Python代码雨的终结者:5步解决性能瓶颈,提升代码效率
发布时间: 2024-06-19 03:55:19 阅读量: 99 订阅数: 32 

java计算器源码.zip
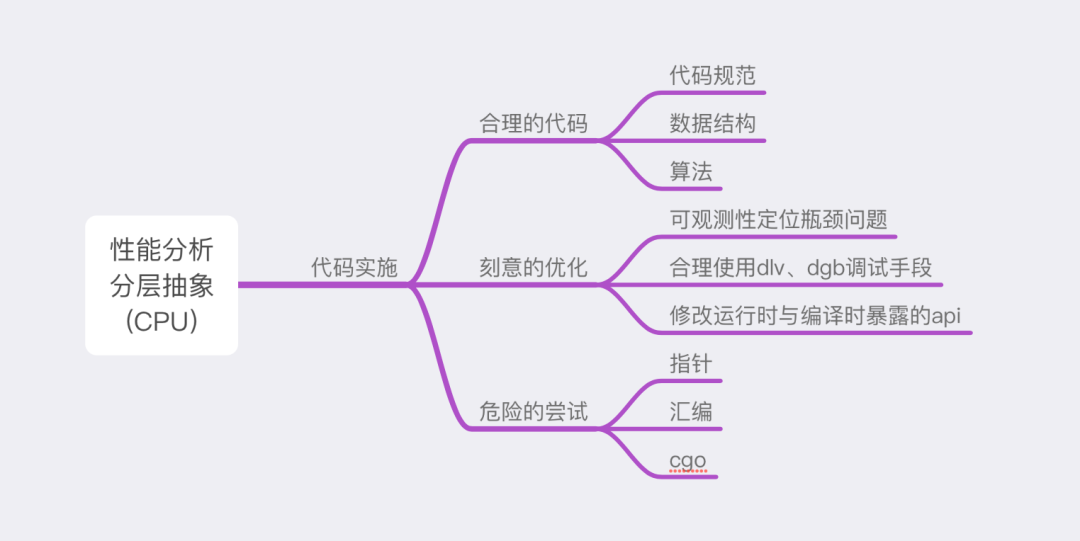
# 1. Python代码性能瓶颈概述**
Python是一种解释型语言,其性能通常不如编译型语言。Python代码性能瓶颈可能源于多种因素,包括:
- **算法复杂度:**算法的复杂度会影响代码执行时间。高复杂度的算法,如O(n^2)或O(2^n),会导致代码性能下降。
- **数据结构选择:**选择不当的数据结构会降低代码效率。例如,使用列表而不是集合进行快速查找操作。
- **内存管理:**Python的垃圾回收机制可能会导致性能问题。频繁的垃圾回收操作会中断代码执行。
# 2. Python代码性能分析与优化**
**2.1 代码剖析与性能瓶颈定位**
Python代码的性能瓶颈往往隐藏在复杂或低效的算法、数据结构或内存管理实践中。代码剖析工具可以帮助识别这些瓶颈,并提供有关程序执行时间和资源消耗的详细报告。
**代码剖析工具**
* **cProfile:** 内置的Python模块,用于分析函数调用和执行时间。
* **line_profiler:** 第三方库,提供按行分析,显示每行代码的执行次数和时间。
* **memory_profiler:** 第三方库,用于分析内存使用情况,并识别内存泄漏。
**使用cProfile剖析代码**
```python
import cProfile
def my_function():
# 你的代码
if __name__ == "__main__":
cProfile.run("my_function()")
```
**输出示例:**
```
3 function calls in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 main.py:1(my_function)
1 0.000 0.000 0.000 0.000 {built-in method builtins.exec}
```
**分析输出:**
* **ncalls:** 函数调用的次数。
* **tottime:** 函数执行的总时间(以秒为单位)。
* **percall:** 每个函数调用的平均时间。
* **cumtime:** 函数及其所有子调用的累积时间。
* **percall:** 每个函数调用的累积平均时间。
**2.2 数据结构和算法选择优化**
数据结构和算法的选择对Python代码的性能有重大影响。适当的数据结构可以提高查找、插入和删除操作的效率,而有效的算法可以减少时间和空间复杂度。
**常见数据结构**
* **列表:** 可变长度的元素集合,支持快速插入和删除。
* **元组:** 不可变长度的元素集合,比列表更有效率,但不能修改。
* **字典:** 键值对集合,提供快速查找和插入。
* **集合:** 无序的元素集合,支持快速成员关系测试和删除。
**算法优化**
* **二分查找:** 在有序列表中快速查找元素。
* **哈希表:** 使用哈希函数将键映射到值,实现快速查找。
* **动态规划:** 将问题分解成较小的子问题,避免重复计算。
* **贪心算法:** 在每一步中做出局部最优选择,以达到全局最优。
**2.3 内存管理和垃圾回收优化**
Python使用引用计数进行内存管理,当对象的引用计数降为0时,它将被垃圾回收器回收。不当的内存管理会导致内存泄漏,从而降低性能。
**内存管理技巧**
* **使用weakref:** 允许对象在不再被使用时被垃圾回收。
* **使用上下文管理器:** 确保在使用后释放资源,例如文件和数据库连接。
* **避免循环引用:** 当两个或多个对象相互引用时,会导致内存泄漏。
**垃圾回收优化**
* **调整垃圾回收器:** 使用`gc.set_threshold()`调整垃圾回收器的触发阈值。
* **使用内存池:** 预分配对象并将其存储在池中,以减少垃圾回收频率。
* **使用第三方垃圾回收器:** 如PyPy或Cython,提供更有效的垃圾回收机制。
**2.4 并发和多线程优化**
Python支持并发和多线程编程,可以提高I/O密集型任务的性能。但是,不当的并发和多线程使用会导致竞争条件和死锁。
**并发编程**
* **协程:** 允许在不使用多线程的情况下并发执行代码。
* **异步I/O:** 使用非阻塞I/O操作,提高I/O密集型任务的性能。
**多线程编程**
* **线程:** 独立执行的代码单元,可以并行执行。
* **锁:** 用于同步对共享资源的访问,防止竞争条件。
* **队列:** 用于在线程之间安全地传递数据。
# 3. Python代码性能提升实践
### 3.1 使用Cython加速代码执行
Cython是一种编译器,它将Python代码翻译成C代码。与纯Python代码相比,C代码的执行速度要快得多。Cython通过以下方式提高代码性能:
- **类型化变量:** Cython允许对变量进行类型化,这可以提高代码的执行速度,因为编译器可以对类型化的变量进行更有效的优化。
- **静态类型检查:** Cython在编译时进行静态类型检查,这可以发现类型错误并防止它们在运行时发生。
- **内联函数:** Cython可以将函数内联到调用它们的代码中,这可以减少函数调用的开销。
**代码块:**
```cython
def fibonacci(n):
cdef int a = 0
cdef int b = 1
for i in range(n):
a, b = b, a + b
return a
```
**逻辑分析:**
此代码块使用Cython编译器将Python代码翻译成C代码。它使用类型化的变量(`cdef int a`和`cdef int b`)和静态类型检查来提高代码的执行速度。
**参数说明:**
- `n`:要计算的斐波那契数的索引。
### 3.2 使用Numba进行JIT编译
Numba是一种JIT(即时编译器)编译器,它将Python代码编译成机器代码。与Cython类似,Numba通过以下方式提高代码性能:
- **JIT编译:** Numba在运行时编译Python代码,这可以根据特定的硬件和输入数据进行优化。
- **类型推断:** Numba可以推断变量的类型,这可以提高代码的执行速度。
- **并行执行:** Numba支持并行执行,这可以利用多核处理器来提高代码的性能。
**代码块:**
```python
import numba
@numba.jit
def fibonacci(n):
a = 0
b = 1
for i in range(n):
a, b = b, a + b
return a
```
**逻辑分析:**
此代码块使用Numba JIT编译器将Python代码编译成机器代码。它使用类型推断和并行执行来提高代码的执行速度。
**参数说明:**
- `n`:要计算的斐波那契数的索引。
### 3.3 使用多处理和多线程提高并发性
多处理和多线程是提高Python代码并发性的两种技术。
- **多处理:** 多处理使用多个进程来并行执行代码。每个进程都有自己的内存空间,这可以防止共享内存引起的竞争条件。
- **多线程:** 多线程使用多个线程来并行执行代码。每个线程共享相同的内存空间,这可以提高代码的性能,但也会增加竞争条件的风险。
**代码块:**
**多处理:**
```python
import multiprocessing
def fibonacci(n):
a = 0
b = 1
for i in range(n):
a, b = b, a + b
return a
if __name__ == '__main__':
pool = multiprocessing.Pool(processes=4)
results = pool.map(fibonacci, range(10))
print(results)
```
**多线程:**
```python
import threading
def fibonacci(n):
a = 0
b = 1
for i in range(n):
a, b = b, a + b
return a
if __name__ == '__main__':
threads = []
for i in range(10):
thread = threading.Thread(target=fibonacci, args=(i,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
```
**逻辑分析:**
这些代码块演示了如何使用多处理和多线程来提高Python代码的并发性。多处理代码使用多个进程来并行执行斐波那契计算,而多线程代码使用多个线程来执行相同的任务。
**参数说明:**
- `n`:要计算的斐波那契数的索引。
### 3.4 优化输入/输出操作
输入/输出操作可能是Python代码性能瓶颈的来源。以下是一些优化输入/输出操作的技巧:
- **使用二进制文件:** 二进制文件比文本文件更快,因为它们不需要解析文本格式。
- **使用缓冲:** 缓冲可以减少输入/输出操作的数量,从而提高性能。
- **使用内存映射文件:** 内存映射文件允许程序将文件直接映射到内存中,从而避免了文件系统调用。
**代码块:**
```python
import mmap
with open('large_file.txt', 'r') as f:
mm = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
data = mm.read()
```
**逻辑分析:**
此代码块使用内存映射文件来优化对大文件的读取操作。它将文件映射到内存中,从而避免了文件系统调用,从而提高了性能。
**参数说明:**
- `large_file.txt`:要读取的大文件。
# 4. Python代码性能监控与调优
### 4.1 使用性能分析工具进行监控
为了有效地监控Python代码的性能,可以使用各种性能分析工具。这些工具可以帮助识别性能瓶颈,分析代码执行时间,并生成可视化报告以帮助理解代码的行为。
常见的性能分析工具包括:
- **cProfile:**一个内置的Python模块,用于分析代码的执行时间和调用次数。
- **line_profiler:**另一个内置的Python模块,用于分析代码的执行时间和行号。
- **pyinstrument:**一个第三方库,提供更高级的性能分析功能,包括调用图和内存分析。
- **py-spy:**一个交互式性能分析工具,允许用户实时监视代码执行。
**代码块 4.1:使用cProfile进行性能分析**
```python
import cProfile
def fib(n):
if n < 2:
return n
else:
return fib(n-1) + fib(n-2)
cProfile.run('fib(30)')
```
**逻辑分析:**
此代码块使用cProfile模块分析fib函数的性能。fib函数计算斐波那契数列的第n项。cProfile.run()函数运行fib(30)并生成一个性能分析报告。
### 4.2 性能指标的收集和分析
在监控Python代码的性能时,收集和分析以下关键性能指标非常重要:
- **执行时间:**代码执行所需的时间,通常以秒或毫秒为单位。
- **内存使用:**代码执行期间使用的内存量,通常以字节或千字节为单位。
- **CPU利用率:**代码执行期间使用的CPU资源量,通常以百分比表示。
- **I/O操作:**代码执行期间执行的I/O操作的数量和类型。
**表格 4.1:性能指标示例**
| 指标 | 描述 |
|---|---|
| 执行时间 | 代码执行所需的时间 |
| 内存使用 | 代码执行期间使用的内存量 |
| CPU利用率 | 代码执行期间使用的CPU资源量 |
| I/O操作 | 代码执行期间执行的I/O操作的数量和类型 |
### 4.3 性能调优策略和最佳实践
一旦识别了性能瓶颈,就可以实施各种策略和最佳实践来调优Python代码的性能:
- **优化数据结构和算法:**选择适合特定任务的合适数据结构和算法可以显著提高性能。
- **减少内存使用:**通过使用内存管理技术,例如引用计数和垃圾回收,可以减少内存使用并提高性能。
- **优化并发和多线程:**利用并发和多线程可以提高代码在多核系统上的性能。
- **优化I/O操作:**通过使用缓冲、缓存和异步I/O,可以优化I/O操作并提高性能。
**Mermaid格式流程图 4.1:Python代码性能调优流程**
```mermaid
graph LR
subgraph 性能监控
A[使用性能分析工具] --> B[收集性能指标]
end
subgraph 性能调优
C[优化数据结构和算法]
D[减少内存使用]
E[优化并发和多线程]
F[优化I/O操作]
end
B --> C
B --> D
B --> E
B --> F
```
# 5. Python代码性能优化案例研究
### 5.1 数据科学算法性能优化
在数据科学领域,算法的性能至关重要,因为它直接影响到数据处理和分析的效率。以下是一些优化数据科学算法性能的案例:
- **使用NumPy和SciPy进行矢量化计算:**NumPy和SciPy提供了一系列高效的矢量化函数,可以显著提高数值计算的性能。通过使用这些函数,可以避免使用for循环,从而减少内存开销和提高执行速度。
```python
# 使用 NumPy 的矢量化函数进行数组相加
import numpy as np
a = np.array([1, 2, 3, 4, 5])
b = np.array([6, 7, 8, 9, 10])
# 使用 for 循环进行相加
sum = 0
for i in range(len(a)):
sum += a[i] + b[i]
# 使用 NumPy 的矢量化函数进行相加
sum = np.sum(a + b)
```
- **利用并行化技术:**并行化技术允许算法同时在多个处理器上运行,从而提高计算速度。可以使用多处理或多线程等技术来实现并行化。
```python
# 使用多处理进行并行化
import multiprocessing
def square(n):
return n * n
# 创建一个进程池
pool = multiprocessing.Pool(4)
# 使用 map() 函数并行化计算
result = pool.map(square, range(10))
```
- **选择合适的算法:**不同的算法具有不同的时间复杂度和空间复杂度。对于大型数据集,选择时间复杂度较低或空间复杂度较低的算法至关重要。
```python
# 选择时间复杂度较低的算法
def linear_search(arr, target):
for i in range(len(arr)):
if arr[i] == target:
return i
return -1
def binary_search(arr, target):
low = 0
high = len(arr) - 1
while low <= high:
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1
```
### 5.2 Web应用程序性能优化
Web应用程序的性能直接影响用户体验和网站的转化率。以下是一些优化Web应用程序性能的案例:
- **使用缓存机制:**缓存机制可以将频繁访问的数据存储在内存中,从而减少数据库查询的次数,提高响应速度。
```python
# 使用 Flask 框架中的缓存机制
from flask import Flask, render_template, cache
app = Flask(__name__)
@app.route('/')
@cache.cached(timeout=300)
def home():
# 从数据库中获取数据
data = get_data_from_db()
# 渲染模板
return render_template('home.html', data=data)
```
- **优化数据库查询:**优化数据库查询可以减少数据库的负载,提高响应速度。可以使用索引、适当的查询语句和批量处理等技术来优化查询。
```python
# 使用 SQLAlchemy 优化数据库查询
from sqlalchemy import create_engine, MetaData, Table
engine = create_engine('sqlite:///database.sqlite')
metadata = MetaData()
users = Table('users', metadata, autoload_with=engine)
# 使用索引优化查询
stmt = users.select().where(users.c.name.like('%John%')).order_by(users.c.name)
```
- **使用CDN加速静态资源:**CDN(内容分发网络)可以将静态资源(如图像、CSS和JavaScript文件)缓存到全球各地的服务器上,从而减少延迟并提高加载速度。
```python
# 使用 Flask-CDN 扩展启用 CDN
from flask_cdn import CDN
cdn = CDN(app)
cdn.config['AWS_S3_BUCKET'] = 'my-bucket'
cdn.config['AWS_ACCESS_KEY_ID'] = 'my-access-key-id'
cdn.config['AWS_SECRET_ACCESS_KEY'] = 'my-secret-access-key'
```
### 5.3 机器学习模型训练性能优化
机器学习模型的训练过程通常需要大量的计算资源和时间。以下是一些优化机器学习模型训练性能的案例:
- **使用GPU加速训练:**GPU(图形处理单元)具有并行处理能力,可以显著提高机器学习模型训练的速度。
```python
# 使用 TensorFlow-GPU 进行训练
import tensorflow as tf
# 创建一个 GPU 设备
device = tf.config.list_physical_devices('GPU')[0]
tf.config.experimental.set_memory_growth(device, True)
# 创建一个模型
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
```
- **使用分布式训练:**分布式训练允许模型在多个机器上并行训练,从而减少训练时间。
```python
# 使用 Horovod 进行分布式训练
import horovod.tensorflow as hvd
# 初始化 Horovod
hvd.init()
# 创建一个模型
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 编译模型
optimizer = tf.keras.optimizers.Adam(learning_rate=hvd.local_size())
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
```
- **优化超参数:**超参数是机器学习模型训练过程中的可调参数,如学习率、批量大小和正则化参数。优化超参数可以提高模型的性能。
```python
# 使用 Optuna 进行超参数优化
import optuna
def objective(trial):
# 设置超参数
learning_rate = trial.suggest_float('learning_rate', 1e-5, 1e-1)
batch_size = trial.suggest_int('batch_size', 16, 128)
dropout_rate = trial.suggest_float('dropout_rate', 0.0, 0.5)
# 创建一个模型
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dropout(dropout_rate),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=batch_size)
# 返回验证集上的准确率
return model.evaluate(X_val, y_val)[1]
# 创建一个研究
study = optuna.create_study(direction='maximize')
# 优化超参数
study.optimize(objective, n_trials=100)
```
# 6. Python代码性能优化总结与展望
通过对Python代码性能优化的深入探讨,我们总结了以下关键要点:
- **性能瓶颈识别和定位:**使用代码剖析工具和性能分析工具可以有效识别性能瓶颈,从而有针对性地进行优化。
- **数据结构和算法选择:**选择合适的算法和数据结构对于优化Python代码性能至关重要,例如使用哈希表或二叉树来提高查找效率。
- **内存管理和垃圾回收:**优化内存管理和垃圾回收可以减少内存开销,提高代码执行效率。
- **并发和多线程:**利用多处理和多线程可以提高Python代码的并发性,并行执行任务以提升性能。
- **性能监控和调优:**使用性能分析工具进行监控,并结合性能指标分析和调优策略,可以持续优化Python代码性能。
**展望**
随着Python在各种领域的广泛应用,对性能优化的需求将不断增长。未来Python代码性能优化将重点关注以下几个方面:
- **人工智能和机器学习:**优化人工智能和机器学习算法的性能,以满足实时处理和训练大型数据集的需求。
- **云计算和分布式系统:**优化Python代码在云计算和分布式系统中的性能,以充分利用分布式计算资源。
- **低代码和无代码开发:**探索低代码和无代码开发平台与Python代码性能优化之间的集成,降低性能优化门槛。
- **自动化和持续集成:**开发自动化和持续集成工具,以简化性能优化流程,确保代码的持续高性能。
通过持续的研究和创新,Python代码性能优化将不断取得突破,为各种应用领域提供更强大的性能支持。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Python代码雨(性能瓶颈)的成因和解决方案。专栏文章涵盖了10个优化秘诀、5步解决性能瓶颈、案例分析和解决方案、10个实用技巧、快速定位和解决问题、从设计到测试的预防措施、行业最佳实践、与内存管理和并发编程的关联性、与数据库交互和Web开发的优化策略、与云计算和人工智能的计算密集性优化、与可扩展性和可维护性的设计和实现,以及编写有效测试用例以防止代码雨发生。通过遵循这些指南,Python开发者可以显著提升代码效率,避免性能瓶颈,打造无雨代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ROS运动仿真实用指南】:机械臂操作模拟的关键步骤
# 摘要
随着机器人技术的快速发展,机械臂仿真技术在自动化领域扮演了至关重要的角色。本文首先介绍了ROS(Robot Operating System)运动仿真基础,强调了机械臂仿真前的准备工作,包括环境配置、模型导入、仿真工具集成等。接着,文章深入探讨了机械臂基本运动的编程实现方法,包括ROS话题、服务和动作协议的应用。第三部分着重于机械臂感知与环境交互能力的构建,包括传感器集成、物体识别、环境建模和避障检测。文章最
【模型泛化秘籍】:如何用ProtoPNet的可解释性助力深度学习模型避免过度拟合

# 摘要
深度学习模型在泛化能力和解释性方面面临着显著挑战。本文首先探讨了这些挑战及其对模型性能的影响,随后深入分析了ProtoPNet模型的设计原理和构建过程,重点讨论了其原型层的工作机制和可解释性。文章接着提出了避免过度拟合的策略,并通过实验验证了 ProtoPNet 在特定问题中的泛化能力。最后,文中对ProtoPNet模型在不同领域的
【MPU-9250数据采集程序】:从零开始,手把手教你编写
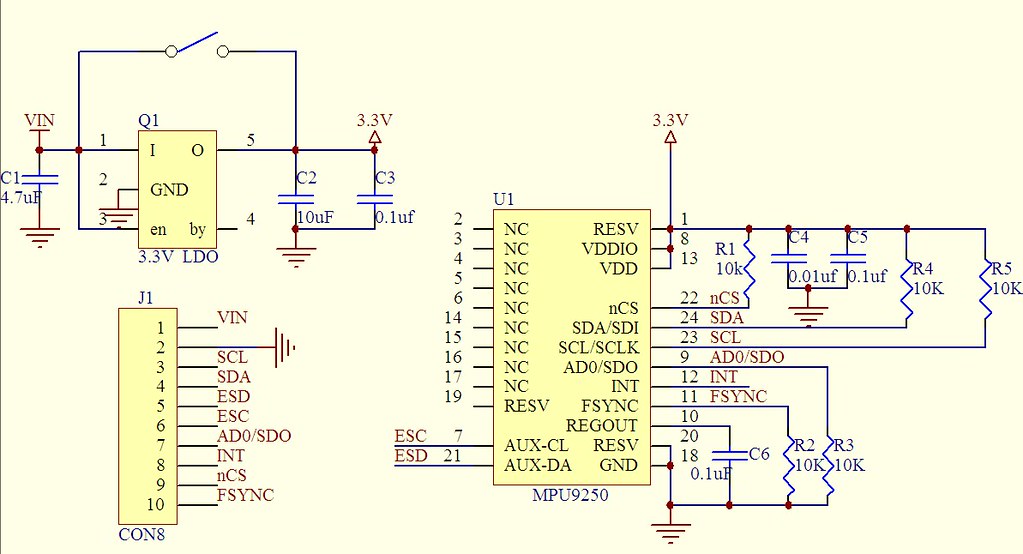
# 摘要
本文旨在全面介绍MPU-9250传感器的工作原理、硬件连接、初始化流程、数据采集理论基础以及编程实践。首先,概述了MPU-9250传感器的功能和结构,并介绍了硬件连接和初始化过程中的关键步骤。随后,详细讨论了数据采集的基本概念、处理技术以及编程接口,为实现精确的数据捕获和分析提供了理论基础。在实践案例与分析部分,通过采集三轴加速度、陀螺仪和磁力计的数据,展示了MPU-9250的实际应用,并
【MAC用户远程连接MySQL全攻略】:一文搞定远程操作
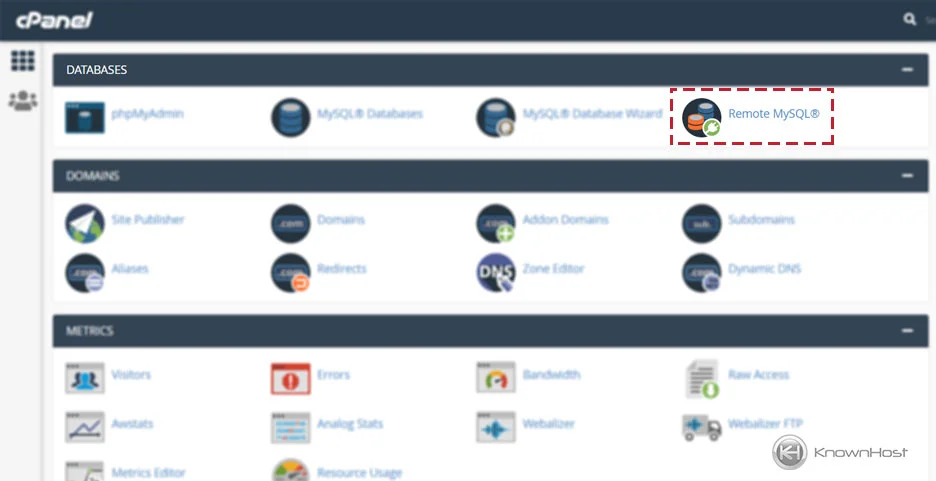
# 摘要
随着信息技术的快速发展,远程连接数据库变得尤为重要,特别是在数据管理和维护方面。本文首先探讨了远程连接MySQL的必要性和准备工作,随后深入到MySQL的配置与安全设置,包括服务器配置、用户权限管理以及远程连接的安全加固。在介绍了MAC端远程连接的软件工具选择后,文章进一步提供了实战操作指导,涵盖了环境检查、操作示例及问题排查
VisionPro监控工具使用手册:实时网络状态监控与实践

# 摘要
随着网络技术的快速发展,网络状态监控变得越来越重要,它能够帮助系统管理员及时发现并处理网络异常,优化网络性能。本文介绍了VisionPro监控工具,从网络监控的基础理论、使用技巧到实践应用进行了全面阐述。文中详细分析了网络监控的重要性及其对系统性能的影响,并探讨了网络流量分析、数据包捕获等关键监控技术原理。同时,本文分享了VisionPro监控工具的安装、配置、使
Matlab专家视角:数字调制系统的完整搭建与案例分析
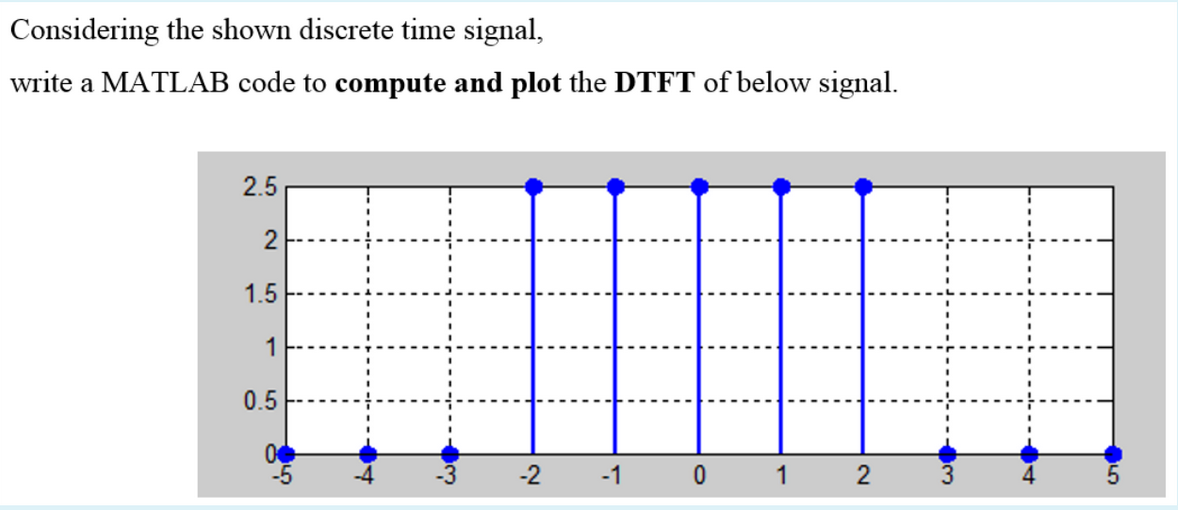
# 摘要
本论文全面探讨了数字调制系统的基本理论、实践应用以及性能分析。首先介绍了数字调制的定义、分类、理论基础和系统组成,随后通过Matlab环境下的调制解调算法实践,展示了调制与解调的实现及其仿真分析。第三章通过模拟分析了不同信号调制过程和噪声对传输信号的影响。在高级数字调制技术章节中,介绍了OFDM和MIMO技术,并评估了其性能。最后一章通过案例研究探讨了数
信号完整性分析:FPGA设计中的PCIE接口优化要点
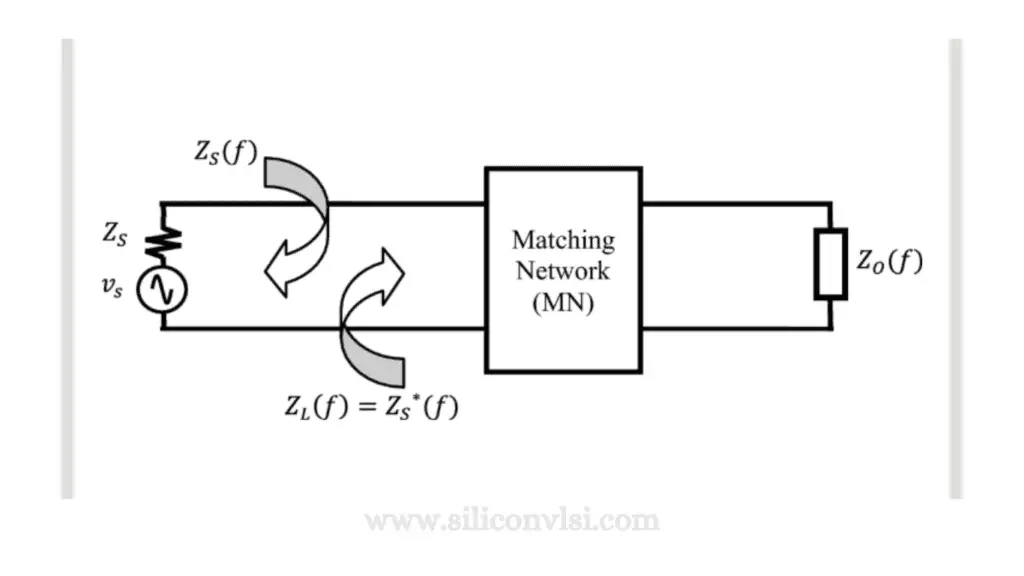
# 摘要
信号完整性是高性能FPGA设计的关键因素,尤其在PCIE接口的应用中尤为重要。本文首先介绍了信号完整性的基础概念,并概述了FPGA及其在高速数据通信中的作用。随后,深入分析了PCIE接口技术标准以及它在FPGA设计中的作用,强调了信号完整性对FPGA性能的影响。第三章详细探讨了信号完整性基本理论,包括反射、串扰和同步切换噪声等,并讨论了信号完整性参数:阻抗、
【模拟与实验对比】:板坯连铸热过程的精准分析技术

# 摘要
本文综合分析了板坯连铸热过程的基础理论、模拟技术应用、实验方法的重要性以及模拟与实验数据对比分析,并展望了连铸热过程精准分析技术的挑战与发展。通过深入探讨理论、模拟与实验技术的结合,揭示了它们在连铸热过程精准控制中的作用和优化路径。同时,文章也指出了当前技术面临的主要挑战,并对未来技术发展趋势提出了建设性的展望和建议。
# 关键字
板坯连铸;热过程分析;模拟技术;实验方法;数据对比;精准分析技术
参考资源链接
通讯录备份系统云迁移指南:从本地到云服务的平滑过渡

# 摘要
本文全面探讨了通讯录备份系统的云迁移过程,涵盖了从云服务基础理论的选择到系统设计、实现,再到迁移实践和性能调优的整个流程。首先介绍了云迁移的概念和云服务模型,包括不同模型间的区别与应用场景,并对云服务提供商进行了市场分析。随后,重点讨论了通讯录备份系统的架构设计、数据库和应用迁移的优化策略。在迁移实践部分,详细阐述了数据迁移执行步骤、应用部署与测试以及灾难
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )