【VAE在PyTorch中的实现】:理论与实践,打造个性化图像生成系统
发布时间: 2024-12-11 18:28:52 阅读量: 6 订阅数: 12 
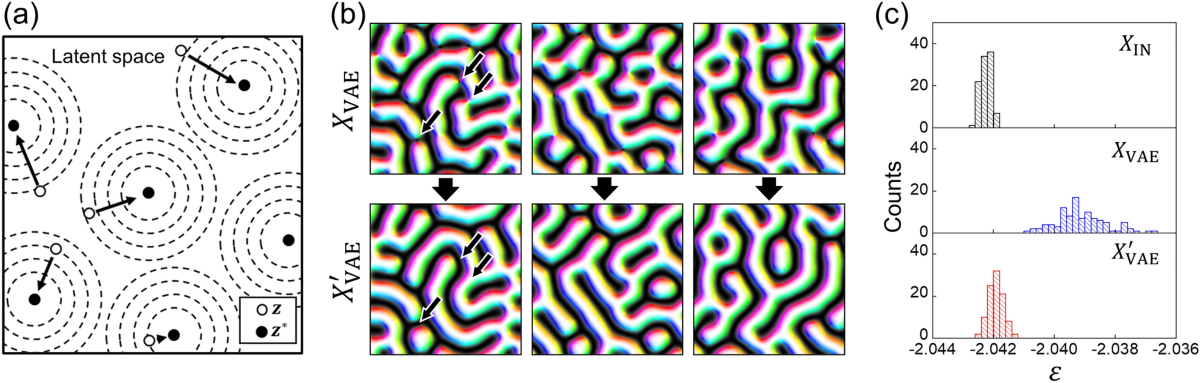
# 1. VAE(变分自编码器)的基础理论
在深度学习的众多模型中,变分自编码器(Variational Autoencoder,简称VAE)已经成为一种重要的生成模型。它结合了自动编码器与概率生成模型的优点,能够学习数据的潜在表示,同时生成高质量的新样本。本章将详细介绍VAE的基本原理和数学基础。
## 1.1 VAE的基本概念
VAE是一种基于变分推断的生成模型,其核心思想是使用一个编码器网络将观测数据映射到潜在空间,然后再通过解码器网络重构出观测数据。这种模型在许多领域如图像生成、文本生成等都显示出了巨大的潜力。
## 1.2 VAE的工作原理
VAE的关键在于它的编码器不是直接映射输入到潜在变量,而是映射到潜在变量的参数,然后通过采样潜在变量来生成观测数据。这种方法使得模型能够捕捉输入数据的多样性,并生成新的、未曾见过的样本。
## 1.3 VAE的优势
与传统的自编码器相比,VAE能够给出潜在空间中样本的分布,这使得它不仅能够进行数据重建,还能进行有效的样本生成。此外,由于引入了概率模型,VAE能够在潜在空间中进行平滑的插值和学习,这对于理解和操作数据表示特别有用。
# 2. PyTorch框架入门
### 2.1 PyTorch简介
#### 2.1.1 PyTorch的历史和特点
PyTorch是由Facebook的人工智能研究团队于2016年推出的开源机器学习库,它主要用于计算机视觉和自然语言处理等应用。PyTorch提供了一个高效的张量计算环境,支持GPU加速,同时具有动态计算图(Dynamic Computational Graphs)特性,这使得研究人员能以更接近Python自然风格的方式快速开发和调试模型。
特点上,PyTorch以其灵活性和易用性著称,尤其是以下几点:
- **动态计算图**:PyTorch构建的计算图是动态的,这意味着图的构建是在运行时完成的,可以实现更复杂和灵活的数据流控制。
- **易用性**:简洁的API设计,使得新手也容易上手。
- **强大的社区支持**:拥有大量的社区贡献和预训练模型,方便开发者学习和使用。
- **良好的性能**:支持多GPU训练,性能优化良好,适合大规模模型训练。
#### 2.1.2 PyTorch的安装和配置
安装PyTorch非常直接,可以访问官方网站获取详细的安装指令,一般有以下几种方式:
- 使用`pip`直接安装:适合大多数用户。
- 使用`conda`安装:适合需要安装预构建二进制包的用户,尤其是GPU版本。
- Docker镜像:适合希望在一个隔离环境中快速运行PyTorch的用户。
以通过`pip`安装CPU版本为例,可以使用以下命令:
```sh
pip install torch torchvision torchaudio
```
对于GPU版本,需要确认你的CUDA版本,并使用以下命令:
```sh
pip install torch torchvision torchaudio -f https://download.pytorch.org/whl/torch_stable.html
```
安装完成后,可以运行以下Python代码检查PyTorch是否安装成功并利用了GPU资源:
```python
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"Is CUDA available: {torch.cuda.is_available()}")
```
### 2.2 PyTorch核心概念
#### 2.2.1 张量(Tensor)和自动微分(autograd)
张量是PyTorch中用于存储数据的基本数据结构,可以看作是一个多维数组。张量的操作和NumPy数组类似,但能够利用GPU进行加速。
```python
import torch
# 创建一个5x3的未初始化的张量
x = torch.empty(5, 3)
print(x)
```
自动微分是深度学习中非常重要的特性,它能够自动计算梯度,减少了手动求导的负担。在PyTorch中,我们可以通过创建一个`requires_grad=True`的张量来启用自动微分。
```python
# 创建一个需要计算梯度的张量
w = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# 定义计算图
y = w[0] * w[0] + w[1] * w[1] + w[2] * w[2]
# 反向传播,计算梯度
y.backward()
print(w.grad) # 打印梯度
```
#### 2.2.2 神经网络模块(nn.Module)和优化器(optim)
`nn.Module`是PyTorch中所有神经网络模块的基类,我们可以通过继承这个类来定义自己的网络结构。PyTorch提供了一个包含各种常见层(如卷积层、全连接层等)的模块库。
```python
import torch.nn as nn
import torch.nn.functional as F
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(3, 5)
self.fc2 = nn.Linear(5, 3)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
net = SimpleNet()
print(net)
```
优化器负责更新网络的权重,常见的优化算法如SGD、Adam等在PyTorch中通过`optim`模块提供。例如:
```python
import torch.optim as optim
optimizer = optim.Adam(net.parameters(), lr=0.001)
```
### 2.3 PyTorch实践基础
#### 2.3.1 模型的构建和训练循环
在PyTorch中,构建模型和训练循环是分开的。首先定义模型,然后通过循环对数据进行前向传播、计算损失、反向传播和参数更新。
```python
# 假设我们有一批数据和对应标签
data = torch.randn(20, 3)
target = torch.randint(0, 3, (20,))
# 设定损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 训练循环
for epoch in range(10): # 进行10个训练周期
optimizer.zero_grad() # 清空梯度
output = net(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
```
#### 2.3.2 数据加载和预处理
PyTorch通过`DataLoader`和`Dataset`类支持高效的数据加载。`Dataset`负责存储数据样本,而`DataLoader`负责批量加载数据并提供迭代接口。
```python
from torch.utils.data import DataLoader, Dataset
# 定义自己的数据集
class MyDataset(Dataset):
def __init__(self, data, target):
self.data = data
self.target = target
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.target[idx]
# 创建数据集和数据加载器
dataset = MyDataset(data, target)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
# 使用DataLoader进行数据迭代
for batch_data, batch_target in dataloader:
# 进行模型训练步骤
pass
```
预处理阶段常常包含对数据进行标准化、转换等操作,以确保数据质量满足模型训练的要求。
在本章节中,我们介绍了PyTorch的基础知识,从安装配置到核心概念,再到实际的模型构建和训练,为后面深入探讨VAE模型的实现打下了坚实的基础。通过本章节的学习,读者应该能够理解PyTorch的基本操作,并能够在自己的项目中应用这些技术。
# 3. VAE模型构建与训练
## 3.1 VAE模型的数学原理
### 3.1.1 概率图模型和变分推断
变分自编码器(VAE)是一种深度生成模型,它利用概率图模型和变分推断的原理来生成新的数据样本。概率图模型使用图结构来表示变量之间的条件依赖关系,它由显式变量(可以直接观测到的变量)和隐式变量(需要通过观测数据推断出的变量)组成。在VAE

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用 PyTorch 进行图像生成的各个方面,从入门基础到高级技巧。它提供了全面的案例和代码实践,涵盖了从构建 StyleGAN 模型到优化面部图像生成等广泛主题。该专栏还比较了 PyTorch 和 TensorFlow 在图像生成中的优势和劣势,并介绍了使用 PyTorch 构建跨平台移动端图像编辑工具的方法。此外,它还探讨了 GPU 和 TPU 等硬件加速技术在提升 PyTorch 图像生成性能中的作用。通过深入浅出的讲解和丰富的示例,本专栏旨在帮助读者掌握 PyTorch 图像生成技术,从初学者到精通者,全面提升技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ZEMAX zpl脚本构建:一步步教你如何打造首个脚本
# 摘要
ZEMAX ZPL脚本是用于光学设计和系统建模的专用语言。本文从基础入门讲起,逐步深入到ZPL脚本的语法和结构,以及变量和控制结构的使用。通过实践操作,本文指导用户如何应用ZPL脚本进行设计优化、系统建模分析以及数据可视化报告的生成。进一步,本文探讨了高级技巧,包括自定义函数、模块化编程、异常处理和脚本性能优化。在案例分析与实战演练章节中,本文通过实际案例展示了脚本的综合应用。最后,本文展望了ZPL脚本的未来技术趋势和社区资源分享的重要性,以期推动光学设计领域的发展。
# 关键字
ZEMAX;ZPL脚本;光学设计;系统建模;自动化脚本;性能优化
参考资源链接:[ZEMAX中ZPL
【Android SQLite并发控制】:多线程下的数据安全解决方案

# 摘要
随着移动应用的发展,SQLite数据库在Android平台上的并发控制成为优化应用性能和稳定性的重要议题。本文首先介绍了SQLite并发控制的基础知识和Android多线程编程的基础,接着深入探讨了SQLite并发控制机制中的事务机制、锁机制以及并发问题的诊断与处理。在实践应用章节中,本文提供了线程安全的数据访问模式,分析了高并发场景下的
模块化设计指南:TC8-WMShare对OPEN Alliance协议栈的影响详解

# 摘要
模块化设计是现代通信协议架构中提升系统可维护性、可扩展性和稳定性的关键技术。本文首先介绍了模块化设计的基本原理及其重要性,随后深入分析了TC8-WMShare协议的起源、架构以及与OPEN Alliance协议栈的关联。接着,本文探讨了模块化设计在TC8-WMShare协议中的具体实现和应用,以及它对OPE
【RT LAB高级特性】:详解如何优化你的仿真模型与系统
# 摘要
本文全面探讨了RT LAB仿真模型的基础知识、优化理论、高级应用、实践应用以及未来发展趋势。首先
【Silvaco TCAD核心解析】:3个步骤带你深入理解器件特性

# 摘要
Silvaco TCAD是半导体和电子领域中广泛使用的器件模拟软件,它能够模拟和分析从材料到器件的各种物理过程。本文介绍了TCAD的基本原理、模拟环境的搭建和配置,以及器件特性分析的方法。特别强调了如何使用TCAD进行高级应用技巧的掌握,以及在工业应用中如何通过TCAD对半导体制造工艺进行优化、新器件开发的支持和可靠性分析。此外,本文还探讨了TCAD未来发展
【开发者个性化设置】:Arduino IDE主题颜色设置的终极攻略

# 摘要
Arduino IDE作为一个广泛使用的集成开发环境,不仅为开发者提供了便利的编程工具,还支持个性化定制以满足不同用户的需求。本文首先概览了Arduino IDE的功能与用户个性化需求,随后深入探讨了主题颜色设置的理论基础、技术原理及个性化定制的方法。文章详细介绍了如何使用主题颜色编辑器进行内置主题的访问、修改和自定义主题的创建。
【S7-1200与MCGS数据交换秘籍】:交互机制全面解读(数字型、推荐词汇、实用型、私密性)
# 摘要
本文深入探讨了S7-1200 PLC与MCGS组态软件之间的数据交换机制。首先介绍S7-1200 PLC和MCGS组态软件的基础知识,接着详细论述数字型数据交换的理论基础和实践操作。本文进一步探讨了深度数据交换中的高级处理技巧、安全性和异常处理方法,并通过实战项目案例来
WinCC变量管理:一步提升效率的批量操作技术

# 摘要
本文全面概述了WinCC变量管理的各个方面,从基本操作到高级技术应用,再到实践案例与扩展应用,最后探讨了未来技术趋势。文章首先介绍了WinCC变量管理的基本概念,详细说明了变量的创建、编辑、批量操作和组织管理。接着,深入探讨了高级技术应用,如动态链接、性能优化和安全性管理。实践案例章节通过真实案例分析,展示了变量管理在工程实践中的应用,以及如何自动化批量操作和解决常见问题。最后,本文展望了WinCC变量管理技术的未来,探讨了新技
Fluent Scheme vs SQL:大数据处理中的关键对比分析

# 摘要
随着大数据技术的快速发展,高效的处理和分析技术变得至关重要。本文首先概述了大数据处理的背景,然后详细分析了Fluent Scheme语言的核心特性和高级特性,包括其数据流处理、嵌入式查询转换和并行处理机制,及其性能优化方法。同时,本文也探讨了SQL语言的基础、在大数据环境中的应用及其性能优化策略。文章进一步对比了Flu
DIP2.0与医疗数据隐私:探讨新标准下的安全与隐私保护
# 摘要
随着数字化医疗的兴起,医疗数据隐私保护变得日益重要。DIP2.0标准旨在提供一种全面的医疗数据隐私保护框架,不仅涉及敏感医疗信息的加密和匿名化,还包括访问控制、身份验证和数据生命周期管理等机制。本文探讨了DIP2.0标准的理论基础、实践应用以及面临的挑战,并分析了匿名化数据在临床研究中的应用和安全处理策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )