深度学习原理与实战应用
发布时间: 2024-02-22 10:57:39 阅读量: 30 订阅数: 31 

深度学习TF—14.WGAN原理及实战 深度学习原理.pdf
# 1. 深度学习简介
### 1.1 深度学习的历史与发展
深度学习起源于20世纪中期,经过多年的发展,特别是近年来大数据和计算能力的快速发展,深度学习取得了显著的突破。2012年,AlexNet在ImageNet比赛上取得了突破性的成绩,标志着深度学习进入了飞速发展的新阶段。
### 1.2 深度学习与传统机器学习的区别
传统机器学习算法主要是基于特征工程和手工设计的模型,而深度学习则通过多层神经网络自动地学习到数据的特征表示,避免了手工设计特征的繁琐和困难。
### 1.3 深度学习的基本原理
深度学习的基本原理是构建多层神经网络,并使用反向传播算法来不断调整网络中的参数,使得网络最小化损失函数,从而实现对复杂数据的特征学习和表征学习。
以上是第一章的内容,接下来是第二章的内容。
# 2. 神经网络结构与训练
神经网络是深度学习的核心组成部分,通过不同层次的神经元构建复杂的模型以实现对数据的学习和预测。本章将介绍神经网络的基本结构和训练方法。
### 2.1 感知机模型
感知机是最简单的神经网络模型,由多个输入节点、权重和一个激活函数组成。其在输入数据上进行加权求和,经过激活函数后输出结果。以下是一个简单的Python实现:
```python
import numpy as np
class Perceptron:
def __init__(self, num_inputs, activation_fn):
self.weights = np.random.rand(num_inputs)
self.activation_fn = activation_fn
def predict(self, inputs):
weighted_sum = np.dot(inputs, self.weights)
return self.activation_fn(weighted_sum)
# 实例化感知机模型
perceptron = Perceptron(3, lambda x: 1 if x >= 0 else 0)
inputs = np.array([1, 0, 1]) # 输入数据
output = perceptron.predict(inputs)
print("Perceptron output:", output)
```
在上述代码中,我们定义了一个简单的感知机模型,使用随机权重和阶跃函数作为激活函数,对输入数据进行预测。
### 2.2 多层感知机与反向传播算法
多层感知机(MLP)是深度学习中常用的神经网络结构,由输入层、隐藏层和输出层组成。反向传播算法通过计算损失函数的梯度并反向传播更新网络参数,实现对模型的训练和优化。下面是一个简单的多层感知机的实现示例:
```python
from keras.models import Sequential
from keras.layers import Dense
# 构建多层感知机模型
model = Sequential()
model.add(Dense(units=64, activation='relu', input_dim=100))
model.add(Dense(units=10, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5, batch_size=32)
# 评估模型
loss, accuracy = model.evaluate(x_test, y_test)
print("Test accuracy:", accuracy)
```
### 2.3 卷积神经网络(CNN)与递归神经网络(RNN)
除了多层感知机外,卷积神经网络(CNN)和递归神经网络(RNN)是深度学习中常用的结构。CNN适用于图像数据的处理,而RNN适用于序列数据的学习,如自然语言处理。以下是一个简单的CNN和RNN实现示例:
```python
# 使用Keras构建CNN模型
from keras.models import Seque
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电力电子技术基础:7个核心概念与原理让你快速入门
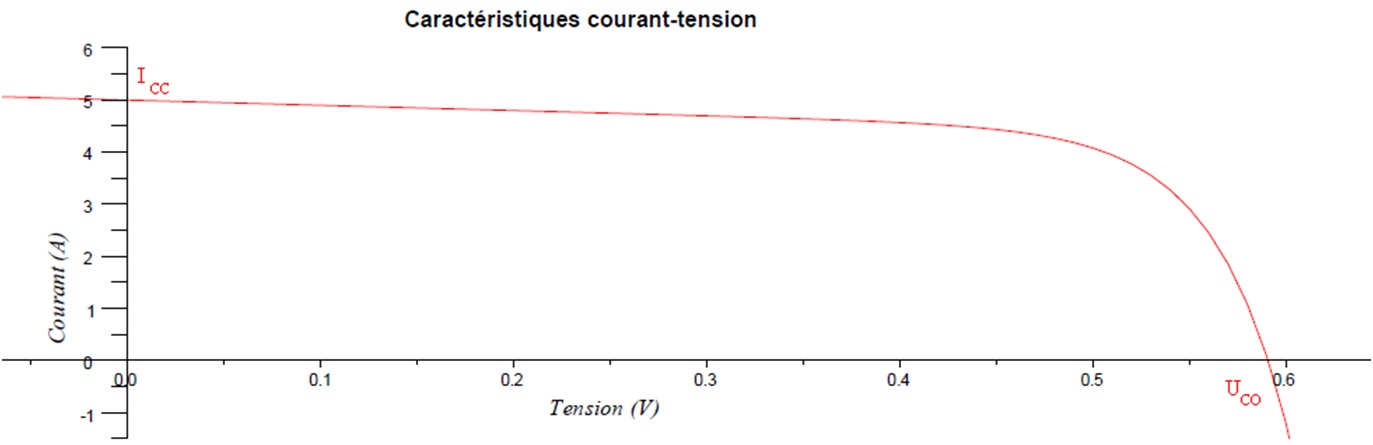
# 摘要
电力电子技术作为电力系统与电子技术相结合的交叉学科,对于现代电力系统的发展起着至关重要的作用。本文首先对电力电子技术进行概述,并深入解析其核心概念,包括电力电子变换器的分类、电力半导体器件的特点、控制策略及调制技术。进一步,本文探讨了电路理论基础、功率电子变换原理以及热管理与散热设计等基础理论与数学模型。文章接
PDF格式全面剖析:内部结构深度解读与高级操作技巧

# 摘要
PDF格式因其跨平台性和保持文档原貌的优势,在数字出版、办公自动化、法律和医疗等多个行业中得到广泛应用。本文首先概述了PDF格式的基本概念及其内部结构,包括文档组成元素、文件头、交叉引用表和PDF语法。随后,文章深入探讨了进行PDF文档高级操作的技巧,如编辑内容、处理表单、交互功能以及文档安全性的增强方法。接着,
【施乐打印机MIB效率提升秘籍】:优化技巧助你实现打印效能飞跃

# 摘要
施乐打印机中的管理信息库(MIB)是提升打印设备性能的关键技术,本文对MIB的基础知识进行了介绍,并理论分析了其效率。通过对MIB的工作原理和与打印机性能关系的探讨,以及效率提升的理论基础研究,如响应时间和吞吐量的计算模型,本文提供了优化打印机MIB的实用技巧,包括硬件升级、软件和固件调
FANUC机器人编程新手指南:掌握编程基础的7个技巧

# 摘要
本文提供了FANUC机器人编程的全面概览,涵盖从基础操作到高级编程技巧,以及工业自动化集成的综合应用。文章首先介绍了FANUC机器人的控制系统、用户界面和基本编程概念。随后,深入探讨了运动控制、I/O操作
【移远EC200D-CN固件升级速通】:按图索骥,轻松搞定固件更新

# 摘要
本文全面概述了移远EC200D-CN固件升级的过程,包括前期的准备工作、实际操作步骤、升级后的优化与维护以及案例研究和技巧分享。文章首先强调了进行硬件与系统兼容性检查、搭建正确的软件环境、备份现有固件与数据的重要性。其次,详细介绍了固件升级工具的使用、升级过程监控以及升级后的验证和测试流程。在固件升级后的章节中,本文探讨了系统性能优化和日常维护的策略,并分享了用户反馈和升级技巧。
【二次开发策略】:拉伸参数在tc itch中的应用,构建高效开发环境的秘诀

# 摘要
本文旨在详细阐述二次开发策略和拉伸参数理论,并探讨tc itch环境搭建和优化。首先,概述了二次开发的策略,强调拉伸参数在其中的重要作用。接着,详细分析了拉伸参数的定义、重要性以及在tc itch环境中的应用原理和设计原则。第三部分专注于tc itch环境搭建,从基本步骤到高效开发环境构建,再到性能调
CANopen同步模式实战:精确运动控制的秘籍
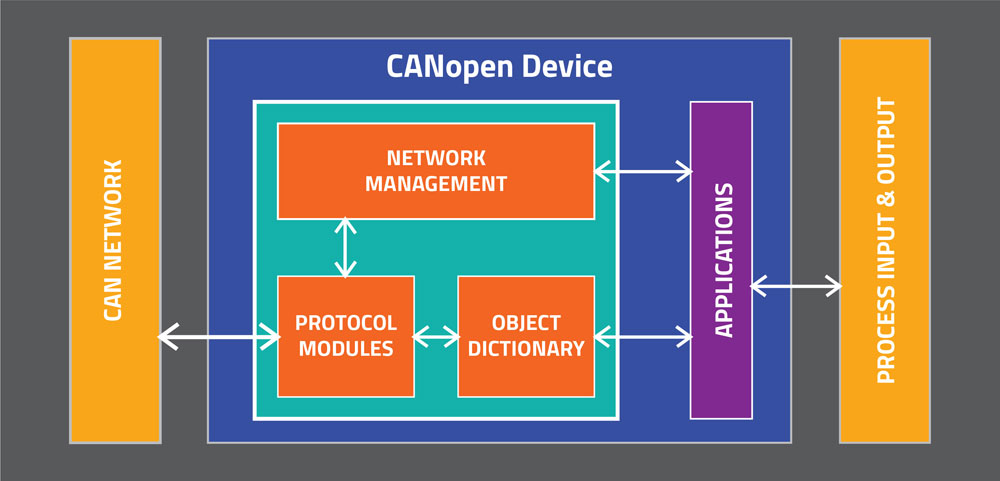
# 摘要
CANopen是一种广泛应用在自动化网络通信中的协议,其中同步模式作为其重要特性,尤其在对时间敏感的应用场景中扮演着关键角色。本文首先介绍了CANopen同步模式的基础知识,然后详细分析了同步机制的关键组成部分,包括同步消息(SYNC)的原理、同步窗口(SYNC Window)的配置以及同步计数器(SYNC Counter)的管理。文章接着
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )