声音识别与音频处理技术详解
发布时间: 2024-03-03 17:04:29 阅读量: 13 订阅数: 18 
# 1. I. 声音识别技术概述
## A. 什么是声音识别技术?
声音识别技术,又称语音识别技术,是指通过计算机对从声音中提取出的特征进行分析和识别,将声音转化为文字或命令的一种技术。它通过使用数字信号处理、模式识别等方法,实现对声音的自动识别和理解。声音识别技术在人机交互、智能语音助手、智能音箱、语音搜索、语音翻译等领域有广泛应用。
## B. 声音识别的应用领域
声音识别技术在各行各业都有着广泛的应用,包括但不限于:
- 语音助手:如Siri、Alexa、小爱同学等
- 语音搜索:通过说出关键词来获取相关信息
- 语音输入:用语音命令替代键盘输入
- 语音翻译:将一种语言的口头语言翻译成另一种语言
- 语音识别支付:通过声音识别进行身份验证和支付
- 电话客服机器人:自动识别客户的语音指令并作出回应
- 医疗诊断与辅助:用于语音识别诊断和辅助医学交流
## C. 声音识别与语音识别的区别
声音识别和语音识别都涉及分析和理解声音,但它们有着微妙的区别。声音识别更注重声音的频率、振幅等特征,而语音识别则更注重语言的理解和转化,即将声音转化为文字。声音识别通常包含更广泛的声音范围,而语音识别更加专注于语言表达的识别和理解。
# 2. II. 声音信号的获取与处理
声音信号的获取与处理在声音识别与音频处理技术中起着关键作用。下面将介绍声音信号的采集方式、数字化处理以及特征提取方法。
### A. 声音信号的采集方式
在声音信号的采集中,通常会使用麦克风等设备将声音转换为电信号。采集方式可以分为单声道和多声道,单声道一般用于普通语音通信,而多声道适用于环绕声或音乐录制等场景。
```python
import sounddevice as sd
import numpy as np
# 采集声音信号
fs = 44100 # 采样率
duration = 5 # 采集时长
audio_data = sd.rec(int(fs * duration), samplerate=fs, channels=1, dtype='float32')
sd.wait()
print("采集到的声音信号数据为:", audio_data)
```
**代码说明:**
以上代码使用Python的`sounddevice`库采集声音信号,设置采样率为44100Hz,采集时长为5秒,结果存储在`audio_data`中。
### B. 声音信号的数字化处理
声音信号的模拟信号需要经过数字化处理,将其转换为数字信号,方便计算机处理和分析。
```java
import javax.sound.sampled.*;
import java.io.*;
public class AudioCapture {
public static void main(String[] args) {
try {
AudioFormat format = new AudioFormat(44100, 16, 1, true, false);
TargetDataLine line = (TargetDataLine) AudioSystem.getLine(new DataLine.Info(TargetDataLine.class, format));
line.open(format);
line.start();
ByteArrayOutputStream out = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int numBytesRead;
while (true) {
numBytesRead =
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以“智能交互技术”为主题,深入探讨了该领域的多个关键话题和发展趋势。文章涵盖了智能交互技术的简介与发展趋势、用户界面设计原则与实践、人机交互技术与用户体验设计等方面。同时还介绍了自然语言处理技术在智能交互中的应用、手势识别与动作感知技术、情感识别技术与智能交互的融合等内容。此外,专栏还涵盖了智能对话系统、智能推荐系统、数据分析与可视化技术、深度学习算法、无线通信技术、嵌入式系统设计、传感器技术、智能家居系统等诸多方面的内容。通过本专栏,读者将能够全面了解智能交互技术领域的最新进展和未来发展方向。
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB随机数交通规划中的应用:从交通流量模拟到路线优化

# 1.1 交通流量的随机特性
交通流量具有明显的随机性,这主要体现在以下几个方面:
- **车辆到达时间随机性:**车辆到达某个路口或路段的时间不是固定的,而是服从一定的概率分布。
- **车辆速度随机性:**车辆在道路上行驶的速度会受到各种因素的影响,如道路状况、交通状况、天气状况等,因此也是随机的。
- **交通事故随机性:**交通事故的发生具有偶然性,其发生时间
应用MATLAB傅里叶变换:从图像处理到信号分析的实用指南

# 1. MATLAB傅里叶变换概述
傅里叶变换是一种数学工具,用于将信号从时域转换为频域。它在信号处理、图像处理和通信等领域有着广泛的应用。MATLAB提供了一系列函
MATLAB等高线常见问题解答:解决绘制等高线时的疑难杂症,快速上手

# 1. 等高线绘制概述**
等高线是连接具有相同值的点的曲线,广泛用于可视化地理数据、科学数据和工程数据。在 MATLAB 中,等高线绘制是通过使用 `contour`、`contourf` 和 `contour3` 函数实现的。
`contour` 函数绘制二维等高线,而 `contourf` 函数绘制填充等高线,`contour3` 函数绘制三维等高线。这些函数允许用
傅里叶变换在MATLAB中的云计算应用:1个大数据处理秘诀

# 1. 傅里叶变换基础**
傅里叶变换是一种数学工具,用于将时域信号分解为其频率分量。它在信号处理、图像处理和数据分析等领域有着广泛的应用。
傅里叶变换的数学表达式为:
```
F(ω) = ∫_{-\infty}^{\infty} f(t) e^(-iωt) dt
```
其中:
* `f(t)` 是时域信号
* `F(ω)` 是频率域信号
* `ω`
C++内存管理详解:指针、引用、智能指针,掌控内存世界
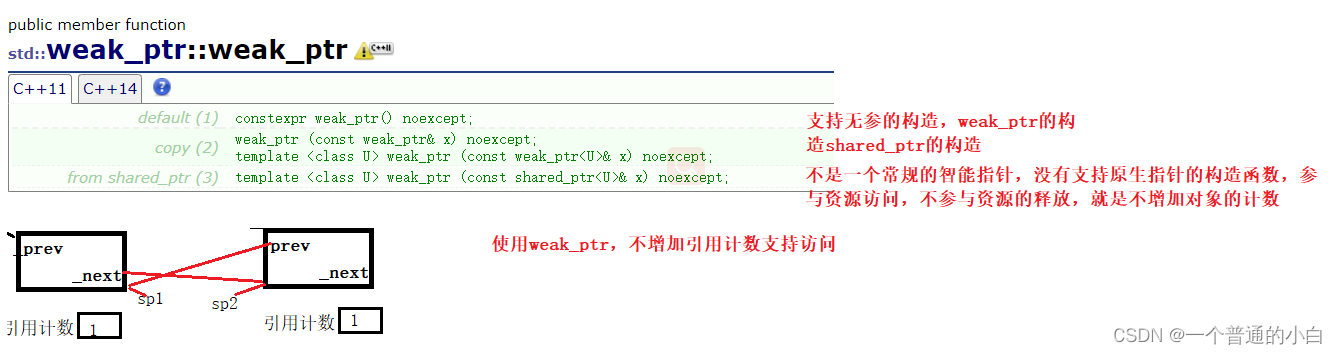
# 1. C++内存管理基础**
C++内存管理是程序开发中的关键环节,它决定了程序的内存使用效率、稳定性和安全性。本章将介绍C++内存管理的基础知识,为后续章节的深入探讨奠定基础。
C++中,内存管理主要涉及两个方面:动态内存分配和内存释放。动态内存分配是指在程序运行时从堆内存中分配内存空间,而内存释放是指释放不再使用的内存空间,将其返还给系统。
# 2. 指针与引用
### 2.1 指针的本
MATLAB阶乘大数据分析秘籍:应对海量数据中的阶乘计算挑战,挖掘数据价值
# 1. MATLAB阶乘计算基础**
MATLAB阶乘函数(factorial)用于计算给定非负整数的阶乘。阶乘定义为一个正整数的所有正整数因子的乘积。例如,5的阶乘(5!)等于120,因为5! = 5 × 4 × 3 × 2 × 1。
MATLAB阶乘函数的语法如下:
```
y = factorial(x)
```
其中:
* `x`:要计算阶
MATLAB数值计算高级技巧:求解偏微分方程和优化问题

# 1. MATLAB数值计算概述**
MATLAB是一种强大的数值计算环境,它提供了一系列用于解决各种科学和工程问题的函数和工具。MATLAB数值计算的主要优
MATLAB遗传算法交通规划应用:优化交通流,缓解拥堵难题

# 1. 交通规划概述**
交通规划是一门综合性学科,涉及交通工程、城市规划、经济学、环境科学等多个领域。其主要目的是优化交通系统,提高交通效率,缓解交通拥堵,保障交通安全。
交通规划的范围十分广泛,包括交通需求预测、交通网络规划、交通管理和控制、交通安全管理等。交通规划需要考虑多种因素,如人口分布、土地利用、经济发展、环境保护等,并综合运用各种技术手段和管理措施,实现交通系统的可持续发展。
# 2. 遗传算法原理
直方图反转:图像处理中的特殊效果,创造独特视觉体验
# 1. 直方图反转简介**
直方图反转是一种图像处理技术,它通过反转图像的直方图来创造独特的视觉效果。直方图是表示图像中不同亮度值分布的图表。通过反转直方图,可以将图像中最亮的像素变为最暗的像素,反之亦然。
这种技术可以产生引人注目的效果,例如创建高对比度的图像、增强细节或创造艺术性的表达。直方图反转在图像处理中有着广泛的应用,包括图像增强、图像分割和艺术表达。
# 2. 直
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )