使用web3.py与以太坊进行简单交易
发布时间: 2023-12-29 17:54:56 阅读量: 76 订阅数: 33 

web3.py:用于与以太坊区块链和生态系统进行交互的python接口
1. 简介
## 1.1 什么是web3.py
Web3.py是一个用于与以太坊区块链进行交互的Python库。它提供了一个用户友好的方式来创建和管理以太坊账户、构建交易、与智能合约进行交互等功能。通过使用web3.py,我们可以快速、方便地开发基于以太坊的应用程序。
## 1.2 以太坊简介
以太坊是一个开源的区块链平台,它允许开发者构建和部署智能合约。与比特币区块链不同,以太坊区块链的主要目的是为了支持更复杂的去中心化应用程序。以太坊的代币称为以太币(Ether),它是加密货币市场中排名第二的数字货币(仅次于比特币)。
## 1.3 目标: 使用web3.py与以太坊进行简单交易
本文的目标是介绍如何使用web3.py库与以太坊进行简单的交易操作。我们将会介绍如何连接以太坊网络,创建以太坊账户,构建交易,签名交易并发送至以太坊网络。通过学习本文内容,读者将能够了解web3.py的基本用法,并能够进行基本的以太坊交易操作。接下来,我们将详细介绍环境设置和连接以太坊网络的步骤。
### 2. 环境设置
在开始使用web3.py与以太坊进行简单交易之前,我们需要先进行环境设置。这包括安装和配置Python、安装web3.py库,以及配置以太坊节点。
#### 2.1 安装和配置Python
首先,确保你已经安装了Python。你可以从 [Python官方网站](https://www.python.org) 下载最新的Python版本,并按照官方指南进行安装。
安装完成后,你可以在命令行中输入以下命令来检查Python是否成功安装:
```bash
python --version
```
#### 2.2 安装web3.py库
安装web3.py库是使用web3.py的第一步。你可以使用pip来安装web3.py:
```bash
pip install web3
```
#### 2.3 配置以太坊节点
在本地进行开发时,你可以使用Ganache来模拟一个以太坊网络。Ganache是一个用于本地以太坊开发和调试的工具,可以快速启动一个私有以太坊区块链。
如果你希望连接到真实的以太坊网络,你需要获取远程以太坊节点的连接信息,并确保网络和账户的安全性。
完成以上步骤后,我们就可以进入下一步,连接以太坊网络。
### 3. 连接以太坊网络
以太坊是一个开放的区块链平台,通过连接以太坊网络,我们可以进行各种交易和智能合约的操作。本章将介绍如何使用web3.py库连接以太坊网络。
#### 3.1 创建web3实例
在使用web3.py之前,首先需要创建web3实例,Web3是一个用Python编写的以太坊客户端。通过Web3,我们可以与以太坊网络进行交互,包括发送交易、调用智能合约等操作。
```python
from web3 import Web3
# 创建web3实例
web3 = Web3(Web3.HTTPProvider('http://127.0.0.1:8545'))
```
在上面的代码中,我们通过HTTPProvider指定了连接的以太坊节点的地址和端口号。这里使用的是本地节点,也可以连接远程节点。
#### 3.2 连接本地以太坊节点
要连接本地的以太坊节点,可以使用以下代码:
```python
web3 = Web3(Web3.IPCProvider('/path/to/geth.ipc'))
```
通过IPCProvider可以连接本地的以太坊客户端(如Geth或Parity),需要指定geth.ipc文件的路径。
#### 3.3 连接远程以太坊节点
要连接远程的以太坊节点,可以使用以下代码:
```python
web3 = Web3(Web3.HTTPProvider('http://remote-node-ip:8545'))
```
通过HTTPProvider可以连接到远程的以太坊节点,需要指定节点的IP地址和端口号。
#### 3.4 测试网络连接
连接以太坊网络后,我们可以进行一些简单的测试,例如获取当前的区块高度:
```python
block_height = web3.eth.blockNumber
print("Current block height:", block_height)
```
以上代码中,我们使用`web3.eth.blockNumber`获取当前区块高度,并打印输出。
通过以上步骤,我们成功连接到了以太坊网络,并可以进行后续的交易和操作。
在本章节中,我们介绍了如何通过web3.py连接以太坊网络,包括连接本地节点、远程节点以及测试网络连接。在接下来的章节中,我们将继续学习以太坊账户的创建和简单交易的发起。
4. 创建以太坊账户
==================
在使用以太坊网络进行交易之前,我们需要创建一个以太坊账户来存储我们的加密货币。创建以太坊账户的过程涉及生成私钥和公钥,以及在链上注册账户。
4.1 生成私钥和公钥
------------------
私钥是一个256位的随机数,可以用于生成加密签名。公钥是由私钥通过椭圆曲线加密生成的一对坐标,在以太坊中用于验证交易签名。
以下是使用web3.py生成私钥和公钥的示例代码:
```python
from eth_account import Account
private_key = Account.create().privateKey.hex()
public_key = Account.from_key(private_key).address
```
在上述代码中,我们使用`eth_account`库中的`Account`类来生成私钥和公钥。首先,我们用`Account.create()`方法生成一个账户对象,并通过`.privateKey.hex()`方法获取私钥的十六进制表示。然后,我们使用`Account.from_key()`方法将私钥转换为公钥,再通过`.address`属性获取公钥的地址。
4.2 创建以太坊账户
------------------
在以太坊中,创建账户实际上是将公钥注册到链上,并为其分配一个唯一的地址。我们可以使用web3.py库提供的功能来创建以太坊账户。
以下是使用web3.py创建以太坊账户的示例代码:
```python
from web3 import Web3
web3 = Web3(Web3.HTTPProvider('https://mainnet.infura.io/v3/your-infura-project-id'))
def create_eth_account():
account = web3.eth.account.create()
return account.address
eth_address = create_eth_account()
```
在上述代码中,我们首先通过`Web3`类创建web3实例,并指定连接的以太坊节点(此处使用Infura提供的主网节点)。然后,我们定义一个`create_eth_account()`函数,该函数使用`web3.eth.account.create()`方法创建一个以太坊账户,并通过`.address`属性获取账户的地址。最后,我们调用`create_eth_account()`函数,并将结果保存在`eth_address`变量中。
4.3 导出和导入账户
------------------
通过web3.py,我们还可以将生成的以太坊账户导出到外部文件,并从文件中导入账户。
以下是将账户导出到文件和从文件中导入账户的示例代码:
```python
from web3 import Account
account = web3.eth.account.create()
private_key = account.privateKey
# 导出私钥到文件
Account.encrypt(private_key, 'your-encryption-password', 'path/to/keystore-file')
# 从文件中导入账户
decoded_account = Account.decrypt('path/to/keystore-file', 'your-encryption-password')
```
在上述代码中,我们首先使用`web3.eth.account.create()`方法创建一个以太坊账户,并通过`.privateKey`属性获取私钥。然后,我们使用`Account.encrypt()`方法将私钥加密并保存到指定的keystore文件中。最后,我们可以使用`Account.decrypt()`方法从keystore文件中解密私钥,返回一个包含账户信息的字典。
通过将账户导出到文件,我们可以方便地将账户用于不同的应用程序和环境中,同时保证账户的私钥安全。
在本章中,我们学习了如何使用web3.py创建以太坊账户,生成私钥和公钥,并将账户导出和导入到文件中。在下一章节中,我们将介绍如何使用web3.py发起简单的以太坊交易。
### 5. 发起简单交易
在这一章节中,我们将使用web3.py与以太坊进行简单的交易操作。我们将演示如何构建交易对象、使用私钥签名交易、发送交易至以太坊网络以及验证交易结果。
#### 5.1 构建交易对象
首先,我们需要构建一个交易对象,该对象包括了交易的发送者地址、接收者地址、转账金额等信息。以下是一个简单的示例代码:
```python
from web3 import Web3, HTTPProvider
from eth_account import Account
# 连接到以太坊节点
w3 = Web3(HTTPProvider('http://localhost:8545'))
# 发送者账户地址
sender_address = "0x1234567890123456789012345678901234567890"
# 接收者账户地址
receiver_address = "0xabcdefABCDEFabcdefABCDEFabcdefabcdefABCD"
# 转账金额
amount = Web3.toWei(1, 'ether')
# 构建交易对象
transaction = {
'to': receiver_address,
'value': amount,
'gas': 2000000,
'gasPrice': w3.toWei('50', 'gwei'),
'nonce': w3.eth.getTransactionCount(sender_address),
}
```
在上面的代码中,我们使用了web3.py库的`Web3`和`HTTPProvider`模块来连接到本地以太坊节点,并使用了`eth_account`模块中的`Account`来处理账户相关操作。然后,我们指定了发送者地址、接收者地址以及转账金额,构建了交易对象`transaction`。
#### 5.2 使用私钥签名交易
接下来,我们将使用发送者的私钥对交易进行签名。下面是一个示例代码:
```python
# 发送者私钥
sender_private_key = "0x1234567890123456789012345678901234567890123456789012345678901234"
# 使用私钥签名交易
signed_transaction = w3.eth.account.signTransaction(transaction, sender_private_key)
```
在上面的代码中,我们将发送者的私钥`sender_private_key`用于对交易对象`transaction`进行签名,得到了`signed_transaction`。
#### 5.3 发送交易至以太坊网络
现在,我们将签名后的交易发送至以太坊网络。以下是示例代码:
```python
# 发送交易
transaction_hash = w3.eth.sendRawTransaction(signed_transaction.rawTransaction)
```
在上面的代码中,我们使用web3.py的`sendRawTransaction`方法发送了已签名的交易,并获得了交易的哈希值`transaction_hash`。
#### 5.4 验证交易结果
最后,我们可以验证交易的结果,判断交易是否成功执行。以下是一个简单的示例代码:
```python
# 等待交易被打包并获取交易收据
transaction_receipt = w3.eth.waitForTransactionReceipt(transaction_hash)
# 打印交易收据
print(transaction_receipt)
```
在上面的代码中,我们使用`waitForTransactionReceipt`方法等待交易被打包,并获取了交易的收据`transaction_receipt`,然后打印出了交易的结果信息。
通过以上操作,我们成功地使用web3.py与以太坊进行了简单的交易操作。
## 6. 总结与拓展
本文详细介绍了使用web3.py与以太坊进行简单交易的过程。首先,我们了解了web3.py库的基本概念和以太坊的简介。然后,通过设置环境,包括安装Python、web3.py库以及配置以太坊节点,完成了与以太坊网络的连接。
接着,我们学习了如何创建以太坊账户,包括生成私钥和公钥,创建账户以及导入和导出账户的操作。在此基础上,我们展示了如何发起简单交易,包括构建交易对象,使用私钥签名交易,发送交易至以太坊网络以及验证交易结果。
在编写本文时,我们使用了Python作为示例语言,展示了使用web3.py库进行以太坊交易的过程。同时,我们还提供了一些拓展话题,让读者深入了解更复杂的以太坊交易操作、区块链中的智能合约以及未来发展前景。
总结起来,通过学习本文,读者可以掌握使用web3.py与以太坊进行简单交易的基本流程和操作。同时,也可以进一步了解和探索更深入的区块链技术和应用领域。
### 6.1 总结与回顾
在本文中,我们首先介绍了web3.py库和以太坊的基本概念,然后通过设置环境建立与以太坊网络的连接。接着,我们学习了如何创建以太坊账户,并展示了发起简单交易的完整流程。
通过本文的学习,我们可以总结以下几点:
- 使用web3.py库可以方便地与以太坊进行交互,进行账户创建、交易签名、交易发送等操作。
- 设置环境是使用web3.py库的前提,需要安装Python、web3.py库以及配置与以太坊网络的连接。
- 创建以太坊账户需要生成私钥和公钥,并通过私钥导入账户或导出账户。
- 发起简单交易需要构建交易对象,并使用私钥对交易进行签名,然后发送到以太坊网络进行验证和执行。
### 6.2 更复杂的以太坊交易操作
本文只介绍了基本的以太坊交易操作,实际应用中可能会涉及更复杂的操作,比如使用智能合约进行交易、查询区块链状态、监听事件等。
web3.py库提供了丰富的功能和API,可以进行更多高级的以太坊交易操作。读者可以继续深入学习web3.py库的文档和示例代码,以掌握更多高级用法和技巧。
### 6.3 区块链中的智能合约
智能合约是区块链上的可编程代码,可以实现自动执行和去中心化的交互。通过智能合约,可以在区块链上创建功能强大的去中心化应用(DApp)。
web3.py库提供了与智能合约进行交互的API,可以方便地调用合约方法、发送交易、查询数据等操作。读者可以深入学习智能合约的开发和部署,以及使用web3.py库与智能合约进行交互的方法。
### 6.4 未来发展前景
区块链技术作为一种分布式账本和去中心化机制的创新,正在逐步应用于金融、供应链、物联网等众多领域。以太坊作为最具代表性的智能合约平台,也在不断发展和演进。
随着区块链技术的成熟和应用场景的不断拓展,使用web3.py库与以太坊进行交互的需求也会增加。同时,web3.py库自身也在不断更新和改进,提供更多功能和更好的性能。
未来,我们可以期待以太坊和web3.py库在区块链领域的广泛应用和发展,以及更多相关技术和工具的涌现,为开发者提供更多便利和创新的机会。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
"web3.py"专栏全面介绍了Python语言实现的Web3接口库在以太坊和区块链领域的应用。从初识web3.py的基本概念开始,逐步深入探讨了与以太坊进行简单交易、智能合约交互、区块链数据分析、DApp开发、合约编译、交易签名等诸多方面。此外,专栏中还涵盖了以太坊代币交易、Gas费用优化、多重签名交易、链上存储交互、ERC-20代币开发、链上证明、去中心化交易所开发等内容。同时,还深入探讨了DApp集成与部署、以太坊治理投票、身份验证与凭证管理等实用技术。通过本专栏,读者可以全面了解web3.py在以太坊和区块链开发中的应用,为区块链开发者提供了丰富的学习和实践指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Origin自动化操作】:一键批量导入ASCII文件数据,提高工作效率
# 摘要
本文旨在介绍Origin软件在自动化数据处理方面的应用,通过详细解析ASCII文件格式以及Origin软件的功能,阐述了自动化操作的实现步骤和高级技巧。文中首先概述了Origin的自动化操作,紧接着探讨了自动化实现的理论基础和准备工作,包括环境配置和数据集准备。第三章详细介绍了Origin的基本操作流程、脚本编写、调试和测试方法
【揭秘CPU架构】:5大因素决定性能,你不可不知的优化技巧
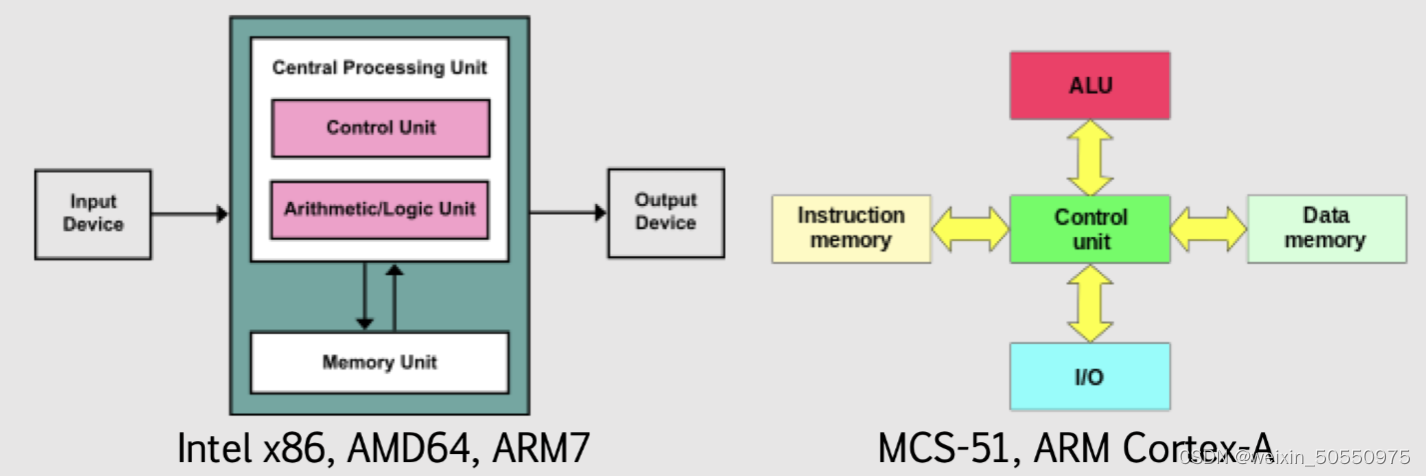
# 摘要
CPU作为计算机系统的核心部件,其架构的设计和性能优化一直是技术研究的重点。本文首先介绍了CPU架构的基本组成,然后深入探讨了影响CPU性能的关键因素,包括核心数量与线程、缓存结构以及前端总线与内存带宽等。接着,文章通过性能测试与评估的方法,提供了对CPU性能的量化分析,同时涉及了热设计功耗与能耗效率的考量。进一步,本文探讨了CPU优化的实践,包括超频技术及其风险预防,以及操作系统与硬件
AP6521固件升级后系统校验:确保一切正常运行的5大检查点

# 摘要
本文全面探讨了AP6521固件升级的全过程,从准备工作、关键步骤到升级后的系统校验以及问题诊断与解决。首先,分析了固件升级的意义和必要性,提出了系统兼容性和风险评估的策略,并详细说明了数据备份与恢复计划。随后,重点阐述了升级过程中的关键操作、监控与日志记录,确保升级顺利进行。升级完成后,介绍了系统的功能性检查、稳定性和兼容性测试以及安全漏洞扫描的重要性。最后,本研究总结
【金融时间序列分析】:揭秘同花顺公式中的数学奥秘

# 摘要
本文全面介绍时间序列分析在金融领域中的应用,从基础概念和数据处理到核心数学模型的应用,以及实际案例的深入剖析。首先概述时间序列分析的重要性,并探讨金融时间序列数据获取与预处理的方法。接着,深入解析移动平均模型、自回归模型(AR)及ARIMA模型及其扩展,及其在金融市场预测中的应用。文章进一步阐述同花顺公式中数学模型的应用实践,以及预测、交易策略开发和风险管理的优化。最后,通过案例研究,展现时间序列分析在个股和市场指数分析中
Muma包高级技巧揭秘:如何高效处理复杂数据集?

# 摘要
本文全面介绍Muma包在数据处理中的应用与实践,重点阐述了数据预处理、清洗、探索分析以及复杂数据集的高效处理方法。内容覆盖了数据类型
IT薪酬策略灵活性与标准化:要素等级点数公式的选择与应用

# 摘要
本文系统地探讨了IT行业的薪酬策略,从薪酬灵活性的理论基础和实践应用到标准化的理论框架与方法论,再到等级点数公式的应用与优化。文章不仅分析了薪酬结构类型和动态薪酬与员工激励的关联,还讨论了不同职级的薪酬设计要点和灵活福利计划的构建。同时,本文对薪酬标准化的目的、意义、设计原则以及实施步骤进行了详细阐述,并进一步探讨了等级点数公式的选取、计算及应用,以及优
社区与互动:快看漫画、腾讯动漫与哔哩哔哩漫画的社区建设与用户参与度深度对比
# 摘要
本文围绕现代漫画平台社区建设及其对用户参与度影响展开研究,分别对快看漫画、腾讯动漫和哔哩哔哩漫画三个平台的社区构建策略、用户互动机制以及社区文化进行了深入分析。通过评估各自社区功能设计理念、用户活跃度、社区运营实践、社区特点和社区互动文化等因素,揭示了不同平台在促进用户参与度和社区互动方面的策略与成效。此外,综合对比三平台的社区建设模式和用户参与度影响因素,本文提出了关于漫画平
【算法复杂度分析】:SVM算法性能剖析:时间与空间的平衡艺术

# 摘要
支持向量机(SVM)是一种广泛使用的机器学习算法,尤其在分类和回归任务中表现突出。本文首先概述了SVM的核心原理,并基于算法复杂度理论详细分析了SVM的时间和空间复杂度,包括核函数的作用、对偶问题的求解、SMO算法的复杂度以及线性核与非线性核的时间对比。接下来,本文探讨了SVM性能优化策略,涵盖算法和系统层面的改进,如内存管理和并行计算的应用。最后,本文展望了SV
【广和通4G模块硬件接口】:掌握AT指令与硬件通信的细节
# 摘要
本文全面介绍了广和通4G模块的硬件接口,包括各类接口的类型、特性、配置与调试以及多模块之间的协作。首先概述了4G模块硬件接口的基本概念,接着深入探讨了AT指令的基础知识及其在通信原理中的作用。通过详细介绍AT指令的高级特性,文章展示了其在不同通信环境下的应用实例。文章还详细阐述了硬件接口的故障诊断与维护策略,并对4G模块硬件接口的未来技术发展趋势和挑战进行了展望,特别是在可穿戴设备、微型化接口设计以及云计算和大数据需求的背景下。
#
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )