Detailed Solutions for MATLAB Chinese Command Line Display Issues: 5 Solutions for Easy Control of Chinese Command Line
发布时间: 2024-09-13 18:57:32 阅读量: 38 订阅数: 30 

FPGA技术资料 A Detailed Rounter for FPGA-综合文档
# 1. Detailed Explanation of Issues with MATLAB Chinese Command Line Display: 5 Solutions for Easy Control of Chinese Command Lines
As a powerful technical computing software, MATLAB is widely used in scientific research, engineering design, and data analysis. However, after localizing MATLAB into Chinese, users may encounter garbled text issues on the command line, which can affect the user experience. This chapter provides an overview of the problems with MATLAB localized command line display, laying the groundwork for subsequent analysis of causes and solutions.
The issue with MATLAB localized command line display manifests as garbled or missing Chinese characters on the command line, making it difficult for users to read and understand command line outputs. This problem may be caused by various factors, including inconsistent character encoding, incorrect font settings, and system environment variable configuration issues. By understanding these potential causes, we can tailor solutions to effectively address the issue of MATLAB localized command line display.
# 2. Cause Analysis of MATLAB Localized Command Line Display Problems
The problems with MATLAB localized command line display are mainly caused by the following three reasons:
### 2.1 Inconsistent Character Encoding
MATLAB defaults to using UTF-8 character encoding, while Chinese operating systems typically use GBK or GB2312 character encoding. When MATLAB outputs Chinese characters on the command line, if the character encoding is inconsistent, garbled text will occur.
### 2.2 Incorrect Font Settings
MATLAB command line display of Chinese requires the use of Chinese fonts. If there are no Chinese fonts installed in the MATLAB editor, or the font settings are incorrect, Chinese characters will also become garbled.
### 2.3 System Environment Variable Configuration Issues
System environment variables contain information needed for MATLAB to run, including language environment variables and font paths. If these environment variables are not configured correctly, MATLAB command line display of Chinese may also become garbled.
### 2.3.1 Language Environment Variables
The language environment variable LANG specifies the default language and character set of the system. If the LANG variable is not set correctly, MATLAB may not be able to correctly recognize Chinese characters.
### 2.3.2 Font Paths
The system environment variable PATH includes paths to font files. If the PATH variable does not include the path to Chinese fonts, the MATLAB editor will not be able to load Chinese fonts, resulting in garbled Chinese text.
# 3. Solutions to the MATLAB Localized Command Line Display Problems
### 3.1 Modifying Character Encoding
Inconsistent character encoding is a common cause of MATLAB localized command line display problems. The solution is to set MATLAB's character encoding to be consistent with the system, specifically using one of the following two methods:
#### 3.1.1 Setting MATLAB Launch Options
In the MATLAB command line window, enter the fol

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Odroid XU4与Raspberry Pi比较分析
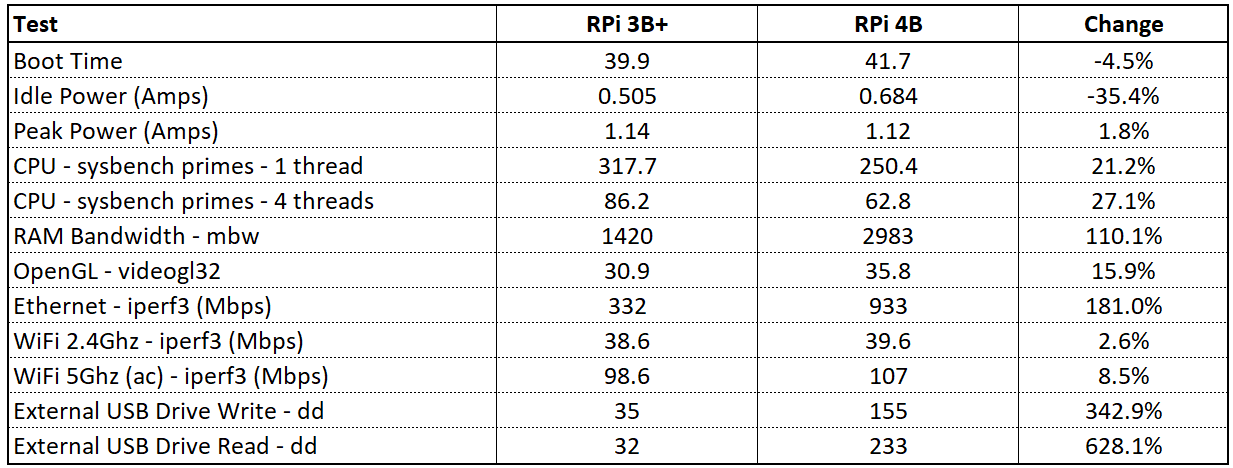
# 摘要
本文详细比较了Odroid XU4与Raspberry Pi的硬件规格、操作系统兼容性、性能测试与应用场景分析,并进行了成本效益分析。通过对比处理器性能、内存存储能力、扩展性和连接性等多个维度,揭示了两款单板计算机的优劣。文章还探讨了它们在图形处理、视频播放、科学计算和IoT应用等方面的实际表现,并对初次购买成本与长期运营维护成本进行了
WinRAR CVE-2023-38831漏洞全生命周期管理:从漏洞到补丁

# 摘要
WinRAR CVE-2023-38831漏洞的发现引起了广泛关注,本文对这一漏洞进行了全面概述和分析。我们深入探讨了漏洞的技术细节、成因、利用途径以及受影响的系统和应用版本,评估了漏洞的潜在风险和影响等级。文章还提供了详尽的漏洞应急响应策略,包括初步的临时缓解措施、长期修复
【数据可视化个性定制】:用Origin打造属于你的独特图表风格

# 摘要
随着数据科学的发展,数据可视化已成为传达复杂信息的关键手段。本文详细介绍了Origin软件在数据可视化领域的应用,从基础图表定制到高级技巧,再到与其他工具的整合,最后探讨了最佳实践和未来趋势。通过Origin丰富的图表类型、强大的数据处理工具和定制化脚本功能,用户能够深入分析数据并创建直观的图表。此外,本文还探讨了如何利用Origin的自动化和网络功能实现高效的数据可视化协作和分享。通
【初学者到专家】:LAPD与LAPDm帧结构的学习路径与进阶策略
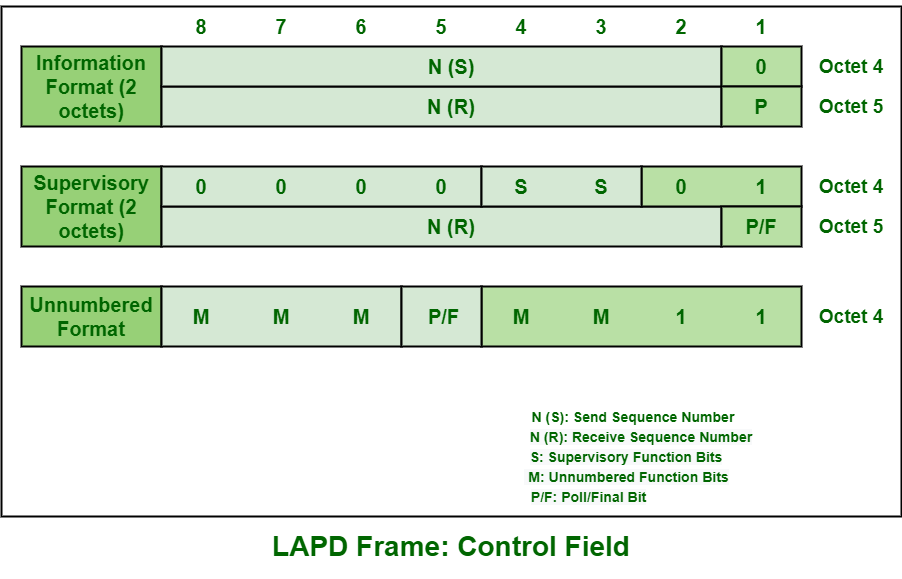
# 摘要
本文全面阐述了LAPD(Link Access Procedure on the D-channel)和LAPDm(LAPD modified)协议的帧结构及其相关理论,并深入探讨了这两种协议在现代通信网络中的应用和重要性。首先,对LAPD和LAPDm的帧结构进行概述,重点分析其组成部分与控制字段。接着,深入解析这两种协议的基础理论,包括历史发展、主要功能与特点
医学成像革新:IT技术如何重塑诊断流程

# 摘要
本文系统探讨了医学成像技术的历史演进、IT技术在其中的应用以及对诊断流程带来的革新。文章首先回顾了医学成像的历史与发展,随后深入分析了IT技术如何改进成像设备和数据管理,特别是数字化技术与PACS的应用。第三章着重讨论了IT技术如何提升诊断的精确性和效率,并阐述了远程医疗和增强现实技术在医学教育和手术规划中的应用。接着,文章探讨了数据安全与隐私保护的挑战,以及加密
TriCore工具链集成:构建跨平台应用的链接策略与兼容性解决

# 摘要
本文对TriCore工具链在跨平台应用构建中的集成进行了深入探讨。文章首先概述了跨平台开发的理论基础,包括架构差异、链接策略和兼容性问题的分析。随后,详细介绍了TriCore工具链的配置、优化以及链接策略的实践应用,并对链接过程中的兼容性
【ARM调试技巧大公开】:在ARMCompiler-506中快速定位问题

# 摘要
本文详述了ARM架构的调试基础,包括ARM Compiler-506的安装配置、程序的编译与优化、调试技术精进、异常处理与排错,以及调试案例分析与实战。文中不仅提供安装和配置ARM编译器的具体步骤,还深入探讨了代码优化、工具链使用、静态和动态调试、性能分析等技术细节。同时,本文还对ARM异常机制进行了解
【远程桌面工具稳定安全之路】:源码控制与版本管理策略
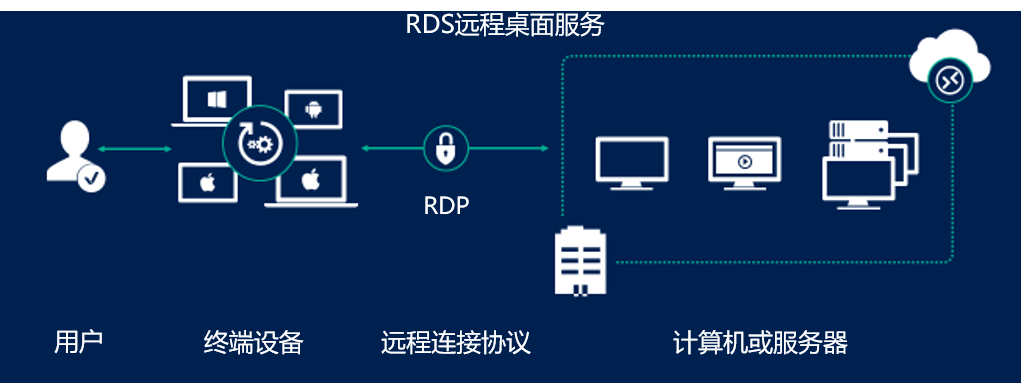
# 摘要
本文系统地介绍了远程桌面工具与源码控制系统的概念、基础和实战策略。文章首先概述了远程桌面工具的重要性,并详细介绍了源码控制系统的理论基础和工具分类,包括集中式与分布式源码控制工具以及它们的工作流程。接着,深入讨论了版本管理策略,包括版本号规范、分支模型选择和最佳实践。本文还探讨了远程桌面工具源码控制策略中的安全、权限管理、协作流程及持续集成。最后,文章展望了版本管理工具与
【网络连接优化】:用AT指令提升MC20芯片连接性能,效率翻倍(权威性、稀缺性、数字型)

# 摘要
随着物联网设备的日益普及,MC20芯片在移动网络通信中的作用愈发重要。本文首先概述了网络连接优化的重要性,接着深入探讨了AT指令与MC20芯片的通信原理,包括AT指令集的发展历史、结构和功能,以及MC20芯片的网络协议栈。基于理论分析,本文阐述了AT指令优化网络连接的理论基础,着重于网络延迟、吞吐量和连接质量的评估。实
【系统稳定性揭秘】:液态金属如何提高计算机物理稳定性
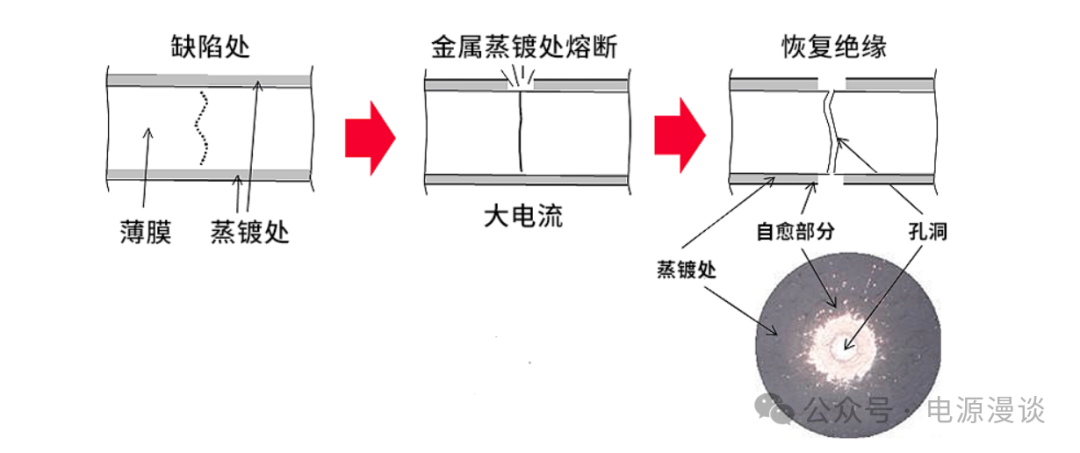
# 摘要
随着计算机硬件性能的不断提升,计算机物理稳定性面临着前所未有的挑战。本文综述了液态金属在增强计算机稳定性方面的潜力和应用。首先,文章介绍了液态金属的理论基础,包括其性质及其在计算机硬件中的应用。其次,通过案例分析,探讨了液态金属散热和连接技术的实践,以及液态金属在提升系统稳定性方面的实际效果。随后,对液态金属技术与传统散热材
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )