继承关系的适用场景与注意事项
发布时间: 2024-01-14 05:23:46 阅读量: 45 订阅数: 45 
# 1. 介绍
### 1.1 什么是继承关系
继承关系是面向对象编程中的一个重要概念,它描述了一个类(子类)可以基于另一个类(父类)来定义,并且可以继承父类的属性和方法。在继承关系中,子类可以继承父类的特征和行为,并且可以通过添加新的特征和行为来扩展或修改父类的功能。
继承关系的核心思想是通过类的层级结构来组织代码,实现代码的复用和模块化。通过定义共性的父类,可以将公共的属性和方法提取出来,在子类中直接使用,从而避免代码的重复编写。
### 1.2 继承关系在IT中的应用
继承关系在IT领域中被广泛应用于软件开发和系统设计中。这种关系可以帮助开发者构建清晰、可维护和可扩展的代码结构,提高代码的复用性和可读性。
在软件开发中,继承关系可以用于设计和实现基础框架、抽象类和接口等。通过定义一个通用的父类,可以使子类共享父类的属性和方法,并且可以通过重写父类的方法来实现特定的业务逻辑。此外,通过多态的特性,可以实现对同一类型的不同子类对象的统一操作。
在系统设计中,继承关系可以用于构建层次化的权限管理、用户角色和权限模块。通过继承关系,可以定义通用的用户角色和权限类,并通过继承实现特定的角色和权限。这样可以轻松地扩展和维护用户角色和权限系统。
# 2. 继承关系的基本概念和原理
在面向对象编程中,继承是一个重要的概念。通过继承,子类可以继承父类的属性和方法,从而实现代码的重用和扩展。接下来我们将介绍继承关系的基本概念和原理。
#### 2.1 子类和父类的定义
在继承关系中,我们通常将原有的类称为父类或基类,新建的类称为子类或派生类。父类中定义的属性和方法可以被子类继承和使用,从而减少重复代码的编写。下面是一个简单的父类和子类的定义示例:
```python
# Python示例
# 父类
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
pass
# 子类
class Dog(Animal):
def speak(self):
return "Woof!"
# 创建实例并调用方法
my_dog = Dog("Buddy")
print(my_dog.speak()) # 输出: "Woof!"
```
在上面的示例中,`Animal`类是父类,`Dog`类是子类。`Dog`类继承了`Animal`类中的`__init__`方法和`speak`方法,同时可以定义自己的属性和方法。
#### 2.2 继承的基本语法
在大多数面向对象的编程语言中,继承可以通过关键字(如`extends`、`:`)来实现。以Python为例,继承的基本语法如下:
```python
class ChildClassName(ParentClassName):
# 子类的定义
# ...
```
#### 2.3 继承关系的实现方式:单继承和多继承
继承关系可以分为单继承和多继承两种方式。单继承指一个子类只继承一个父类,而多继承指一个子类可以同时继承多个父类。在实际应用中,需要根据具体的场景来选择合适的继承方式。
以上是继承关系的基本概念和原理,接下来我们将介绍继承关系在实际开发中的应用场景。
# 3. 继承关系的适用场景
在软件开发中,继承关系是一种重要的设计模式,在以下场景中特别适用:
#### 3.1 代码复用和模块化
继承允许子类继承父类的属性和方法,通过继承可以实现代码的复用和模块化。父类的公共属性和方法可以被多个子类共享,减少了重复编写代码的工作量,提高了代码的可维护性和开发效率。
例如,在一个电商平台的系统中,有多种类型的商品,如电子产品、家具、服装等。这些商品都有一些共同的属性和方法,比如名称、价格、描述、展示图片等。可以定义一个父类`Product`,包含这些共同的属性和方法,然后每个具体的商品类型可以作为父类的子类,并继承父类的属性和方法。这样可以节省编写重复代码的时间和精力。
```python
class Product:
def __init__(self, name, price, description):
self.name = name
self.price = price
self.description = description
def display_info(self):
print(f"Name: {self.name}")
print(f"Price: {self.price}")
print(f"Description: {self.description}")
class ElectronicProduct(Product):
def __init__(self, name, price, description, brand):
super().__init__(name, price, description)
self.brand = brand
def display_info(self):
super().display_info()
print(f"Brand: {self.brand}")
class Furniture(Product):
def __init__(self, name, price, description, material):
super().__init__(name, price, description)
self.material = material
def display_info(self):
super().display_info()
print(f"Material: {self.material}")
# 创建商品对象并展示信息
iphone = ElectronicProduct("iPhone 12", 6999, "A powerful smartphone", "Apple")
iphone.display_info()
chair = Furniture("Wooden Chair", 199, "A comfortable chair", "Wood")
chair.display_info()
```
代码说明:在上述代码中,定义了一个父类`Product`,包含商品的共同属性和方法。然后,通过定义子类`ElectronicProduct`和`Furniture`分别继承父类,子类可以继承父类的属性和方法,并可以根据自身特点进行扩展,如`ElectronicProduct`新增了品牌属性,`Furniture`新增了材质属性。最后,创建子类的对象并调用`display_info`方法展示商品的详细信息。
#### 3.2 特定业务需求的实现
继承关系可以根据特定的业务需求进行定制化的实现。子类可以在继承父类的基础上进行扩展和重写,以满足特定的业务需求。
例如,在一个银行系统中,有多种类型的账户,如储蓄账户、信用卡账户、基金账户等。每种账户有不同的操作和规则,但也有一些共同的属性和方法,如账户号、账户余额、账户类型等。可以定义一个父类`Account`,包含共同的属性和方法,然后每种账户类型可以作为父类的子类,并根据自身特点进行扩展和重写。
```java
public class Account {
private String accountNumber;
private double balance;
private String accountType;
public Account(String accountNumber, double balance, String accountType) {
this.accountNumber = accountNumber;
this.balance = balance;
this.accountType = accountType;
}
public void deposit(double amount) {
balance += amount;
System.out.println("Deposit successful. Current balance: " + balance);
}
public void withdraw(double amount) {
if (balance >= amount) {
balance -= amount;
System.out.println("Withdrawal successful. Current balance: " + balance);
} else {
System.out.println("Insufficient balance.");
}
}
public void displayInfo() {
System.out.println("Account Number: " + accountNumber);
System.out.println("Balance: " + balance);
System.out.println("Account Type: " + accountType);
}
}
public class SavingAccount extends Account {
private double interestRate;
public SavingAccount(String accountNumber, double balance, double interestRate) {
super(accountNumber, balance, "Savings");
this.interestRate = interestRate;
}
public void calculateInterest() {
double interest = balance * interestRate / 100;
System.out.println("Interest calculated: " + interest);
}
@Override
public void displayInfo() {
super.displayInfo();
System.out.println("Interest Rate: " + interestRate);
}
}
// 创建账户对象并进行操作
SavingAccount savings = new SavingAccount("SAV-001", 1000, 3.5);
savings.deposit(500);
savings.withdraw(200);
savings.calculateInterest();
savings.displayInfo();
```
代码说明:在上述代码中,定义了父类`Account`,包含账户的共同属性和方法。然后,通过定义子类`SavingAccount`继承父类,子类可以继承父类的属性和方法,并可以根据特定的业务需求进行扩展和重写。`SavingAccount`新增了计算利息的方法`calculateInterest`,并重写了`displayInfo`方法来展示账户的信息。最后,创建子类的对象并进行相关操作和展示账户信息。
#### 3.3 扩展和定制化需求的实现
继承关系还可以用于扩展和定制化需求的实现。通过继承父类,子类可以在父类的基础上添加新的功能、修改现有功能,以满足复杂的业务需求。
例如,在一个电商平台的订单系统中,有多种类型的订单,如普通订单、团购订单、秒杀订单等。每种订单类型有不同的流程和逻辑,但也有一些共同的属性和方法,如订单号、订单金额、下单时间等。可以定义一个父类`Order`,包含共同的属性和方法,然后每种订单类型可以作为父类的子类,并根据具体需求进行扩展和定制化实现。
```python
class Order:
def __init__(self, order_number, total_amount, ordered_at):
self.order_number = order_number
self.total_amount = total_amount
self.ordered_at = ordered_at
def calculate_discount(self):
# 共同的折扣计算逻辑
pass
def process_payment(self):
# 共同的支付处理逻辑
pass
class GroupOrder(Order):
def __init__(self, order_number, total_amount, ordered_at, group_size):
super().__init__(order_number, total_amount, ordered_at)
self.group_size = group_size
def calculate_discount(self):
# 团购订单的折扣计算逻辑
pass
def process_payment(self):
# 团购订单的支付处理逻辑
pass
class FlashSaleOrder(Order):
def __init__(self, order_number, total_amount, ordered_at, start_time, end_time):
super().__init__(order_number, total_amount, ordered_at)
self.start_time = start_time
self.end_time = end_time
def calculate_discount(self):
# 秒杀订单的折扣计算逻辑
pass
def process_payment(self):
# 秒杀订单的支付处理逻辑
pass
# 创建订单对象并执行相关操作
group_order = GroupOrder("GR-001", 1000, "2021-01-01", 10)
group_order.calculate_discount()
group_order.process_payment()
flash_sale_order = FlashSaleOrder("FS-001", 500, "2021-02-01", "10:00", "12:00")
flash_sale_order.calculate_discount()
flash_sale_order.process_payment()
```
代码说明:在上述代码中,定义了父类`Order`,包含订单的共同属性和方法。然后,通过定义子类`GroupOrder`和`FlashSaleOrder`分别继承父类,子类可以继承父类的属性和方法,并可以根据具体需求进行扩展和定制化实现。每个子类实现了自己特有的折扣计算逻辑和支付处理逻辑。最后,创建子类的对象并执行相关操作。
继承关系的适用场景包括代码复用和模块化、特定业务需求的实现、扩展和定制化需求的实现等。在实际开发中,需要根据具体需求,合理设计继承关系,充分发挥继承的优势,同时注意继承关系的维护和扩展,以保证代码的可读性、可维护性和可扩展性。
# 4. 继承关系的注意事项
在使用继承关系时,需要注意一些问题和注意事项,以确保代码的可维护性和灵活性。
#### 4.1 避免过度继承
过度继承会导致代码结构复杂化,增加理解和维护的难度。过度的层级关系也会增加耦合度,降低代码的灵活性。因此,在设计时要避免过度的继承关系,尽量保持简洁清晰。
#### 4.2 父类和子类的合理设计
父类应该包含子类共有的属性和行为,而子类则可以根据需要进行扩展和定制化。在设计父类时要考虑到可能的子类扩展,提供合适的扩展点和接口。
#### 4.3 继承关系的维护和扩展
在继承关系中,父类的变化会影响所有子类。因此,当需要修改父类时,必须仔细考虑对所有子类的影响,并确保行为的一致性和稳定性。
#### 4.4 继承关系的灵活性和耦合度
继承关系会增加类之间的耦合度,子类与父类之间的紧密联系也会限制其灵活性。因此,在使用继承关系时,需要权衡耦合度和灵活性,确保继承关系能够满足实际需求,并且不至于过度复杂化。
以上是在使用继承关系时需要注意的一些问题,合理的继承设计可以带来代码的重用和扩展性,但需要注意合理控制和维护。
# 5. 继承关系与其他关系的对比
在软件开发中,除了继承关系外,还存在着其他几种重要的关系,包括组合关系、接口实现和聚合关系。下面将对继承关系与这些关系进行对比,以便更好地理解它们之间的异同点和适用场景。
#### 5.1 继承关系与组合关系的比较
- 继承关系是一种"is-a"关系,表示子类是父类的一种特殊类型,具有父类的属性和方法。
- 组合关系是一种"has-a"关系,表示一个类包含另一个类作为其成员变量,实现了代码的复用和模块化。
在实际应用中,当子类需要继承父类的行为并扩展其功能时,可以选择继承关系;当某个类需要使用另一个类的功能而不具备继承关系时,可以选择组合关系。
#### 5.2 继承关系与接口实现的比较
- 继承关系中,子类继承父类的属性和方法,并可以重写父类方法以实现特定功能。
- 接口实现是为了达成某种规范,类似于一种契约,要求实现类实现接口定义的所有方法。
在实际应用中,如果需要表达"is-a"关系并且子类需要继承父类的属性和方法,可以选择继承关系;如果需要实现一种契约或规范,可以选择接口实现关系。
#### 5.3 继承关系与聚合关系的比较
- 继承关系中,子类继承父类的属性和方法,并具有"is-a"关系。
- 聚合关系表示整体与部分的关系,一个类作为另一个类的成员变量存在。
在实际应用中,如果需要表达"is-a"关系并且子类需要继承父类的属性和方法,可以选择继承关系;如果需要表示整体与部分的关系,可以选择聚合关系。
通过以上对比,可以更好地理解继承关系与其他关系之间的区别和联系,从而更加准确地选择适合的关系来设计和实现软件系统。
# 6. 总结与展望
### 6.1 继承关系的优势和局限性
继承关系作为面向对象编程中的重要特性,具有以下优势:
- 代码复用和模块化:通过继承,子类可以直接继承父类的属性和方法,避免了重复编写相同的代码,提高了代码的复用性和可维护性。
- 特定业务需求的实现:继承关系可以将类层次化,根据不同的业务需求,定义不同的子类,使得代码结构更加清晰和易于扩展。
- 扩展和定制化需求的实现:通过继承,可以在不修改父类的情况下,对其进行扩展和定制化,满足特定的需求。
然而,继承关系也存在一些局限性:
- 过度继承的问题:当继承关系过于复杂或层次过深时,会导致代码可读性降低,维护和调试困难。
- 父类和子类的设计需要谨慎:父类的设计需要足够通用,而子类的设计需要遵循单一责任原则,避免出现类的职责分散和耦合度过高的情况。
- 继承关系的维护和扩展:修改父类的实现可能会影响所有子类的行为,需要慎重考虑。
- 继承关系的灵活性和耦合度:子类与父类之间的耦合度较高,修改父类可能会对子类产生很大的影响,因此需要注意继承关系的灵活性。
### 6.2 未来发展趋势和新的应用场景
随着软件开发需求的不断变化和发展,继承关系也在不断演变和应用于新的场景:
- 混合继承:除了单继承和多继承的传统模式外,混合继承成为一种新的趋势,通过结合多种继承方式,实现更灵活和可扩展的类设计。
- 接口继承的强化:接口继承在一些编程语言中得到了强化,作为一种更加纯粹和抽象的继承方式,适用于需要实现标准接口的场景。
- 组件化开发:随着软件架构的转型,组件化开发成为一种流行的开发模式,继承关系在组件之间的交互中扮演着重要的角色,实现代码的复用和模块化。
- 元编程和反射:元编程和反射技术的发展使得动态继承成为可能,可以在运行时动态地修改和扩展类的行为。
总之,继承关系作为面向对象编程的基础特性之一,一直在不断地演进和适应新的需求。在未来的发展中,我们可以期待继承关系在软件开发中的更广泛应用。
通过以上分析和总结,我们对继承关系有了更深入的理解,并了解了其优势、局限性以及未来的发展趋势。在实际的软件开发中,我们应该灵活运用继承关系,根据具体的业务需求和设计目标,合理地使用继承关系,以实现代码的复用、结构的清晰和系统的可维护性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"C面向对象编程方法"为主题,旨在探索面向对象编程在C语言中的应用与实践。专栏将从基础概念入手,介绍对象和类的概念及其关系,探讨如何在C语言中实现面向对象编程。紧接着,我们将深入探讨面向对象编程的核心概念,包括继承、多态、抽象类和接口的使用等。同时,我们还会详细讨论静态成员和静态方法的使用方法,以及复合关系和关联关系的区别与使用。此外,我们将针对继承关系的适用场景与注意事项进行探讨,并介绍如何使用封装提高代码的可维护性和可重用性。同时,我们将帮助读者避免继承陷阱,掌握继承和多态的核心概念。此外,我们还将探讨如何使用C的函数模板提高代码的灵活性,并解决对象之间的依赖关系问题。最后,我们将总结面向对象设计的五个原则,并深入讨论在设计复杂系统时的类和对象关系。通过本专栏的学习,读者将能够全面了解面向对象编程在C语言中的应用方法,提升自己的编程技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【银行系统建模基础】:UML图解入门与实践,专业破解建模难题
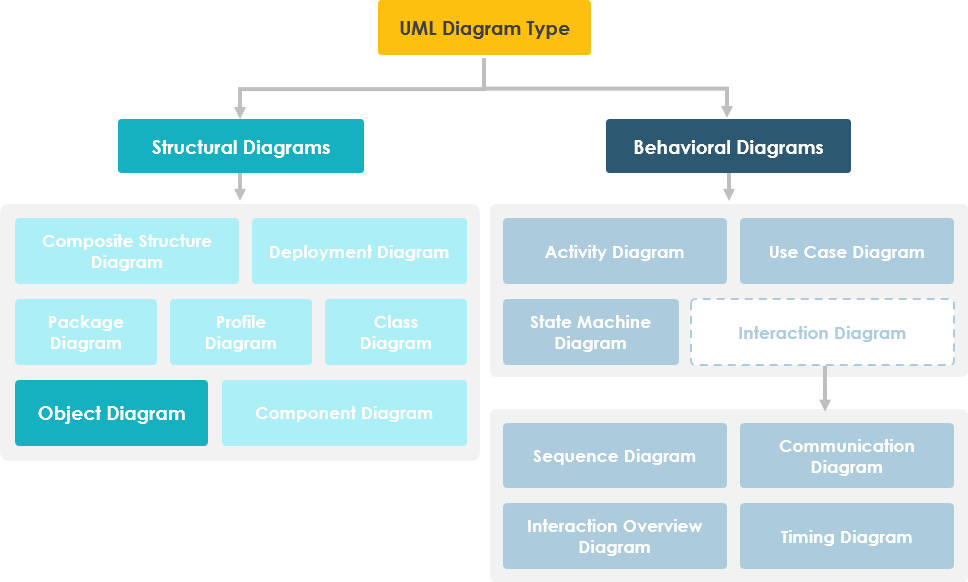
# 摘要
本文系统地介绍了UML在银行系统建模中的应用,从UML基础理论讲起,涵盖了UML图解的基本元素、关系与连接,以及不同UML图的应用场景。接着,本文深入探讨了银行系统用例图、类图的绘制与分析,强调了绘制要点和实践应用。进一步地,文章阐释了交互图与活动图在系统行为和业务流程建模中的设
深度揭秘:VISSIM VAP高级脚本编写与实践秘籍
# 摘要
本文详细探讨了VISSIM VAP脚本的编程基础与高级应用,旨在为读者提供从入门到深入实践的完整指导。首先介绍了VAP脚本语言的基础知识,包括基础语法、变量、数据类型、控制结构、类与对象以及异常处理,为深入编程打下坚实的基础。随后,文章着重阐述了VAP脚本在交通模拟领域的实践应用,包括交通流参数控制、信号动态管理以及自定义交通规则实现等。本文还提供了脚本优化和性能提升的策略,以及高级数据可视化技术和大规模模拟中的应用。最
【软件实施秘籍】:揭秘项目管理与风险控制策略
# 摘要
软件实施项目管理是一个复杂的过程,涉及到项目生命周期、利益相关者的分析与管理、风险管理、监控与控制等多个方面。本文首先介绍了项目管理的基础理论,包括项目定义、利益相关者分析、风险管理框架和方法论。随后,文章深入探讨了软件实施过程中的风险控制实践,强调了风险预防、问题管理以及敏捷开发环境下的风险控制策略。在项目监控与控制方面,本文分析了关键指标、沟通管理与团队协作,以及变
RAW到RGB转换技术全面解析:掌握关键性能优化与跨平台应用策略

# 摘要
本文系统地介绍了RAW与RGB图像格式的基础知识,深入探讨了从RAW到RGB的转换理论和实践应用。文章首先阐述了颜色空间与色彩管理的基本概念,接着分析了RAW
【51单片机信号发生器】:0基础快速搭建首个项目(含教程)
# 摘要
本文系统地介绍了51单片机信号发生器的设计、开发和测试过程。首先,概述了信号发生器项目,并详细介绍了51单片机的基础知识及其开发环境的搭建,包括硬件结构、工作原理、开发工具配置以及信号发生器的功能介绍。随后,文章深入探讨了信号发生器的设计理论、编程实践和功能实现,涵盖了波形产生、频率控制、编程基础和硬件接口等方面。在实践搭建与测试部分,详细说明了硬件连接、程序编写与上传、以
深入揭秘FS_Gateway:架构与关键性能指标分析的五大要点

# 摘要
FS_Gateway作为一种高性能的系统架构,广泛应用于金融服务和电商平台,确保了数据传输的高效率与稳定性。本文首先介绍FS_Gateway的简介与基础架构,然后深入探讨其性能指标,包括吞吐量、延迟、系统稳定性和资源使用率等,并分析了性能测试的多种方法。针对性能优化,本文从硬件和软件优化、负载均衡及分布式部署角度提出策略。接着,文章着重阐述了高可用性架构设计的重要性和实施策略,包括容错机制和故障恢复流程。最后,通过金
ThinkServer RD650故障排除:快速诊断与解决技巧

# 摘要
本文全面介绍了ThinkServer RD650服务器的硬件和软件故障诊断、解决方法及性能优化与维护策略。首先,文章对RD650的硬件组件进行了概览,随后详细阐述了故障诊断的基础知识,包括硬件状态的监测、系统日志分析、故障排除工具的使用。接着,针对操作系统级别的问题、驱动和固件更新以及网络与存储故障提供了具体的排查和处理方法。文章还探讨了性能优化与
CATIA粗糙度参数实践指南:设计师的优化设计必修课
# 摘要
本文详细探讨了CATIA软件中粗糙度参数的基础知识、精确设定及其在产品设计中的综合应用。首先介绍了粗糙度参数的定义、分类、测量方法以及与材料性能的关系。随后,文章深入解析了如何在CATIA中精确设定粗糙度参数,并阐述了这些参数在不同设计阶段的优化作用。最后,本文探讨了粗糙度参数在机械设计、模具设计以及质量控制中的应用,提出了管理粗糙度参数的高级策略,包括优化技术、自动化和智能
TeeChart跨平台部署:6个步骤确保图表控件无兼容问题
# 摘要
本文介绍TeeChart图表控件的跨平台部署与兼容性分析。首先,概述TeeChart控件的功能、特点及支持的图表类型。接着,深入探讨TeeChart的跨平台能力,包括支持的平台和部署优势。第三章分析兼容性问题及其解决方案,并针对Windows、Linux、macOS和移动平台进行详细分析。第四章详细介绍TeeChart部署的步骤,包括前期准备、实施部署和验证测试。第五
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )