【Google库文件快速入门指南】:Python开发者必备秘籍
发布时间: 2024-10-17 01:33:10 阅读量: 18 订阅数: 23 

初学者Python入门指南:从安装到应用

# 1. Google库文件概述
Google库文件是Google公司开发的一套功能强大的软件开发工具库,它包含了众多模块,旨在简化开发者在各个领域的工作流程。这些库文件覆盖了网络编程、数据处理、自动化测试等多个方面,为开发者提供了高效、稳定的编程接口和工具。
本章将首先概述Google库文件的背景和用途,为读者提供一个全面的认识。接着,我们将深入探讨Google库文件的基础使用方法,包括安装、配置以及基本操作。通过本章的学习,读者将能够掌握Google库文件的基本知识,为进一步的学习和应用打下坚实的基础。
# 2. Google库文件的基础使用
## 2.1 Google库文件的基本安装和配置
### 2.1.1 安装Google库文件
在本章节中,我们将介绍如何在不同的操作系统上安装Google库文件。Google库文件提供了强大的API支持,可以帮助开发者在网络编程、数据处理以及自动化测试等方面提高效率。安装过程相对简单,但需要确保系统的环境变量正确设置,以保证库文件能够被正确识别和使用。
对于大多数的Python开发者来说,安装第三方库文件通常使用`pip`命令。在命令行中输入以下命令即可开始安装:
```bash
pip install google
```
安装过程中可能会遇到的一些问题包括网络连接问题、权限问题以及库文件版本与Python版本不兼容的问题。为了确保安装成功,建议在安装前更新`pip`到最新版本,并使用虚拟环境来隔离不同项目的依赖关系。
### 2.1.2 配置Google库文件环境
在安装完成后,我们需要对Google库文件进行基本的配置,以确保它能够正确地执行。配置过程主要包括以下几个方面:
1. **环境变量设置**:确保Python的安装路径和`pip`的路径被添加到系统的环境变量中。
2. **版本控制**:检查并安装与当前Python版本兼容的Google库文件版本。
3. **依赖管理**:使用`pip freeze`命令导出依赖列表,以便在其他环境中重建相同的环境。
以下是配置环境变量的一个示例,假设你的Python安装在`C:\Python39`目录下:
```cmd
setx PATH "%PATH%;C:\Python39"
setx PATH "%PATH%;C:\Python39\Scripts"
```
这些命令将Python的安装路径和脚本路径添加到Windows的环境变量中。在Linux或macOS系统中,你可以在`.bashrc`或`.bash_profile`文件中添加以下内容:
```bash
export PATH=$PATH:/path/to/python/bin
export PATH=$PATH:/path/to/python/bin/scripts
```
确保替换`/path/to/python/bin`为实际的Python安装路径。
## 2.2 Google库文件的基本操作
### 2.2.1 基本语法和函数
Google库文件的使用涉及到一系列的基本语法和函数。以下是一些常用的函数和它们的简单示例:
```python
import google
# 发起一个网络请求
response = google.request('GET', '***')
# 读取响应内容
content = response.read()
# 打印响应状态码
print(response.status_code)
```
在这个例子中,我们首先导入了`google`库,然后使用`request`函数发起了一个GET请求。接着,我们读取了响应内容,并打印了响应的状态码。
### 2.2.2 常用模块和应用
Google库文件中包含了许多常用的模块,每个模块都有其特定的功能。以下是一些常用模块及其应用示例:
1. **http** 模块用于处理HTTP请求和响应。例如,设置请求头:
```python
import google
request = google.Request('***')
request.headers['User-Agent'] = 'Custom User Agent'
response = google.send(request)
```
2. **解析器** 模块用于解析HTML或XML文档。例如,解析HTML文档中的链接:
```python
import google
from google import html
parsed_html = google.html.fromstring('<html><body><a href="***">Google</a></body></html>')
links = google.html.resolve_links(parsed_html)
print(links)
```
这些模块和函数为开发者提供了强大的工具集,以便于在网络编程和数据处理中发挥更大的作用。在实际应用中,开发者可以根据需要选择合适的模块来构建更复杂的逻辑。
## 2.3 Google库文件的常见问题及解决方法
### 2.3.1 安装和配置问题
安装和配置Google库文件时可能会遇到的问题及其解决方案如下:
1. **网络连接问题**:由于某些地区网络限制,可能会导致`pip`安装失败。解决方案是使用国内的镜像源,例如清华大学镜像源:
```cmd
pip install google -i ***
```
2. **权限问题**:在某些操作系统中,安装库文件需要管理员权限。在Windows中,可以使用管理员模式的命令提示符;在Linux或macOS中,可以使用`sudo`命令。
3. **版本不兼容问题**:如果安装的库文件版本与当前Python版本不兼容,可以尝试安装不同版本的库文件:
```cmd
pip install google==1.0.0
```
### 2.3.2 使用过程中的问题
在使用Google库文件的过程中,可能会遇到一些问题,例如:
1. **HTTP请求失败**:如果HTTP请求失败,可以检查网络连接,请求的URL是否正确,以及是否设置了正确的请求头。
2. **解析错误**:在解析HTML或XML时,如果遇到错误,需要检查选择器是否正确,以及是否处理了所有异常。
通过本章节的介绍,我们已经了解了Google库文件的基本安装、配置、基本操作以及常见问题的解决方法。这些知识对于初学者来说是非常有用的,可以帮助他们快速上手并开始使用Google库文件。对于有经验的开发者而言,这些内容也是基础中的基础,是进一步探索高级应用的前提。接下来的章节,我们将深入探讨Google库文件在网络编程和数据处理中的高级应用。
# 3. Google库文件的高级应用
在本章节中,我们将深入探讨Google库文件的高级应用,包括在网络编程、数据处理和自动化测试中的具体应用。我们将逐步解析这些高级功能的实现原理,并提供实际的应用示例。
## 3.1 Google库文件在网络编程中的应用
### 3.1.1 网络请求和响应处理
在网络编程中,Google库文件提供了强大的网络请求和响应处理功能。它支持多种协议,如HTTP、HTTPS、FTP等,可以处理复杂的网络请求,并能够对响应进行解析和处理。
```python
import requests
# 发送GET请求
response = requests.get('***')
# 发送POST请求
response = requests.post('***', data={'key': 'value'})
# 解析JSON响应
data = response.json()
print(data)
```
在上述代码中,我们使用了`requests`模块发送HTTP请求,并解析了JSON格式的响应内容。这种操作在进行API交互时非常常见。
#### 网络请求参数设置
在发送网络请求时,我们可能需要设置各种参数,比如超时时间、认证信息等。Google库文件允许我们通过传递参数字典来设置这些请求参数。
```python
params = {
'timeout': 10, # 设置超时时间为10秒
'headers': {
'Authorization': 'Bearer token',
},
}
response = requests.get('***', params=params)
```
### 3.1.2 网络数据的解析和处理
在网络编程中,我们经常需要对获取的网络数据进行解析和处理。Google库文件提供了多种工具来帮助我们完成这项工作。
```python
import json
# 假设我们有一个JSON字符串
json_str = '{"name": "John", "age": 30, "city": "New York"}'
# 将JSON字符串解析为Python字典
data = json.loads(json_str)
print(data['name']) # 输出: John
# 将Python字典转换为JSON字符串
json_str = json.dumps(data)
print(json_str) # 输出: {"name": "John", "age": 30, "city": "New York"}
```
在上述代码中,我们使用了`json`模块来解析和生成JSON数据。这是处理JSON格式网络数据的常用方法。
#### 表格:网络数据处理工具
| 工具 | 描述 |
| ----------- | ---------------------------------------------------------- |
| requests | 发送HTTP请求并处理响应 |
| json | 解析和生成JSON数据 |
|BeautifulSoup| 解析HTML和XML文档,用于网页内容提取 |
| xml.etree.ElementTree | 解析XML数据 |
## 3.2 Google库文件在数据处理中的应用
### 3.2.1 数据的读写操作
Google库文件提供了多种工具来处理数据的读写操作,包括文本文件、CSV文件、Excel文件等。
```python
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
# 写入CSV文件
df.to_csv('output.csv', index=False)
# 读取Excel文件
df = pd.read_excel('data.xlsx')
# 写入Excel文件
df.to_excel('output.xlsx', sheet_name='Sheet1')
```
在上述代码中,我们使用了`pandas`库来读取和写入CSV和Excel文件。`pandas`是处理表格数据的强大工具。
#### 数据格式转换
有时候我们需要将数据从一种格式转换为另一种格式,比如从CSV转换为Excel,或者反之。Google库文件可以帮助我们完成这类转换。
```python
# 使用pandas读取CSV文件
df_csv = pd.read_csv('data.csv')
# 将DataFrame转换为Excel文件
df_csv.to_excel('data.xlsx', index=False)
```
### 3.2.2 数据的分析和处理
Google库文件提供了多种工具来进行数据分析和处理,包括数据清洗、数据变换、数据分析等。
```python
import numpy as np
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [10, 20, 30, 40]
})
# 数据清洗:去除含有缺失值的行
df_cleaned = df.dropna()
# 数据变换:计算每行的总和
df['D'] = df.sum(axis=1)
# 数据分析:计算每列的平均值
df_mean = df.mean()
```
在上述代码中,我们使用了`pandas`和`numpy`库来进行数据清洗、数据变换和数据分析。
## 3.3 Google库文件在自动化测试中的应用
### 3.3.1 自动化测试的基本原理和方法
自动化测试是软件测试的重要组成部分,它可以提高测试效率,减少重复性工作。Google库文件中的一些工具可以用来实现自动化测试。
```python
from selenium import webdriver
# 初始化WebDriver
driver = webdriver.Chrome()
# 打开网页
driver.get('***')
# 查找元素并点击
element = driver.find_element_by_id('submit')
element.click()
# 关闭浏览器
driver.quit()
```
在上述代码中,我们使用了`selenium`库来实现自动化测试。`selenium`是一个用于Web应用程序测试的工具。
#### 自动化测试的优势
自动化测试相比手动测试具有以下优势:
- 提高测试效率
- 可以执行复杂的测试场景
- 便于维护和扩展测试脚本
- 提高测试结果的一致性
### 3.3.2 Google库文件在自动化测试中的应用实例
在本小节中,我们将通过一个实例来展示如何使用Google库文件中的`selenium`库来实现自动化测试。
```pyth**
***mon.by import By
import time
# 初始化WebDriver
driver = webdriver.Chrome()
# 打开网页
driver.get('***')
# 找到用户名和密码输入框并输入数据
username_input = driver.find_element(By.ID, 'username')
password_input = driver.find_element(By.ID, 'password')
username_input.send_keys('my_username')
password_input.send_keys('my_password')
# 找到登录按钮并点击
login_button = driver.find_element(By.XPATH, '//button[text()="Login"]')
login_button.click()
# 等待一段时间,以便页面加载完成
time.sleep(2)
# 关闭浏览器
driver.quit()
```
在上述代码中,我们模拟了一个登录操作的自动化测试。我们使用了`selenium`库中的`WebDriver`来控制浏览器,`find_element`方法来找到页面元素,并模拟用户操作。
#### 测试脚本的维护
自动化测试脚本需要定期维护,以适应应用程序的变化。以下是一些维护自动化测试脚本的建议:
- 定期检查测试脚本是否与应用程序的当前版本兼容
- 更新元素定位器,以应对页面结构的变化
- 添加和修改测试用例,以覆盖应用程序的新功能
- 使用版本控制系统来管理测试脚本的版本
通过本章节的介绍,我们了解了Google库文件在网络编程、数据处理和自动化测试中的高级应用。这些应用展示了Google库文件的强大功能和灵活性,可以帮助开发者和测试人员提高工作效率,实现更加复杂和高效的编程任务。在接下来的章节中,我们将进一步探索Google库文件的最佳实践,包括项目实战、性能优化和未来发展趋势。
# 4. Google库文件的最佳实践
## 4.1 Google库文件的项目实战
### 4.1.1 项目的需求分析
在开始一个基于Google库文件的项目之前,首先要进行详细的需求分析。这一步骤是至关重要的,因为它将决定项目的功能范围、性能要求以及最终的成功。需求分析应该包括对项目目标的定义、用户需求的收集、现有系统的评估以及技术可行性研究。
#### 需求分析流程
1. **项目目标定义**:明确项目的最终目标,例如提高数据处理效率、优化网络请求性能等。
2. **用户需求收集**:通过访谈、问卷等方式收集用户的需求和期望。
3. **现有系统评估**:分析当前系统(如果存在)的优缺点,确定是否需要替换或升级。
4. **技术可行性研究**:评估使用Google库文件是否技术上可行,包括库文件的成熟度、社区支持、文档完整性等。
#### 需求分析工具
- **思维导图**:帮助整理和可视化需求之间的关系。
- **用户故事地图**:将用户需求转化为可执行的任务。
- **SWOT分析**:评估项目的优点、缺点、机会和威胁。
### 4.1.2 项目的架构设计
在需求分析完成后,下一步是进行项目的架构设计。这包括确定系统的组件、模块以及它们之间的交互方式。Google库文件的使用应当融入整个系统的架构中,确保其能够高效地支持项目的需求。
#### 架构设计原则
1. **模块化**:将系统分解为可独立开发和测试的模块。
2. **可扩展性**:设计应考虑未来可能的扩展需求。
3. **性能优化**:确保系统在使用Google库文件时能够达到预期的性能。
#### 架构设计模式
- **MVC(Model-View-Controller)**:分离数据、展示和控制逻辑。
- **微服务架构**:将应用拆分成一组小的服务,每个服务运行在自己的进程中。
### 4.1.3 项目的代码实现
代码实现阶段是将架构设计转化为实际代码的过程。在这个阶段,开发者需要将Google库文件的特性应用到具体的实现中。
#### 代码实现的最佳实践
1. **代码规范**:遵循编码规范,如PEP 8(Python编码规范)。
2. **版本控制**:使用版本控制系统,如Git,来管理代码变更。
3. **测试驱动开发**(TDD):先写测试,再写代码,确保代码质量。
#### 代码实现步骤
1. **环境搭建**:配置开发环境,安装必要的依赖。
2. **编写代码**:根据设计文档编写代码。
3. **代码审查**:通过同行评审来检查代码质量和一致性。
4. **测试**:编写和执行测试用例,确保代码的正确性和稳定性。
## 4.2 Google库文件的性能优化
### 4.2.1 性能优化的基本原理和方法
性能优化是确保Google库文件应用高效运行的关键。优化可以从多个层面进行,包括代码层面、系统配置层面以及硬件资源层面。
#### 性能优化方法
1. **算法优化**:选择或设计更高效的算法。
2. **代码剖析**(Profiling):分析代码运行的瓶颈。
3. **缓存**:使用缓存来减少数据访问时间。
4. **并发和并行**:利用多线程或多进程来提高处理速度。
### 4.2.2 Google库文件的性能优化实例
#### 实例分析
假设有一个使用Google库文件进行大量数据处理的项目,性能瓶颈主要出现在数据解析阶段。我们可以使用以下步骤来优化性能:
1. **数据解析**:使用Google库文件的解析工具进行数据解析。
2. **缓存解析结果**:将解析结果存储在缓存中,避免重复解析。
3. **并发处理**:将数据分割成多个批次,使用多线程同时处理。
4. **监控和调整**:使用性能监控工具来跟踪优化效果,并根据结果进行调整。
#### 代码示例
```python
import threading
import functools
import cache_module # 假设这是我们自定义的缓存模块
def cache_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
result = cache_module.get(func, args)
if result is None:
result = func(*args, **kwargs)
cache_module.set(func, args, result)
return result
return wrapper
@cache_decorator
def parse_data(data):
# 这里是解析数据的代码
pass
def process_data_in_threads(data_list):
threads = []
for data in data_list:
thread = threading.Thread(target=parse_data, args=(data,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
data_list = [...] # 大量数据
process_data_in_threads(data_list)
```
在这个示例中,我们使用了一个装饰器来缓存解析数据的结果,并通过多线程来并发处理数据,以此来提高性能。
## 4.3 Google库文件的未来发展趋势
### 4.3.1 Google库文件的新功能和技术
Google库文件作为Google官方支持的库,不断有新功能和技术被加入。了解这些新功能和技术,可以帮助开发者更好地利用Google库文件。
#### 新功能和技术趋势
1. **异步编程支持**:随着异步编程的流行,Google库文件可能会增加对异步操作的支持。
2. **更好的性能分析工具**:提供更强大的性能分析工具,帮助开发者找出性能瓶颈。
3. **扩展库和插件**:随着技术的发展,可能会出现更多的扩展库和插件来扩展Google库文件的功能。
### 4.3.2 Google库文件在行业中的应用前景
Google库文件在各个行业中的应用前景广阔。无论是在数据分析、机器学习还是Web开发中,Google库文件都有着广泛的应用。
#### 应用前景分析
1. **数据分析**:在数据科学领域,Google库文件可以用来进行数据清洗、分析和可视化。
2. **机器学习**:结合TensorFlow等框架,Google库文件可以用于构建和训练机器学习模型。
3. **Web开发**:在Web开发中,Google库文件可以帮助开发者处理HTTP请求、管理会话等。
通过本章节的介绍,我们深入探讨了Google库文件的最佳实践,包括项目实战、性能优化以及未来的发展趋势。这些内容不仅提供了理论知识,还通过实际的代码示例和应用场景,展示了如何在实际项目中应用这些知识。希望这些内容能够帮助读者更好地理解和掌握Google库文件的使用,并在未来的项目中发挥其强大的功能。
# 5. Google库文件的深入研究
## 5.1 Google库文件的源码分析
### 5.1.1 源码结构和设计模式
深入研究Google库文件的源码,首先需要了解其源码结构和设计模式。Google库文件采用的是模块化设计,使得每个模块都能够独立工作,同时也能够与其他模块协同。源码结构通常包括以下几个主要部分:
- 核心模块:包含库文件的核心功能,如网络请求、数据处理等。
- 辅助模块:提供额外的功能,如日志记录、异常处理等。
- 配置文件:定义库文件的配置参数,便于用户根据需要进行调整。
- 测试代码:用于验证库文件功能的正确性和稳定性。
设计模式方面,Google库文件主要采用工厂模式、单例模式和策略模式等,以确保代码的灵活性和可维护性。
### 5.1.2 关键函数和类的解析
在源码分析中,识别并理解关键函数和类对于掌握库文件的工作原理至关重要。以下是部分关键函数和类的解析示例:
```python
# 模块导入
import google_lib_module
# 关键类:HTTPRequest
class HTTPRequest:
def __init__(self, url):
# 初始化请求对象
pass
def send(self):
# 发送请求并获取响应
pass
# 关键函数:log_error
def log_error(message):
# 记录错误信息
pass
```
在上述代码块中,`HTTPRequest` 类负责处理网络请求,包含初始化和发送请求的方法。`log_error` 函数用于记录错误信息,便于调试和问题追踪。
## 5.2 Google库文件的扩展开发
### 5.2.1 如何开发自定义模块
开发自定义模块是扩展Google库文件功能的有效途径。以下是开发自定义模块的基本步骤:
1. **确定需求**:分析需要解决的问题,确定模块的功能。
2. **设计模块结构**:设计模块的类和函数,确保与现有库文件的兼容性。
3. **编写代码**:实现模块的功能,编写相应的单元测试。
4. **集成测试**:将自定义模块集成到库文件中,进行测试以确保整体功能的稳定性。
5. **文档编写**:为新模块编写使用文档,方便其他开发者理解和使用。
### 5.2.2 如何贡献代码到Google库文件项目
贡献代码到Google库文件项目需要遵循一定的流程,以下是贡献代码的基本步骤:
1. **选择合适的issue**:在Google库文件的issue列表中选择一个未解决的问题。
2. **创建分支**:从官方库文件的master分支创建一个新的分支,用于开发。
3. **编写代码**:实现解决方案,并确保代码质量。
4. **提交PR**:将代码改动提交到官方库文件仓库,并创建一个Pull Request。
5. **等待反馈**:等待项目维护者或社区成员的反馈和审查。
6. **合并代码**:一旦代码通过审查,它将被合并到master分支。
## 5.3 Google库文件的学习资源和社区
### 5.3.1 学习书籍和教程
为了深入学习和掌握Google库文件,以下是一些推荐的学习资源:
- 官方文档:Google库文件的官方文档是最权威的学习资料。
- 书籍:例如《Python高级编程》中可能包含对Google库文件的深入讲解。
- 在线教程:如Coursera、Udemy等平台提供的相关课程。
### 5.3.2 社区和论坛
加入Google库文件的社区和论坛可以与同行交流,获取帮助和分享经验。以下是一些推荐的社区和论坛:
- Stack Overflow:在Stack Overflow上搜索和提问与Google库文件相关的问题。
- GitHub:参与Google库文件的官方仓库,关注讨论和更新。
- Reddit:在r/Python或其他相关子版块中讨论Google库文件。
通过上述深入研究,我们可以更好地理解Google库文件的工作原理,开发自定义模块,贡献代码,以及利用学习资源和社区资源提高我们的技能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Python库文件学习之Google”专栏,这是一个全面的指南,旨在帮助您充分利用Google提供的强大库文件。本专栏深入探讨了Google库文件的各个方面,从基础概念到高级特性,涵盖了构建高效Python应用程序所需的一切知识。通过一系列引人入胜的文章,您将学习如何使用Google库文件优化代码性能、提高可维护性、处理并发任务、进行测试和调试,以及管理代码变更。本专栏还提供了有关数据结构、API设计原则、模块化设计和文档编写的深入见解,帮助您编写清晰、可重用且易于维护的代码。无论您是Python新手还是经验丰富的开发人员,本专栏都将为您提供构建卓越Python应用程序所需的工具和技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【工作效率倍增器】:Origin转置矩阵功能解锁与实践指南
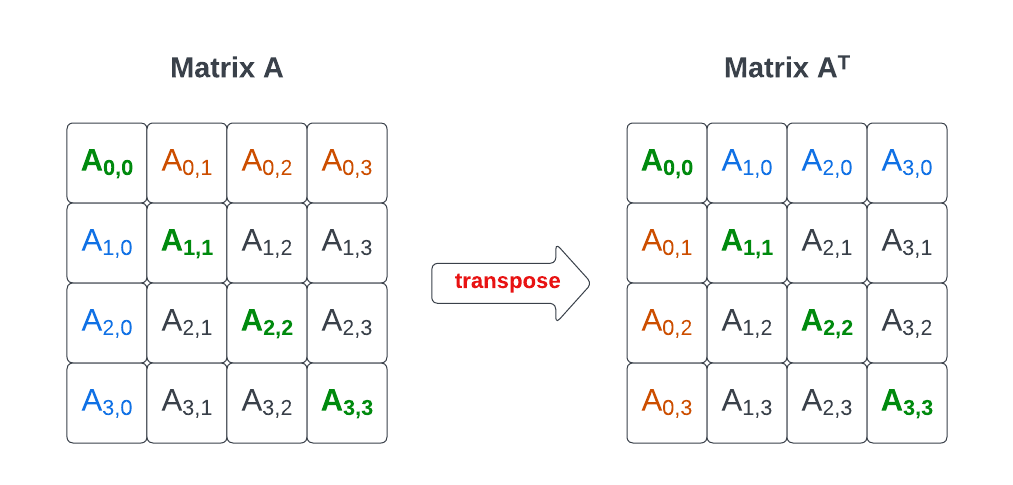
# 摘要
本文系统介绍了Origin软件中转置矩阵功能的理论基础与实际操作,阐述了矩阵转置的数学原理和Origin软件在矩阵操作中的重要
【CPCL打印语言的扩展】:开发自定义命令与功能的必备技能

# 摘要
CPCL(Common Printing Command Language)是一种广泛应用于打印领域的编程语言,特别适用于工业级标签打印机。本文系统地阐述了CPCL的基础知识,深入解析了其核心组件,包括命令结构、语法特性以及与打印机的通信方式。文章还详细介绍了如何开发自定义CPCL命令,提供了实践案例,涵盖仓库物流、医疗制药以及零售POS系统集成等多个行业应用。最后,本文探讨了CPCL语言的未来发展,包括演进改进、跨平台与云
系统稳定性与参数调整:南京远驱控制器的平衡艺术

# 摘要
本文详细介绍了南京远驱控制器的基本概念、系统稳定性的理论基础、参数调整的实践技巧以及性能优化的方法。通过对稳定性分析的数学模型和关键参数的研究,探讨了控制系统线性稳定性理论与非线性系统稳定性的考量。文章进一步阐述了参数调整的基本方法与高级策略,并在调试与测试环节提供了实用的技巧。性能优化章节强调了理论指导与实践案例的结合,评估优化效果并讨论了持续改进与反馈机制。最后,文章通过案例研究揭示了控制
【通信性能极致优化】:充电控制器与计费系统效率提升秘法
# 摘要
随着通信技术的快速发展,通信性能的优化成为提升系统效率的关键因素。本文首先概述了通信性能优化的重要性,并针对充电控制器、计费系统、通信协议与数据交换以及系统监控等关键领域进行了深入探讨。文章分析了充电控制器的工作原理和性能瓶颈,提出了相应的硬件和软件优化技巧。同时,对计费系统的架构、数据处理及实时性与准确性进行了优化分析。此外,本文还讨论了通信协议的选择与优化,以及数据交换的高效处理方法,强调了网络延迟与丢包问题的应对措施。最后,文章探讨了系统监控与故障排除的策略,以及未来通信性能优化的趋势,包括新兴技术的融合应用和持续集成与部署(CI/CD)的实践意义。
# 关键字
通信性能优化
【AST2400高可用性】:构建永不停机的系统架构

# 摘要
随着信息技术的快速发展,高可用性系统架构对于保障关键业务的连续性变得至关重要。本文首先对高可用性系统的基本概念进行了概述,随后深入探讨了其理论基础和技术核心,包括系统故障模型、恢复技术、负载均衡、数据复制与同步机制等关键技术。通过介绍AST2400平台的架构和功能,本文提供了构建高可用性系统的实践案例。进一步地,文章分析了常见故障案例并讨论了性
【Origin脚本进阶】:高级编程技巧处理ASCII码数据导入

# 摘要
本文详细介绍了Origin脚本的编写及应用,从基础的数据导入到高级编程技巧,再到数据分析和可视化展示。首先,概述了Origin脚本的基本概念及数据导入流程。接着,深入探讨了高级数据处理技术,包括数据筛选、清洗、复杂数据结构解析,以及ASCII码数据的应用和性能优化
【频谱资源管理术】:中兴5G网管中的关键技巧

# 摘要
本文详细介绍了频谱资源管理的基础概念,分析了中兴5G网管系统架构及其在频谱资源管理中的作用。文中深入探讨了自动频率规划、动态频谱共享和频谱监测与管理工具等关键技术,并通过实践案例分析频谱资源优化与故障排除流程。文章还展望了5G网络频谱资源管理的发展趋势,强调了新技术应用和行业标准的重要性,以及对频谱资源管理未来策略的深入思考。
# 关键字
频谱资源管理;5G网管系统;自动频率规划;动态频谱共享;频谱监测工
【边缘计算与5G技术】:应对ES7210-TDM级联在新一代网络中的挑战

# 摘要
本文探讨了边缘计算与5G技术的融合,强调了其在新一代网络技术中的核心地位。首先概述了边缘计算的基础架构和关键技术,包括其定义、技术实现和安全机制。随后,文中分析了5G技术的发展,并探索了其在多个行业中的应用场景以及与边缘计算的协同效应。文章还着重研究了ES7210-TDM级联技术在5G网络中的应用挑战,包括部署方案和实践经验。最后,对边缘计算与5G网络的未来发展趋势、创新
【文件系统演进】:数据持久化技术的革命,实践中的选择与应用

# 摘要
文件系统作为计算机系统的核心组成部分,不仅负责数据的组织、存储和检索,也对系统的性能、可靠性及安全性产生深远影响。本文系统阐述了文件系统的基本概念、理论基础和关键技术,探讨了文件系统设计原则和性能考量,以及元数据管理和目录结构的重要性。同时,分析了现代文件系统的技术革新,包括分布式文件系统的架构、高性能文件系统的优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )