Python数据分析实战:10大技术洞察,让你的数据处理能力飞跃
发布时间: 2024-12-07 01:40:25 阅读量: 9 订阅数: 13 

实现SAR回波的BAQ压缩功能

# 1. Python数据分析概述
随着大数据时代的到来,数据分析已经成为了IT行业的一个重要领域。Python,作为一门开源、灵活、强大的编程语言,在数据分析领域表现出了卓越的性能。数据分析不仅仅是数字的游戏,它更是一种将原始数据转化为有价值的洞察,进而推动业务发展的艺术。
在本章节,我们将简要概述Python在数据分析中的作用,它如何从数据清洗到数据可视化,再到深入的数据解释和业务决策支持,为IT专业人士提供了一个全面的工具集。我们会讨论Python数据分析的核心库,比如Pandas、NumPy和Matplotlib,并将阐述数据分析流程中的关键步骤。
此外,本章也会对Python数据分析的应用场景进行分析,例如金融分析、市场研究、机器学习等,帮助读者了解Python数据分析在不同领域的具体应用方式,为进一步学习和实践打下坚实基础。
# 2. Python数据分析环境搭建
## 2.1 Python数据分析的必备工具
### 2.1.1 安装Anaconda和Jupyter
Python数据分析离不开强大的数据科学工具包,而Anaconda是其中的佼佼者。Anaconda是一个开源的Python发行版本,其包含了丰富的数据科学库和环境管理工具。Jupyter Notebook则是数据科学家和分析师用于展示和分享代码、结果与可视化结果的交互式平台。
**安装Anaconda:**
在安装Anaconda前,请访问[Anaconda官网](https://www.anaconda.com/products/individual)下载适合自己操作系统的Anaconda安装包。下载完成后,执行安装程序并遵循向导指示完成安装。需要注意的是,在安装过程中选择将Anaconda路径加入到环境变量,这样可以在任何目录下使用Anaconda中的Python和命令行工具。
**安装Jupyter:**
Anaconda安装完成后,Jupyter Notebook已经可以使用。打开命令行工具,输入以下命令安装JupyterLab,JupyterLab是Jupyter Notebook的新版本,提供更灵活和强大的用户界面:
```bash
conda install -c conda-forge jupyterlab
```
安装完成后,可以通过运行`jupyter lab`命令在浏览器中启动JupyterLab界面。
### 2.1.2 配置Pandas和NumPy库
Pandas和NumPy是数据分析的核心库。Pandas用于处理结构化数据,而NumPy是Python中用于科学计算的基础库。它们是几乎所有数据科学项目的基础。
**配置Pandas:**
在命令行中运行以下命令安装Pandas:
```bash
pip install pandas
```
**配置NumPy:**
同样,在命令行中输入以下命令安装NumPy:
```bash
pip install numpy
```
在安装这些库之后,通常需要进行配置以确保它们能够正常工作。检查库是否正确安装可以通过运行:
```bash
python -c "import pandas as pd; print(pd.__version__)"
python -c "import numpy as np; print(np.__version__)"
```
如果安装无误,命令行将输出各自库的版本号。
## 2.2 Python环境管理与虚拟环境
### 2.2.1 使用pipenv进行环境管理
在开发多个项目时,保持依赖关系的独立性和一致性是非常重要的。Pipenv是一个为Python项目而生的虚拟环境管理工具,它结合了`pip`和`virtualenv`的功能,用于管理包依赖关系和环境变量。
**安装pipenv:**
通过以下命令安装pipenv:
```bash
pip install pipenv
```
**创建和使用虚拟环境:**
进入你的项目目录,运行以下命令创建一个虚拟环境:
```bash
pipenv --python 3.8
```
这里指定了Python版本为3.8。之后,你可以通过`pipenv shell`命令启动虚拟环境,或者使用`pipenv install <package_name>`安装包,这样可以将依赖自动记录到`Pipfile`中。
### 2.2.2 用virtualenv创建虚拟环境
`virtualenv`是一个用于创建隔离的Python环境的工具,与`pipenv`相比,它更轻量级,但是需要手动管理依赖文件。
**安装virtualenv:**
```bash
pip install virtualenv
```
**创建和激活虚拟环境:**
在项目目录下,运行以下命令创建虚拟环境:
```bash
virtualenv venv
```
然后通过以下命令激活虚拟环境:
```bash
# Windows
venv\Scripts\activate
# macOS/Linux
source venv/bin/activate
```
## 2.3 数据分析项目结构设计
### 2.3.1 项目目录布局的最佳实践
一个良好的项目结构有助于维护和扩展项目的代码。以下是一个基本的数据分析项目目录结构推荐:
```
project_name/
│
├── data/
│ ├── raw/
│ ├── processed/
│ └── README.md
│
├── notebooks/
│ └── analysis.ipynb
│
├── src/
│ ├── __init__.py
│ └── module.py
│
├── tests/
│ └── test_module.py
│
├── .gitignore
├── requirements.txt
└── setup.py
```
- **data/**: 存放项目的原始数据和处理后的数据。
- **notebooks/**: 存放交互式分析用的Jupyter Notebook文件。
- **src/**: 存放源代码文件。
- **tests/**: 存放单元测试文件。
- **.gitignore**: 忽略文件列表。
- **requirements.txt**: 列出项目依赖。
- **setup.py**: 项目的安装配置文件。
### 2.3.2 文件和模块组织策略
组织文件和模块以保持代码的可读性和可维护性是很重要的。一个Python模块通常包含一个或多个函数和类,并且通常有相应的测试模块。在src目录下组织模块,每个模块通常包含一个`__init__.py`文件,将其标记为Python包。
例如,如果你有一个模块名为`utils.py`,你可以这样导入它:
```python
from src.utils import some_function
```
通过这样的目录结构和模块组织,项目将更加易于导航和维护,同时也便于其他开发者理解和协作。
# 3. Python数据处理与清洗技术
## 3.1 数据预处理基础
### 数据预处理的意义
数据预处理是数据分析的第一步,也是至关重要的一步。在实践中,原始数据往往含有噪声、异常值、缺失值等问题,这些问题如果不加以处理,会对后续的数据分析和模型构建产生不良影响。因此,数据预处理的主要目标是提高数据质量,为后续分析打下坚实的基础。
数据预处理通常包括数据清洗、数据集成、数据转换和数据规约四个步骤。其中,数据清洗主要处理缺失值和异常值;数据集成处理来自多个源的数据;数据转换处理数据格式和结构问题;数据规约则是减少数据量但尽量保留重要信息的过程。
### 3.1.1 Pandas数据结构简介
Pandas是一个强大的Python数据分析工具库,它提供了高效的数据结构和数据分析工具。Pandas中的两个主要数据结构是Series和DataFrame。
Series是一维数组结构,能够存储任何数据类型(整数、字符串、浮点数、Python对象等),其索引默认为整数序列。下面是创建Series的一个简单示例:
```python
import pandas as pd
# 创建一个Series
data = pd.Series([0.25, 0.5, 0.75, 1.0])
print(data)
```
输出结果将如下所示:
```
0 0.25
1 0.50
2 0.75
3 1.00
dtype: float64
```
DataFrame是二维的表格型数据结构,可以看作是一个Series的容器,它的行和列可以分别拥有不同的标签。DataFrame在数据处理和分析中应用非常广泛。下面创建DataFrame的示例代码:
```python
# 创建一个DataFrame
data = {
'Country': ['Belgium', 'India', 'Brazil'],
'Capital': ['Brussels', 'New Delhi', 'Brasília'],
'Population': [11_190_846, 1_380_004_385, 212_559_417]
}
df = pd.DataFrame(data, index=['BR', 'IN', 'BE'])
print(df)
```
输出结果将如下所示:
```
Country Capital Population
BR Brazil Brasília 212559417
IN India New Delhi 1380004385
BE Belgium Brussels 11190846
```
在上述代码中,我们首先导入了pandas库,并创建了一个包含国家、首都和人口信息的DataFrame。我们使用了一个字典来创建DataFrame,其中的键是列名。DataFrame的每列都具有相同的数据类型,而行索引(默认为整数序列)则可以通过`index`参数来自定义。
### 3.1.2 数据清洗常用方法
数据清洗是数据预处理的重要环节,其中处理缺失值、重复记录和不一致的数据是常见的数据清洗任务。
#### 处理缺失值
在数据分析过程中,缺失值是经常遇到的问题。Pandas提供了多种处理缺失值的方法,例如`dropna()`, `fillna()`, `interpolate()`等。下面举个例子说明如何使用`dropna()`方法:
```python
# 生成含有缺失值的DataFrame
df = pd.DataFrame([[1, 2, np.nan], [1, np.nan, np.nan], [np.nan, np.nan, np.nan]], columns=list('ABC'))
print(df)
```
输出结果将如下所示:
```
A B C
0 1.0 2.0 NaN
1 1.0 NaN NaN
2 NaN NaN NaN
```
假设我们想删除任何含有NaN值的行,可以使用`dropna()`方法:
```python
# 删除含有缺失值的行
df_cleaned = df.dropna()
print(df_cleaned)
```
输出结果将如下所示:
```
Empty DataFrame
Columns: [A, B, C]
Index: []
```
上例中我们删除了含有NaN值的所有行,结果得到一个空的DataFrame。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面涵盖 Python 编程规范和代码风格,旨在帮助开发者提升代码质量和开发效率。专栏内容包括:
* 代码重构策略,让代码更易读、可维护
* 编码规范详解,统一团队代码风格
* 代码审查要点,确保代码质量
* 异常处理技巧,优雅解决运行时错误
* 内存管理精要,避免内存泄漏
* 函数式编程风格,提高代码效率和清晰度
* Python 在 Web 开发中的应用,框架选择和项目架构秘籍
* Python 与数据库交互,ORM 使用技巧和性能优化
* 数据可视化技巧,用图表讲好数据故事
* 网络编程技术,构建高效稳定的网络应用
* API 设计原则,创建清晰易用的接口
* 装饰器深入解析,揭秘函数增强背后的原理
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ROST软件数据可视化技巧:让你的分析结果更加直观动人
:max_bytes(150000):strip_icc()/ScreenShot2019-10-28at1.25.36PM-ab811841a30d4ee5abb2ff63fd001a3b.jpg)
参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
RTCM 3.3协议深度剖析:如何构建秒级精准定位系统

参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议简介及其在精准定位中的作用
RTCM (Radio Technical Co
提升航空数据传输效率:AFDX网络数据流管理技巧
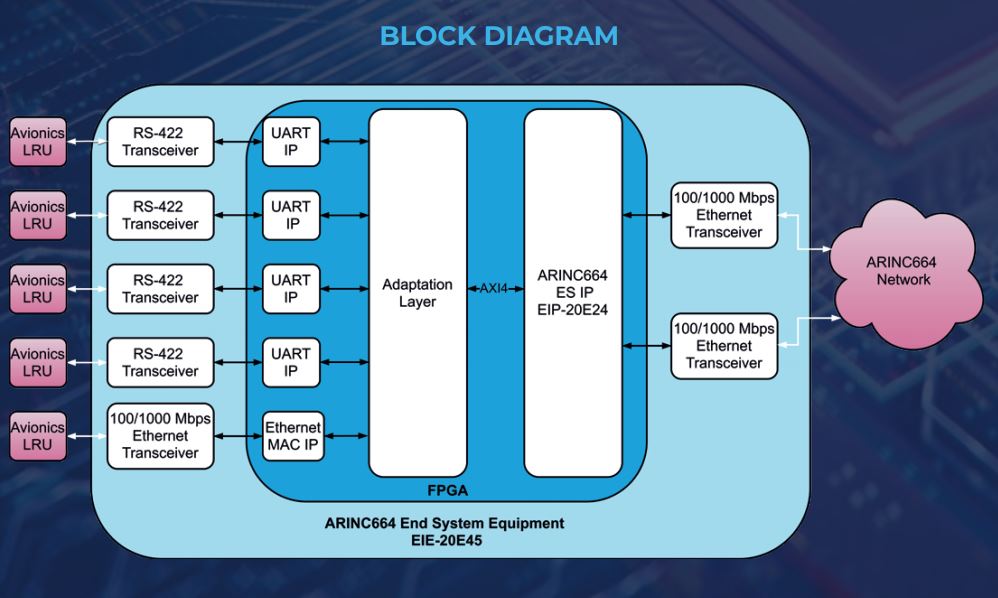
参考资源链接:[AFDX协议/ARINC664中文详解:飞机数据网络](https://wenku.csdn.net/doc/66azonqm6a?spm=1055.2635.3001.10343)
# 1. AFDX网络技术概述
## 1.1 AFDX网络技术的起源与应用背景
AFDX (Avionics Full-Duplex Switched Ethernet) 网络技术,是专为航空电子通信设计
软件开发者必读:与MIPI CSI-2对话的驱动开发策略
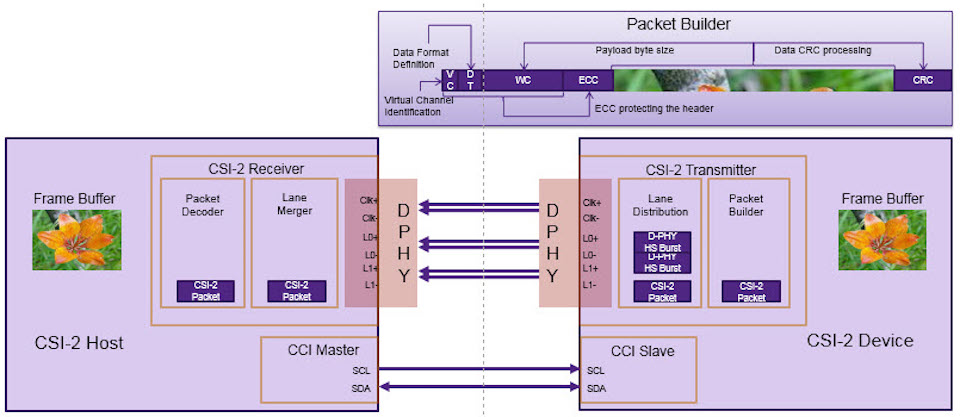
参考资源链接:[mipi-CSI-2-标准规格书.pdf](https://wenku.csdn.net/doc/64701608d12cbe7ec3f6856a?spm=1055.2635.3001.10343)
# 1. MIPI CSI-2协议概述
在当今数字化和移动化的世界里,移动设备图像性能的提升是用户体验的关键部分。为
【PCIe接口新革命】:5.40a版本数据手册揭秘,加速硬件兼容性分析与系统集成
参考资源链接:[2019 Synopsys PCIe Endpoint Databook v5.40a:设计指南与版权须知](https://wenku.csdn.net/doc/3rfmuard3w?spm=1055.2635.3001.10343)
# 1. PCIe接口技术概述
PCIe( Peripheral Component Interconnect Express)是一种高速串行计算机扩展总线标准,被广泛应用于计算机内部连接高速组件。它以点对点连接的方式,能够提供比传统PCI(Peripheral Component Interconnect)总线更高的数据传输率。PCIe的进
ZMODEM协议的高级特性:流控制与错误校正机制的精妙之处

参考资源链接:[ZMODEM传输协议深度解析](https://wenku.csdn.net/doc/647162cdd12cbe7ec3ff9be7?spm=1055.2635.3001.10343)
# 1. ZMODEM协议简介
## 1.1 什么是ZMODEM协议
ZMODEM是一种在串行通信中广泛使用的文件传输协议,它支持二进制数据传输,并可以对数据进行分块处理,确保文件完整无误地传输到目标系统。与早期的XMODEM和YMODEM协
IS903优盘通信协议揭秘:USB通信流程的全面解读

参考资源链接:[银灿IS903优盘完整的原理图](https://wenku.csdn.net/doc/6412b558be7fbd1778d42d25?spm=1055.2635.3001.10343)
# 1. USB通信协议概述
USB(通用串行总线)通信协议自从1996年首次推出以来,已经成为个人计算机和其他电子设备中最普遍的接口技术之一。该章节将概述USB通信协议的基础知识,为后续章节深入探讨USB的硬件结构、信号传输和通信流程等主题打
【功能拓展】创维E900 4K机顶盒应用管理:轻松安装与管理指南
参考资源链接:[创维E900 4K机顶盒快速配置指南](https://wenku.csdn.net/doc/645ee5ad543f844488898b04?spm=1055.2635.3001.10343)
# 1. 创维E900 4K机顶盒概述
在本章中,我们将揭开创维E900 4K机顶盒的神秘面纱,带领读者了解这一强大的多媒体设备的基本信息。我们将从其设计理念讲起,探索它如何为家庭娱乐带来高清画质和智能功能。本章节将为读者提供一个全面的概览,包括硬件配置、操作系统以及它在市场中的定位,为后续章节中关于设置、应用使用和维护等更深入的讨论打下坚实的基础。
创维E900 4K机顶盒采用先
【cx_Oracle数据库管理】:全面覆盖连接、事务、性能与安全性

参考资源链接:[cx_Oracle使用手册](https://wenku.csdn.net/doc/6476de87543f84448808af0d?spm=1055.2635.3001.10343)
# 1. cx_Oracle数据库基础介绍
cx_Oracle 是一个
【深度学习的交通预测力量】:构建上海轨道交通2030的智能预测模型

参考资源链接:[上海轨道交通规划图2030版-高清](https://wenku.csdn.net/doc/647ff0fc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )