5. XPath的文本、属性和命名空间操作
发布时间: 2024-02-26 12:19:11 阅读量: 133 订阅数: 44 

XPATH读取有命名空间的节点
# 1. 理解XPath基础
XPath是一种用于在XML文档中定位和选择节点的语言,它提供了一种简洁而强大的方式来处理XML结构化数据。在本章节中,我们将介绍XPath的基础知识,包括其概念、基本语法和常见用法,以及如何使用XPath来定位和提取文本信息。
## 1.1 什么是XPath?
XPath(XML Path Language)是一种用于在XML文档中导航和查询节点的语言。它可以帮助我们快速准确地定位到XML文档中的特定节点,从而方便地提取需要的信息。XPath通常被用于XML文档的解析、数据挖掘和网页信息抽取等领域。
## 1.2 XPath的基本语法和用法
XPath的基本语法包括路径表达式、节点测试、谓词等组成部分。通过XPath表达式,我们可以指定要选择的节点、属性或文本内容,从而实现对XML文档的精确操作。常用的XPath函数和操作符也能够进一步扩展XPath的功能。
## 1.3 XPath的文本定位和提取
在XPath中,文本定位和提取是一种常见的操作。通过XPath表达式中的文本函数,我们可以准确地定位到XML文档中包含特定文本内容的节点,然后提取所需的信息。这种方式对于从网页中提取信息或者解析XML数据非常有用。
通过深入学习XPath的基础知识,我们可以更加灵活高效地处理XML文档,并且能够在实际项目中应用XPath来完成数据提取和处理的任务。接下来,让我们继续探讨XPath在属性操作上的应用。
# 2. XPath属性操作
XPath不仅可以用于定位和提取HTML/XML文档中的元素,还可以操作元素的属性。在这一章节中,我们将深入探讨XPath在处理属性时的用法和技巧。
### 2.1 定位和提取HTML/XML文档中的属性值
在XPath中,可以通过`@`符号来定位和提取元素的属性。下面是一个简单的示例,演示如何使用XPath提取HTML文档中`<a>`标签的`href`属性值:
```python
from lxml import etree
# 假设html为包含了a标签的HTML文档
html = """
<html>
<body>
<a href="http://example.com">Click here!</a>
</body>
</html>
# 解析HTML文档
tree = etree.HTML(html)
# 使用XPath提取href属性值
href = tree.xpath("//a/@href")[0]
print(href) # 输出结果为:http://example.com
```
在上述代码中,我们使用XPath表达式`//a/@href`来定位`<a>`标签的`href`属性,并提取其值。
### 2.2 使用XPath定位特定属性
有时候我们需要定位具有特定属性的元素,XPath也可以很好地实现这一功能。下面是一个示例,演示如何使用XPath定位具有特定属性的元素:
```python
# 假设html为包含多个图片元素的HTML文档
html = """
<html>
<body>
<img src="image1.jpg">
<img src="image2.jpg" alt="Nature">
<img src="image3.jpg" alt="City">
</body>
</html>
# 解析HTML文档
tree = etree.HTML(html)
# 使用XPath定位具有alt属性的img元素
alt_images = tree.xpath("//img[@alt]")
for img in alt_images:
print(img.attrib['src'], img.attrib['alt'])
```
以上代码演示了如何使用XPath定位具有`alt`属性的`<img>`元素,并输出它们的`src`和`alt`属性值。
### 2.3 属性操作的常见问题和解决方案
在处理属性时,有时会遇到一些常见问题,比如属性值包含特殊字符、属性值为空等情况。针对这些问题,我们通常可以通过适当的XPath表达式和处理方法来解决。
上面的示例演示了如何使用XPath在HTML/XML文档中定位和操作属性,通过灵活运用XPath,我们可以更精准地提取需要的数据,处理各种属性操作问题。
# 3. XPath命名空间处理
XPath在处理XML文档时,经常会碰到命名空间的处理,特别是在一些复杂的XML文档中。了解命名空间的概念和XPath在处理命名空间时的注意事项是非常重要的。本章将介绍XPath命名空间处理的相关知识,并解决XPath命名空间相关的常见问题。
#### 3.1 了解命名空间的概念和作用
命名空间是XML中用于确保元素和属性名的唯一性的机制。它通过为元素和属性添加命名空间前缀来实现区分,一般形式为`prefix:localname`。XPath中对命名空间的支持使得我们能够更精确地定位和提取XML文档中的元素和属性。
#### 3.2 XPath在处理命名空间时的注意事项
在使用XPath处理带有命名空间的XML文档时,需要注意以下几点:
- 使用命名空间前缀:在XPath表达式中,需要使用命名空间前缀来定位带命名空间的元素和属性。
- 命名空间映射:需要将XML文档中使用的命名空间前缀映射到具体的命名空间URI。
- 默认命名空间:默认命名空间的处理需要格外注意,它在XPath中的处理方式与非默认命名空间略有不同。
#### 3.3 解决XPath命名空间相关的常见问题
在XPath处理带有命名空间的XML文档时,常见的问题包括命名空间前缀未映射、默认命名空间处理不当、跨命名空间定位元素等。我们将介绍如何通过XPath解决这些常见问题,以及如何优雅地处理带有命名空间的XML文档数据。
希望这些内容能够帮助您更好地理解和处理XPath命名空间相关的问题。
接下来,我们将通过实例演示如何使用XPath处理带有命名空间的XML文档。
# 4. 使用XPath提取网页信息
XPath是一种强大的工具,可以帮助我们从网页中提取所需的信息。在本章中,我们将探讨如何有效地使用XPath来提取网页信息,包括文本信息、属性值等。
#### 4.1 如何使用XPath提取网页中的文本信息
在这个场景中,我们将展示如何使用XPath来提取网页中的文本信息。假设我们要从一个示例网页中提取标题和正文内容,以下是使用Python和XPath的示例代码:
```python
from lxml import html
import requests
# 发起网页请求
page = requests.get('http://example.com')
tree = html.fromstring(page.content)
# 使用XPath提取标题
title = tree.xpath('//h1/text()')[0]
print("标题:", title)
# 使用XPath提取正文内容
content = tree.xpath('//div[@class="content"]/p/text()')
print("正文内容:")
for paragraph in content:
print(paragraph)
```
**代码解释:**
1. 通过`requests`库发送网页请求,并用`html.fromstring`将页面内容转换为可用于XPath的树结构。
2. 使用`tree.xpath()`方法并结合XPath表达式提取标题和正文内容。
3. 最后输出提取到的标题和正文内容。
**结果说明:**
- 该代码将从示例网页中成功提取到标题和正文内容,并将其打印输出。
这是一个简单的示例,演示了如何使用XPath从网页中提取文本信息。接下来,让我们看一下XPath在网页抓取和数据挖掘中的更广泛应用。
# 5. XPath的高级应用
XPath作为一种强大的路径表达式语言,在数据提取和处理中具有广泛的应用,除了基本的定位和提取功能外,还有许多高级的应用技巧和功能。在本章中,我们将深入探讨XPath的一些高级应用,包括函数、操作符、数据筛选和处理等内容。
#### 5.1 XPath的函数和操作符
XPath提供了丰富的函数和操作符,可以对节点和数值进行操作和计算,进一步扩展了XPath的功能和灵活性。以下是一些常用的函数和操作符:
```python
# Python示例代码
from lxml import etree
# 使用XPath函数:获取节点文本内容
xml = '<bookstore><book><title>Harry Potter</title></book></bookstore>'
root = etree.fromstring(xml)
result = root.xpath('//title/text()')
print(result)
# 使用XPath操作符:比较数值大小
xml = '<numbers><num>10</num><num>20</num><num>30</num></numbers>'
root = etree.fromstring(xml)
result = root.xpath('//num[number(.) > 15]/text()')
print(result)
```
**代码总结:**
- XPath函数可用于节点文本内容的提取和操作。
- XPath操作符可用于比较、计算数值等操作。
**结果说明:**
- 第一个示例输出节点 `<title>` 的文本内容 "Harry Potter"。
- 第二个示例输出大于 15 的数值节点的文本内容 "20" 和 "30"。
#### 5.2 使用XPath进行数据筛选和处理
通过结合XPath的路径表达式和函数/操作符,可以实现复杂的数据筛选和处理功能,对于大规模数据集的提取和分析非常实用。以下是一个示例:
```java
// Java示例代码
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(new InputSource(new StringReader(xml)));
XPathFactory xPathfactory = XPathFactory.newInstance();
XPath xpath = xPathfactory.newXPath();
XPathExpression expr = xpath.compile("//book[price>20]");
NodeList nl = (NodeList) expr.evaluate(doc, XPathConstants.NODESET);
for (int i = 0; i < nl.getLength(); i++) {
System.out.println(nl.item(i).getTextContent());
}
```
**代码总结:**
- 结合XPath路径表达式和条件,实现对数据的筛选和过滤。
- 使用XPath表达式对XML文档进行查询,并输出符合条件的节点内容。
**结果说明:**
- 示例中筛选出价格大于 20 的书籍节点,并输出其内容。
#### 5.3 XPath在XML处理和解析中的扩展应用
除了在数据提取和筛选中的应用外,XPath还可以结合XSLT等技术实现XML的转换、处理和解析,为XML文档的操作提供了便利和灵活性。以下是一个简单的示例:
```javascript
// JavaScript示例代码
var xml = "<book><title>JavaScript Ninja</title><author>John Resig</author></book>";
var xmlDoc = new DOMParser().parseFromString(xml, 'text/xml');
var xPathResult = xmlDoc.evaluate('//title/text()', xmlDoc, null, XPathResult.ANY_TYPE, null);
var title = xPathResult.iterateNext().nodeValue;
console.log(title);
```
**代码总结:**
- 使用XPath结合DOM解析XML文档,并提取所需内容。
- XPath与XSLT、DOM等结合应用,实现XML文档的处理与解析。
**结果说明:**
- 示例中提取出书籍标题 "JavaScript Ninja"。
本章介绍了XPath的高级应用,包括函数、操作符、数据处理等内容,并通过具体示例展示了这些技巧的实际应用场景和效果。XPath的强大功能和灵活性为数据处理和XML操作提供了便利和支持。
# 6. 实例分析与实战演练
在本章中,我们将通过实例分析和实战演练来深入理解XPath的应用,以及在实际项目中可能遇到的挑战和解决方案。
### 6.1 实际案例分析:使用XPath提取特定网页信息
在这个实例中,我们将以Python语言为例,演示如何使用XPath提取特定网页信息。首先,我们需要安装lxml模块,它是Python中用于解析HTML和XML文档的模块。
```python
# 安装lxml模块
pip install lxml
```
接下来,我们将使用lxml库和XPath表达式来提取网页中的特定信息。假设我们要从一个网页中提取所有标题为"H2"的内容,代码如下所示:
```python
from lxml import etree
import requests
# 发起HTTP请求获取网页内容
response = requests.get('https://example.com')
html = response.text
# 使用lxml解析网页内容
tree = etree.HTML(html)
# 使用XPath提取特定信息(此处以H2标题为例)
titles = tree.xpath('//h2/text()')
# 输出提取的信息
for title in titles:
print(title)
```
通过上述代码,我们可以成功提取网页中所有H2标题的文本内容。这个实例演示了如何在实际项目中使用XPath来获取特定网页信息。
### 6.2 实战演练:利用XPath解析和处理XML文档数据
在这个实战演练中,我们将使用Java语言来演示如何利用XPath解析和处理XML文档数据。假设我们有一个XML文档如下:
```xml
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
```
我们将使用Java语言和XPath表达式提取所有书籍的标题和价格信息,代码如下所示:
```java
// 导入XPath相关的Java库
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathFactory;
import org.xml.sax.InputSource;
import org.w3c.dom.Document;
// 解析XML文档
Document doc = // 从文件或字符串中加载XML文档
// 创建XPath实例
XPath xpath = XPathFactory.newInstance().newXPath();
// 使用XPath提取标题和价格信息
String expression = "//book/title | //book/price";
NodeList nodeList = (NodeList) xpath.compile(expression).evaluate(doc, XPathConstants.NODESET);
// 输出提取的信息
for (int i = 0; i < nodeList.getLength(); i++) {
System.out.println(nodeList.item(i).getTextContent());
}
```
上述代码演示了如何使用Java语言和XPath从XML文档中提取特定信息。这个实战演练可以帮助读者更好地理解XPath在XML数据处理中的应用。
### 6.3 探索XPath在实际项目中的应用与挑战
在本节中,我们将探讨XPath在实际项目中的应用与挑战。通过介绍一些真实项目中遇到的问题和解决方案,帮助读者更好地理解XPath在实际应用中可能面临的挑战,并提供相应的解决思路。
希望通过本章的内容,读者可以更深入地理解XPath的实际应用场景,并对其在项目中的使用有更清晰的认识。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以「XPath实现元素的精确定位」为主题,深入探讨了XPath在元素定位中的重要作用。首先介绍了XPath的基本语法及其在元素定位中的作用,使读者对XPath有了初步的了解。然后重点讲解了XPath对文本、属性和命名空间的操作,以及使用XPath进行元素定位的路径表达式和相对路径定位元素的方法,让读者能够灵活运用XPath进行元素定位。此外,还详细讨论了XPath定位元素的属性、通配符和模糊匹配实例,以及如何使用XPath定位符合条件的元素,展示了XPath在定位技巧和策略上的高级应用。最后,特别强调了在软件测试和JMeter中使用XPath定位元素的实践技巧,让读者能够将所学知识应用到实际项目中。通过本专栏的学习,读者将对XPath在元素定位中的应用有全面的认识,并能够灵活、准确地使用XPath定位元素。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
datasheet解读速成课:关键信息提炼技巧,提升采购效率

# 摘要
本文全面探讨了datasheet在电子组件采购过程中的作用及其重要性。通过详细介绍datasheet的结构并解析其关键信息,本文揭示了如何通过合理分析和利用datasheet来提升采购效率和产品质量。文中还探讨了如何在实际应用中通过标准采购清单、成本分析以及数据整合来有效使用datasheet信息,并通过案例分析展示了datasheet在采购决策中的具体应用。最后,本文预测了datasheet智能化处
【光电传感器应用详解】:如何用传感器引导小车精准路径

# 摘要
光电传感器在现代智能小车路径引导系统中扮演着核心角色,涉及从基础的数据采集到复杂的路径决策。本文首先介绍了光电传感器的基础知识及其工作原理,然后分析了其在小车路径引导中的理论应用,包括传感器布局、导航定位、信号处理等关键技术。接着,文章探讨了光电传感器与小车硬件的集成过程,包含硬件连接、软件编程及传感器校准。在实践部分,通过基
新手必看:ZXR10 2809交换机管理与配置实用教程
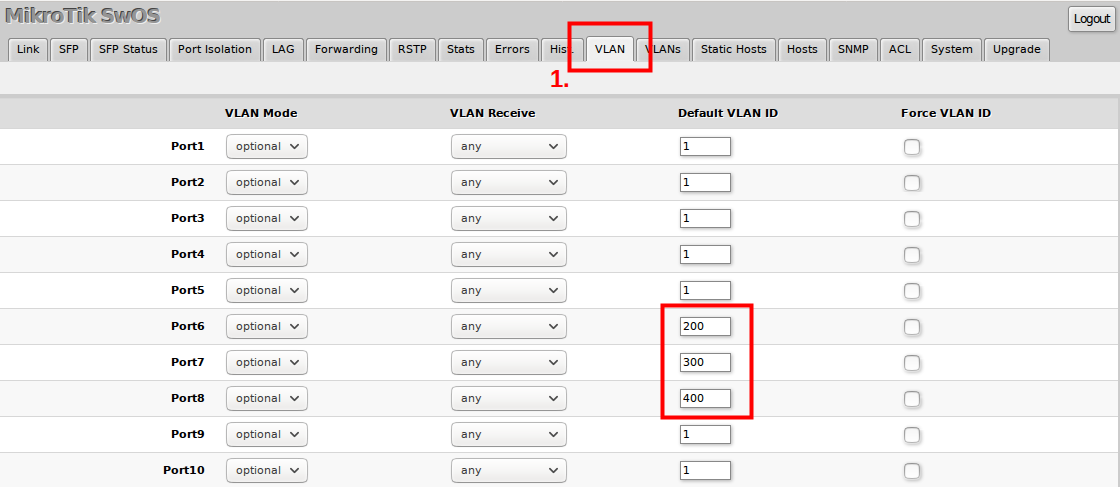
# 摘要
ZXR10 2809交换机作为网络基础设施的关键设备,其配置与管理是确保网络稳定运行的基础。本文首先对ZXR10 2809交换机进行概述,并介绍了基础管理知识。接着,详细阐述了交换机的基本配置,包括物理连接、初始化配置、登录方式以及接口的配置与管理。第三章深入探讨了网络参数的配置,VLAN的创建与应用,以及交换机的安全设置,如ACL配置和端口安全。第四章涉及高级网络功能,如路由配置、性能监控、故障排除和网络优
加密技术详解:专家级指南保护你的敏感数据
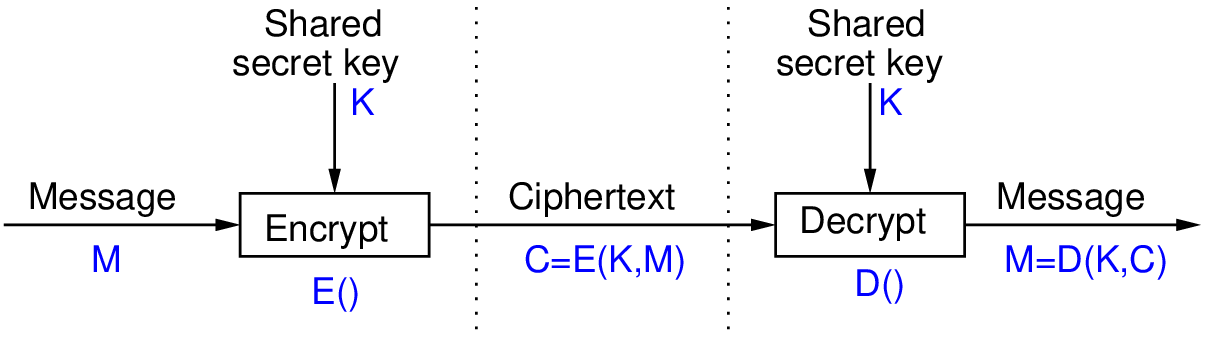
# 摘要
本文系统介绍了加密技术的基础知识,深入探讨了对称加密与非对称加密的理论和实践应用。分析了散列函数和数字签名在保证数据完整性与认证中的关键作用。进一步,本文探讨了加密技术在传输层安全协议TLS和安全套接字层SSL中的应用,以及在用户身份验证和加密策略制定中的实践。通过对企业级应用加密技术案例的分析,本文指出了实际应用中的挑战与解决方案,并讨论了相关法律和合规问题。最后,本文展望了加密技术的未来发展趋势,特别关注了量
【16串电池监测AFE选型秘籍】:关键参数一文读懂

# 摘要
本文全面介绍了电池监测AFE(模拟前端)的原理和应用,着重于其关键参数的解析和选型实践。电池监测AFE是电池管理系统中不可或缺的一部分,负责对电池的关键性能参数如电压、电流和温度进行精确测量。通过对AFE基本功能、性能指标以及电源和通信接口的分析,文章为读者提供了选择合适AFE的实用指导。在电池监测AFE的集成和应用章节中
VASPKIT全攻略:从安装到参数设置的完整流程解析

# 摘要
VASPKIT是用于材料计算的多功能软件包,它基于密度泛函理论(DFT)提供了一系列计算功能,包括能带计算、动力学性质模拟和光学性质分析等。本文系统介绍了VASPKIT的安装过程、基本功能和理论基础,同时提供了实践操作的详细指南。通过分析特定材料领域的应用案例,比如光催化、
【Exynos 4412内存管理剖析】:高速缓存策略与性能提升秘籍
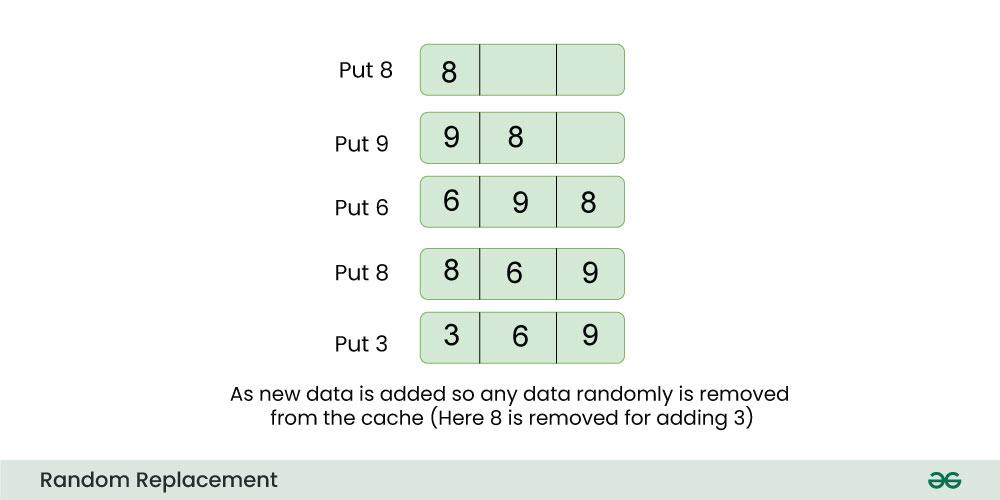
# 摘要
本文对Exynos 4412处理器的内存管理进行了全面概述,深入探讨了内存管理的基础理论、高速缓存策略、内存性能优化技巧、系统级内存管理优化以及新兴内存技术的发展趋势。文章详细分析了Exynos 4412的内存架构和内存管理单元(MMU)的功能,探讨了高速缓存架构及其对性能的影响,并提供了一系列内存管理实践技巧和性能提升秘籍。此外,
慧鱼数据备份与恢复秘籍:确保业务连续性的终极策略(权威指南)
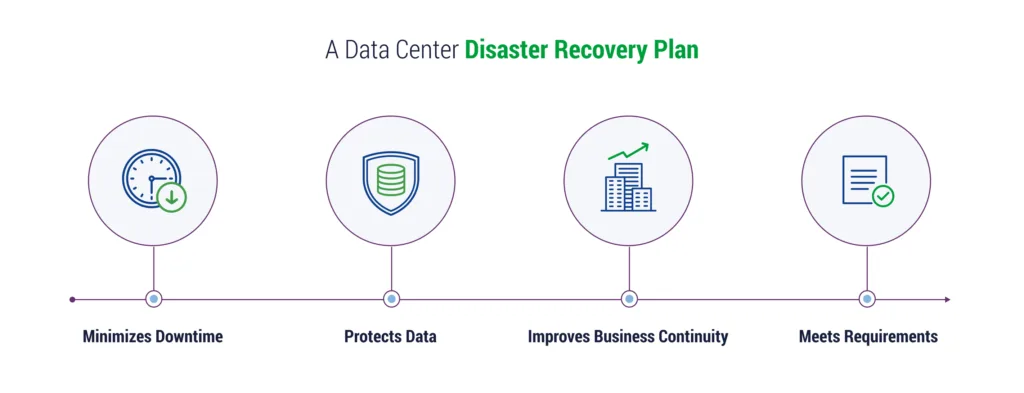
# 摘要
本文全面探讨了数据备份与恢复的基础概念,备份策略的设计与实践,以及慧鱼备份技术的应用。通过分析备份类型、存储介质选择、备份工具以及备份与恢复策略的制定,文章提供了深入的技术见解和配置指导。同时,强调了数据恢复的重要性,探讨了数据恢复流程、策略以及慧鱼数据恢复工具的应用。此
【频谱分析与Time Gen:建立波形关系的新视角】:解锁频率世界的秘密
# 摘要
本文旨在探讨频谱分析的基础理论及Time Gen工具在该领域的应用。首先介绍频谱分析的基本概念和重要性,然后详细介绍Time Gen工具的功能和应用场景。文章进一步阐述频谱分析与Time Gen工具的理论结合,分析其在信号处理和时间序列分析中的作用。通过多个实践案例,本文展示了频谱分析与Time Gen工具相结合的高效性和实用性,并探讨了其在高级应用中的潜在方向和优势。本文为相关领域的研究人员和工程师
【微控制器编程】:零基础入门到编写你的首个AT89C516RD+程序
# 摘要
本文深入探讨了微控制器编程的基础知识和AT89C516RD+微控制器的高级应用。首先介绍了微控制器的基本概念、组成架构及其应用领域。随后,文章详细阐述了AT89C516RD+微控制器的硬件特性、引脚功能、电源和时钟管理。在软件开发环境方面,本文讲述了Keil uVision开发工具的安装和配置,以及编程语言的使用。接着,文章引导读者通过实例学习编写和调试AT89C516RD+的第一个程序,并探讨了微控制器在实践应用中的接口编程和中断驱动设计。最后,本文提供了高级编程技巧,包括实时操作系统的应用、模块集成、代码优化及安全性提升方法。整篇文章旨在为读者提供一个全面的微控制器编程学习路径,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )