【DBSCAN聚类算法:核心原理大揭秘,带你解锁数据聚类新境界】
发布时间: 2024-08-21 00:47:43 阅读量: 32 订阅数: 44 

用C++实现DBSCAN聚类算法

# 1. DBSCAN聚类算法概述**
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它能够发现具有任意形状的簇,并且对噪声点不敏感。与其他聚类算法相比,DBSCAN具有以下优点:
- 不需要预先指定簇的数量。
- 能够处理噪声点。
- 能够发现任意形状的簇。
# 2. DBSCAN聚类算法原理
### 2.1 核心点、边界点和噪声点
DBSCAN算法将数据点分为三种类型:核心点、边界点和噪声点。
* **核心点:**一个点如果在其ε邻域内至少包含minPts个点,则称为核心点。
* **边界点:**一个点如果在其ε邻域内包含少于minPts个点,但它位于某个核心点的ε邻域内,则称为边界点。
* **噪声点:**一个点如果既不是核心点也不是边界点,则称为噪声点。
### 2.2 距离度量和邻域查询
DBSCAN算法使用距离度量来计算点之间的距离。常用的距离度量包括欧氏距离、曼哈顿距离和余弦相似度。
邻域查询是DBSCAN算法的关键操作。给定一个点p和一个距离阈值ε,邻域查询返回p的ε邻域内的所有点。
**代码块:**
```python
def get_neighbors(point, data, epsilon):
"""
获取一个点的ε邻域内的所有点。
参数:
point: 要查询的点。
data: 数据集。
epsilon: 距离阈值。
返回:
一个包含ε邻域内所有点的列表。
"""
neighbors = []
for other_point in data:
if distance(point, other_point) <= epsilon:
neighbors.append(other_point)
return neighbors
```
**逻辑分析:**
该函数遍历数据集中的所有点,并计算每个点与给定点的距离。如果距离小于或等于ε,则将该点添加到邻域列表中。
**参数说明:**
* point:要查询的点。
* data:数据集。
* epsilon:距离阈值。
### 2.3 聚类过程
DBSCAN算法的聚类过程如下:
1. 从数据集中的一个未访问的点开始。
2. 计算该点的ε邻域。
3. 如果该点是核心点,则创建一个新的簇并将其添加到簇中。
4. 否则,如果该点是边界点,则将其添加到最近的核心点的簇中。
5. 重复步骤1-4,直到所有点都被访问。
**流程图:**
```mermaid
graph TD
subgraph DBSCAN聚类过程
start[从一个未访问的点开始] --> calculate_neighborhood[计算ε邻域]
calculate_neighborhood --> is_core_point[判断是否为核心点]
is_core_point(yes) --> create_cluster[创建新簇]
is_core_point(no) --> find_nearest_core_point[查找最近的核心点]
find_nearest_core_point --> add_to_cluster[添加到簇]
end[所有点都被访问]
end
```
# 3.1 Python实现DBSCAN算法
#### DBSCAN算法Python实现
```python
import numpy as np
from scipy.spatial import distance_matrix
def dbscan(data, eps, min_pts):
"""
DBSCAN算法Python实现
参数:
data: 输入数据,形状为(n_samples, n_features)
eps: 半径阈值
min_pts: 最小核心点数量
返回:
labels: 聚类标签,形状为(n_samples,)
"""
# 初始化聚类标签为-1(未聚类)
labels = np.full(data.shape[0], -1)
# 核心点索引
core_point_indices = []
# 遍历所有数据点
for i in range(data.shape[0]):
# 计算数据点i到其他所有数据点的距离
distances = distance_matrix(data[i].reshape(1, -1), data).ravel()
# 找出距离小于eps的数据点索引
neighbors = np.where(distances <= eps)[0]
# 如果邻居数量大于等于min_pts,则数据点i为核心点
if len(neighbors) >= min_pts:
core_point_indices.append(i)
# 遍历核心点
cluster_id = 0
for core_point_index in core_point_indices:
# 如果数据点i未被聚类
if labels[core_point_index] == -1:
# 创建一个新的簇
labels[core_point_index] = cluster_id
# 将核心点i的邻居加入待处理队列
queue = [core_point_index]
# 遍历待处理队列
while queue:
# 取出队列中的第一个数据点
point_index = queue.pop(0)
# 计算数据点point_index到其他所有数据点的距离
distances = distance_matrix(data[point_index].reshape(1, -1), data).ravel()
# 找出距离小于eps的数据点索引
neighbors = np.where(distances <= eps)[0]
# 如果邻居数量大于等于min_pts,则数据点point_index为核心点
if len(neighbors) >= min_pts:
# 将数据点point_index的邻居加入待处理队列
queue.extend([neighbor for neighbor in neighbors if labels[neighbor] == -1])
# 将数据点point_index及其邻居标记为同一簇
labels[neighbors] = cluster_id
# 递增簇ID
cluster_id += 1
# 返回聚类标签
return labels
```
#### 代码逻辑分析
* `distance_matrix`函数计算两个数据点之间的距离矩阵。
* `np.where`函数返回满足条件的元素的索引。
* `queue`是一个存储待处理数据点索引的列表。
* 算法遍历核心点,并将核心点的邻居加入待处理队列。
* 算法从待处理队列中取出数据点,并计算其邻居。
* 如果邻居数量大于等于`min_pts`,则数据点为核心点,将其邻居加入待处理队列。
* 算法将数据点及其邻居标记为同一簇。
### 3.2 数据预处理和参数选择
#### 数据预处理
DBSCAN算法对数据预处理要求不高,但以下预处理步骤可以提高算法的性能:
* **数据标准化:**将数据归一化到[0, 1]或[-1, 1]的范围内,以消除数据尺度差异的影响。
* **缺失值处理:**缺失值可以被删除、插补或用平均值代替。
* **异常值处理:**异常值可以被删除或用更合理的值代替。
#### 参数选择
DBSCAN算法有两个主要参数:`eps`和`min_pts`。
* **eps:**半径阈值,控制簇的紧密度。较小的`eps`值会产生更细粒度的簇,而较大的`eps`值会产生更粗粒度的簇。
* **min_pts:**最小核心点数量,控制簇的最小大小。较小的`min_pts`值会产生更多的小簇,而较大的`min_pts`值会产生更少的、更大的簇。
参数选择可以通过交叉验证或网格搜索等技术进行优化。
# 4. DBSCAN聚类算法应用**
**4.1 文本聚类**
文本聚类是将文本数据分组为具有相似主题或内容的组的过程。DBSCAN算法可以有效地用于文本聚类,因为它可以处理噪声数据和发现任意形状的簇。
**4.1.1 文本预处理**
在进行文本聚类之前,需要对文本数据进行预处理,包括:
* **分词:**将文本分解为单个单词或词组。
* **去停用词:**移除常见的非信息性单词,如介词和连词。
* **词干化:**将单词还原为其基本形式,以提高聚类的准确性。
**4.1.2 DBSCAN参数选择**
对于文本聚类,DBSCAN算法的两个关键参数是:
* **eps(邻域半径):**定义了核心点的邻域大小。
* **minPts(最小点数量):**定义了成为核心点的最小点数。
**4.1.3 聚类过程**
文本聚类的DBSCAN算法流程如下:
1. 计算每个数据点的邻域。
2. 识别核心点:具有大于或等于minPts个邻居的数据点。
3. 扩展簇:将核心点及其邻居递归地添加到簇中,直到没有更多的点可以添加到簇中。
4. 分配噪声点:不属于任何簇的数据点被标记为噪声点。
**4.2 图像聚类**
图像聚类是将图像像素分组为具有相似颜色或纹理的组的过程。DBSCAN算法可以用于图像聚类,因为它可以处理噪声数据和发现任意形状的簇。
**4.2.1 图像预处理**
在进行图像聚类之前,需要对图像数据进行预处理,包括:
* **图像分割:**将图像分解为单个像素或像素块。
* **颜色空间转换:**将图像从RGB颜色空间转换为其他颜色空间,如HSV或Lab。
**4.2.2 DBSCAN参数选择**
对于图像聚类,DBSCAN算法的两个关键参数是:
* **eps(邻域半径):**定义了核心点的邻域大小。
* **minPts(最小点数量):**定义了成为核心点的最小点数。
**4.2.3 聚类过程**
图像聚类的DBSCAN算法流程如下:
1. 计算每个像素的邻域。
2. 识别核心点:具有大于或等于minPts个邻居的像素。
3. 扩展簇:将核心点及其邻居递归地添加到簇中,直到没有更多的像素可以添加到簇中。
4. 分配噪声点:不属于任何簇的像素被标记为噪声点。
# 5. DBSCAN聚类算法进阶**
**5.1 算法优化和扩展**
DBSCAN算法的优化和扩展主要集中在以下几个方面:
- **参数优化:**DBSCAN算法有两个主要参数:`minPts`和`eps`。`minPts`表示一个点成为核心点所需的最小邻域点数量,`eps`表示邻域的半径。这两个参数对聚类结果有很大影响,需要根据具体数据集进行调整。
- **距离度量优化:**DBSCAN算法默认使用欧氏距离作为距离度量,但对于某些数据集,其他距离度量(如曼哈顿距离、余弦相似度)可能更合适。
- **并行化:**DBSCAN算法可以并行化,以提高大型数据集上的聚类效率。
- **扩展算法:**DBSCAN算法可以扩展到处理高维数据、流数据和有噪声的数据。
**5.2 DBSCAN算法在实际场景中的应用案例**
DBSCAN算法已广泛应用于各种实际场景中,包括:
- **文本聚类:**将文本文档聚类到不同的主题或类别。
- **图像聚类:**将图像聚类到不同的对象或场景。
- **客户细分:**将客户聚类到不同的组,以便进行有针对性的营销。
- **异常检测:**识别数据集中的异常点或噪声点。
- **疾病诊断:**将患者聚类到不同的疾病组,以便进行早期诊断。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《DBSCAN聚类方法与应用》专栏深入探讨了DBSCAN(基于密度的空间聚类算法)聚类方法的原理、实践、优缺点和应用场景。专栏包含一系列文章,涵盖了DBSCAN算法的核心原理、实战指南、性能优化技巧、变体和改进算法,以及与其他聚类算法的比较。此外,专栏还展示了DBSCAN算法在图像处理、自然语言处理、生物信息学、金融、零售、制造业、医疗保健、科学研究、教育和交通运输等领域的广泛应用。通过深入分析DBSCAN算法,该专栏为数据科学家和机器学习从业者提供了全面的指南,帮助他们了解、应用和优化DBSCAN算法,以从数据中提取有价值的见解和模式。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CANopen与Elmo协同工作:自动化系统集成的终极指南
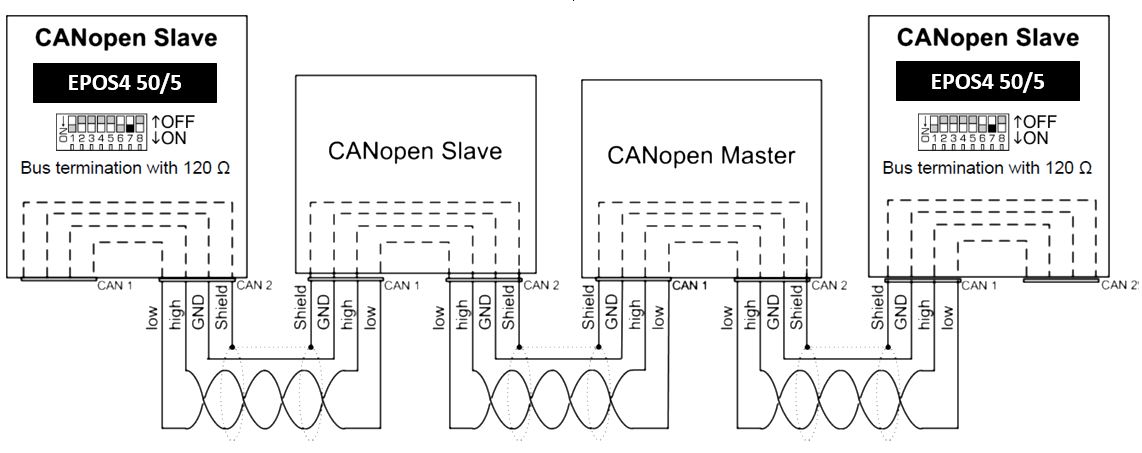
# 摘要
本文综合介绍了CANopen协议和Elmo伺服驱动器的基础知识、集成和协同工作实践,以及高级应用案例研究。首先,概述了CANopen通信模型、消息对象字典、数据交换和同步机制,接着详细讲解了Elmo伺服驱动器的特点、配置优化和网络通信。文章深入探讨了CANopen与Elmo在系统集成、配置和故障诊断方面的协同工作,并通过案例研究,阐述了其在高级应用中的协同功能和性能调优。最后,展望了
【CAT021报文实战指南】:处理与生成,一步到位

# 摘要
CAT021报文作为特定领域内的重要通信协议,其结构和处理技术对于相关系统的信息交换至关重要。本文首先介绍了CAT021报文的基本概览和详细结构,包括报文头、数据字段和尾部的组成及其功能。接着,文章深入探讨了CAT021报文的生成技术,包括开发环境的搭建、编
【QoS终极指南】:7个步骤精通服务质量优化,提升网络性能!
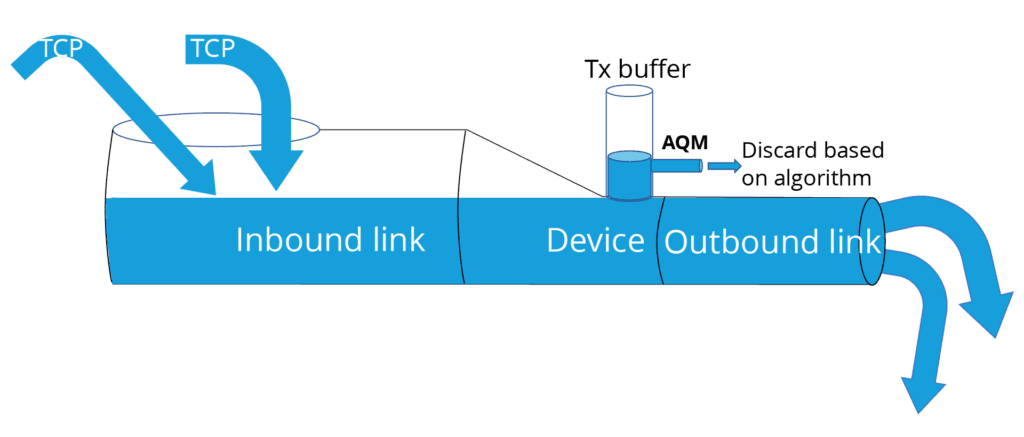
# 摘要
服务质量优化(QoS)是网络管理和性能保障的核心议题,对确保数据传输效率和用户体验至关重要。本文首先介绍了QoS的基础知识,包括其概念、重要性以及基本模型和原理。随后,文章详细探讨了流量分类、标记以及QoS策略的实施和验证方法。在实战技巧部分,本文提供了路由器和交换机上QoS配置的实战指导,包括VoIP和视频流量的优化技术。案例研究章节分析了QoS在不同环境下的部署和
【必备技能】:从零开始的E18-D80NK传感器与Arduino集成指南

# 摘要
本论文旨在介绍E18-D80NK传感器及其与Arduino硬件平台的集成应用。文章首先简要介绍E18-D80NK传感器的基本特性和工作原理,随后详细阐述Arduino硬件和编程环境,包括开发板种类、IDE安装使用、C/C++语言应用、数字和模拟输入输出操作。第三章深入探讨了传感器与Arduino硬件的集成,包括硬件接线、安全
ArcGIS空间数据分析秘籍:一步到位掌握经验半变异函数的精髓
# 摘要
空间数据分析是地理信息系统(GIS)研究的关键组成部分,而半变异函数作为分析空间自相关性的核心工具,在多个领域得到广泛应用。本文首先介绍了空间数据分析与半变异函数的基本概念,深入探讨了其基础理论和绘图方法。随后,本文详细解读了ArcGIS空间分析工具在半变异函数分析中的应用,并通过实际案例展示了其在环境科学和土地资源管理中的实用性。文章进一步探讨了半变异函数模型的构建、空间插值与预测,以及空间数据模拟的高
【Multisim14实践案例全解】:如何构建现实世界与虚拟面包板的桥梁
# 摘要
本文详细介绍了Multisim 14软件的功能与应用,包括其基本操作、高级应用以及与现实世界的对接。文章首先概述了Multisim 14的界面布局和虚拟元件的使用,然后探讨了高级电路仿真技术、集成电路设计要点及故障诊断方法。接着,文章深入分析了如何将Multisim与实际硬件集成,包括设计导出、PCB设计与制作流程,以及实验案例分析。最后,文章展望了软件的优化、扩展和未来发展方向,涵
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )