数据预处理与数据清洗的技术方法
发布时间: 2023-12-21 01:56:19 阅读量: 45 订阅数: 42 

数据预处理方法
## 第一章:数据预处理的概述
### 1.1 数据预处理的基本概念
数据预处理是指在进行数据分析之前,对原始数据进行清洗、转换、集成和规约等操作的过程。其目的是为了使原始数据更适合构建和训练机器学习模型。
### 1.2 数据预处理的重要性
数据预处理是数据分析的关键步骤之一。原始数据往往存在噪声、缺失值、异常值、不一致的格式等问题,如果不经过预处理,会影响数据分析和挖掘的结果准确性和可靠性。
### 1.3 数据预处理对数据分析的影响
数据预处理对数据分析有着直接的影响,合适的数据预处理可以提高模型的准确性和效率,加快模型的训练速度,并且能够更好地挖掘数据的潜在特征,提高数据分析的质量和效果。
## 第二章:数据清洗的基本步骤
数据清洗是数据预处理的重要步骤,通过数据清洗可以解决数据质量问题,提高数据的准确性和可信度。数据清洗的基本步骤包括数据质量问题的识别、错误数据的修复、格式统一化等。下面将介绍数据清洗的基本步骤:
### 2.1 数据清洗的定义
数据清洗是指对原始数据进行清理、筛选、转换以及规范化等操作,以便为数据分析和挖掘提供高质量的数据。
### 2.2 数据质量问题的识别
在数据清洗的过程中,首先需要识别数据中存在的质量问题,常见的数据质量问题包括缺失值、异常值、重复数据、不一致的格式等。
### 2.3 数据清洗的基本步骤
数据清洗的基本步骤包括以下几个方面:
- **缺失值处理:** 对于缺失值,可以选择删除、填充或者插值等方法进行处理。
- **异常值处理:** 通过统计分析或者规则定义的方式识别和处理异常值,可以选择剔除或者修复异常值。
- **数据格式统一化:** 将数据统一转换成一致的格式,比如统一日期格式、统一命名规范等。
- **数据去重:** 对于重复的数据进行去重操作,保留唯一的数据记录。
- **错误数据修复:** 通过规则定义或者模型预测的方式修复数据中的错误。
经过上述基本步骤的数据清洗之后,可以得到更加干净和高质量的数据,为后续的数据分析和建模提供可靠的基础。
# 第三章:常见的数据预处理方法
在数据分析和挖掘过程中,数据预处理是非常重要的一步,它涉及到对数据进行清洗、转换和集成等一系列工作,以确保数据的质量和准确性。下面将介绍一些常见的数据预处理方法,包括缺失值处理、异常值处理以及数据平滑和变换的技术方法。
## 3.1 缺失值处理方法
### 3.1.1 删除缺失值
删除缺失值是一种简单粗暴的方法,当数据中的某些记录存在缺失值时,可以选择直接将这些记录删除。这种方法适用于数据量较大、缺失值占比较小的情况。
```python
# Python示例代码:删除缺失值
df.dropna(inplace=True)
```
### 3.1.2 填充缺失值
填充缺失值是常见的缺失值处理方法,可以使用平均值、中位数、众数等统计量来填充缺失值,也可以使用插值法进行填充。
```python
# Python示例代码:填充缺失值
df['column_name'].fillna(df['column_name'].mean(), inplace=True)
```
## 3.2 异常值处理方法
### 3.2.1 标准差方法
通过计算数据的标准差,可以判断数据是否偏离了均值过多,从而识别异常值。
```python
# Python示例代码:标准差方法识别异常值
mean = df['column_name'].mean()
std = df['column_name'].std()
threshold = 3
df = df[(df['column_name'] > mean - threshold * std) & (df['column_name'] < mean + threshold * std)]
```
### 3.2.2 箱线图方法
利用箱线图可以直观地识别数据中的异常值,箱线图的上下边界以外的数值可以被视为异常值。
```python
# Python示例代码:箱线图方法识别异常值
import seaborn as sns
sns.boxplot(x=df['column_name'])
```
## 3.3 数据平滑和数据变换的技术方法
### 3.3.1 数据平滑
数据平滑可以减少数据的波动和噪音,常见的数据平滑方法包括移动平均法、加权移动平均法等。
```python
# Python示例代码:移动平均法
df['smoothed_data'] = df['original_data'].rolling(window=3).mean()
```
### 3.3.2 数据变换
数据变换可以使数据符合模型的假设,常见的数据变换方法包括对数变换、幂次变换等。
```python
# Python示例代码:对数变换
df['log_transformed_data'] = np.log(df['original_data'])
```
通过以上数据预处理方法,可以使原始数据变得更加整洁和准确,为后续的数据分析工作奠定良好的基础。
以上是第三章的内容,请问是否还需要其他章节的内容呢?
### 第四章:常用的数据清洗技术
数据清洗是数据预处理的一个重要环节,通过清洗可以有效处理数据中存在的噪声、错误和不一致,提高数据的质量。在数据清洗过程中,常用的技术包括去重复、格式统一化和错误数据修复。
#### 4.1 去重复
去重复是清洗数据中常见的操作,通过去除重复的记录可以避免数据分析中产生错误的结果。在实际应用中,可以通过以下方式实现数据的去重复操作:
```python
# Python示例:使用pandas库对数据进行去重复操作
import pandas as pd
# 读取数据
data = pd.read_csv('data.csv')
# 去除重复行
data.drop_duplicates(inplace=True)
# 保存结果
data.to_csv('cleaned_data.csv', index=False)
```
代码总结:上述代码使用pandas库读取数据后,调用drop_duplicates()函数去除重复行,并最终保存清洗后的数据。
结果说明:经过去重复操作后,清洗后的数据可以提供给后续的数据分析使用,避免重复数据对分析结果产生影响。
#### 4.2 格式统一化
在实际数据中,有时候同一类数据可能因为来源不同导致格式不一致,这就需要进行格式统一化的工作,以确保数据的一致性和准确性。以下是一个简单的格式统一化操作示例:
```java
// Java示例:使用String类的方法进行格式统一化
public class DataFormatNormalization {
public String normalizeString(String input) {
// 格式统一化处理
String output = input.trim().toUpperCase(); // 去除空格并转换为大写
return output;
}
}
```
代码总结:上述Java示例通过定义一个方法来对字符串进行格式统一化处理,去除空格并统一转换为大写。
结果说明:经过格式统一化处理后,可以确保数据在同一标准下进行分析,避免格式不一致导致的错误分析结果。
#### 4.3 错误数据修复
数据中常常会存在一些错误数据,例如缺失值、异常值等,需要通过修复操作将其纠正。以下是一个针对缺失值的简单修复示例:
```javascript
// JavaScript示例:使用lodash库对数据中的缺失值进行修复
const _ = require('lodash');
// 修复缺失值
function fixMissingValue(data) {
_.forEach(data, function (value, key) {
if (_.isNull(value) || _.isUndefined(value) || value === '') {
data[key] = 'N/A'; // 使用默认值填充缺失值
}
});
return data;
}
```
代码总结:上述JavaScript示例使用lodash库中的forEach函数遍历数据,对缺失值进行修复,使用默认值"N/A"填充缺失值。
结果说明:经过错误数据修复操作后,可以保证数据的完整性和准确性,为后续的数据分析提供可靠的数据基础。
以上是常用的数据清洗技术的介绍,这些技术方法在数据预处理过程中起着至关重要的作用。
## 第五章:数据预处理与数据清洗工具的介绍
在数据预处理与数据清洗过程中,使用适当的工具可以提高效率,简化操作,降低错误率。本章将介绍一些常用的数据预处理与数据清洗工具,以及它们的特点和适用场景。
### 5.1 数据预处理工具
#### Python中的工具
- **Pandas**:Pandas是Python中一个强大的数据分析库,提供了丰富的数据预处理功能,包括数据清洗、转换、合并等,是数据分析师和科学家的首选工具之一。
- **NumPy**:NumPy是Python中用于数值计算的库,也提供了许多数据预处理的功能,例如处理缺失值、数据变换等。
#### Java中的工具
- **Weka**:Weka是一款使用Java编写的数据挖掘软件,提供了丰富的数据预处理功能,包括数据过滤、特征选择、异常值处理等,适用于需要进行大规模数据处理的场景。
- **RapidMiner**:RapidMiner是一个集成了数据挖掘、机器学习和预测分析的开源工具,也是使用Java编写,提供了直观的用户界面和丰富的数据预处理功能,适用于初学者和专家。
### 5.2 数据清洗工具
#### 开源工具
- **OpenRefine**:OpenRefine(之前叫做Google Refine)是一款强大的开源数据清洗工具,提供了交互式的界面和丰富的数据清洗功能,包括数据转换、合并、拆分等,适用于各种数据清洗场景。
- **Trifacta Wrangler**:Trifacta Wrangler是另一款功能强大的开源数据清洗工具,提供了自动化的数据清洗功能和智能建议,可以大大简化数据清洗的流程,使用户可以更快速地进行数据清洗。
#### 商业工具
- **Informatica Data Quality**:Informatica是一家知名的数据管理和集成解决方案提供商,其Data Quality产品提供了全面的数据清洗功能,包括数据分析、重复记录识别、地址解析等,适用于企业级数据清洗应用。
- **Talend Data Preparation**:Talend是一家提供数据集成解决方案的公司,其Data Preparation产品提供了直观的数据清洗界面和丰富的数据清洗功能,适用于企业数据处理和分析场景。
### 5.3 开源工具与商业工具对比
开源工具通常免费且社区支持强大,适合个人用户和小型团队使用;而商业工具提供了更多高级功能和技术支持,适用于大型企业和复杂场景下的数据清洗需求。选择工具时需要根据实际需求和预算来进行权衡和选择。
### 第六章:数据预处理与数据清洗的最佳实践
在数据预处理与数据清洗的实践中,有一些技术方法和应用是业界认可的最佳实践。本章将从实际案例分析、数据挖掘中的应用以及未来发展趋势与展望三个方面进行探讨。
#### 6.1 最佳实践案例分析
在实际业务中,数据预处理与清洗是至关重要的步骤,下面我们以一个电商平台的数据为例,来介绍最佳实践的案例分析。
##### 场景描述:
假设我们是一家电商平台,拥有海量的用户数据,并且每天都会产生大量新的交易数据。在进行数据分析之前,我们首先需要对这些数据进行预处理与清洗,以保证数据质量和准确性。
##### 代码示例(Python):
```python
# 导入数据预处理与清洗所需的库
import pandas as pd
import numpy as np
# 读取原始数据
raw_data = pd.read_csv('raw_data.csv')
# 去除重复数据
cleaned_data = raw_data.drop_duplicates()
# 缺失值处理
cleaned_data['age'].fillna(cleaned_data['age'].mean(), inplace=True)
cleaned_data['gender'].fillna('unknown', inplace=True)
# 数据格式统一化
cleaned_data['amount'] = cleaned_data['amount'].str.replace('$', '').astype(float)
# 错误数据修复
cleaned_data.loc[cleaned_data['age'] < 0, 'age'] = 0
# 保存处理后的数据
cleaned_data.to_csv('cleaned_data.csv', index=False)
```
##### 代码总结:
在这个案例中,我们使用Python的pandas库对电商平台的用户数据进行了预处理与清洗。具体包括去重复、缺失值处理、数据格式统一化和错误数据修复等步骤。最终得到了清洗后的数据集,并保存为cleaned_data.csv文件。
##### 结果说明:
经过数据预处理与清洗后,我们得到了一份数据质量更高、更适合进行后续分析挖掘的数据集,可以更加准确地了解用户行为、购买习惯等信息,为业务决策提供支持。
#### 6.2 数据挖掘中的数据预处理与清洗技术应用
数据挖掘是数据预处理与清洗的重要应用领域之一。在进行数据挖掘任务时,高质量的数据预处理与清洗能够有效提升模型的准确性和稳定性。
##### 数据预处理:
- 特征选择:去除无效特征和冗余特征,提高模型效率。
- 特征变换:对原始特征进行变换、缩放和归一化,以便更好地满足模型的假设和要求。
##### 数据清洗:
- 异常值处理:识别和处理异常值,避免异常值对模型的影响。
- 数据平滑:通过数据平滑技术处理噪声数据,提高数据质量。
#### 6.3 未来发展趋势与展望
随着大数据、人工智能等技术的快速发展,数据预处理与清洗技术也在不断演进和完善。未来,我们可以期待以下发展趋势:
- 自动化处理:数据预处理与清洗的自动化处理将会更加成熟,节省人力成本。
- 多模态数据处理:结合图像、文本等多模态数据的处理方法,拓展数据处理技术的应用场景。
- 实时处理:针对实时数据的预处理与清洗技术将会更加重要,满足实时分析与决策需求。
通过对这些发展趋势的应用与实践,数据预处理与清洗技术将会在更多领域展现出强大的作用,为数据驱动决策提供更可靠的支持。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏涵盖了百亿级数据存储与管理策略、数据索引与查询优化、高性能数据查询实现、并行计算与数据处理、分布式数据库的横向扩展与高可用性、数据安全与权限控制等多个方面的内容。其中包括了如何设计支持百亿级数据秒级检索的数据库架构、倒排索引在大规模数据检索中的应用与优化、基于内存数据库的高性能数据查询实现、大规模数据存储系统的容灾与备份策略等具有广泛实用价值的话题。同时,专栏还深入探讨了关系型数据库与NoSQL数据库的选择与比较、分布式缓存与缓存一致性的解决方案、数据压缩与压缩索引的实现与优化等技术细节,为数据领域的从业者提供了丰富的实践经验和技术指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Windows系统性能升级】:一步到位的WinSXS清理操作手册
# 摘要
本文针对Windows系统性能升级提供了全面的分析与指导。首先概述了WinSXS技术的定义、作用及在系统中的重要性。其次,深入探讨了WinSXS的结构、组件及其对系统性能的影响,特别是在系统更新过程中WinSXS膨胀的挑战。在此基础上,本文详细介绍了WinSXS清理前的准备、实际清理过程中的方法、步骤及
Lego性能优化策略:提升接口测试速度与稳定性
# 摘要
随着软件系统复杂性的增加,Lego性能优化变得越来越重要。本文旨在探讨性能优化的必要性和基础概念,通过接口测试流程和性能瓶颈分析,识别和解决性能问题。文中提出多种提升接口测试速度和稳定性的策略,包括代码优化、测试环境调整、并发测试策略、测试数据管理、错误处理机制以及持续集成和部署(CI/CD)的实践。此外,本文介绍了性能优化工具和框架的选择与应用,并
UL1310中文版:掌握电源设计流程,实现从概念到成品

# 摘要
本文系统地探讨了电源设计的全过程,涵盖了基础知识、理论计算方法、设计流程、实践技巧、案例分析以及测试与优化等多个方面。文章首先介绍了电源设计的重要性、步骤和关键参数,然后深入讲解了直流变换原理、元件选型以及热设计等理论基础和计算方法。随后,文章详细阐述了电源设计的每一个阶段,包括需求分析、方案选择、详细设计、仿真
Redmine升级失败怎么办?10分钟内安全回滚的完整策略
# 摘要
本文针对Redmine升级失败的问题进行了深入分析,并详细介绍了安全回滚的准备工作、流程和最佳实践。首先,我们探讨了升级失败的潜在原因,并强调了回滚前准备工作的必要性,包括检查备份状态和设定环境。接着,文章详解了回滚流程,包括策略选择、数据库操作和系统配置调整。在回滚完成后,文章指导进行系统检查和优化,并分析失败原因以便预防未来的升级问题。最后,本文提出了基于案例的学习和未来升级策
频谱分析:常见问题解决大全

# 摘要
频谱分析作为一种核心技术,对现代电子通信、信号处理等领域至关重要。本文系统地介绍了频谱分析的基础知识、理论、实践操作以及常见问题和优化策略。首先,文章阐述了频谱分析的基本概念、数学模型以及频谱分析仪的使用和校准问题。接着,重点讨论了频谱分析的关键技术,包括傅里叶变换、窗函数选择和抽样定理。文章第三章提供了一系列频谱分析实践操作指南,包括噪声和谐波信号分析、无线信号频谱分析方法及实验室实践。第四章探讨了频谱分析中的常见问题和解决
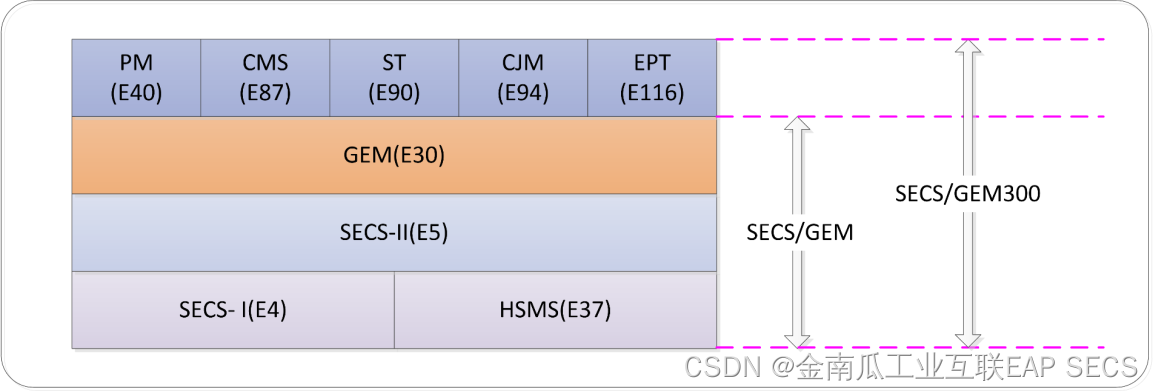
SECS-II在半导体制造中的核心角色:现代工艺的通讯支柱
# 摘要
SECS-II标准作为半导体行业中设备通信的关键协议,对提升制造过程自动化和设备间通信效率起着至关重要的作用。本文首先概述了SECS-II标准及其历史背景,随后深入探讨了其通讯协议的理论基础,包括架构、组成、消息格式以及与GEM标准的关系。文章进一步分析了SECS-II在实践应用中的案例,涵盖设备通信实现、半导体生产应用以及软件开发与部署。同时,本文还讨论了SECS-II在现代半导体制造
深入探讨最小拍控制算法

# 摘要
最小拍控制算法是一种用于实现快速响应和高精度控制的算法,它在控制理论和系统建模中起着核心作用。本文首先概述了最小拍控制算法的基本概念、特点及应用场景,并深入探讨了控制理论的基础,包括系统稳定性的分析以及不同建模方法。接着,本文对最小拍控制算法的理论推导进行了详细阐述,包括其数学描述、稳定性分析以及计算方法。在实践应用方面,本文分析了最小拍控制在离散系统中的实现、
【Java内存优化大揭秘】:Eclipse内存分析工具MAT深度解读

# 摘要
本文深入探讨了Java内存模型及其优化技术,特别是通过Eclipse内存分析工具MAT的应用。文章首先概述了Java内存模型的基础知识,随后详细介绍MAT工具的核心功能、优势、安装和配置步骤。通过实战章节,本文展示了如何使用MAT进行堆转储文件分析、内存泄漏的检测和诊断以及解决方法。深度应用技巧章节深入讲解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )