【深入探索Genshi.Template】:揭秘模板语言与Python的绝妙融合
发布时间: 2024-10-14 06:11:13 阅读量: 19 订阅数: 25 

Origin教程009所需练习数据

# 1. Genshi.Template概述
## Genshi.Template是什么?
Genshi.Template是一个用于生成HTML、XML和其他文本格式的模板引擎,它结合了Python的强大功能和XML的灵活结构。它是基于流的模板引擎,意味着它在处理模板时不会生成中间的表示形式,而是直接输出最终的文本。
### 为什么选择Genshi.Template?
Genshi.Template提供了一种高效且灵活的方式来生成动态内容,它不仅支持多种模板语言(包括Genshi自己的XML-based语言和Markov模板语言),而且还与Python紧密集成,使得在模板中嵌入逻辑变得简单自然。
### Genshi.Template的应用场景
Genshi.Template广泛应用于Web开发中,尤其适合于需要高度定制化的动态网页和API响应的场景。它的性能和安全性都经过了优化,能够满足中到大型项目的需求。
```python
# 示例:简单Genshi.Template模板
from genshi.template import TemplateLoader
# 加载模板文件
loader = TemplateLoader('path/to/templates')
template = loader.load('my_template.genshi')
# 渲染模板
rendered = template.generate(name='World').render()
print(rendered)
```
在上述代码中,我们加载了一个名为`my_template.genshi`的模板文件,并使用`generate`方法传递了一个变量`name`,最后通过`render`方法输出渲染后的文本。这个例子展示了Genshi.Template的基本用法,也是了解其工作流程的良好起点。
# 2. Genshi.Template基础语法
## 2.1 模板的基本结构
### 2.1.1 模板声明和属性
Genshi.Template的模板文件通常以`.pt`为扩展名,其基本结构包括了模板声明和属性。模板声明定义了模板的语言和类型,而属性则用于配置模板的渲染行为。例如,一个基本的模板声明如下:
```xml
<?xml version="1.0"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"***">
<html xmlns="***" xml:lang="en" xmlns:py="***"
xmlns:xi="***"
py:strip="True" py:extend="master.pt">
```
在这个例子中,`xml version="1.0"`声明了模板使用的是XML格式。`DOCTYPE`定义了模板遵循的XHTML标准。`xmlns`属性定义了命名空间,例如`py`用于Genshi的功能,`xi`用于包含其他模板。
### 2.1.2 基本指令和表达式
在Genshi.Template中,基本指令和表达式用于控制模板的逻辑和输出。例如,`py:with`指令可以定义一个变量的作用域,而`py:text`用于输出表达式的结果:
```xml
<py:with vars="name='World'">
Hello, <b py:text="name" />!
</py:with>
```
在这个例子中,`py:with`指令创建了一个名为`name`的变量,其值为`'World'`。然后`py:text`指令用于输出`name`变量的值。
## 2.2 数据模型与模板渲染
### 2.2.1 数据模型的构建和传递
在Genshi.Template中,数据模型是模板渲染的核心。数据模型通常是一个Python对象,它包含了一系列的数据项,这些数据项在模板中被引用和显示。
数据模型可以通过多种方式构建,例如从数据库查询结果或业务逻辑层获取。在模板渲染过程中,数据模型需要被传递给模板引擎。这通常在控制器层完成,如下示例:
```python
from genshi.template import TemplateLoader
loader = TemplateLoader('templates')
template = loader.load('hello.pt')
data = {'name': 'World'}
stream = template.generate(**data)
```
在这个例子中,`data`字典包含了要传递给模板的数据模型。`**data`语法将字典解包为关键字参数。
### 2.2.2 模板渲染过程解析
模板渲染过程涉及到模板的解析、数据模型的绑定和输出的生成。首先,模板引擎解析模板文件,将模板指令和表达式转换为可执行的代码。然后,将数据模型绑定到模板,替换所有的变量和执行所有的表达式。最后,生成最终的输出流。
这个过程可以通过以下代码块进行演示:
```python
from genshi.template import MarkupTemplate
# 定义模板内容
template_content = """
<py:strip>
Hello, <b py:text="name" />!
</py:strip>
# 创建模板
template = MarkupTemplate(template_content)
# 创建数据模型
data = {'name': 'World'}
# 渲染模板
stream = template.generate(**data)
# 输出结果
output = ''.join(stream)
```
在这个例子中,`MarkupTemplate`用于创建一个模板,`generate`方法用于渲染模板并生成输出流。
## 2.3 控制结构与迭代
### 2.3.1 条件控制
Genshi.Template支持条件控制,例如`py:if`和`py:choose`指令,用于在模板中根据条件渲染不同的内容。例如:
```xml
<py:choose>
<py:when test="user.is_authenticated()">
Welcome, <b py:text="user.name" />!
</py:when>
<py:otherwise>
Please log in.
</py:otherwise>
</py:choose>
```
在这个例子中,`py:choose`和`py:when`用于根据`user.is_authenticated()`的结果决定是否显示欢迎信息。
### 2.3.2 迭代机制
迭代是模板中常用的功能,用于重复渲染模板片段。在Genshi.Template中,`py:for`指令用于迭代列表或其他可迭代对象。例如:
```xml
<ul>
<li py:for="item in items" py:text="item.name" />
</ul>
```
在这个例子中,`py:for`指令迭代了`items`列表,并为每个元素生成了一个`<li>`标签。
以上是Genshi.Template基础语法的介绍,包括模板的基本结构、数据模型与模板渲染以及控制结构与迭代。在本章节中,我们通过具体的代码示例和解析,逐步介绍了Genshi.Template的核心概念和使用方法。通过本章节的介绍,读者应能够理解和运用Genshi.Template的基础语法,为进一步深入学习和实践打下坚实的基础。
# 3. Genshi.Template高级特性
## 3.1 高级模板指令
### 3.1.1 自定义指令
在本章节中,我们将深入探讨Genshi.Template的高级特性之一:自定义指令。自定义指令是Genshi中一个强大的功能,允许开发者扩展模板语言的功能,以满足特定需求。这些指令可以被定义为可重用的代码片段,使得模板编写更加模块化和高效。
自定义指令通常通过Python代码实现,并且可以访问模板的上下文,这意味着它们可以访问传递给模板的数据,并且可以根据这些数据执行逻辑操作。下面是一个简单的自定义指令的例子:
```python
from genshi.template import Directive
from genshi.filters import Transformer
class MyDirective(Directive):
def __init__(self, name, *args, **kwargs):
super(MyDirective, self).__init__('my-directive', *args, **kwargs)
def render(self, renderrable, context, *args, **kwargs):
# 在这里实现自定义逻辑
# renderable 是传入的可渲染对象
return renderrable
```
在模板中使用自定义指令,首先需要将其注册到模板引擎中:
```python
from genshi.template import TemplateLoader
loader = TemplateLoader('path/to/templates')
# 注册自定义指令
loader.directives['my-directive'] = MyDirective
```
然后在模板中就可以使用它了:
```xml
<my:directive name="value">
<!-- 这里可以写模板代码,将会被自定义指令处理 -->
</my:directive>
```
### 3.1.2 模板继承与包含
模板继承和包含是提高代码复用性的关键技术。在Genshi中,可以通过继承机制来创建一个基础模板,然后在子模板中定义特定区域的内容。这种技术不仅减少了重复代码,也使得网站的整体风格和布局更加一致。
模板继承的基本语法如下:
```xml
<!-- base_template.xml -->
<html>
<head>
<title>${title}</title>
</head>
<body
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Genshi.Template,一个用于构建动态 Web 内容的 Python 库文件。专栏从入门指南开始,逐步介绍了库文件的核心概念和基本用法。随着深入,读者将掌握必备技巧、基础教程和高级优化技巧。专栏还提供了实战案例分析、与 Mako 模板的比较、调试技巧和安全性分析。此外,还介绍了扩展应用和性能测试,帮助读者构建高效、安全的 Web 模板系统。通过本专栏,读者将全面了解 Genshi.Template,并掌握优化模板渲染性能、解决问题和增强模板功能的最佳实践。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
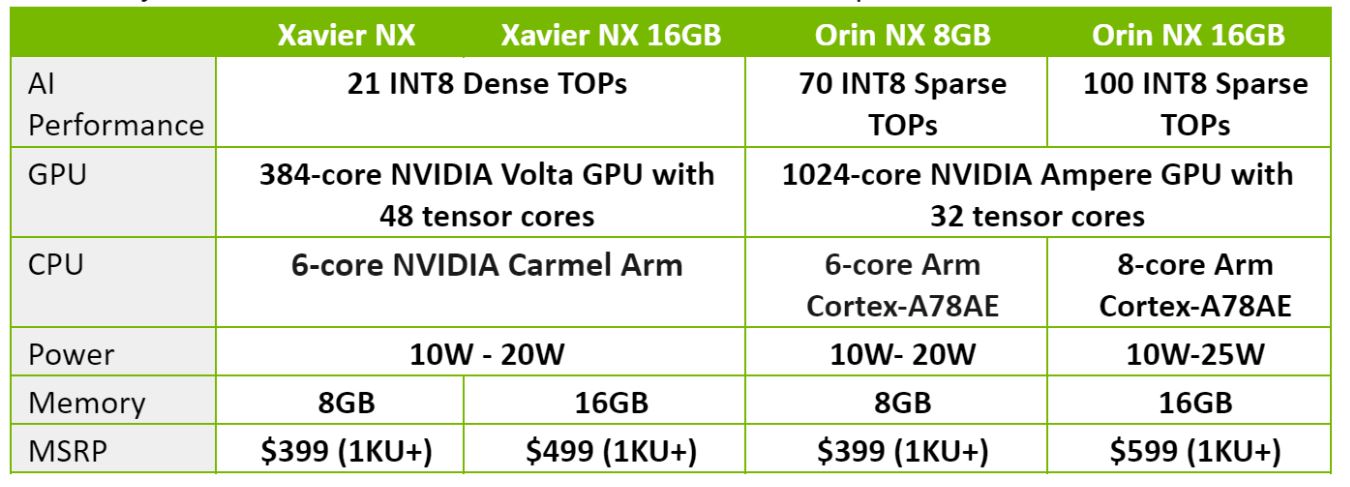
NVIDIA ORIN NX性能基准测试:超越前代的关键技术突破
# 摘要
本文全面介绍了NVIDIA ORIN NX处理器的性能基准测试理论基础,包括性能测试的重要性、测试类型与指标,并对其硬件架构进行了深入分析,探讨了处理器核心、计算单元、内存及存储的性能特点。此外,文章还对深度学习加速器及软件栈优化如何影响AI计算性能进行了重点阐述。在实践方面,本文设计了多个实验,测试了NVI
图论期末考试必备:掌握核心概念与问题解答的6个步骤

# 摘要
图论作为数学的一个分支,广泛应用于计算机科学、网络分析、电路设计等领域。本文系统地介绍图论的基础概念、图的表示方法以及基本算法,为图论的进一步学习与研究打下坚实基础。在图论的定理与证明部分,重点阐述了最短路径、树与森林、网络流问题的经典定理和算法原理,包括Dijkstra和Floyd-Warshall算法的详细证明过程。通过分析图论在社交网络、电路网络和交通网络中的实际应用,本文探讨了图论问题解决策略和技巧,包括策略规划、数学建模与软件
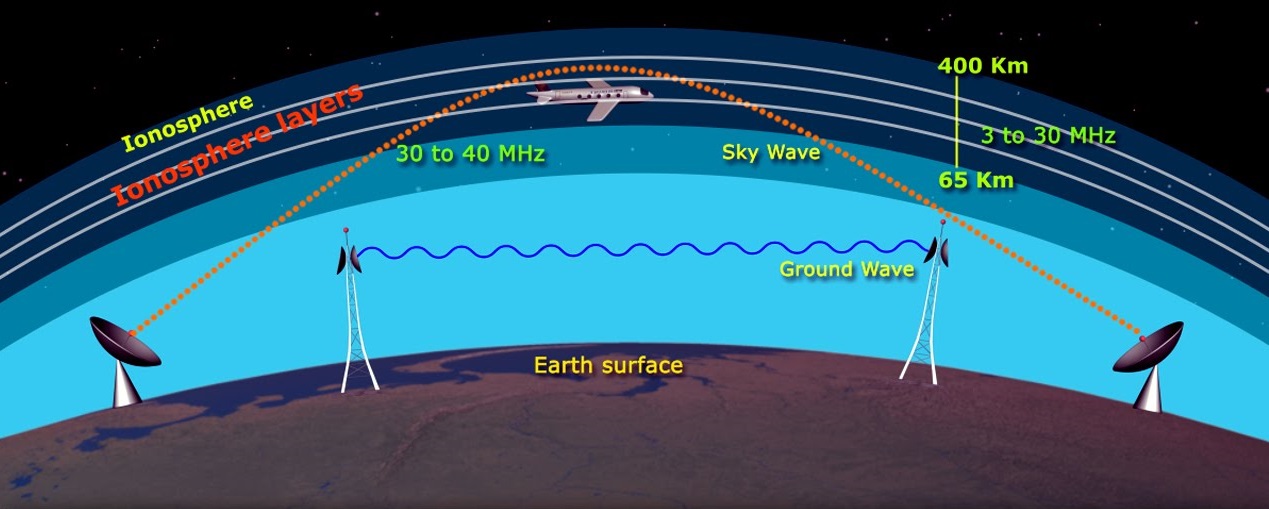
【无线电波传播影响因素详解】:信号质量分析与优化指南
# 摘要
本文综合探讨了无线电波传播的基础理论、环境影响因素以及信号质量的评估和优化策略。首先,阐述了大气层、地形、建筑物、植被和天气条件对无线电波传播的影响。随后,分析了信号衰减、干扰识别和信号质量测量技术。进一步,提出了包括天线技术选择、传输系统调整和网络规划在内的优化策略。最后,通过城市、农村与偏远地区以及特殊环境下无线电波传播的实践案例分析,为实际应用提供了理论指导和解决方案。
# 关键字
无线电波传播;信号衰减;信号干扰;信号
FANUC SRVO-062报警:揭秘故障诊断的5大实战技巧

# 摘要
FANUC SRVO-062报警是工业自动化领域中伺服系统故障的常见表现,本文对该报警进行了全面的综述,分析了其成因和故障排除技巧。通过深入了解FANUC伺服系统架构和SRVO-062报警的理论基础,本文提供了详细的故障诊断流程,并通过伺服驱动器和电机的检测方法,以及参数设定和调整的具体操作
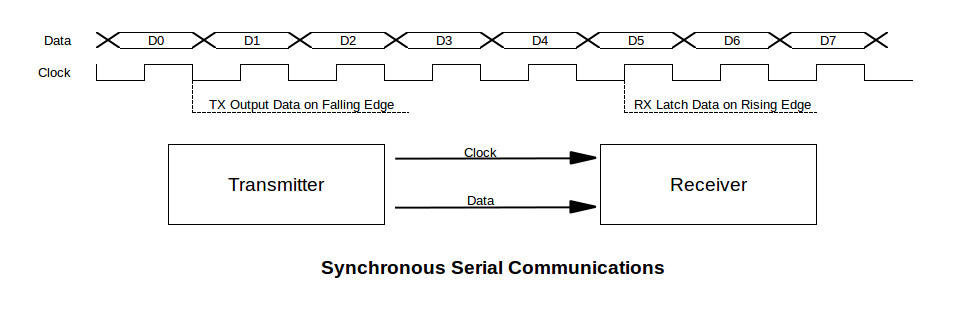
【单片微机接口技术速成】:快速掌握数据总线、地址总线与控制总线
# 摘要
本文深入探讨了单片微机接口技术,重点分析了数据总线、地址总线和控制总线的基本概念、工作原理及其在单片机系统中的应用和优化策略。数据总线的同步与异步机制,以及其宽度对传输效率和系统性能的影响是本文研究的核心之一。地址总线的作用、原理及其高级应用,如地址映射和总线扩展,对提升寻址能力和系统扩展性具有重要意义。同时,控制总线的时序控制和故障处理也是确保系统稳定运行的关键技术。最后
【Java基础精进指南】:掌握这7个核心概念,让你成为Java开发高手

# 摘要
本文全面介绍了Java语言的开发环境搭建、核心概念、高级特性、并发编程、网络编程及数据库交互以及企业级应用框架。从基础的数据类型和面向对象编程,到集合框架和异常处理,再到并发编程和内存管理,本文详细阐述了Java语言的多方面知识。特别地,对于Java的高级特性如泛型和I/O流的使用,以及网络编程和数据库连接技
电能表ESAM芯片安全升级:掌握最新安全标准的必读指南
# 摘要
ESAM芯片作为电能表中重要的安全组件,对于确保电能计量的准确性和数据的安全性发挥着关键作用。本文首先概述了ESAM芯片及其在电能表中的应用,随后探讨了电能表安全标准的演变历史及其对ESAM芯片的影响。在此基础上,深入分析了ESAM芯片的工作原理和安全功能,包括硬件架构、软件特性以及加密技术的应用。接着,本文提供了一份关于ESAM芯片安全升级的实践指南,涵盖了从前期准备到升级实施以及后
快速傅里叶变换(FFT)实用指南:精通理论与MATLAB实现的10大技巧
# 摘要
快速傅里叶变换(FFT)是信号处理和数据分析的核心技术,它能够将时域信号高效地转换为频域信号,以进行频谱分析和滤波器设计等。本文首先回顾FFT的基础理论,并详细介绍了MATLAB环境下FFT的使用,包括参数解析及IFFT的应用。其次,深入探讨了多维FFT、离散余弦变换(DCT)以及窗函数在FFT中的高级应用和优化技巧。此外,本文通过不同领域的应用案例
【高速ADC设计必知】:噪声分析与解决方案的全面解读

# 摘要
高速模拟-数字转换器(ADC)是现代电子系统中的关键组件,其性能受到噪声的显著影响。本文系统地探讨了高速ADC中的噪声基础、噪声对性能的影响、噪声评估与测量技术以及降低噪声的实际解决方案。通过对噪声的分类、特性、传播机制以及噪声分析方法的研究,我们能
【Python3 Serial数据完整性保障】:实施高效校验和验证机制
# 摘要
本论文首先介绍了Serial数据通信的基础知识,随后详细探讨了Python3在Serial通信中的应用,包括Serial库的安装、配置和数据流的处理。本文进一步深入分析了数据完整性的理论基础、校验和验证机制以及常见问题。第四章重点介绍了使用Python3实现Serial数据校验的方法,涵盖了基本的校验和算法和高级校验技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )