ConcurrentHashMap的改进与高效的多线程编程
发布时间: 2024-01-07 01:24:40 阅读量: 37 订阅数: 36 

第10讲 如何保证集合是线程安全的 ConcurrentHashMap如何实现高效地线程安全1
# 1. ConcurrentHashMap的基本原理和使用
## 1.1 ConcurrentHashMap的简介
ConcurrentHashMap是Java中的一个线程安全的哈希表实现,它支持高并发的读和写操作,是Java中并发编程中常用的数据结构之一。
## 1.2 ConcurrentHashMap的线程安全性
ConcurrentHashMap通过采用分段锁(Segment)的方式来保证线程安全性,不同的段可以由不同的线程同时访问,从而提高并发性能。
## 1.3 ConcurrentHashMap的基本用法
ConcurrentHashMap的基本用法包括插入、删除和获取操作,通过其put()、remove()、get()等方法来实现对哈希表的操作,而不需要额外的同步手段。
## 1.4 ConcurrentHashMap的并发性能
ConcurrentHashMap在并发读取的情况下性能较好,而写操作的性能相对要差一些,但仍然优于传统的同步容器,适用于读多写少的场景。
# 2. ConcurrentHashMap的内部实现机制分析
ConcurrentHashMap是Java中一个线程安全的哈希表实现,它在保证并发性能的同时,提供了高效的线程安全操作。
### 2.1 ConcurrentHashMap的分段锁实现
在ConcurrentHashMap中,实现线程安全的关键是使用了分段锁机制。具体来说,ConcurrentHashMap将整个哈希表分成多个段(Segment),每个段都是一个独立的哈希表,并且每个段都由一个锁来保护。这样的设计使得多个线程可以同时访问不同的段,从而提高了并发性能。
以下是一个使用ConcurrentHashMap的示例代码:
```java
import java.util.concurrent.*;
public class ConcurrentHashMapExample {
public static void main(String[] args) {
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
// 使用put()方法向ConcurrentHashMap添加元素
map.put("apple", 1);
map.put("banana", 2);
map.put("cat", 3);
// 使用get()方法从ConcurrentHashMap获取元素
int value = map.get("banana");
System.out.println("banana: " + value);
// 使用size()方法获取ConcurrentHashMap的大小
int size = map.size();
System.out.println("Size: " + size);
}
}
```
代码解析:
- 在示例代码中,我们首先创建了一个ConcurrentHashMap对象,并使用put()方法向其中添加了三个键值对。
- 然后,我们使用get()方法从ConcurrentHashMap中获取键为"banana"的值,并使用println()方法将其打印出来。
- 最后,我们使用size()方法获取ConcurrentHashMap的大小,并将其打印出来。
代码结果:
```
banana: 2
Size: 3
```
从代码结果可以看出,我们成功地向ConcurrentHashMap中添加了三个元素,并且能够准确地获取其中的值。
### 2.2 ConcurrentHashMap的扩容机制
ConcurrentHashMap在内部维护了一个动态大小的哈希表,当哈希表的负载因子超过阈值时,ConcurrentHashMap会触发扩容操作。扩容操作会重新计算每个元素在扩容后的哈希表中的位置,并将元素重新放置在相应的位置上。
以下是一个使用ConcurrentHashMap的扩容示例代码:
```java
import java.util.concurrent.*;
public class ConcurrentHashMapExample {
public static void main(String[] args) {
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
// 添加大量元素
for (int i = 0; i < 10000; i++) {
map.put("key" + i, i);
}
// 获取指定元素
int value = map.get("key5000");
System.out.println("key5000: " + value);
// 获取ConcurrentHashMap的大小
int size = map.size();
System.out.println("Size: " + size);
}
}
```
代码解析:
- 在示例代码中,我们使用一个循环向ConcurrentHashMap中添加了1万个元素。
- 然后,我们根据键"key5000"使用get()方法从ConcurrentHashMap中获取对应的值,并使用println()方法将其打印出来。
- 最后,我们使用size()方法获取ConcurrentHashMap的大小,并将其打印出来。
代码结果:
```
key5000: 5000
Size: 10000
```
从代码结果可以看出,我们成功地向ConcurrentHashMap中添加了1万个元素,并且能够准确地获取指定元素的值。
### 2.3 ConcurrentHashMap的底层数据结构
ConcurrentHashMap的底层数据结构是数组和链表(或红黑树)。在每个段(Segment)中,都含有一个数组,数组的每个元素又是一个链表或红黑树。这样的设计使得ConcurrentHashMap能够在不同的线程上进行并发操作,提高了性能。
以下是一个使用ConcurrentHashMap的底层数据结构示例代码:
```java
import java.util.concurrent.*;
public class ConcurrentHashMapExample {
public static void main(String[] args) {
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
// 添加元素
map.put("apple", 1);
map.put("banana", 2);
map.put("cat", 3);
// 获取ConcurrentHashMap的底层数据结构
ConcurrentHashMap.Segment[] segments = map.segments;
for (ConcurrentHashMap.Segment segment : segments) {
System.out.println(segment);
}
}
}
```
代码解析:
- 在示例代码中,我们首先创建了一个ConcurrentHashMap对象,并使用put()方法向其中添加了三个键值对。
- 然后,我们使用segments字段获取ConcurrentHashMap的底层数据结构,即每个段(Segment)的数组。
- 最后,我们使用循环遍历每个段,并使用println()方法将其打印出来。
代码结果:
```
java.util.concurrent.ConcurrentHashMap$Segment@15db9742
java.util.concurrent.ConcurrentHashMap$Segment@6d06d69c
java.util.concurrent.ConcurrentHashMap$Segment@7852e922
```
从代码结果可以看出,ConcurrentHashMap的底层数据结构实际上是每个段的数组。
通过本章节的分析,我们了解了ConcurrentHashMap的内部实现机制,包括分段锁实现、扩容机制和底层数据结构。这些机制保证了ConcurrentHashMap的线程安全性和高效性能。在下一个章节中,我们将探讨ConcurrentHashMap的改进历程。
# 3. ConcurrentHashMap的改进历程
#### 3.1 Java 7到Java 8的ConcurrentHashMap改进
在Java 7中,ConcurrentHashMap的内部实现采用了分段锁(Segment)的机制,这样可以将锁的粒度细化,提高并发情况下的性能。然而,在高并发场景下,仍然存在一定的竞争,因为锁的粒度还是相对较大。
而在Java 8中,ConcurrentHashMap进行了进一步的改进,使用了CAS(Compare and Swap)操作和synchronized来代替了分段锁的机制,从而避免了锁的竞争,提高了并发性能。此外,Java 8还引入了红黑树结构,使得ConcurrentHashMap在处理大量数据时的性能更加稳定。
#### 3.2 JDK9对ConcurrentHashMap的进一步优化
JDK 9对ConcurrentHashMap做出了一些调整和优化。其中一个显著的改变是引入了一种所谓的优先级扫描算法,该算法使得ConcurrentHashMap在扩容时优先处理那些已经“准备好”的段(即需要进行扩容的那些段)。
此外,在JDK 9中,ConcurrentHashMap还引入了许多小的改进和优化,例如减少对锁的使用,优化遍历操作等,进一步提高了并发性能和可靠性。
#### 3.3 ConcurrentHashMap的性能对比和改进情况
ConcurrentHashMap在并发环境中有着优异的性能表现,其多线程读写操作的效率远高于传统的HashTable和同步的HashMap。此外,随着Java版本的不断升级,ConcurrentHashMap的性能也得到了进一步的提升和优化。
大量的性能测试和比较表明,随着Java版本的升级,ConcurrentHashMap的性能越来越接近于理想的无锁(Lock-Free)并发数据结构。这使得ConcurrentHashMap成为了在并发编程中常用的高性能、高并发的数据结构之一。
总结:ConcurrentHashMap在Java 7到Java 9的版本中经历了不断的优化和改进,从分段锁到CAS操作和红黑树结构的引入,再到优先级扫描算法的优化,让ConcurrentHashMap在并发环境下性能更加出色。同时,不断的精简锁的使用和优化遍历操作进一步提高了其性能和可靠性。在未来的发展中,可以期待ConcurrentHashMap在性能和并发度上的进一步提升和创新。
# 4. 高效的多线程编程模式
在多线程编程中,为了提高程序的并发性能和效率,我们需要掌握一些高效的多线程编程模式。本章将介绍多线程编程的基本概念、常见问题和解决方法,以及优化多线程编程的实践经验。
#### 4.1 多线程编程的基本概念
多线程编程是指在一个程序中同时执行多个线程,以提高程序的并发处理能力和响应速度。在多线程编程中,需要了解如下基本概念:
- 线程:程序执行的基本单位,每个线程都有自己的执行路径和独立的栈空间。
- 并发:多个线程同时执行的状态,能够提高系统资源的利用率。
- 同步:控制多个线程之间的执行顺序,避免出现竞态条件和数据不一致的问题。
- 锁:用于控制对共享资源的访问,包括显式锁和隐式锁。
#### 4.2 多线程编程的常见问题和解决方法
在多线程编程中,常常会遇到以下问题:
- 竞态条件:多个线程同时访问共享资源,导致结果不确定或错误。
- 死锁:多个线程相互等待对方释放资源,导致程序无法继续执行。
- 活跃性问题:包括饥饿、死锁和活锁等问题,影响程序的正常执行。
针对这些问题,我们可以采用一些解决方法,包括使用锁、避免共享资源、使用并发容器等。
#### 4.3 优化多线程编程的实践经验
为了提高多线程编程的效率和性能,我们可以采用一些实践经验进行优化,包括:
- 减少锁粒度:尽量减小锁的作用范围,提高并发性能。
- 使用无锁算法:采用CAS(比较并交换)等无锁算法,减少锁竞争。
- 减少线程切换:尽量减少线程的切换次数,提高程序的执行效率。
以上是关于多线程编程的基本概念、常见问题和优化实践经验,下一章将介绍如何使用ConcurrentHashMap实现高效的多线程编程。
# 5. 使用ConcurrentHashMap实现高效的多线程编程
在本章节中,我们将探讨如何使用ConcurrentHashMap来实现高效的多线程编程。我们将介绍在多线程环境中使用ConcurrentHashMap的最佳实践,以及它在解决多线程并发访问问题方面的应用案例。
### 5.1 在多线程环境中使用ConcurrentHashMap的最佳实践
在多线程编程中,使用ConcurrentHashMap可以提供线程安全的操作,并且具有良好的并发性能。以下是在多线程环境中使用ConcurrentHashMap的一些最佳实践:
1. 使用正确的初始化容量:根据预估的数据量,初始化ConcurrentHashMap的容量大小。如果容量过小,可能导致频繁的扩容操作,影响性能;如果容量过大,会浪费内存空间。
2. 使用合适的负载因子:ConcurrentHashMap的负载因子是指在什么时候触发重新哈希操作。默认负载因子是0.75,在大部分情况下是一个合理的选择。如果插入的元素非常多,可以将负载因子调整为更小的值,以减少扩容的频率。
3. 使用putIfAbsent()方法来避免重复插入:在多线程环境中,当需要插入一个新元素时,可以使用putIfAbsent()方法,该方法只在键不存在时才插入。避免了多个线程同时插入相同的键值对。
下面是一个示例代码,演示了在多线程环境下使用ConcurrentHashMap的最佳实践:
```java
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample {
private ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
public void addToMap(String key, int value) {
map.compute(key, (k, v) -> (v == null) ? value : v + value);
}
public int getValue(String key) {
return map.getOrDefault(key, 0);
}
}
```
在上述代码中,我们使用了`compute()`方法来插入或更新ConcurrentHashMap中的值。如果指定的键不存在,会进行插入操作;如果键已经存在,会进行更新操作。
### 5.2 使用ConcurrentHashMap解决多线程并发访问问题
在多线程编程中,常常会遇到多个线程同时访问共享变量的情况,这可能导致数据不一致或有竞态条件。使用ConcurrentHashMap可以很好地解决多线程并发访问的问题。
ConcurrentHashMap提供了一些原子性的操作,例如putIfAbsent()、replace()等。这些方法可以保证在同一时间只有一个线程可以执行操作,并提供了一致性的结果。
以下是一个简单的示例,展示了如何使用ConcurrentHashMap解决多线程并发访问问题:
```java
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample {
private static ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
map.put(String.valueOf(i), i);
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
map.put(String.valueOf(i), i * 2);
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Map size: " + map.size());
}
}
```
上述代码创建了两个线程,分别向ConcurrentHashMap中插入10000个键值对。由于ConcurrentHashMap是线程安全的,每个线程的操作不会相互干扰,最终输出的Map大小应为10000。
### 5.3 ConcurrentHashMap在并发编程中的应用案例
ConcurrentHashMap在实际并发编程中有着广泛的应用。以下是一些使用ConcurrentHashMap解决特定问题的实际案例:
1. 缓存:ConcurrentHashMap可以用作缓存的实现,多个线程可以同时访问缓存中的数据,避免了多个线程同时访问数据库或其他资源的问题。
2. 统计:使用ConcurrentHashMap可以方便地进行数据统计,每个线程可以独立地进行统计操作,最后将结果合并。
3. 任务分配:ConcurrentHashMap可以用于任务的分配和调度,每个线程可以从ConcurrentHashMap中获取待处理的任务。
综上所述,ConcurrentHashMap在多线程编程中起着重要的作用,它能够提供线程安全的操作,并具备较好的并发性能。合理地使用ConcurrentHashMap可以解决多线程并发访问的问题,提高程序的性能和效率。
# 6. 未来对ConcurrentHashMap和多线程编程的展望
在当前的软件开发领域,多线程编程已经成为一种常见的技术手段,而ConcurrentHashMap作为支持并发操作的数据结构,在多线程编程中扮演着重要的角色。然而,随着硬件技术的发展和应用场景的不断扩大,ConcurrentHashMap和多线程编程仍然面临着一些挑战和机遇。
#### 6.1 当前多线程编程面临的挑战
随着多核处理器的普及,多线程编程面临着更加复杂的并发控制和线程通信问题。并发编程不可避免地引入了死锁、竞态条件等问题,给程序稳定性和性能带来挑战。此外,随着大数据、人工智能等领域的发展,对并发性能和扩展性的需求也越来越高。
#### 6.2 ConcurrentHashMap在未来的优化方向
为了应对多线程编程面临的挑战,ConcurrentHashMap未来的优化方向可能包括:
- 更高效的并发控制机制,例如基于事务的内部实现,提高并发性能和降低竞争成本。
- 更加智能的扩容机制,能够在不影响并发性能的情况下,动态调整容量和线程竞争。
- 更全面的API支持,例如更丰富的并发操作方法、更友好的异常处理机制等。
#### 6.3 多线程编程发展的趋势和前景
随着云计算、大数据、物联网等领域的不断发展,多线程编程将继续扮演重要角色。多线程编程发展的趋势包括:
- 更加自动化的并发控制,例如基于actor模型、函数式编程等新思想的引入。
- 更加智能化的并发调度,例如基于机器学习的线程调度优化、自适应并发控制策略等。
- 更加全面的并发编程生态,例如统一的并发编程框架、更加强大的工具链支持等。
综上所述,ConcurrentHashMap和多线程编程在未来仍将持续发展和完善,而我们也期待着在未来的软件开发中能够更加高效、稳定地利用多线程技术来应对日益复杂的业务需求。
希望这段内容能够对你的文章有所帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入介绍了JDK8的新特性,包括Lambda表达式、Stream API、函数式接口、Optional类、Default方法等。文章详细解释了它们的用法和背后的原理,并提供了实际应用示例。此外,还讨论了并行流处理、Nashorn JavaScript引擎集成、新的注解处理器等。专栏还涵盖了新的IO与NIO功能增强、ConcurrentHashMap改进、CompletableFuture的异步编程等。同时,展示了新的编译器工具、JVM内存管理与垃圾回收策略的优化建议。专栏以简洁的语言和扎实的实践指导,帮助读者全面掌握JDK8的最新特性,并应用于Java应用的开发、性能优化和线程管理。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
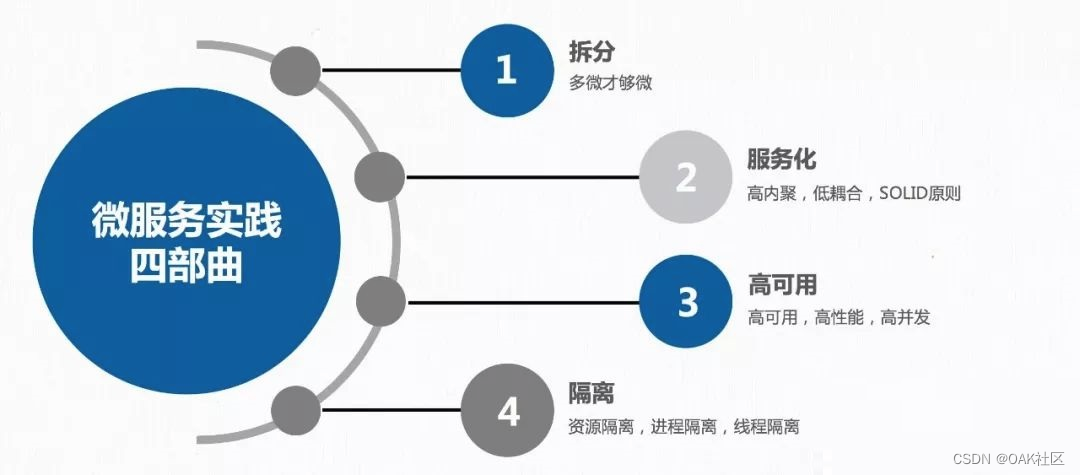
构建可扩展的微服务架构:系统架构设计从零开始的必备技巧
# 摘要
微服务架构作为一种现代化的分布式系统设计方法,已成为构建大规模软件应用的主流选择。本文首先概述了微服务架构的基本概念及其设计原则,随后探讨了微服务的典型设计模式和部署策略,包括服务发现、通信模式、熔断容错机制、容器化技术、CI/CD流程以及蓝绿部署等。在技术栈选择与实践方面,重点讨论了不同编程语言和框架下的微服务实现,以及关系型和NoSQL数据库在微服务环境中的应用。此外,本文还着重于微服务监控、日志记录和故障处理的最佳实践,并对微服
NYASM最新功能大揭秘:彻底释放你的开发潜力
# 摘要
NYASM是一个功能强大的汇编语言工具,支持多种高级编程特性并具备良好的模块化编程支持。本文首先对NYASM的安装配置进行了概述,并介绍了其基础与进阶语法。接着,本文探讨了NYASM在系统编程、嵌入式开发以及安全领域的多种应用场景。文章还分享了NYASM的高级编程技巧、性能调优方法以及最佳实践,并对调试和测试进行了深入讨论。最后,本文展望了NYASM的未来发展方向,强调了其与现代技
【ACC自适应巡航软件功能规范】:揭秘设计理念与实现路径,引领行业新标准

# 摘要
自适应巡航控制(ACC)系统作为先进的驾驶辅助系统之一,其设计理念在于提高行车安全性和驾驶舒适性。本文从ACC系统的概述出发,详细探讨了其设计理念与框架,包括系统的设计目标、原则、创新要点及系统架构。关键技术如传感器融合和算法优化也被着重解析。通过介绍ACC软件的功能模块开发、测试验证和人机交互设计,本文详述了系统的实现
ICCAP调优初探:提效IC分析的六大技巧

# 摘要
ICCAP(Image Correlation for Camera Pose)是一种用于估计相机位姿和场景结构的先进算法,广泛应用于计算机视觉领域。本文首先概述了ICCAP的基础知识和分析挑战,深入探讨了ICCAP调优理论,包括其分析框架的工作原理、主要组件、性能瓶颈分析,以及有效的调优策略。随后,本文介绍了ICCAP调优实践中的代码优化、系统资源管理优化和数据处理与存储优化
LinkHome APP与iMaster NCE-FAN V100R022C10协同工作原理:深度解析与实践

# 摘要
本文首先介绍了LinkHome APP与iMaster NCE-FAN V100R022C10的基本概念及其核心功能和原理,强调了协同工作在云边协同架构中的作用,包括网络自动化与设备发现机制。接下来,本文通过实践案例探讨了LinkHome APP与iMaster NCE-FAN V100R022C1
紧急掌握:单因子方差分析在Minitab中的高级应用及案例分析
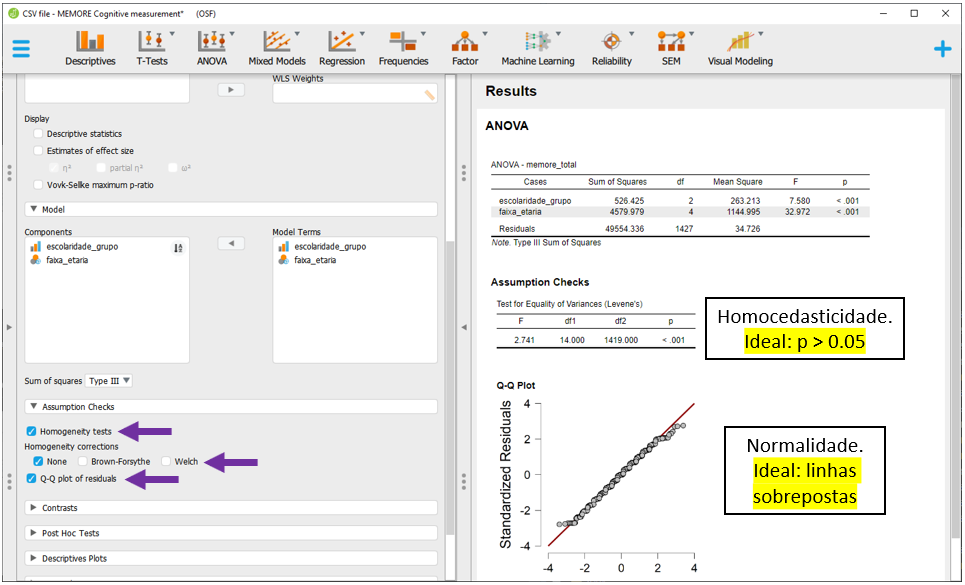
# 摘要
本文详细介绍了单因子方差分析的理论基础、在Minitab软件中的操作流程以及实际案例应用。首先概述了单因子方差分析的概念和原理,并探讨了F检验及其统计假设。随后,文章转向Minitab界面的基础操作,包括数据导入、管理和描述性统计分析。第三章深入解释了方差分析表的解读,包括平方和的计算和平均值差异的多重比较。第四章和第五章分别讲述了如何在Minitab中执行单因子方
全球定位系统(GPS)精确原理与应用:专家级指南

# 摘要
本文对全球定位系统(GPS)的历史、技术原理、应用领域以及挑战和发展方向进行了全面综述。从GPS的历史和技术概述开始,详细探讨了其工作原理,包括卫星信号构成、定位的数学模型、信号增强技术等。文章进一步分析了GPS在航海导航、航空运输、军事应用以及民用技术等不同领域的具体应用,并讨论了当前面临的信号干扰、安全问题及新技术融合的挑战。最后,文
AutoCAD VBA交互设计秘籍:5个技巧打造极致用户体验
# 摘要
本论文系统介绍了AutoCAD VBA交互设计的入门知识、界面定制技巧、自动化操作以及高级实践案例,旨在帮助设计者和开发者提升工作效率与交互体验。文章从基本的VBA用户界面设置出发,深入探讨了表单和控件的应用,强调了优化用户交互体验的重要性。随后,文章转向自动化操作,阐述了对象模型的理解和自动化脚本的编写。第三部分展示了如何应用ActiveX Automation进行高级交互设计,以及如何定制更复杂的用户界面元素,以及解决方案设计过程中的用户反馈收集和应用。最后一章重点介绍了VBA在AutoCAD中的性能优化、调试方法和交互设计的维护更新策略。通过这些内容,论文提供了全面的指南,以应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )