C++面向对象编程实战指南:掌握设计模式的5个关键步骤
发布时间: 2024-12-09 23:30:57 阅读量: 30 订阅数: 18 

编程高手和老手的C\C++编程指南经验技巧

# 1. 面向对象编程的基本概念和原则
面向对象编程(OOP)是一种流行的编程范式,其核心思想是将数据(属性)和操作数据的方法(函数或行为)封装为一个单一的实体,即“对象”。这种封装为代码提供了模块化和可重用性,使得系统更易于维护和扩展。
## 1.1 对象和类的基本概念
对象是面向对象编程中的基本单位,它代表现实世界中具有特定属性和行为的事物。而类是创建对象的模板或蓝图,它定义了一组具有相同属性和方法的对象的集合。
### 对象的特性
- **封装性**:对象将属性和方法捆绑在一起,隐藏内部实现细节。
- **继承性**:类可以继承另一个类的特性,形成一个层次结构。
- **多态性**:对象可以根据不同情况表现出不同的行为。
## 1.2 OOP的基本原则
面向对象编程的四大基本原则是封装、继承、多态以及抽象。这些原则是设计面向对象系统时的关键考虑因素。
### 封装
封装是一种把数据(属性)和操作数据的代码(方法)结合在一起形成一个对象的方法,其目的是隐藏对象的实现细节,只暴露接口。这样可以限制对象属性和方法的访问级别,保护对象不被外部直接访问。
### 继承
继承允许一个类继承另一个类的属性和方法,使得子类能够重用父类的功能,并扩展其自己的功能。继承是建立类层次结构的基础。
### 多态
多态是一种编程思想,允许将父类的引用指向子类的对象,并通过父类引用调用在各个子类中实现的方法,实现不同类的对象以不同的方式响应相同的消息(或方法调用)。
### 抽象
抽象是将复杂系统中的具体事务通过简化的方式来表示,重点突出事物的本质特征,忽略不重要的细节。它使得程序员能够专注于问题的核心,而不是细节。
面向对象编程通过这些原则提高了代码的可读性、可维护性和可扩展性。下一章节我们将深入探讨如何在C++中实现这些概念。
# 2. C++中的类与对象
## 2.1 类的定义和对象的创建
### 2.1.1 类的基本结构
C++是一种面向对象的编程语言,其中类是面向对象程序设计的核心,它是一种自定义数据类型,允许将数据(属性)和操作(函数)封装在一起。类的定义通常包含了成员变量和成员函数。成员变量表示类的状态,而成员函数定义了类的行为。
下面是一个简单的类定义示例:
```cpp
class Rectangle {
private:
double length;
double width;
public:
// 构造函数
Rectangle(double len, double wid) : length(len), width(wid) {}
// 成员函数计算面积
double area() {
return length * width;
}
// 成员函数设置宽度
void setWidth(double wid) {
width = wid;
}
// 成员函数设置长度
void setLength(double len) {
length = len;
}
};
```
在上述代码中,`Rectangle`类有两个私有成员变量`length`和`width`,它们分别表示矩形的长度和宽度。同时,定义了几个公共成员函数来管理矩形的状态,例如`setLength`和`setWidth`用于设置长度和宽度,`area`用于计算面积。此外,还有一个构造函数用于在创建`Rectangle`对象时初始化这些成员变量。
### 2.1.2 对象的生命周期
对象是类的实例,当对象被创建时,它会分配内存空间,存储其属性和执行方法。对象的生命周期从构造函数执行开始,到析构函数执行结束。在C++中,对象的生命周期管理分为以下几个阶段:
1. **创建对象**:在栈或堆上分配内存给对象。
2. **初始化**:调用构造函数初始化对象状态。
3. **使用对象**:调用成员函数执行操作。
4. **销毁对象**:调用析构函数清理对象占用的资源,通常在对象生命周期结束时自动调用。
在栈上创建的对象会在声明它们的代码块结束时自动销毁。如果对象是在堆上创建的,则必须手动调用`delete`或`delete[]`来释放内存。
```cpp
int main() {
// 在栈上创建对象
Rectangle rect1(10.0, 5.0);
double area = rect1.area(); // 使用对象
// 在堆上创建对象
Rectangle* rect2 = new Rectangle(10.0, 5.0);
double area2 = rect2->area(); // 使用对象
// 销毁对象
delete rect2;
return 0;
}
```
在上述代码示例中,`rect1`是在栈上创建的局部对象,而`rect2`是通过`new`关键字在堆上创建的动态对象。使用完毕后,通过`delete`显式地释放了`rect2`所占用的内存。
## 2.2 访问控制与封装
### 2.2.1 访问修饰符的作用
访问修饰符在C++中用于控制类成员的访问级别。主要有三种类型的访问修饰符:`public`,`private`和`protected`。它们分别控制了类成员可以被哪些代码访问。
- `public`成员可以被任何代码访问。
- `private`成员只能被类的成员函数、友元函数或友元类访问。
- `protected`成员的访问权限介于`public`和`private`之间,通常用于类的继承结构中保护基类成员不被外部直接访问,但可以在派生类中访问。
下面是一个包含不同访问级别的类定义示例:
```cpp
class Example {
public:
void publicFunction() {
// 可以访问 public 成员
}
private:
void privateFunction() {
// 只能被类内部访问
}
protected:
void protectedFunction() {
// 可以被派生类访问
}
};
```
### 2.2.2 封装的意义和实现
封装是面向对象编程的四大基本原则之一,它指的是将数据(或状态)和操作数据的代码捆绑在一起,形成一个对象,并对外隐藏对象的实现细节。封装的好处包括:
- **保护对象的数据**:防止数据被外部程序任意修改。
- **简化接口**:对象的用户不需要了解对象内部的实现细节。
- **增加灵活性**:内部实现可以改变而不影响到用户。
封装通过使用访问修饰符实现。例如,将数据成员设置为`private`,并通过公共成员函数(也称为getters和setters)来访问和修改数据。这样,数据的安全性和对象的接口都得到了控制。
```cpp
class Account {
private:
double balance; // 私有成员变量
public:
// 构造函数
Account(double initBalance) : balance(initBalance) {}
// 获取余额
double getBalance() const {
return balance;
}
// 存款
void deposit(double amount) {
if (amount > 0) {
balance += amount;
}
}
// 取款
bool withdraw(double amount) {
if (amount > 0 && balance
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了 C++ 编程领域的丰富资源和专家见解。从深度解析到实战提升,从面试必备到内存管理,专栏涵盖了 C++ 学习的各个方面。顶级专家分享的高级技巧和最佳实践,助力你提升编程水平。此外,专栏还提供了并发编程、面向对象编程、图形界面开发、游戏开发和模板元编程等专题的深入探讨。通过专栏提供的学习资料和在线课程推荐,你可以制定高效的学习路线图,掌握 C++ 编程的精髓,轻松应对面试挑战,并在实际项目中大展身手。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MODSCAN32专家操作手册:解锁MODBUS通讯的高效工具使用技巧

参考资源链接:[基于MODSCAN32的MODBUS通讯数据解析](https://wenku.csdn.net/doc/6412b5adbe7fbd1778d44019?spm=1055.2635.3001.10343)
# 1. MODSCAN32概述与基础操作
MODSCAN32是一个强大而灵活的工具,被广泛应用于工业通讯协议的测试与维护。作为一款界面友好的MODBUS协议分析工
MATPOWER潮流计算并行处理指南:加速大规模电网分析

参考资源链接:[MATPOWER潮流计算详解:参数设置与案例示范](https://wenku.csdn.net/doc/6412b4a1be7fbd1778d40417?spm=1055.2635.3001.10343)
# 1. MATPOWER潮流计算基础
MATPOWER是一个开源的电
【HyperMesh与HyperView深入应用】:模型分析流程的全方位解析

参考资源链接:[HyperMesh入门:网格划分与模型优化教程](https://wenku.csdn.net/doc/7zoc70ux11?spm=
GP22数据分析高级技巧:挖掘数据潜在价值的终极方法论

参考资源链接:[TDC-GP22:超声波热量表和水表的双通道时间数字转换器](https://wenku.csdn.net/doc/64894c46575329324920fa9a?spm=1055.2635.3001.10343)
# 1. GP22数据分析概述
随着信息技术的飞速发
【单片机USB供电稳定性提升方案】:电源管理电路优化技巧大公开
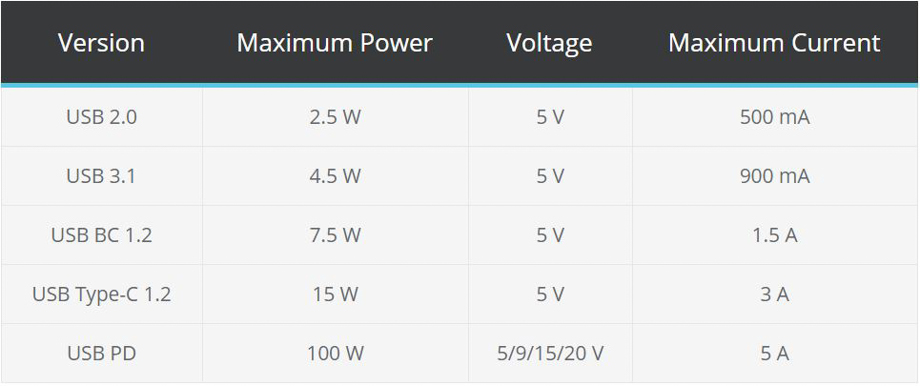
参考资源链接:[单片机使用USB接口供电电路制作](https://wenku.csdn.net/doc/6412b7abbe7fbd1778d4b20d?spm=1055.2635.3001.10343)
# 1. 单片机USB供电基础与挑战
单片机作为电子
【云存储解决方案】:FC协议在云计算中的关键作用

参考资源链接:[FC光纤通道协议详解:从物理层到应用层](https://wenku.csdn.net/doc/4b6s9gwadp?spm=1055.2635.300
飞腾 U-Boot 源码解析:从零开始构建嵌入式系统的权威指南

参考资源链接:[飞腾FT-2000/4 U-BOOT开发与使用手册](https://wenku.csdn.net/doc/3suobc0nr0
B-6系统备份与恢复:数据安全的10个关键步骤

参考资源链接:[墨韵读书会:软件学院书籍共享平台详细使用指南](https://wenku.csdn.net/doc/74royby0s6?spm=1055.2635.3001.10343)
# 1. 数据备份与恢复的重要性
在当今数字化时代,企业
【网络接口设计新手必读】:如何利用LAN8720A构建稳定连接
参考资源链接:[Microchip LAN8720A/LAN8720Ai: 低功耗10/100BASE-TX PHY芯片,全面RMII接口与HP Auto-MDIX支持](https://wenku.csdn.net/doc/6470614a543f844488e461ec?spm=1055.2635.3001.10343)
# 1. 网络接口设计概述
在当今
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )