探索CSS及其网页样式化技术
发布时间: 2024-03-10 17:34:03 阅读量: 30 订阅数: 39 

CSS那些事儿:掌握网页样式与CSS布局核心技术
# 1. CSS基础概念
CSS(Cascading Style Sheets),称为层叠样式表,是一种用来描述文档(如HTML文档)样式和展示方式的标记语言。通过CSS,可以控制网页的布局、颜色、字体等外观样式,使网页呈现出更加美观和符合设计要求的效果。
## 1.1 什么是CSS?
CSS是一种样式表语言,定义了如何显示HTML等文档的样式。使用CSS,可以改变文档的布局、颜色、字体、大小等外观表现,使网页更具吸引力和可读性。
## 1.2 CSS的发展历程
- **CSS1**:于1996年发布,引入了基本的样式设置能力。
- **CSS2**:于1998年发布,增加了定位、浮动、继承等功能。
- **CSS3**:从2001年开始推出,分为多个模块,引入了许多新属性和特性。
## 1.3 CSS的基本语法和规则
CSS的基本语法由选择器、属性和属性值构成,如下所示:
```css
selector {
property: value;
}
```
- **选择器**:用来选择要设置样式的HTML元素。
- **属性**:特定的样式属性,如`color`、`font-size`等。
- **属性值**:属性的取值,如`red`、`16px`等。
CSS的规则有层叠性和继承性,同一元素可以通过多个规则进行样式设置,具体样式按照优先级生效。CSS的基本语法和规则是CSS样式表中的基石,后续的章节将深入探讨CSS的更多内容。
# 2. CSS选择器与样式设置
CSS选择器是一种用来选择要设置样式的HTML元素的方法,通过选择器可以直接作用于指定的元素,实现对元素的样式设置。下面将介绍一些常用的CSS选择器,以及样式的设置方法。
### 2.1 常用的CSS选择器
在CSS中,常用的选择器包括:
- **元素选择器:** 通过元素名称选择对应的HTML元素。
- **类选择器:** 通过类名选择HTML元素,以`.`开头。
- **ID选择器:** 通过ID选择HTML元素,以`#`开头。
- **通配符选择器:** 选择所有HTML元素,使用`*`。
- **后代选择器:** 通过元素的后代关系选择元素,使用空格分隔。
- **子元素选择器:** 选择作为某元素子元素的元素,使用`>`。
- **相邻兄弟选择器:** 选择紧接在另一个元素后的元素,使用`+`。
- **属性选择器:** 通过元素的属性选择元素,使用`[]`。
### 2.2 层叠与继承规则
在CSS中,样式会按照一定的优先级进行层叠,多个样式作用在同一个元素上时,会根据以下规则决定样式的优先级:
1. **重要性**:通过`!important`声明的样式具有最高优先级。
2. **特异性**:选择器的特异性越高,优先级越高。
3. **源代码次序**:样式表中后出现的样式优先级更高。
4. **继承**:子元素会继承父元素的样式。
### 2.3 CSS属性和属性值的设置
CSS属性定义了要设置的样式类型,属性值则规定了样式的具体取值。例如,`color`属性定义了文本颜色,属性值可以是颜色名称、十六进制值或RGB值。
```css
/* 示例:设置文本颜色为红色 */
p {
color: red;
}
```
通过合理选择CSS选择器和设置样式属性,可以实现对网页元素的精细控制和样式设置。
# 3. CSS盒模型
#### 3.1 盒模型概述
在CSS中,每个元素都被看作一个矩形的盒子,这个盒子由内容、内边距、边框和外边距组成,这就是所谓的盒模型。了解盒模型对于掌握网页布局和样式设置至关重要。
#### 3.2 盒模型的组成部分
盒模型由以下几个部分组成:
- 内容(content):元素的实际内容,可以通过设置宽度(width)和高度(height)进行控制。
- 内边距(padding):内容区域与边框之间的距离,可以通过设置padding属性进行控制。
- 边框(border):内边距以外,边框包围着内容区域,可以通过设置border属性进行控制。
- 外边距(margin):边框以外,元素与其他元素之间的距离,可以通过设置margin属性进行控制。
#### 3.3 盒模型的应用与布局技巧
利用盒模型,我们可以进行灵活的布局设计,常见的布局技巧包括:
- 使用盒模型实现等高两栏布局
- 利用盒模型进行响应式布局设计
- 通过调整内边距和外边距实现页面排版效果
希望这部分内容能够解答你的疑惑。如果还有其他问题,欢迎继续提问。
# 4. CSS布局技术
在Web开发中,CSS布局技术是至关重要的,能够帮助我们实现页面的布局和排版。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
空间统计学新手必看:Geoda与Moran'I指数的绝配应用
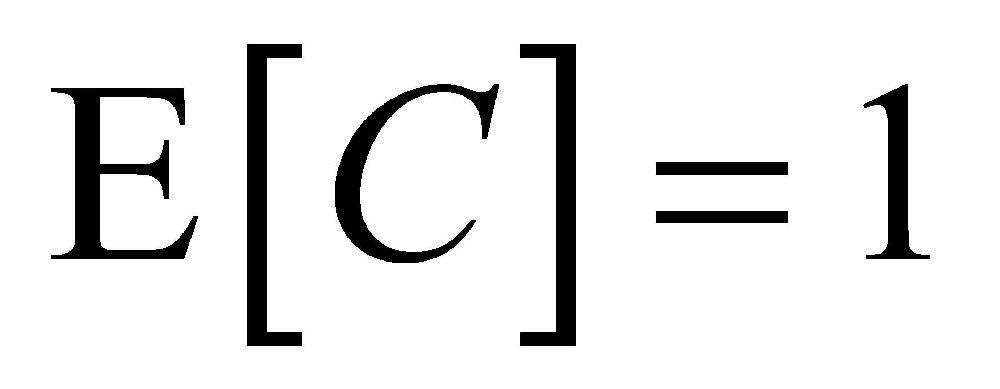
# 摘要
本论文深入探讨了空间统计学在地理数据分析中的应用,特别是运用Geoda软件进行空间数据分析的入门指导和Moran'I指数的理论与实践操作。通过详细阐述Geoda界面布局、数据操作、空间权重矩阵构建以及Moran'I指数的计算和应用,本文旨在为读者提供一个系统的学习路径和实操指南。此外,本文还探讨了如何利用Moran'I指数进行有效的空间数据分析和可视化,包括城市热岛效应的空间分析案例研究。最终,论文展望了空间统计学的未来
【Python数据处理秘籍】:专家教你如何高效清洗和预处理数据

# 摘要
随着数据科学的快速发展,Python作为一门强大的编程语言,在数据处理领域显示出了其独特的便捷性和高效性。本文首先概述了Python在数据处理中的应用,随后深入探讨了数据清洗的理论基础和实践,包括数据质量问题的认识、数据清洗的目标与策略,以及缺失值、异常值和噪声数据的处理方法。接着,文章介绍了Pandas和NumPy等常用Python数据处理库,并具体演示了这些库在实际数
【多物理场仿真:BH曲线的新角色】:探索其在多物理场中的应用
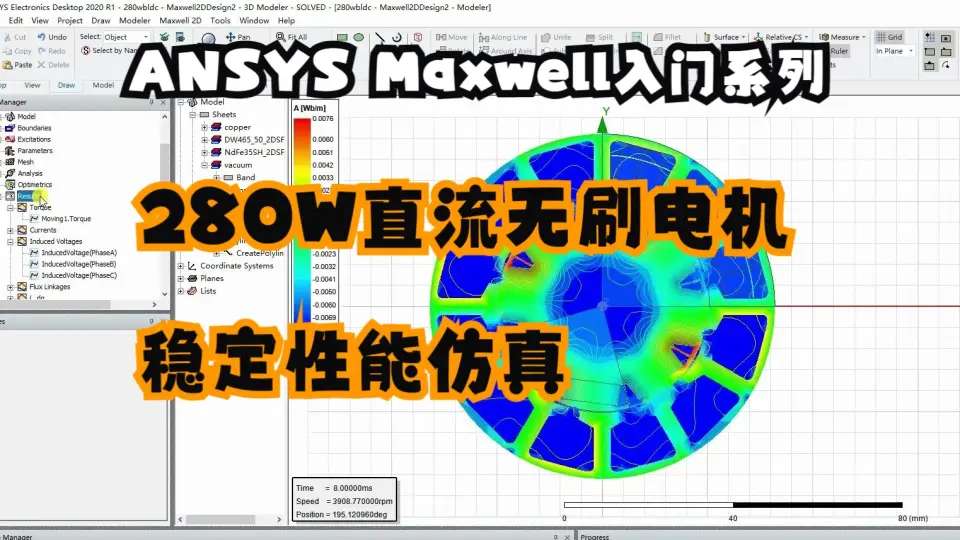
# 摘要
本文系统介绍了多物理场仿真的理论基础,并深入探讨了BH曲线的定义、特性及其在多种材料中的表现。文章详细阐述了BH曲线的数学模型、测量技术以及在电磁场和热力学仿真中的应用。通过对BH曲线在电机、变压器和磁性存储器设计中的应用实例分析,本文揭示了其在工程实践中的重要性。最后,文章展望了BH曲线研究的未来方向,包括多物理场仿真中BH曲线的局限性
【CAM350 Gerber文件导入秘籍】:彻底告别文件不兼容问题
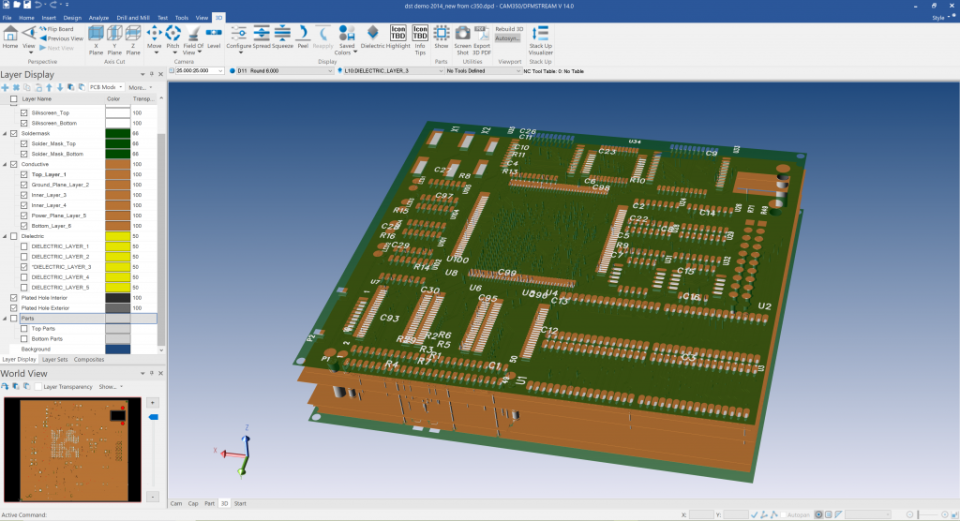
# 摘要
本文全面介绍了CAM350软件中Gerber文件的导入、校验、编辑和集成过程。首先概述了CAM350与Gerber文件导入的基本概念和软件环境设置,随后深入探讨了Gerber文件格式的结构、扩展格式以及版本差异。文章详细阐述了在CAM350中导入Gerber文件的步骤,包括前期
【秒杀时间转换难题】:掌握INT、S5Time、Time转换的终极技巧
# 摘要
时间表示与转换在软件开发、系统工程和日志分析等多个领域中起着至关重要的作用。本文系统地梳理了时间表示的概念框架,深入探讨了INT、S5Time和Time数据类型及其转换方法。通过分析这些数据类型的基本知识、特点、以及它们在不同应用场景中的表现,本文揭示了时间转换在跨系统时间同步、日志分析等实际问题中的应用,并提供了优化时间转换效率的策略和最
【传感器网络搭建实战】:51单片机协同多个MLX90614的挑战

# 摘要
本论文首先介绍了传感器网络的基础知识以及MLX90614红外温度传感器的特点。接着,详细分析了51单片机与MLX90614之间的通信原理,包括51单片机的工作原理、编程环境的搭建,以及传感器的数据输出格式和I2C通信协议。在传感器网络的搭建与编程章节中,探讨了网络架构设计、硬件连接、控制程序编写以及软件实现和调试技巧。进一步
Python 3.9新特性深度解析:2023年必知的编程更新
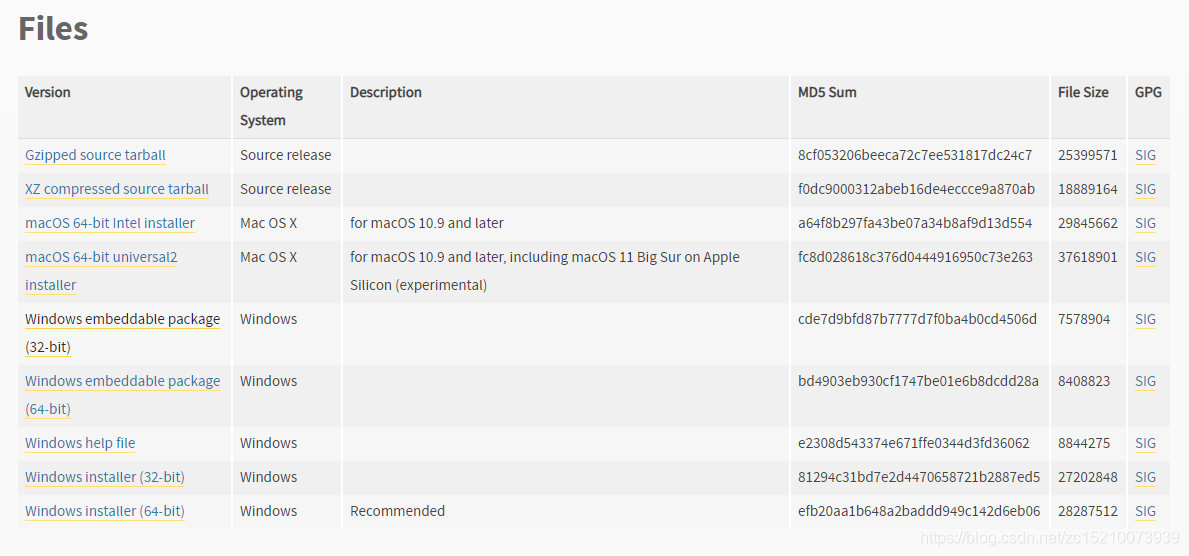
# 摘要
随着编程语言的不断进化,Python 3.9作为最新版本,引入了多项新特性和改进,旨在提升编程效率和代码的可读性。本文首先概述了Python 3.
金蝶K3凭证接口安全机制详解:保障数据传输安全无忧
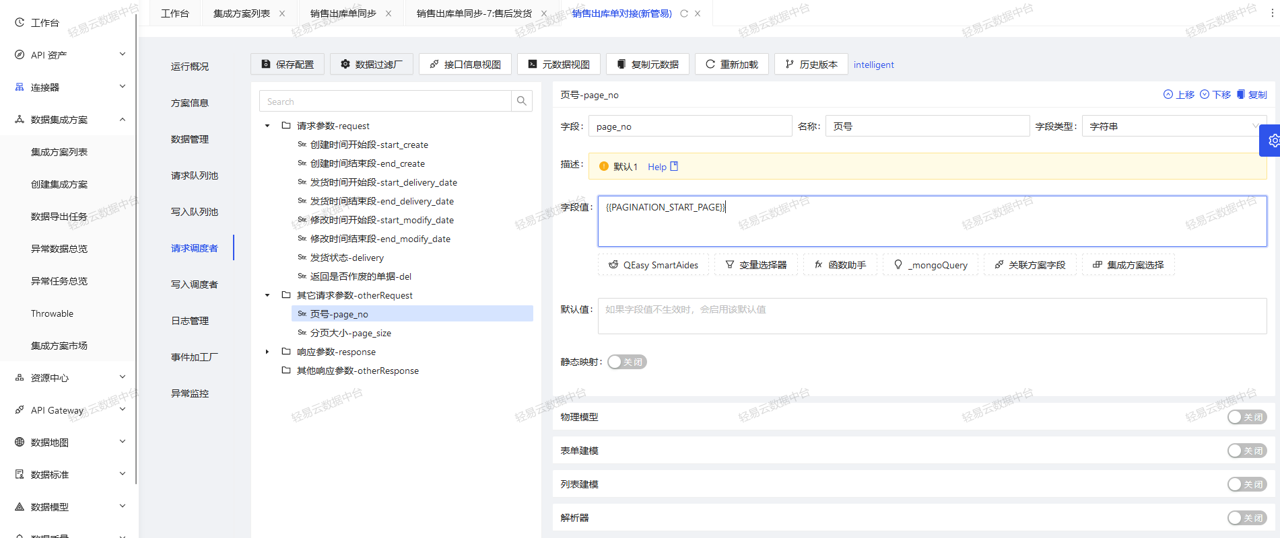
# 摘要
金蝶K3凭证接口作为企业资源规划系统中数据交换的关键组件,其安全性能直接影响到整个系统的数据安全和业务连续性。本文系统阐述了金蝶K3凭证接口的安全理论基础,包括安全需求分析、加密技术原理及其在金蝶K3中的应用。通过实战配置和安全验证的实践介绍,本文进一步阐释了接口安全配置的步骤、用户身份验证和审计日志的实施方法。案例分析突出了在安全加固中的具体威胁识别和解决策略,以及安全优化对业务性能的影响。最后
【C++ Builder 6.0 多线程编程】:性能提升的黄金法则
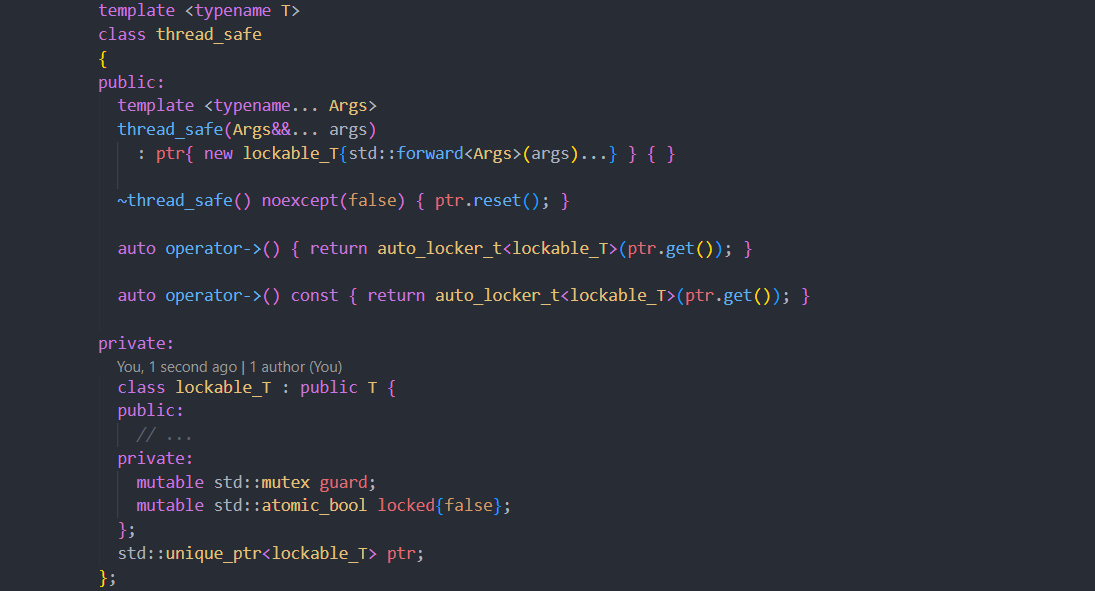
# 摘要
随着计算机技术的进步,多线程编程已成为软件开发中的重要组成部分,尤其是在提高应用程序性能和响应能力方面。C++ Builder 6.0作为开发工具,提供了丰富的多线程编程支持。本文首先概述了多线程编程的基础知识以及C++ Builder 6.0的相关特性,然后深入探讨了该环境下线程的创建、管理、同步机制和异常处理。接着,文章提供了多线程实战技巧,包括数据共享
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )