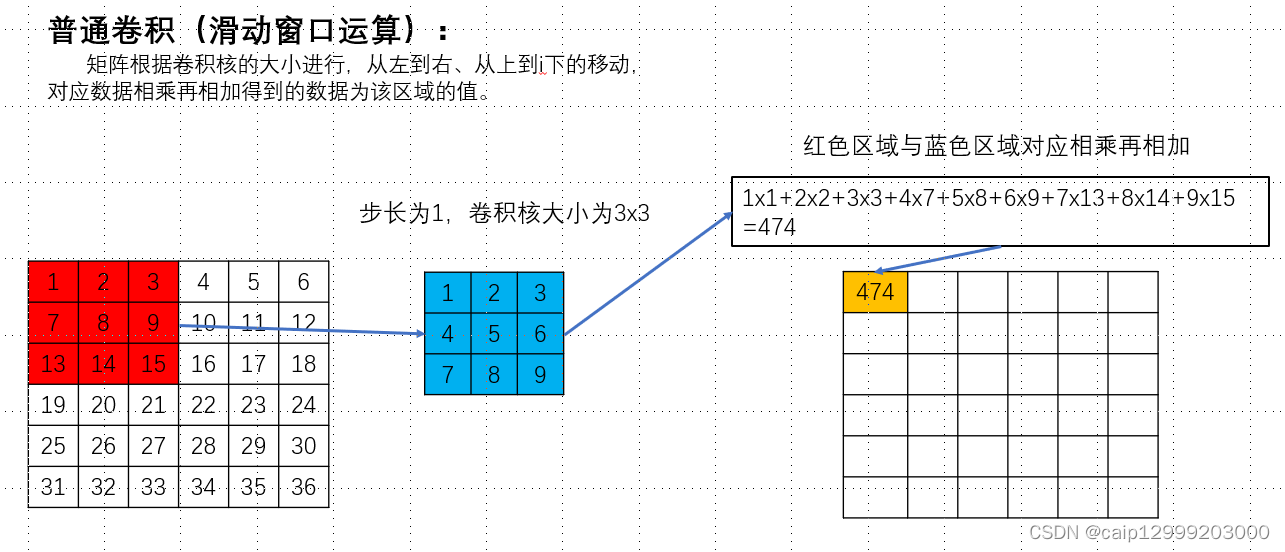
# 摘要
卷积神经网络(CNN)是深度学习领域的重要分支,在图像和视频识别、自然语言处理等方面取得了显著成果。本文从基础知识出发,深入探讨了卷积块的核心原理,包括其结构、数学模型、权重初始化及梯度问题。随后,详细介绍了卷积块的代码实现技巧,包括算法优化、编程框架选择和性能调优。性能测试与分析部分讨论了测试方法和实际应用中性能对比,以及优化策略的评估与选择。最后,展望了卷积块优化的未来趋势,包括新型架构、算法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )