YOLOv8标签匹配策略:精确匹配检测目标的技巧


53.基于单片机的电子琴设计(仿真+实物).pdf
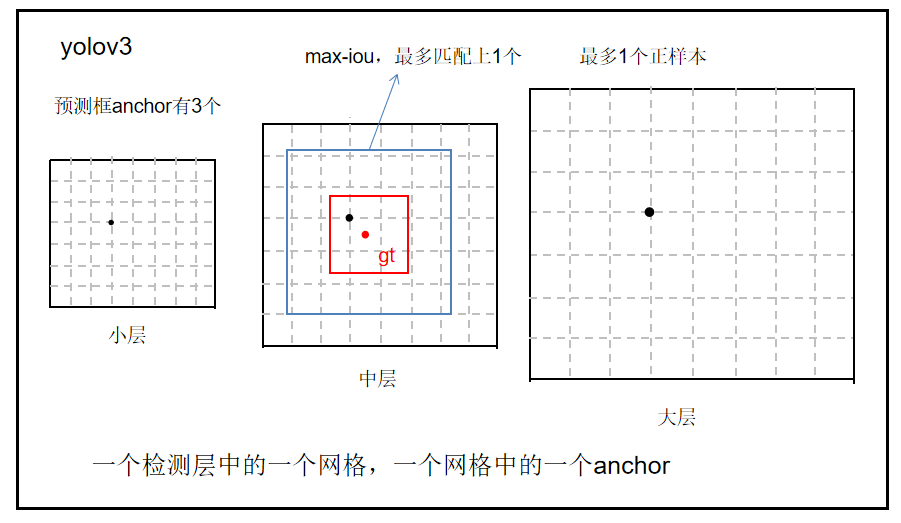
1. YOLOv8标签匹配策略概述
1.1 为什么关注YOLOv8的标签匹配策略
YOLOv8作为目前最热门的目标检测算法之一,其标签匹配策略的优劣直接决定了检测结果的准确性。在计算机视觉领域,高效的标签匹配是理解图像内容并识别目标的关键步骤。因此,对YOLOv8的标签匹配策略进行深入探讨,不仅可以提升现有模型的性能,还可以为未来的研究和应用提供参考。
1.2 YOLOv8标签匹配策略的定义
YOLOv8的标签匹配策略是指在训练过程中,如何将预测框(bounding boxes)与真实标签进行关联,并通过某种策略优化模型的检测精度。这涉及到损失函数的设计、正负样本的选择等核心算法问题。理解其背后的原理,可以帮助开发者和研究人员更有效地构建和训练出性能更优的目标检测模型。
1.3 探索YOLOv8标签匹配策略的重要性
随着技术的发展,目标检测的应用场景越来越广泛,例如自动驾驶、视频监控和人机交互等。这些应用要求检测模型不仅速度快,还要准确可靠。因此,研究YOLOv8的标签匹配策略,能够帮助模型更好地适应各种复杂场景,同时为优化现有模型和开发新一代目标检测算法提供理论与实践基础。
2. YOLOv8标签匹配的理论基础
2.1 目标检测与标签匹配的关系
2.1.1 目标检测的原理
目标检测是计算机视觉中的一个核心任务,它的目的是在图像中识别和定位出一个或多个感兴趣的目标,并给出每个目标的类别。在深度学习时代,目标检测算法通常基于深度卷积神经网络(CNNs)来实现。YOLO(You Only Look Once)系列算法是其中的佼佼者,以其高速度和相对较高的准确性而闻名。
YOLOv8作为该系列的最新成员,延续了YOLO算法的核心思想:将目标检测问题转换为一个单阶段的回归问题。这意味着它在一张图像上仅通过单次前向传播就能预测出目标的类别和位置。YOLOv8通过划分子网格(grid cells)和边界框(bounding boxes),预测中心点落在每个子网格内的目标。每个边界框都包含了目标的坐标位置、宽度、高度和置信度(confidence)等信息。
2.1.2 标签匹配的重要性
标签匹配是指在训练过程中,将每个预测的边界框与真实的标注标签进行匹配,以计算损失函数,并通过反向传播更新网络权重的过程。标签匹配的准确性直接影响到训练模型的性能。一个好的标签匹配策略能够有效地区分哪些预测是准确的,哪些是有误的,从而指导模型学习到更准确的目标特征和边界框位置。
为了确保标签匹配的质量,YOLOv8采用了一种独特的损失函数设计,该设计结合了位置损失、置信度损失和分类损失。位置损失确保了预测边界框的位置尽可能接近真实标注的位置;置信度损失则确保了预测的置信度与目标存在与否的实际概率相匹配;分类损失则确保了对于每个预测的边界框,分类器能够准确地预测出目标的类别。
2.2 YOLOv8算法框架解析
2.2.1 YOLOv8的网络结构
YOLOv8继承了其前辈们的网络结构设计,采用了Darknet作为其基础架构。Darknet是由YOLO的作者首次提出的一种专用于目标检测的网络结构,它通过一系列卷积层、池化层和全连接层来提取图像特征。在最新版本中,YOLOv8针对速度和准确性之间的权衡进行了进一步的优化。
YOLOv8的网络结构中通常包含了多个阶段,每个阶段都会对特征进行提取和上采样。这样设计的目的是逐步将低级特征转化为高级特征,同时保持空间分辨率。这个过程通常依赖于一种称为特征金字塔网络(Feature Pyramid Network, FPN)的架构,以实现多尺度特征融合。
2.2.2 YOLOv8的损失函数
YOLOv8的损失函数由三个主要部分组成:定位损失(Localization Loss)、置信度损失(Confidence Loss)和分类损失(Class Loss)。定位损失负责优化预测的边界框的精确度;置信度损失用来判定目标的出现概率;分类损失则负责分类任务的准确性。
该损失函数可以表示为:
[ Loss = \lambda_{coord} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbf{1}{ij}^{obj} [(x_i - \hat{x}i)^2 + (y_i - \hat{y}i)^2] + \lambda{coord} \sum{i=0}^{S^2} \sum{j=0}^{B} \mathbf{1}{ij}^{obj} [(w_i - \hat{w}i)^2 + (h_i - \hat{h}i)^2] + \sum{i=0}^{S^2} \sum{j=0}^{B} \mathbf{1}{ij}^{obj} (C_i - \hat{C}i)^2 + \lambda{noobj} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbf{1}{ij}^{noobj} (C_i - \hat{C}i)^2 + \sum{i=0}^{S^2} \mathbf{1}{i}^{obj} \sum_{c \in classes} (p_i© - \hat{p}_i©)^2 ]
其中,$S^2$是网格的总数,$B$是每个网格预测的边界框数,$\mathbf{1}_{ij}^{obj}$表示第 $i$ 个网格的第 $j$ 个预测框是否包含目标,$(x_i, y_i)$和$(\hat{x}_i, \hat{y}_i)$分别是预测框和真实框的中心坐标,$(w_i, h_i)$和$(\hat{w}_i, \hat{h}i)$是宽度和高度,$C_i$和$\hat{C}i$分别是预测框的置信度和真实目标的置信度,$\lambda{coord}$和$\lambda{noobj}$是损失函数中位置损失和背景置信度损失的权重,$p_i©$和$\hat{p}_i©$分别表示分类的概率和真实标签。
2.3 标签匹配的评估指标
2.3.1 准确率与召回率
在目标检测任务中,准确率(Precision)和召回率(Recall)是两个重要的评估指标。准确率衡量了预测为正的样本中,实际为正的比例;召回率则衡量了所有实际为正的样本中,被预测出来的比例。对于目标检测来说,预测为正指的是预测出存在目标的边界框。
准确率计算公式为:
[ Precision = \frac{TP}{TP + FP} ]
召回率的计算公式为:
[ Recall = \frac{TP}{TP + FN} ]
其中,TP(True Positive)表示正确检测出的目标数量,FP(False Positive)表示错误检测出的目标数量,FN(False Negative)表示漏检的目标数量。
2.3.2 mAP(mean Average

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MOSFET功率损耗计算:入门到精通的完全手册
L6470驱动器性能极致优化:数据手册参数调整全攻略(专家级指南)
海信ip906h刷机速成班:5个步骤轻松解锁bootloader
【案例解析】:汽车租赁系统的时序图应用,专家建议的正确打开方式
深入UnityWebRequest源码
【性能优化秘籍】:提升微指令技术的水平与垂直策略
【操作安全】:在FANUC机器人ASCII程序中打造无忧操作环境
BeeGFS vs GlusterFS:探索存储解决方案的私密性和权威性


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )