Apache HBase简介与基本概念解析
发布时间: 2024-02-22 10:17:13 阅读量: 50 订阅数: 32 

HBase的详细简介
# 1. Apache HBase简介
## 1.1 什么是Apache HBase?
Apache HBase是一个开源的、分布式的、面向列(column-oriented)的NoSQL数据库管理系统。它构建在Apache Hadoop之上,提供实时读/写访问大规模数据集的能力。
## 1.2 Apache HBase的历史和发展
Apache HBase最初由Powerset公司开发,后来被Apache软件基金会接管并转变为开源项目。它的发展始于2007年,目前已成为Hadoop生态系统中重要组件之一。
## 1.3 Apache HBase与传统数据库的区别
与传统关系型数据库(如MySQL、Oracle)不同,Apache HBase是基于列族(column family)存储数据的,具有较高的水平扩展性和容错性,适用于处理非结构化的大数据。Apache HBase还支持数据的版本控制和强一致性。
# 2. Apache HBase的核心概念
### 2.1 表(Table)和行键(Row Key)
在Apache HBase中,数据存储在表(Table)中,每一行数据都有一个唯一的行键(Row Key)来标识。行键在表中必须是唯一的,而且按照字典序排序存储,这也是HBase强大的检索性能的基础之一。
```python
import happybase
# 连接HBase数据库
connection = happybase.Connection('localhost')
# 创建表
connection.create_table(
'my_table',
{
'cf1': dict() # 列族cf1
}
)
# 获取表
table = connection.table('my_table')
# 插入数据
table.put('row1', {'cf1:col1': 'value1', 'cf1:col2': 'value2'})
# 获取数据
data = table.row('row1')
print(data)
```
**代码总结:** 以上代码演示了如何在HBase中创建表、插入数据和获取数据的基本操作。
**结果说明:** 插入数据后,通过获取数据操作可以获得对应的行数据。
### 2.2 列族(Column Family)和列限定符(Column Qualifier)
在HBase中,数据存储在列族(Column Family)中,每个列族可以包含多个列限定符(Column Qualifier)。列族是在表创建时定义的,而列限定符是在数据插入时指定的。
```java
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
public class HBaseExample {
public static void main(String[] args) {
try {
// 创建表描述符
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("my_table"));
// 添加列族
tableDescriptor.addFamily(new HColumnDescriptor("cf1"));
// 连接HBase数据库
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin();
// 创建表
admin.createTable(tableDescriptor);
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
**代码总结:** 上述Java代码演示了如何在HBase中创建表描述符并添加列族。
### 2.3 版本(Version)和时间戳(Timestamp)
HBase支持为每条数据存储多个版本,并且每个版本都有对应的时间戳。通过时间戳可以方便地获取历史数据版本。
```go
package main
import (
"context"
"fmt"
"log"
"github.com/tsuna/gohbase"
"github.com/tsuna/gohbase/hrpc"
)
func main() {
client := gohbase.NewClient("localhost")
putRequest, err := hrpc.NewPutStr(ctx, "my_table", "row1", map[string]map[string][]byte{
"cf1": {
"col1": []byte("value1"),
"col2": []byte("value2"),
},
}, hrpc.Timestamp(1234567890))
if err != nil {
log.Fatal(err)
}
_, err = client.Put(putRequest)
if err != nil {
log.Fatal(err)
}
}
```
**代码总结:** 以上Go代码展示了如何在HBase中插入带有时间戳的数据。
本节介绍了HBase的核心概念,包括表、行键、列族、列限定符、版本和时间戳。掌握这些概念是使用HBase的基础。
# 3. Apache HBase的架构设计
Apache HBase作为一个分布式、可扩展的大数据存储,其架构设计关乎其性能和稳定性。本章将深入探讨Apache HBase的架构设计,包括分布式存储架构、Master/RegionServer架构以及读写路径分析。
### 3.1 分布式存储架构
Apache HBase基于HDFS(Hadoop分布式文件系统)构建,采用水平扩展的方式存储数据。HBase的数据存储在HDFS上的多个Region中,Region通过行键范围划分,每个Region负责存储某个范围内的行键数据。
HBase的分布式存储架构充分利用了Hadoop的分布式特性,通过在不同的节点上存储不同的Region,实现了数据的分布式存储和读写,并且能够实现水平扩展,使得系统可以应对大规模数据的存储需求。
### 3.2 Master/RegionServer架构
在HBase集群中,有两种角色的节点:Master节点和RegionServer节点。Master节点负责对整个集群进行管理和协调,包括负责表的创建和管理、Region的分割和合并、负载均衡等工作;而RegionServer节点负责具体的数据读写操作,每个RegionServer负责管理若干个Region。
Master节点和RegionServer节点通过ZooKeeper进行协调和通信,Master节点监控RegionServer节点的状态,并根据集群负载情况进行Region的迁移和负载均衡操作,以保证整个集群的稳定运行。
### 3.3 读写路径分析
在HBase中,客户端和RegionServer之间的数据读写流程经过了一系列的步骤。对于数据的读操作,客户端首先通过ZooKeeper获取到正在服务的RegionServer节点的信息,然后直接与目标RegionServer通信获取数据;对于数据的写操作,客户端先将数据写入WAL(Write-Ahead Log),然后写入MemStore,最终异步刷写到HFile中。
在实际的读写操作中,HBase通过WAL和MemStore等机制保证了数据的一致性和持久性,同时通过HFile的存储方式提高了数据的读取效率,保证了系统的高性能和稳定性。
通过对HBase架构设计的深入理解,可以更好地理解HBase在大数据存储领域的优势和特点,为后续的使用和调优提供了基础。
# 4. Apache HBase的基本操作
#### 4.1 创建和管理表
Apache HBase是一个分布式的非关系型数据库,表的创建和管理是使用HBase的基本操作之一。下面我们将介绍如何在HBase中创建和管理表。
##### 4.1.1 创建表
在HBase中,可以使用HBase shell或者HBase API来创建表。下面是使用HBase shell创建表的示例:
```shell
create 'student','info','score'
```
上述命令创建了一个名为"student"的表,该表包含两个列族:"info"和"score"。
通过HBase Java API创建表的示例:
```java
HBaseAdmin hBaseAdmin = new HBaseAdmin(config);
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("student"));
HColumnDescriptor infoFamily = new HColumnDescriptor("info");
HColumnDescriptor scoreFamily = new HColumnDescriptor("score");
tableDescriptor.addFamily(infoFamily);
tableDescriptor.addFamily(scoreFamily);
hBaseAdmin.createTable(tableDescriptor);
```
上述代码通过HBaseAdmin对象创建了一个名为"student"的表,并指定了两个列族:"info"和"score"。
##### 4.1.2 管理表
除了创建表,我们也需要对表进行管理,比如添加或删除列族,修改表的属性等操作。
使用HBase shell添加列族的示例:
```shell
alter 'student', {NAME=>'grade', VERSIONS=>3}
```
上述命令在"student"表中添加了一个名为"grade"的列族,并指定了最大版本数为3。
通过HBase Java API添加列族的示例:
```java
HBaseAdmin hBaseAdmin = new HBaseAdmin(config);
HColumnDescriptor gradeFamily = new HColumnDescriptor("grade");
hBaseAdmin.addColumn("student", gradeFamily);
```
上述代码通过HBaseAdmin对象为"student"表添加了一个名为"grade"的列族。
#### 4.2 数据的读写操作
在Apache HBase中,数据的读写操作是非常重要的,下面我们将介绍如何进行HBase中数据的读写操作。
##### 4.2.1 数据写入
使用Put对象进行数据写入的示例:
```java
HTable table = new HTable(config, "student");
Put put = new Put(Bytes.toBytes("001"));
put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("Tom"));
table.put(put);
```
上述代码向"student"表中插入了一行数据,行键为"001",列族为"info"的列" name"的值为"Tom"。
##### 4.2.2 数据读取
使用Get对象进行数据读取的示例:
```java
HTable table = new HTable(config, "student");
Get get = new Get(Bytes.toBytes("001"));
Result result = table.get(get);
byte[] nameValue = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"));
System.out.println("Name: " + Bytes.toString(nameValue));
```
上述代码从"student"表中获取行键为"001"的数据,并输出了列族为"info"的列" name"的值。
#### 4.3 数据一致性和事务处理
在分布式系统中,数据的一致性和事务处理是非常重要的内容。Apache HBase通过版本控制和事务协调来保证数据的一致性。在实际应用中,开发人员需要结合具体需求来设计合适的数据访问策略,以保证数据一致性和处理事务。
以上便是Apache HBase的基本操作内容,涵盖了表的创建和管理、数据的读写操作以及数据一致性和事务处理。在实际应用中,开发人员可以根据具体场景进一步深入学习和应用。
# 5. Apache HBase的性能优化与调优
Apache HBase作为一个高性能的分布式数据库,性能优化和调优对于大数据应用至关重要。本章将深入探讨如何通过数据模型设计的最佳实践、数据访问性能的优化方法以及HBase集群的扩展和负载均衡策略来提升HBase的性能。
#### 5.1 数据模型设计的最佳实践
在使用HBase时,设计良好的数据模型可以显著提升性能。以下是一些数据模型设计的最佳实践:
- 行键设计:合理的行键设计可以减少磁盘的读取操作,尽量避免随机读取。行键的设计应考虑数据的访问模式和业务需求,避免过长或过短的行键,以及频繁变化的行键。
- 列族和列限定符设计:合理划分列族和设计列限定符可以提高数据的存储效率和访问性能。避免在一个表中使用过多的列族,以及频繁变化列族和列限定符的设计。
- 版本控制:合理设置数据的版本数量和时间戳可以在满足业务需求的前提下,降低存储空间的占用。
#### 5.2 数据访问性能的优化方法
除了良好的数据模型设计外,还可以通过以下方法优化HBase的数据访问性能:
- 批量操作:使用HBase的批量操作API可以减少网络开销和降低延迟,提高数据读写性能。
- 预分区:合理预分区可以减少热点数据的产生,提高集群的负载均衡和性能。
- 数据压缩:启用HBase的数据压缩功能可以减少存储空间的占用,加快数据传输速度。
#### 5.3 HBase集群的扩展和负载均衡策略
对于大规模的数据存储和处理需求,HBase集群的扩展和负载均衡策略显得尤为重要。
- 水平扩展:通过添加更多的RegionServer和机器节点来实现集群的水平扩展,从而提高集群的负载能力和吞吐量。
- 自动负载均衡:HBase内置了负载均衡的功能,可以根据集群的负载情况自动调整RegionServer上的Region分布,实现负载均衡。
- ZooKeeper集群:优化ZooKeeper集群的大小和性能也对HBase的稳定性和性能有着重要影响。
通过以上性能优化和调优的方法,可以使得Apache HBase在大数据应用中发挥更高的性能和效率。
# 6. Apache HBase与大数据生态系统的集成
Apache HBase作为一个分布式的、面向列的开源数据库,广泛应用于大数据存储与分析领域。与其他大数据工具的集成使用,能够更好地发挥其强大的功能与性能优势。本章将介绍Apache HBase与Hadoop、Hive、Spark等工具的集成方式,并通过实际案例分析展示其应用场景。
#### 6.1 与Hadoop的集成
Apache HBase与Hadoop的紧密集成,能够充分利用Hadoop生态系统中的资源与功能,实现高效的数据处理与分析。其集成方式主要有以下几种:
- HDFS存储:HBase的数据存储基于HDFS,通过与Hadoop的HDFS进行集成,可以实现数据的高可靠存储与容错处理。
- MapReduce任务:HBase可以作为MapReduce任务的数据源与数据存储,通过HBase TableInputFormat与TableOutputFormat,实现MapReduce与HBase的无缝集成。
- HBase与Hive:HBase与Hive的集成,可以通过Hive的HBase存储处理器(HBase Storage Handler),实现Hive对HBase数据的查询与分析。
#### 6.2 与Hive、Spark等工具的整合
除了与Hadoop的紧密集成,Apache HBase还能够与Hive、Spark等工具进行良好整合,提供更丰富的数据处理与分析能力。
- 与Hive的整合:通过Hive的HBase存储处理器,可以直接在Hive中操作HBase表数据,实现HiveQL查询、数据加载等操作。
- 与Spark的整合:Spark作为高性能的分布式计算框架,也能够与HBase进行优秀整合,通过Spark对HBase数据进行分布式计算与分析。
#### 6.3 实际案例分析与应用场景
在实际应用中,Apache HBase与大数据生态系统的集成使用,提供了丰富的应用场景和案例。例如:
- 在实时日志分析领域,通过HBase与Hadoop的集成,可以实现日志数据的高效存储与实时分析。
- 在电商行业的推荐系统中,结合HBase与Spark,可以实现对用户行为数据的实时分析与推荐模型的构建。
- 在传统数据仓库的升级与改造过程中,将HBase与Hive、Spark等工具进行整合,为企业提供更灵活、高效的数据处理与分析能力。
通过这些实际案例的分析,可以更好地理解Apache HBase与大数据生态系统的集成应用,并为实际场景的数据处理与分析提供参考与借鉴。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Apache HBase专栏深度解析了Apache HBase这一分布式、可扩展、非关系型的分布式数据库系统。首先从Apache HBase的基本概念出发,系统梳理了其与传统数据库的对比分析,逐步深入探讨了其架构设计、运行机制、数据模型、数据读写流程、数据一致性实现机制,以及数据索引设计与优化技巧等方面。同时,专栏还对Apache HBase的数据备份与恢复策略、数据一致性级别与事务处理、读写性能调优技术,以及安全性配置与权限控制策略等进行了深入解析。此外,专栏还重点讨论了Apache HBase与Hadoop生态系统的整合与优化。通过专栏的全面解读,读者能够系统地了解Apache HBase的特点、原理和应用,为实际项目提供有力的技术支持和指导。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【3D建模新手入门】:5个步骤带你快速掌握实况脸型制作

# 摘要
随着计算机图形学的飞速发展,3D建模在游戏、电影、工业设计等多个领域中扮演着至关重要的角色。本文系统介绍了3D建模的基础知识,对比分析了市面上常见的建模软件功能与特点,并提供了安装与界面配置的详细指导。通过对模型构建、草图到3D模型的转换、贴图与材质应用的深入讲解,本文为初学者提供了从零开始的实操演示。此外,文章还探讨了3D建模中的灯光与渲染技巧,以及在实践案例中如何解决常见问题和
PL4KGV-30KC新手入门终极指南:一文精通基础操作
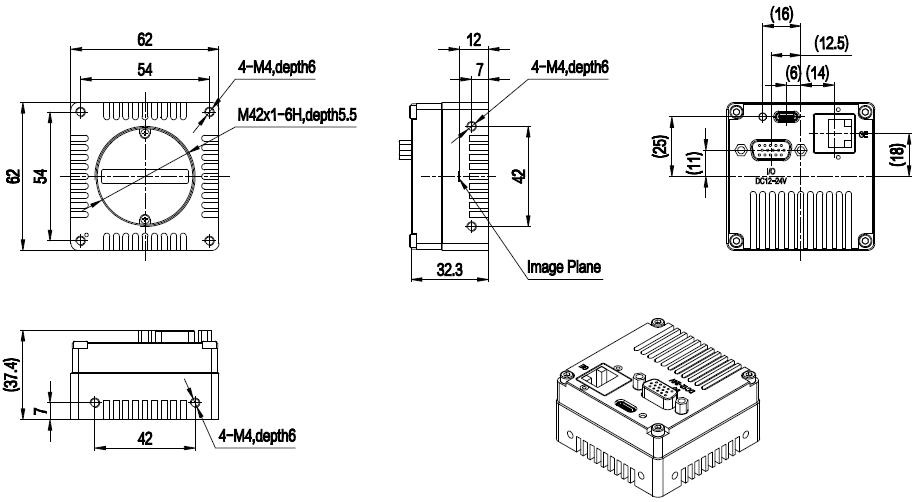
# 摘要
本文全面介绍PL4KGV-30KC设备,包括其基础知识、操作界面、功能、实践操作案例以及高级应用与优化。首先概述了PL4KGV-30KC的基础知识和操作界面布局,随后深入分析其菜单设置、连接通讯以及测量、数据分析等实践操作。文中还探讨了该设备的高级应用,如自定义程序开发、扩展模块集成以及性能调优策略。最后,本文讨论了社区资源的
【海思3798MV100刷机终极指南】:创维E900-S系统刷新秘籍,一次成功!

# 摘要
本文系统介绍了海思3798MV100的刷机全过程,涵盖预备知识、工具与固件准备、实践步骤、进阶技巧与问题解决,以及刷机后的安全与维护措施。文章首先讲解了刷机的基础知识和必备工具的获取与安装,然后详细描述了固件选择、备份数据、以及降低刷机风险的方法。在实践步骤中,作者指导读者如何进入刷机模式、操作刷机流程以及完成刷机后的系统初始化和设置。进阶技巧部分涵盖了刷机中
IP5306 I2C与SPI性能对决:深度分析与对比
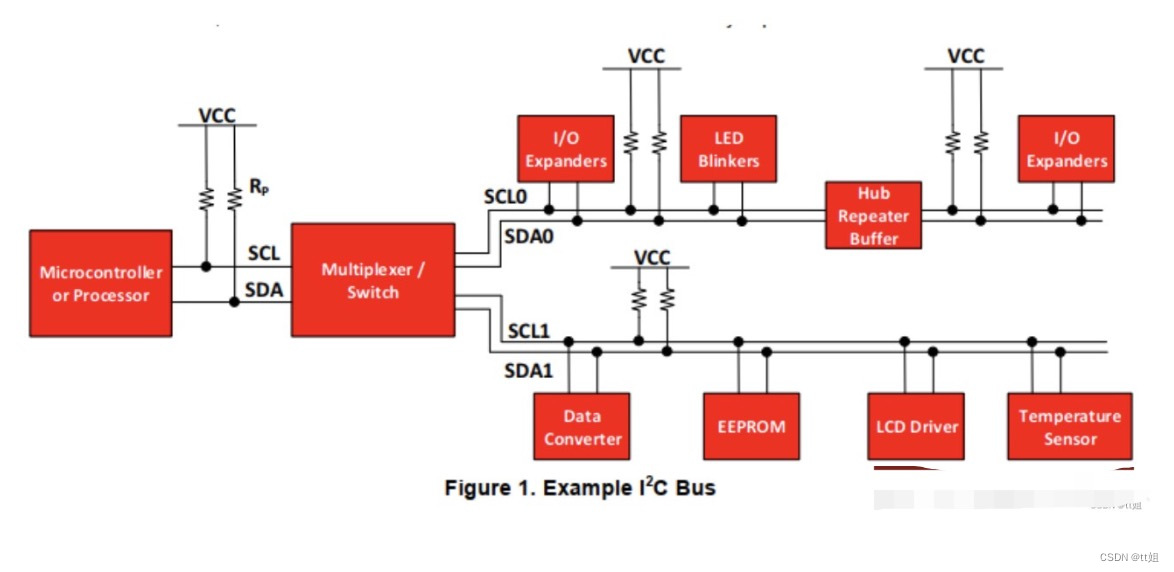
# 摘要
随着电子设备与嵌入式系统的发展,高效的数据通信协议变得至关重要。本文首先介绍了I2C和SPI这两种广泛应用于嵌入式设备的通信协议的基本原理及其在IP5306芯片中的具体实现。通过性能分析,比较了两种协议在数据传输速率、带宽、延迟、兼容性和扩展性方面的差异,并探讨了IP5306在电源管理和嵌入式系统中的应用案例。最后,提出针对I2C与SPI协议性能优化的策略和实践建议,并对未来技术发展趋势进行了
性能优化秘籍:提升除法器设计的高效技巧
# 摘要
本文综合探讨了除法器设计中的性能瓶颈及其优化策略。通过分析理论基础与优化方法论,深入理解除法器的工作原理和性能优化理论框架。文章详细介绍了硬件设计的性能优化实践,包括算法、电路设计和物理设计方面的优化技术。同时,本文也探讨了软件辅助设计与模拟优化的方法,并通过案例研究验证了优化策略的有效性。文章最后总结了研究成果,并指出了进一步研究的方向,包括新兴技术在除法器设计中的应用及未来发展趋势。
# 关键字
除法器设计;性能瓶颈;优化策略;算法优化;电路设计;软件模拟;协同优化
参考资源链接:[4除4加减交替法阵列除法器的设计实验报告](https://wenku.csdn.net/do
FSIM分布式处理:提升大规模图像处理效率

# 摘要
FSIM分布式处理是将图像处理任务分散到多个处理单元中进行,以提升处理能力和效率的一种技术。本文首先概述了FSIM分布式处理的基本概念,并详细介绍了分布式计算的理论基础,包括其原理、图像处理算法、以及架构设计。随后,本文通过FSIM分布式框架的搭建和图像处理任务的实现,进一步阐述了分布式处理的实际操作过程。此外,本文还探讨了FSIM分布式处理在性能评估、优化策略以及高级应用方面的
IEC 60068-2-31冲击试验的行业应用:案例研究与实践

# 摘要
IEC 60068-2-31标准为冲击试验提供了详细规范,是评估产品可靠性的重要依据。本文首先概述了IEC 60068-2-31标准,然后
【高维数据的概率学习】:面对挑战的应对策略及实践案例
# 摘要
高维数据的概率学习是处理复杂数据结构和推断的重要方法,本文概述了其基本概念、理论基础与实践技术。通过深入探讨高维数据的特征、概率模型的应用、维度缩减及特征选择技术,本文阐述了高维数据概率学习的理论框架。实践技术部分着重介绍了概率估计、推断、机器学习算法及案例分析,着重讲解了概率图模型、高斯过程和高维稀疏学习等先进算法。最后一章展望了高维数据概率学习的未来趋势与挑战,包括新兴技术的应用潜力、计算复杂性问题以及可解释性研究。本文为高维数据的概率学习提供了一套全面的理论与实践指南,对当前及未来的研究方向提供了深刻见解。
# 关键字
高维数据;概率学习;维度缩减;特征选择;稀疏学习;深度学
【RTL8812BU模块调试全攻略】:故障排除与性能评估秘籍
# 摘要
本文详细介绍了RTL8812BU无线模块的基础环境搭建、故障诊断、性能评估以及深入应用实例。首先,概述了RTL8812BU模块的基本信息,接着深入探讨了其故障诊断与排除的方法,包括硬件和软件的故障分析及解决策略。第三章重点分析了模块性能评估的关键指标与测试方法,并提出了相应的性能优化策略。第四章则分享了定制化驱动开发的经验、网络安全的增强方法以及多模块协同工作的实践。最后,探讨了新兴技术对RTL8812BU模块未来的影响,并讨论了模块的可持续发展趋势。本文为技术人员提供了全面的RTL8812BU模块应用知识,对于提高无线通信系统的效率和稳定性具有重要的参考价值。
# 关键字
RTL
VC709开发板原理图挑战:信号完整性与电源设计的全面解析(硬件工程师必读)
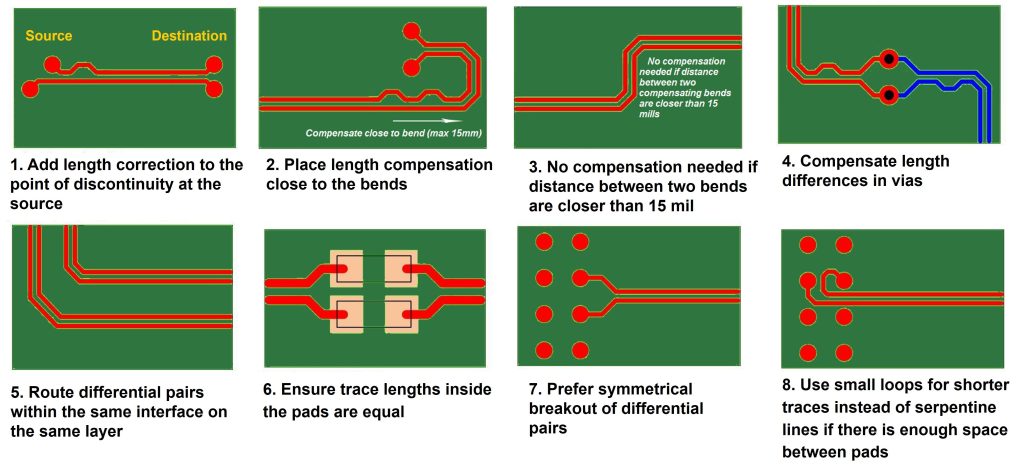
# 摘要
本文旨在详细探讨VC709开发板的信号和电源完整性设计,以及这些设计在实践中面临的挑战和解决方案。首先概述了VC709开发板的基本情况,随后深入研究了信号完整性与电源完整性基础理论,并结合实际案例分析了设计中的关键问题和对策。文章进一步介绍了高级设计技巧和最新技术的应用,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )