从初学者到专家:掌握Django ORM中的ForeignKey,打造高效数据库关系
发布时间: 2024-10-12 09:52:48 阅读量: 69 订阅数: 32 

django中的数据库迁移的实现

# 1. 理解Django ORM中的ForeignKey基础
Django ORM (Object-Relational Mapping) 是一个强大的数据库抽象层,它允许开发者使用Python语言来操作数据库中的数据。在Django中,`ForeignKey` 是一种特殊的字段类型,用于在模型(Model)之间建立关联关系,尤其是指定了“一对多”的关系。本章将引导读者理解ForeignKey的基本概念和使用方法,为深入学习后续章节打下基础。
在本章中,我们将首先介绍ForeignKey字段的基本用法,包括如何在Django模型中定义和创建ForeignKey字段。之后,我们将详细探讨ForeignKey的各种参数,这些参数可以帮助开发者更好地控制字段行为和数据关系。
为了帮助读者更好地理解和应用ForeignKey,本章还会提供一些实际的例子和代码示例,展示如何在实际项目中应用这些基础知识。
以上是第一章的内容概要。接下来,我们将深入探讨ForeignKey的具体使用和优化,为接下来的高级特性探讨打下坚实的基础。
# 2. 深入探究ForeignKey的高级特性
### 2.1 ForeignKey的定义和基本用法
#### 2.1.1 创建和使用ForeignKey字段
在Django中,`ForeignKey`是一种特殊的字段类型,用于定义模型间的一对多关系。它指向另一个模型的主键,并在数据库层面创建一个外键约束。在定义时,`ForeignKey`字段的第一个参数是关联模型的类名。
```python
from django.db import models
class Manufacturer(models.Model):
name = models.CharField(max_length=255)
class Car(models.Model):
manufacturer = models.ForeignKey(Manufacturer, on_delete=models.CASCADE)
```
以上代码定义了两个模型`Manufacturer`和`Car`。`Car`模型中包含一个`ForeignKey`字段`manufacturer`,它关联到`Manufacturer`模型。`on_delete=models.CASCADE`参数指定了当一个`Manufacturer`实例被删除时,所有关联的`Car`实例也会被一同删除。
#### 2.1.2 ForeignKey的参数详解
`ForeignKey`字段提供了多个参数来自定义字段行为:
- `on_delete`: 定义了当关联的对象被删除时应该执行的操作。常见的选项有`CASCADE`(级联删除)、`PROTECT`(阻止删除)、`SET_NULL`(设置为null)等。
- `related_name`: 允许你为关联的反向查询指定一个名称。默认情况下,Django会为反向关系使用`<model_name>_set`的形式。
- `limit_choices_to`: 用于限制在管理界面中可以关联的实例。比如,`limit_choices_to={'active': True}`将只显示活跃的`Manufacturer`。
- `to_field`: 如果不指定,Django默认使用关联模型的主键。这个参数允许你指定另一个字段作为外键。
### 2.2 ForeignKey的查询优化
#### 2.2.1 优化数据库查询性能
在使用`ForeignKey`进行数据操作时,优化查询性能是很重要的。首先,需要避免`n+1`查询问题,即在一个集合上执行N+1次数据库查询。例如,遍历所有汽车时,不应当每次都查询制造商:
```python
# 不优化的查询
for car in Car.objects.all():
print(car.manufacturer.name)
# 优化后的查询
cars = Car.objects.select_related('manufacturer')
for car in cars:
print(car.manufacturer.name)
```
使用`select_related`可以在一个查询中预加载关联对象,从而减少数据库访问次数。
#### 2.2.2 使用select_related和prefetch_related
`select_related`用于优化单个`ForeignKey`的查询,而`prefetch_related`用于优化多对多(`ManyToMany`)关系或一对多关系中的反向查询。
```python
# 使用prefetch_related进行优化
manufacturers = Manufacturer.objects.prefetch_related('car_set')
for manufacturer in manufacturers:
for car in manufacturer.car_set.all():
print(car)
```
`prefetch_related`会生成一个包含多个查询的查询集,每个查询用于获取关联对象集,然后Django会在Python中通过字典合并这些对象,从而减少数据库访问次数。
#### 2.2.3 理解数据库索引的作用
为`ForeignKey`字段创建索引可以提高查询效率。在创建外键字段时,Django会自动为该字段添加索引。如果表的查询非常频繁,可以在字段上额外添加索引来进一步优化性能。
```python
class Car(models.Model):
manufacturer = models.ForeignKey(
Manufacturer,
on_delete=models.CASCADE,
db_index=True # 添加索引优化查询性能
)
```
使用`db_index=True`参数,可以为`manufacturer`字段添加一个数据库索引。索引使得查询操作更快,但也增加了数据库插入、更新和删除操作的开销。
### 2.3 ForeignKey与Django表单的交互
#### 2.3.1 在表单中使用ForeignKey
在Django表单中,`ForeignKey`字段通常表现为一个`ModelChoiceField`,它允许用户从一个下拉列表中选择一个关联的对象。
```python
from django import forms
from .models import Car, Manufacturer
class CarForm(forms.ModelForm):
manufacturer = forms.ModelChoiceField(queryset=Manufacturer.objects.all())
class Meta:
model = Car
fields = ['manufacturer', ...]
```
在上面的表单中,`CarForm`通过`manufacturer`字段让用户可以选择一个`Manufacturer`对象。
#### 2.3.2 处理多对多关系的表单字段
处理多对多关系时,使用`ModelMultipleChoiceField`。这个字段允许用户选择多个对象,例如:
```python
from django.forms import ModelMultipleChoiceField
class ManufacturerForm(forms.ModelForm):
cars = ModelMultipleChoiceField(queryset=Car.objects.all(), required=False)
class Meta:
model = Manufacturer
fields = ['cars', ...]
```
在`ManufacturerForm`中,`cars`字段允许管理员为一个制造商选择多个汽车。参数`required=False`表示这个字段不是必须的,用户可以选择不选任何汽车。
# 3. 实践ForeignKey进行数据建模
## 3.1 设计复杂关系的数据库模型
### 3.1.1 分析业务需求
在构建一个复杂关系的数据库模型之前,首先需要深入分析业务需求。这个过程包括理解业务领域、数据流转、以及数据之间的关系。例如,在电商系统中,我们需要理解商品如何分类、如何关联到用户购买的订单,以及如何处理商品的库存和价格变化等。这些需求将直接影响数据模型的设计,包括如何使用ForeignKey以及其他Django模型字段来定义实体间的关系。
### 3.1.2 创建模型并设置关系
一旦业务需求分析完毕,接下来就是创建模型并设置关系。在Django中,使用模型类来表示数据库中的表,而字段则是表的列。ForeignKey字段在模型中定义为一个类属性,并且指向另一个模型类的实例,从而建立了一个表之间的关联。例如,电商系统中的商品和分类的关联可以用如下代码实现:
```python
class Category(models.Model):
name = models.CharField(max_length=100)
class Product(models.Model):
name = models.CharField(max_length=100)
category = models.ForeignKey(Category, on_delete=models.CASCADE)
# 其他字段定义...
```
这段代码创建了两个模型类:`Category`和`Product`。`Product`类中的`category`字段是一个ForeignKey,它关联到`Category`模型。`on_delete=models.CASCADE`参数表示当关联的分类被删除时,所有相关联的商品也将被删除。
## 3.2 使用ForeignKey处理数据一致性
### 3.2.1 外键约束的理解和应用
在数据库设计中,外键约束是保证数据一致性的重要工具。外键约束确保了两个表之间的参照完整性,即一个表的某列的值必须是另一个表中的某列的值。在Django中,通过在ForeignKey字段中设置`on_delete`参数来实现这一功能。该参数决定了当被引用的对象被删除时,引用对象的行为。Django提供了多种选项,如`models.CASCADE`、`models.SET_NULL`、`models.PROTECT`等,每种选项都有其特定的应用场景。
### 3.2.2 避免循环依赖和级联更新
循环依赖和级联更新是数据库设计中的两个潜在问题,它们可能引起数据一致性的破坏。循环依赖发生在多个表通过外键彼此相互引用时,这可能导致数据更新或删除时出现死锁或者无限递归的问题。级联更新指的是当一个表中的记录更新后,它会自动更新所有引用了这个记录的其他表中的相应记录。这可能会导致意外的数据变更和数据不一致的问题。
为了避免这些问题,Django ORM提供了对级联行为的精细控制。在定义ForeignKey时,我们可以仔细考虑`on_delete`和`related_name`参数的使用,并且在必要时使用数据库的事务管理来控制数据变更的逻辑。
## 3.3 案例分析:构建电商商品关系
### 3.3.1 设计商品分类和属性模型
在构建电商系统的商品分类和属性模型时,我们首先需要定义商品本身以及它的属性。例如,商品可能有多个分类,并且具有多个属性,如价格、库存、颜色、尺寸等。这可以通过在商品模型中定义多个ForeignKey字段来实现,每个字段指向不同的分类或属性模型。
### 3.3.2 实现商品和订单的关联
商品和订单之间的关联通常是多对多的关系,因为一个订单可以包含多种商品,而一个商品也可以出现在多个订单中。在Django中,可以使用多对多字段(`ManyToManyField`)来定义这种关系。下面的代码展示了如何在订单模型中引用商品模型:
```python
class Order(models.Model):
# 其他字段定义...
products = models.ManyToManyField(Product, through='OrderItem')
class OrderItem(models.Model):
order = models.ForeignKey(Order, on_delete=models.CASCADE)
product = models.ForeignKey(Product, on_delete=models.CASCADE)
quantity = models.IntegerField()
```
在上述代码中,`OrderItem`作为中间模型,处理了商品与订单之间的多对多关系,并存储了额外信息,比如购买数量(`quantity`)。通过这种设计,我们不仅实现了商品和订单之间的关联,还能够灵活地扩展数据模型,以存储关于商品在订单中的更多信息。
# 4. 在项目中优化ForeignKey性能
## 4.1 优化数据库访问层代码
### 4.1.1 理解Django的数据库访问抽象
Django为数据库的访问提供了丰富的抽象,包括模型(Model)、查询集(QuerySet)和数据库游标(Database connection cursor)。理解这些抽象的工作原理是优化性能的第一步。模型代表数据库中的表,查询集代表一系列的对象,而数据库游标则用于直接执行SQL语句。
使用Django的ORM系统能减少直接编写原生SQL的需要,但了解ORM背后如何工作可以让我们编写更高效的代码。例如,Django的QuerySet API能够构建复杂的查询,但有时直接编写SQL语句会更加高效。
### 4.1.2 提高查询效率的技巧
在Django项目中,优化查询效率是提高应用性能的关键。以下是一些提高查询效率的技巧:
- **减少数据库访问次数**:使用`select_related`和`prefetch_related`方法可以减少数据库查询次数。`select_related`用于优化外键和一对多关系的查询,而`prefetch_related`用于优化多对多和反向外键关系的查询。
- **使用数据库索引**:为常用的查询字段添加索引可以显著提升查询速度。在Django模型字段中,可以设置`db_index=True`来创建索引。
- **避免N+1查询问题**:这是指在遍历查询集时,每遍历一个对象就产生一次数据库查询,导致性能下降。可以使用`prefetch_related`或者在查询集中使用`iterator()`方法解决。
- **使用Django的聚合和annotate**:在需要对数据进行分组或计算聚合数据时,使用`aggregate`和`annotate`可以一次性完成,而无需多次查询数据库。
### 代码块展示
下面是一个示例代码块,演示如何使用`prefetch_related`来减少数据库访问次数:
```python
# 获取所有的书籍和关联的作者信息
books_with_authors = Book.objects.prefetch_related('author_set').all()
for book in books_with_authors:
print(book.title, book.author_set.all()) # 只有一次数据库查询
```
在上述代码中,`prefetch_related`将获取所有的书籍(Book)对象,并预先加载关联的作者(Author)对象。这避免了在迭代每个书籍对象时产生额外的查询。
## 4.2 使用数据库事务处理复杂操作
### 4.2.1 事务的基本概念
在数据库操作中,事务是一个单一的工作单元,它可以是修改数据库中数据的一系列操作。事务具有一些基本属性,统称为ACID特性:
- **原子性(Atomicity)**:事务中的所有操作要么全部完成,要么全部不完成。
- **一致性(Consistency)**:事务必须使数据库从一个一致性状态转换到另一个一致性状态。
- **隔离性(Isolation)**:事务的中间状态对外部是不可见的。
- **持久性(Durability)**:一旦事务提交,其所做的修改就会永久保存在数据库中。
### 4.2.2 Django中事务的使用
Django提供了`transaction`模块来控制事务。可以使用`@transaction.atomic`装饰器或`transaction.atomic()`上下文管理器来确保代码块中的数据库操作以事务的形式执行。
下面是一个代码示例,演示如何使用事务处理一个复杂的操作,确保其原子性:
```python
from django.db import transaction
@transaction.atomic
def transfer_funds(sender, recipient, amount):
sender.balance -= amount
recipient.balance += amount
sender.save()
recipient.save()
transfer_funds(sender_account, recipient_account, 100)
```
在上面的示例中,转账操作被封装在`@transaction.atomic`装饰的函数中,这样,如果在过程中发生任何异常,所有的数据库更改都将被回滚,保证了操作的原子性。
## 4.3 分析和解决ForeignKey相关问题
### 4.3.1 常见问题的诊断与解决
在使用ForeignKey字段时,开发者可能会遇到一些常见问题,如循环依赖、级联更新引发的数据不一致等。在诊断和解决这些问题时,需要具体问题具体分析。例如,循环依赖可以通过调整模型关系的顺序来解决;级联更新则需要在ForeignKey字段中设置`on_delete`参数来控制。
### 4.3.2 分析数据库性能瓶颈
当应用运行变慢时,数据库性能瓶颈可能是罪魁祸首。利用Django的`debug`工具栏,可以查看查询的执行时间和相关的SQL语句,从而分析出哪些查询是耗时的。此外,数据库系统本身也提供了性能分析工具,比如PostgreSQL的`EXPLAIN`。
下面是一个示例,使用Django的`debug`工具栏中的`SQL`面板来分析性能:
```mermaid
graph TD
A[开始分析] --> B[检查Slow Queries]
B --> C[查看Query详情]
C --> D[分析Query执行计划]
D --> E[优化慢查询]
E --> F[验证优化效果]
```
通过上述流程图,我们可以了解性能瓶颈分析的基本步骤。首先,检查工具栏中的慢查询(Slow Queries);然后,查看具体查询的详细信息;接着分析查询的执行计划(Explain Plan);最后,对慢查询进行优化,并验证优化后的效果。
接下来,使用以下Django代码块优化慢查询:
```python
from django.db import connection
def optimize_query(query):
with connection.cursor() as cursor:
cursor.execute("EXPLAIN ANALYZE " + query)
result = cursor.fetchall()
return result
slow_query = "SELECT * FROM your_table WHERE condition;"
optimized_result = optimize_query(slow_query)
```
在这个代码块中,我们利用Django的数据库连接对象,执行`EXPLAIN ANALYZE`命令来获取查询的执行计划和性能指标。这将帮助我们了解查询的性能瓶颈所在,并据此优化数据库操作。
以上章节内容展示了如何在项目中优化使用ForeignKey时遇到的性能问题,通过理解Django的数据库访问抽象、合理使用数据库事务、以及分析数据库性能瓶颈来提高应用性能。在实际操作中,开发者应将这些知识应用到项目实践中,不断优化代码,以达到最佳性能表现。
# 5. ForeignKey进阶应用与未来展望
## 5.1 扩展ForeignKey功能
### 5.1.1 自定义ForeignKey类
在Django中,ForeignKey字段是非常灵活的,它允许我们通过继承`models.ForeignKey`来创建自定义的外键类。这样做可以让我们在项目中重用某些特定的外键设置,减少重复代码,并增强模型之间的关系管理。
例如,假设我们需要为多个模型添加一个特殊的外键,该外键需要添加额外的查询参数。我们可以定义一个自定义的`ForeignKey`类:
```python
from django.db import models
class CustomForeignKey(models.ForeignKey):
def __init__(self, to, on_delete=models.CASCADE, **kwargs):
kwargs['db_table'] = kwargs.get('db_table', 'custom_foreign_key_table')
super().__init__(to, on_delete=on_delete, **kwargs)
class MyModel(models.Model):
my_field = CustomForeignKey('to.AnyModel', on_delete=models.CASCADE)
```
在这个例子中,我们创建了一个新的`CustomForeignKey`类,它接受与常规`ForeignKey`相同的参数,并添加了一个自定义的数据库表名。然后我们可以像使用普通的`ForeignKey`一样,在模型中使用它。
### 5.1.2 使用第三方库增强功能
第三方库为Django ORM提供了额外的功能,扩展了模型间关系的处理能力。例如,`django-mptt`用于管理具有树形结构的数据,`django-model-utils`提供了更易于使用的字段类型,例如`TimeStampedModel`和`SoftDeletableModel`。
使用第三方库,我们不仅可以简化代码,还可以实现一些原生Django ORM不支持的高级功能。例如,如果我们需要管理一个具有层次结构的模型,我们可以使用`django-mptt`提供的`MPTTModel`和`TreeForeignKey`:
```python
from django.db import models
from mptt.models import MPTTModel, TreeForeignKey
class Category(MPTTModel, models.Model):
parent = TreeForeignKey('self', on_delete=models.CASCADE, null=True, blank=True, related_name='children')
```
在上面的代码中,我们创建了一个`Category`模型,它使用`MPTTModel`作为基础,可以方便地构建和查询树形结构。
## 5.2 Django ORM的未来趋势
### 5.2.1 ORM技术的发展方向
随着数据处理需求的日益增长,ORM技术正朝着更加高效、智能和用户友好的方向发展。未来的ORM工具将更加注重性能优化,同时提供更高级的数据抽象和更灵活的查询接口。
一种趋势是使用更细粒度的数据库操作,如存储过程和触发器,以减少数据传输和加快处理速度。另一个方向是增强ORM的元数据管理和代码生成能力,使得数据库模式和应用层代码能够更紧密地集成。
### 5.2.2 Django ORM可能的改进与更新
Django团队致力于不断改进和更新其ORM框架。随着技术的发展,Django ORM预计会引入更多的优化技术,例如更好的缓存机制、异步数据库操作、以及更复杂的查询优化策略。
此外,Django社区一直在积极讨论对数据库事务、非阻塞操作以及数据库连接池的支持,这些都是为了提高大型应用的性能和可靠性。
## 5.3 建立企业级数据库模型的最佳实践
### 5.3.1 高级数据模型设计原则
设计企业级数据库模型时,需要考虑数据的一致性、可扩展性和性能。首先,我们应当遵循数据库规范化原则,减少数据冗余。同时,合理使用索引可以显著提高查询效率。模型应支持横向扩展,以便可以增加更多服务器来处理增加的数据量和负载。
其次,数据模型需要支持灵活的查询和报告功能,这对于任何业务分析和决策过程都是必不可少的。最后,随着数据模型变得越来越复杂,使用版本控制和迁移策略来管理数据库变更变得至关重要。
### 5.3.2 案例研究:构建可扩展的数据库架构
假设我们要构建一个具有高流量的电商应用。我们需要设计一个能够轻松处理大量并发用户请求的数据库架构。我们可以采用读写分离的策略,将查询和更新操作分布在不同的数据库服务器上。这样,读操作可以分散到多个只读副本上,而更新操作仍然由主服务器处理。
此外,我们可以使用分片技术来进一步提高扩展性,将大型表分割成更小、更易于管理的片。分片可以根据特定的键(如用户ID或地理位置)进行,使得查询更高效,同时减轻单个数据库服务器的负载。
为了保证数据的一致性和可靠性,应使用事务保证跨多个表和操作的事务完整性。我们还可以使用触发器和存储过程来自动执行复杂的业务逻辑,减少应用层的负担。
```mermaid
graph LR
A[开始] --> B[分析业务需求]
B --> C[创建模型]
C --> D[设置关系]
D --> E[优化外键约束]
E --> F[避免级联更新]
F --> G[评估数据库索引]
G --> H[构建可扩展的数据库架构]
```
以上就是构建企业级数据库模型的最佳实践案例分析。通过遵循这些原则和实践,我们可以确保我们的数据库架构不仅能够满足当前的需求,还能适应未来的增长和变化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析了 Django ORM 中至关重要的 `django.db.models.fields.related` 模块,旨在帮助开发者充分利用关系字段,优化数据库性能并提升代码复用性。通过一系列深入浅出的文章,本专栏涵盖了各种关系字段类型,包括一对一、一对多、多对多以及自定义字段关系的构建。此外,还探讨了反向关系、事务管理、安全性、性能优化以及缓存策略等高级主题。本专栏旨在为 Django 开发者提供全面的指南,帮助他们掌握关系字段的方方面面,构建高效、安全且可扩展的数据库架构。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单高级应用

# 摘要
扇形菜单作为一种创新的用户界面设计方式,近年来在多个应用领域中显示出其独特优势。本文概述了扇形菜单设计的基本概念和理论基础,深入探讨了其用户交互设计原则和布局算法,并介绍了其在移动端、Web应用和数据可视化中的应用案例
C++ Builder高级特性揭秘:探索模板、STL与泛型编程

# 摘要
本文系统性地介绍了C++ Builder的开发环境设置、模板编程、标准模板库(STL)以及泛型编程的实践与技巧。首先,文章提供了C++ Builder的简介和开发环境的配置指导。接着,深入探讨了C++模板编程的基础知识和高级特性,包括模板的特化、非类型模板参数以及模板
【深入PID调节器】:掌握自动控制原理,实现系统性能最大化

# 摘要
PID调节器是一种广泛应用于工业控制系统中的反馈控制器,它通过比例(P)、积分(I)和微分(D)三种控制作用的组合来调节系统的输出,以实现对被控对象的精确控制。本文详细阐述了PID调节器的概念、组成以及工作原理,并深入探讨了PID参数调整的多种方法和技巧。通过应用实例分析,本文展示了PID调节器在工业过程控制中的实际应用,并讨
【Delphi进阶高手】:动态更新百分比进度条的5个最佳实践

# 摘要
本文针对动态更新进度条在软件开发中的应用进行了深入研究。首先,概述了进度条的基础知识,然后详细分析了在Delphi环境下进度条组件的实现原理、动态更新机制以及多线程同步技术。进一步,文章探讨了数据处理、用户界面响应性优化和状态视觉呈现的实践技巧,并提出了进度
【TongWeb7架构深度剖析】:架构原理与组件功能全面详解
# 摘要
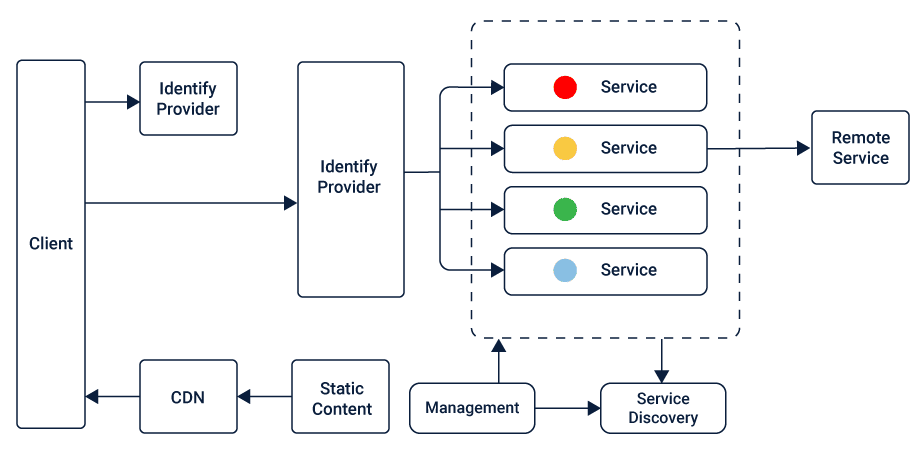
TongWeb7作为一个复杂的网络应用服务器,其架构设计、核心组件解析、性能优化、安全性机制以及扩展性讨论是本文的主要内容。本文首先对TongWeb7的架构进行了概述,然后详细分析了其核心中间件组件的功能与特点,接着探讨了如何优化性能监控与分析、负载均衡、缓存策略等方面,以及安全性机制中的认证授权、数据加密和安全策略实施。最后,本文展望
【S参数秘籍解锁】:掌握驻波比与S参数的终极关系
# 摘要
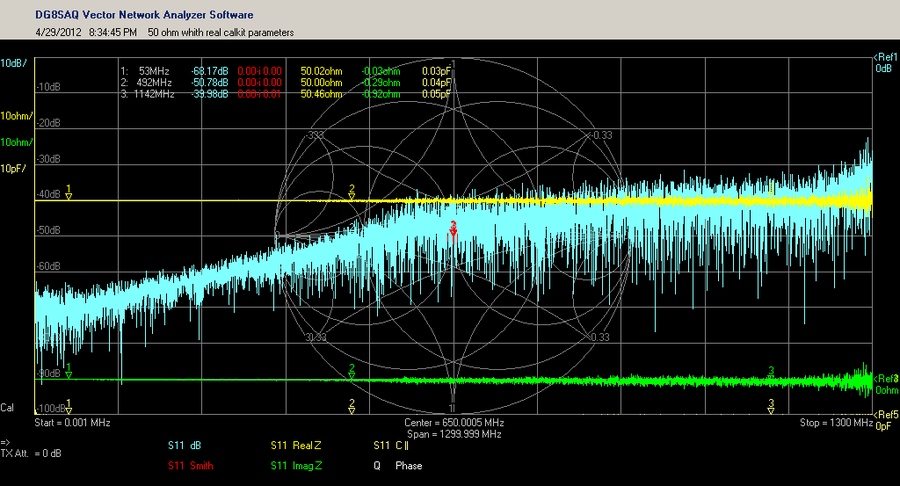
本论文详细阐述了驻波比与S参数的基础理论及其在微波网络中的应用,深入解析了S参数的物理意义、特性、计算方法以及在电路设计中的实践应用。通过分析S参数矩阵的构建原理、测量技术及仿真验证,探讨了S参数在放大器、滤波器设计及阻抗匹配中的重要性。同时,本文还介绍了驻波比的测量、优化策略及其与S参数的互动关系。最后,论文探讨了S参数分析工具的使用、高级分析技巧,并展望
【嵌入式系统功耗优化】:JESD209-5B的终极应用技巧
# 摘要
本文首先概述了嵌入式系统功耗优化的基本情况,随后深入解析了JESD209-5B标准,重点探讨了该标准的框架、核心规范、低功耗技术及实现细节。接着,本文奠定了功耗优化的理论基础,包括功耗的来源、分类、测量技术以及系统级功耗优化理论。进一步,本文通过实践案例深入分析了针对JESD209-5B标准的硬件和软件优化实践,以及不同应用场景下的功耗优化分析。最后,展望了未来嵌入式系统功耗优化的趋势,包括新兴技术的应用、JESD209-5B标准的发展以及绿色计算与可持续发展的结合,探讨了这些因素如何对未来的功耗优化技术产生影响。
# 关键字
嵌入式系统;功耗优化;JESD209-5B标准;低功耗
ODU flex接口的全面解析:如何在现代网络中最大化其潜力
# 摘要
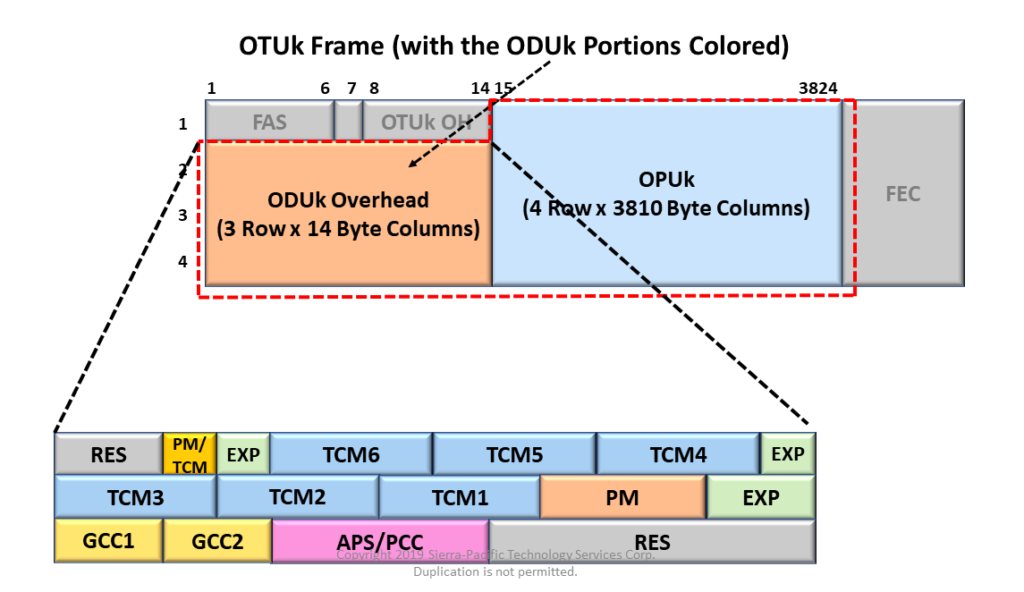
ODU flex接口作为一种高度灵活且可扩展的光传输技术,已经成为现代网络架构优化和电信网络升级的重要组成部分。本文首先概述了ODU flex接口的基本概念和物理层特征,紧接着深入分析了其协议栈和同步机制,揭示了其在数据中心、电信网络、广域网及光纤网络中的应用优势和性能特点。文章进一步
如何最大化先锋SC-LX59的潜力
# 摘要
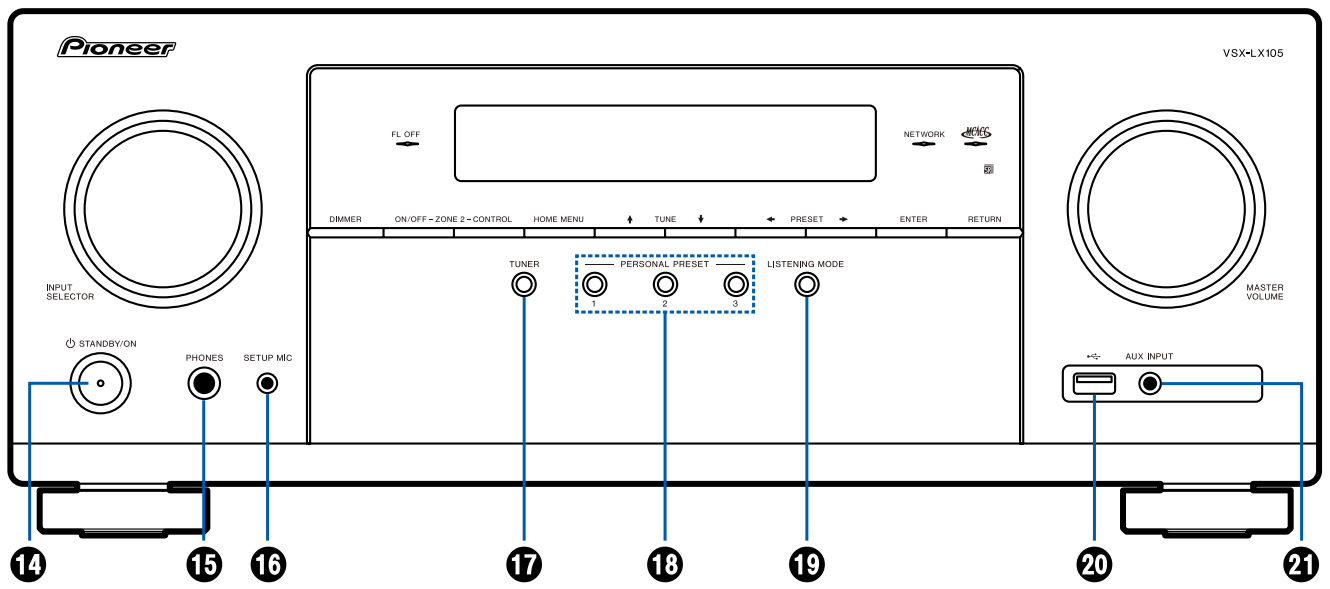
先锋SC-LX59作为一款高端家庭影院接收器,其在音视频性能、用户体验、网络功能和扩展性方面均展现出巨大的潜力。本文首先概述了SC-LX59的基本特点和市场潜力,随后深入探讨了其设置与配置的最佳实践,包括用户界面的个性化和音画效果的调整,连接选项与设备兼容性,以及系统性能的调校。第三章着重于先锋SC-LX59在家庭影院中的应用,特别强调了音视频极致体验、智能家居集成和流媒体服务的充分利用。在高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )