PL_0编译器前端设计:现代方法与前沿技术探索
发布时间: 2024-12-15 11:17:30 阅读量: 4 订阅数: 5 

pl0编译器_编译原理_编译器_PL/0_pl0_
参考资源链接:[PL/0编译程序研究与改进:深入理解编译原理和技术](https://wenku.csdn.net/doc/20is1b3xn1?spm=1055.2635.3001.10343)
# 1. 编译器前端基础知识
## 1.1 编译器的基本组成
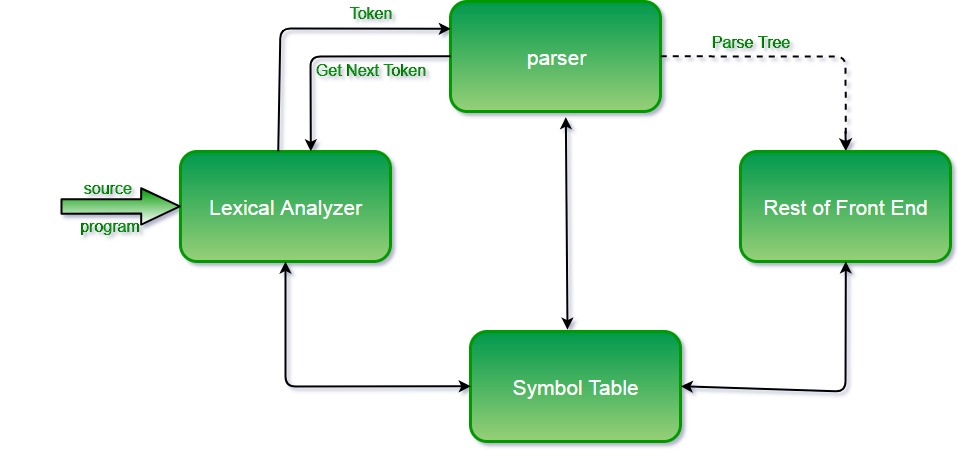
编译器是一个将源代码转换为机器代码的软件程序,分为前端和后端。编译器前端主要负责理解源程序,涉及词法分析、语法分析、语义分析等步骤,将源代码转换为中间表示(IR),为后端的代码生成与优化铺平道路。
## 1.2 编译器前端的关键任务
编译器前端需要处理的主要任务包括:
- **词法分析**:将源代码文本分解为一系列的词法单元(tokens),例如关键字、标识符和操作符。
- **语法分析**:根据词法单元构建抽象语法树(AST),确保源代码符合语言的语法规则。
- **语义分析**:对AST进行语义检查,包括类型检查、作用域解析以及变量声明前使用等错误的检测。
## 1.3 编译器前端的技术栈
理解编译器前端的技术栈涉及了解各种数据结构和算法,包括但不限于:
- **状态机**:用于实现词法分析器,识别输入文本中的有效词法单元。
- **文法**:描述语言的语法规则,通常使用BNF(巴科斯-诺尔范式)或EBNF(扩展巴科斯-诺尔范式)。
- **递归下降解析**:一种自顶向下解析方法,用于语法分析阶段。
在深入探讨编译器前端的更高级主题之前,了解这些基础知识是至关重要的。它们为理解后续的编译过程打下了坚实的理论基础,并为实现编译器前端的各个组成部分提供了必要的工具和方法论。
# 2. PL_0语言规范与词法分析
## 2.1 PL_0语言的语法规则
### 2.1.1 基本语法结构概述
PL_0语言是一种结构化的教学用编程语言,其设计思想源自Pascal语言,但更为简化。它用于帮助初学者理解编译器前端的关键概念,如词法分析、语法分析和语义分析。PL_0语言的主要目标是提供一个清晰、规范的语法规则集,以便于学习和实现编译器前端。
在PL_0中,程序是由一系列的语句(statement)构成的,语句可以是赋值语句、复合语句、条件语句、循环语句和输入输出语句。程序的结构类似于以下的伪代码:
```plaintext
PROGRAM = BLOCK .
BLOCK = { DECLARATION ; STMT } .
DECLARATION = CONST DECLARATIONS | VAR DECLARATIONS .
STMT = ASSIGN | BLOCK | IF | WHILE | CALL | READ | WRITE .
```
### 2.1.2 关键词、标识符和字面量
在PL_0的语法规则中,关键词(keywords)是具有特殊意义的保留字,例如 `program`, `begin`, `end`, `if`, `then`, `while`, `do` 等。它们不能用作变量名或其他标识符。
标识符(identifiers)用于变量名、过程名等,遵循的规则是:必须以字母开头,后面可以跟字母或数字,长度不得超过20个字符。例如 `x`, `number1`, `total_sum` 等都是合法的标识符。
字面量(literals)包括整数和布尔值。整数字面量是直接表示的非负整数,例如 `0`, `123`, `1000`。布尔值字面量是 `true` 和 `false`。
## 2.2 PL_0词法分析器设计
### 2.2.1 状态机理论与实现
词法分析是编译过程的第一个阶段,其任务是读入源程序的字符序列,将它们组织成有意义的词素序列,并输出相应的词法单元。PL_0词法分析器的实现基于有限状态自动机(Finite State Machine, FSM)的理论,它将源代码作为输入,识别出合法的词素,并根据词法单元的类型输出对应的标记(token)。
FSM包含一系列的状态和转移规则。在PL_0词法分析器中,状态机从初始状态开始,根据当前读取的字符和状态,决定转移到哪个状态。例如,当状态机在初始状态下读到字母时,会转移到标识符识别的状态;如果读到数字,则会转移到数字字面量识别的状态。
以下是一个简化的状态转移示例表格:
| 当前状态 | 读入字符 | 转移到的新状态 | 输出的Token |
|----------|----------|----------------|-------------|
| 初始 | 字母 | 标识符状态 | |
| 初始 | 数字 | 数字状态 | |
| ... | ... | ... | ... |
### 2.2.2 词法单元的分类与识别
PL_0词法单元包括以下几种类型:
- 关键词(如 `if`, `then` 等)
- 标识符(变量名或函数名)
- 数字字面量
- 字符串字面量
- 符号(如运算符 `+`, `-`, `*`, `/` 和分隔符 `;`, `,` 等)
为了识别上述的词法单元,PL_0词法分析器使用一系列的模式匹配规则。这些规则描述了如何从源代码文本中识别每个词法单元。例如,数字字面量的模式可以是 `[0-9]+`,表示一个或多个连续的数字字符。
### 2.2.3 错误检测与恢复策略
词法分析阶段的错误检测主要涉及非法字符的识别和未预期的输入格式。为了提高词法分析器的健壮性,必须设计有效的错误检测机制和错误恢复策略。
错误检测可以在状态转移失败时进行,即当输入字符不满足任何有效的转移规则时。在这种情况下,词法分析器会报告错误,然后采取恢复策略,通常是跳过当前的非法字符,继续处理后续的合法输入。
一个简单的错误检测与恢复的伪代码示例:
```python
while not end of file:
token = next_token()
if token is error:
skip_unexpected_input()
report_error()
```
## 2.3 PL_0词法分析器的实现
### 2.3.1 词法分析器的编码实现
在本节中,我们将展示PL_0词法分析器的基本实现代码块。词法分析器通常由两个主要部分组成:扫描器(scanner)和词法单元生成器。
扫描器负责读取源代码的字符流,并将它们转换为标记流。而词法单元生成器则根据扫描器提供的标记和预定义的模式,生成对应的词法单元。
```python
# 示例代码:词法分析器的简化实现
# 定义Token类型
class Token:
def __init__(self, type, value):
self.type = type
self.value = value
# 词法分析器类
class Lexer:
def __init__(self, text):
self.text = text
self.pos = 0
self.current_char = self.text[self.pos]
def advance(self):
"""Advance the 'pos' pointer and set the 'current_char'."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
"""Skip whitespace."""
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer or float consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
if self.current_char == '.':
result += self.current_char
self.advance()
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
token = Token(NUMBER, float(result))
else:
token = Token(NUMBER, int(result))
return token
```
词法分析器的实现需要对源代码进行逐字符的读取和分析,这需要借助一个循环,持续从源代码中提取下一个字符,然后根据当前状态决定下一步的动作。例如,当遇到字母时,可能需要进入一个循环,以读取完整的标识符或关键字。
### 2.3.2 词法单元的识别和输出
PL_0词法分析器的核心工作在于识别词法单元并输出相应的Token。下面的代码段是一个简化的词法分析器如何将源代码字符序列转换为Token序列的过程:
```python
# 伪代码:词法单元的识别和输出过程
def get_n
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 PL/0 编译程序的各个方面,从词法分析到代码生成,再到优化、调试和性能评估。通过一系列专业文章,该专栏提供了对 PL/0 编译器内部工作原理的全面理解。它涵盖了现代方法、前沿技术、性能优化、错误处理和最佳实践。此外,该专栏还探讨了模块化构建、内存管理、自动化测试、跨平台策略、多线程处理和安全性分析等主题。通过深入分析和实战技巧,该专栏旨在帮助读者掌握 PL/0 编译程序的复杂性,并提高其设计、开发和维护能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【IEC 60115-1:2020规范解读】:权威指南助你精通电阻器可靠性要求

参考资源链接:[IEC 60115-1:2020 电子设备固定电阻器通用规范英文完整版](https://wenku.csdn.net/doc/6412b722be7fbd1778d49356?spm=1055.2635.3001.10343)
# 1. IEC 60115-1:2020标准概述
IEC 60115-1:2020是国际电工委员会(IEC)发布的一份
性能优化大师:DLT 698.45-2017扩展协议的提速秘诀
参考资源链接:[DLT 698.45-2017扩展协议详解:通信速率协商与电能表更新](https://wenku.csdn.net/doc/5gtwkw95nz?spm=1055.2635.3001.10343)
# 1. DLT 698.45-2017扩展协议概述
在当今快速发展的信息技术时代,DL
西门子S7-1500同步控制案例深度解析:复杂运动控制的实现
参考资源链接:[S7-1500西门子同步控制详解:MC_GearIn与绝对同步功能](https://wenku.csdn.net/doc/2nhppda6b3?spm=1055.2635.3001.10343)
# 1. 西门子S7-1500同步控制概述
西门子S7-1500作为先进的可编程逻辑控制器(PLC),在工业自动化领域内提供了一系列同步控制解决方案,这些方案广泛应用于需要精密时序和高精度控制的场合,如机械运动同步、物料搬运系统等。本章将探
个性化定制你的ROST CM6工作环境:一步到位的设置教程!

参考资源链接:[ROST CM6使用手册:功能详解与操作指南](https://wenku.csdn.net/doc/79d2n0f5qe?spm=1055.2635.3001.10343)
# 1. ROST CM6环境介绍
在信息技术领域,随着开源文化的发展,定制操作系统环境变得越来越流行。ROST CM6作为一种基于Linux的高级定制操作系统,集成了众多
高精度数据采集:STM32G431 ADC应用详解及实战技巧

参考资源链接:[STM32G431开发板详解:接口与芯片原理图指南](https://wenku.csdn.net/doc/6462d47e543f8444889
灯光控台MA2视觉盛宴:5步打造完美演出照明

参考资源链接:[MA2灯光控台:集成系统与全面兼容的创新解决方案](https://wenku.csdn.net/doc/6412b5a7be7fbd1778d43ec8?spm=1055.2635.3001.10343)
# 1. 灯光控台MA2概述
在现代戏剧、音乐会以及各种舞台活动中,灯光控制台是创造视觉效果的核心工具之一。MA2作为行业
FEMFAT入门到精通:快速掌握材料疲劳分析(24小时速成指南)
参考资源链接:[FEMFAT疲劳分析教程:参数设置与模型导入详解](https://wenku.csdn.net/doc/5co5x8g8he?spm=1055.2635.3001.10343)
# 1. FEMFAT概述及材料疲劳基础
## 1.1 FEMFAT简介
FEMFAT是汽车行业广泛使用的疲劳分析软件,它能够对复杂的工程结构进行寿命预测
Keil 5芯片选型攻略:找到最适合你的MCU的秘诀
参考资源链接:[Keil5软件:C51与ARM版本芯片添加指南](https://wenku.csdn.net/doc/64532401ea0840391e76f34d?spm=1055.2635.3001.10343)
# 1. Keil 5与MCU芯片概述
微控制器单元(MCU)是嵌入式系统中的核心组件,负责处理和管理系统的各项任务。Keil 5是一个流行的集成开发环境(IDE),被广泛应用于MCU的开发和调试工作。本章我们将探索Keil 5的基本功能和与MCU芯片的相关性。
## 1.1 MCU芯片的角色和应用
微控制器单元(MCU)是数字电路设计中的"大脑",它在各种电子设备中发挥
【轨道数据分析】:Orekit中的高级处理技巧详解

参考资源链接:[Orekit安装与使用指南:从基础知识到卫星轨道计算](https://wenku.csdn.net/doc/ujjz6880d0?spm=1055.2635.3001.10343)
# 1. 轨道数据分析概述
轨道数据分析是航天工程领域的重要组成部分,它涉及到利用数学和物理原理对卫星和其他空间物体的运行轨迹进行精确模拟和预测。本章旨在为读者提供轨道数据分析的基础知识,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )